目录
例如:我们需要获取每个品牌的用户评分的min,max,avg等值
聚合
聚合是根据查询后的结果来聚合的,如果没有写query查询条件,就是对索引库的所有文档进行聚合
聚合的分类
聚合(aggregations)可以实现对文档数据的统计,分析,运算。聚合常见的有三类:
1.桶(Bucket)聚合:用来对文档进行分组,相当于mysql的group by
- TermAggregation:按照文档字段值进行分组,注意:这个文档字段不可分词
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一个月为一组
2.度量(Metric)聚合:用来计算一些值,比如:最大值,最小值,平均值
3.管道(pipeline)聚合:其他聚合的结果为基础做聚合
参与聚合的字段类型必须是:
- keyword
- 数值
- 日期
- 布尔
DSL实现桶聚合
现在,我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
dsl语句
GET /hotel/_search
{
"size":0, //返回命中文档的详细信息的数量,(默认执行match_all),这里设置为0就是不返回文档的详细信息
"aggs":{ //聚合查询关键字
"brandSum":{ //桶名字
"trems":{ //聚合的类型,这里使用brand字段聚合,所以使用terms
"field":"brand",
"size":20 //返回最多的桶数量,如果设置为1,就只返回一个桶的信息
}
}
}
}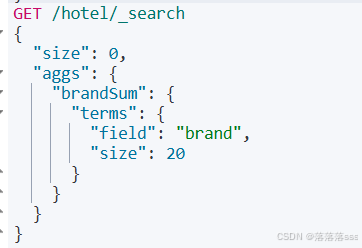
结果
可以看见hits数组里的值为空,因为我们设置了size=0,不返回文档的详细信息
brandSum就是这个聚合的名字,buckets桶数组最大的大小为20,默认通过桶里的文档数降序排序

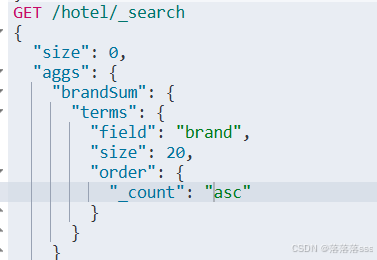
聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{
"size":0,
"aggs":{
"brandSum":{
"terms":{
"field":"brand",
"size":20,
"order":{ #自定义排序规则
"_count":asc #使用桶内的文档数进行升序排序
}
}
}
}
}

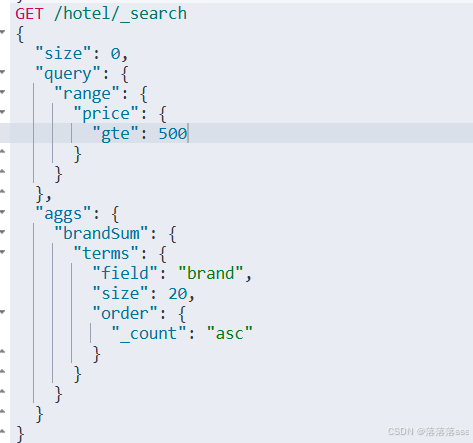
限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
只聚合价格大于500的文档
总结
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置的属性
- size:指定聚合结果(即桶的最大数量)的最大数量
- order:指定聚合结果排序的方式
- field:指定聚合的字段
DSL实现metric聚合
例如:我们需要获取每个品牌的用户评分的min,max,avg等值
GET /hotel/_search
{
"aggs":{
"brandSum":{
"terms":{
"field":"brand",
"size":20
},
"aggs":{ //brandSum聚合下的子聚合
"scoreStats":{//子聚合名字
"stats":{ //聚合的类型·。stats会把max,min,avg,sum,count都算出来
"field":"score"
}
}
}
}
}
}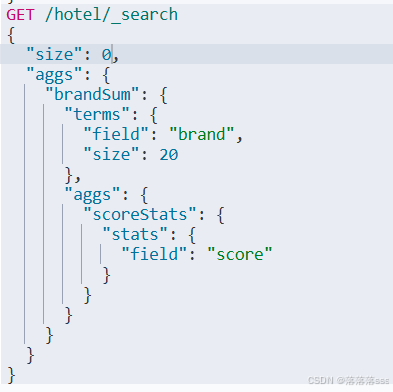

只求socre的max
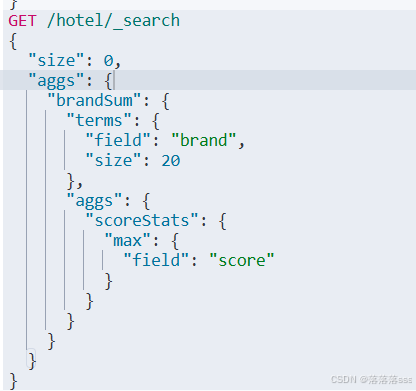

利用RestHighLevelClient实现聚合
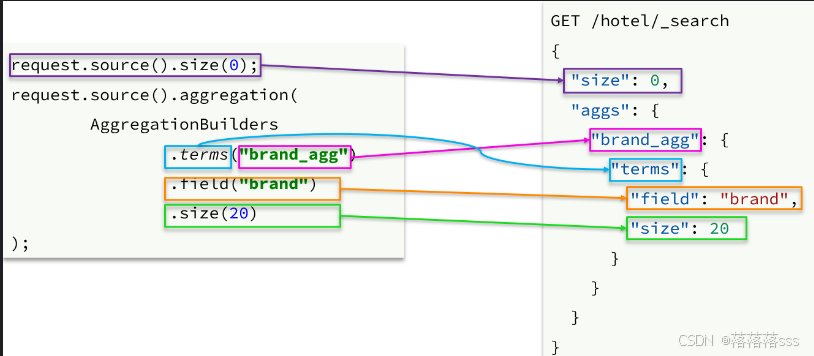

@SpringBootTest
public class TestAggregation {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
public void test01() throws IOException {
//构建 查询对象
SearchRequest request = new SearchRequest("hotel");
//设置dsl语句
request.source().size(0);
request.source().aggregation(AggregationBuilders
.terms("brandSum")//指定聚合的名字为brandSum,且聚合的类型是terms
.field("brand")//指定聚合的字段是brand
.size(20));
//发送请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//解析响应数据
Aggregations aggregations = response.getAggregations();
Terms brandSum= aggregations.get("brandSum");
List<? extends Terms.Bucket> buckets = brandSum.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println(key);
}
}
}业务需求
需求:搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:
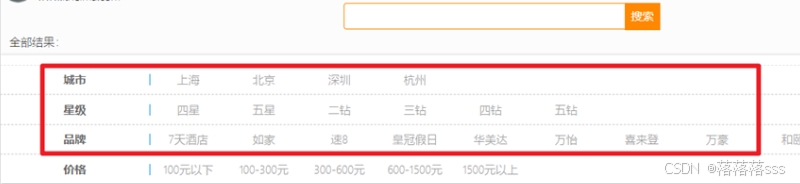
分析:
目前,页面的城市列表、星级列表、品牌列表都是写死的,并不会随着搜索结果的变化而变化。但是用户搜索条件改变时,搜索结果会跟着变化。
例如:用户搜索“东方明珠”,那搜索的酒店肯定是在上海东方明珠附近,因此,城市只能是上海,此时城市列表中就不应该显示北京、深圳、杭州这些信息了。
也就是说,搜索结果中包含哪些城市,页面就应该列出哪些城市;搜索结果中包含哪些品牌,页面就应该列出哪些品牌。
如何得知搜索结果中包含哪些品牌?如何得知搜索结果中包含哪些城市?
使用聚合功能,利用Bucket聚合,对搜索结果中的文档基于品牌分组、基于城市分组,就能得知包含哪些品牌、哪些城市了。
因为是对搜索结果聚合,因此聚合是限定范围的聚合,也就是说聚合的限定条件跟搜索文档的条件一致。
查看浏览器可以发现,前端其实已经发出了这样的一个请求:
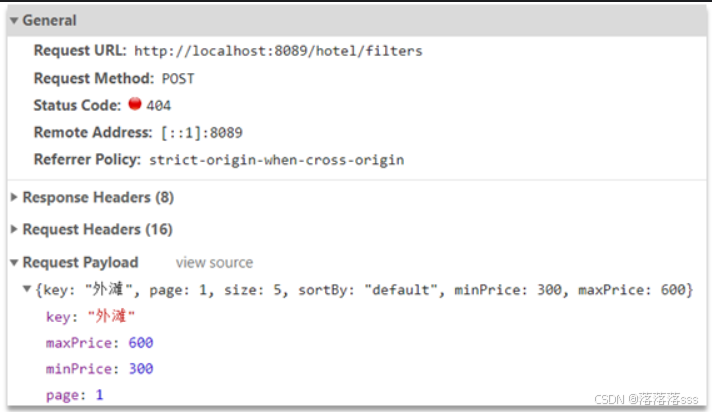
请求参数与搜索文档的参数完全一致。
返回值类型就是页面要展示的最终结果:
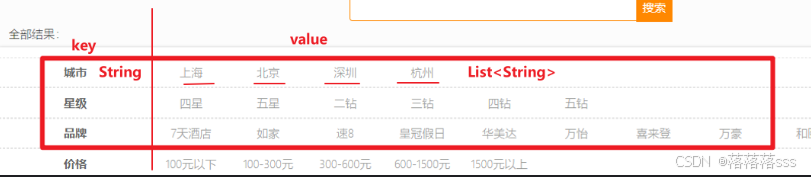
结果是一个Map结构:
- key是字符串,城市、星级、品牌、价格
- value是集合,例如多个城市的名称
dsl语句

结果会有三个桶聚合的结果,可以发现因为查询条件match全文匹配了上海,所以citySum聚合桶内只有一种城市就是上海,这种情况是正确的 ,因为聚合是根据查询后的结果来聚合的,如果没有query查询条件,就是对索引库的所有文档进行聚合
这里有三种聚合,都是独立的 ,city聚合,brand聚合,starName聚合

java代码
前端封装类
package com.hhh.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
// 下面是新增的过滤条件参数
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
//坐标
private String location;
}
controller层
@RestController
@RequestMapping("/hotel")
public class HotelController {
@Autowired
private HotelService hotelService;
@PostMapping("/list")
public PageResult getPageResult(@RequestBody RequestParams params){
return hotelService.getPageResult(params);
}
/**
* 获取传入条件过滤出 星级,城市,品牌
*/
@PostMapping("/filters")
public Map<String, List<String>> getFilters(@RequestBody RequestParams params){
return hotelService.getFilters(params);
}
}service服务层
前端进行搜索时,会发送两个请求,一个请求时/hotel/list获取匹配到的hotel信息,还有一个请求时/hotel/filters获取根据查询条件得到的结果去聚合过滤出的星级,城市和品牌
@Service
public class HotelServiceImpl extends ServiceImpl<HotelMapper, Hotel>
implements HotelService {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public PageResult getPageResult(RequestParams params) {
//1.构建 查询请求对象
SearchRequest request = new SearchRequest("hotel");
//2.编写dsl语句
/* //2.1如果key为空,即搜索的内容为空,就全文查询
if(StringUtils.isBlank(params.getKey())){
request.source().query(QueryBuilders.matchAllQuery());
}else {
request.source().query(QueryBuilders.matchQuery("all",params.getKey()));
}*/
assembleBasicQuery(params,request);
//构建高亮显示
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
//3.构建分页信息
Integer pageNum=params.getPage()==null?1:params.getPage();//默认是第一页
Integer pageSize=params.getSize()==null?5:params.getSize();//默认每页大小为5
request.source().from((pageNum-1)*pageSize).size(pageSize);
//TODO:维护距离排序
if(StringUtils.isNotBlank(params.getLocation())) {
GeoDistanceSortBuilder geoDistanceSortBuilder = new GeoDistanceSortBuilder("location", new GeoPoint(params.getLocation()))
.order(SortOrder.ASC) // 升序排序
.unit(DistanceUnit.KILOMETERS); // 单位为千米
request.source().sort(geoDistanceSortBuilder);
}
if(params.getSortBy().equals("price")){
request.source().sort("price",SortOrder.ASC);
} else if (params.getSortBy().equals("score")) {
request.source().sort("score",SortOrder.DESC);
}
//4.发送请求
SearchResponse response = null;
try {
response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException("查询异常");
}
//5.解析数据
Boolean isEnableKm=false;
if(params.getLocation()!=null){
isEnableKm=true;//location字段不为null,才设置为true,然后获取排序值
}
return ParseResponse(response,isEnableKm);
}
/**
* 获取传入条件过滤出 星级,城市,品牌
*/
@Override
public Map<String, List<String>> getFilters(RequestParams params) {
SearchRequest request = new SearchRequest("hotel");
request.source().size(0);
//设置query DSL语句
assembleBasicQuery(params,request);
//构建桶聚合
request.source().aggregation(AggregationBuilders
.terms("brandSum")
.field("brand")
.size(20));
request.source().aggregation(AggregationBuilders
.terms("citySum")
.field("city")
.size(20));
request.source().aggregation(AggregationBuilders
.terms("starNameSum")
.field("starName")
.size(20));
//发起请求
SearchResponse response = null;
try {
response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//解析返回数据
List<String>brands=parseAggreData(response,"brandSum");
List<String>citys=parseAggreData(response,"citySum");
List<String>startNames=parseAggreData(response,"starNameSum");
Map<String, List<String>> info = new HashMap<>();
info.put("brand",brands);
info.put("city",citys);
info.put("starName",startNames);
return info;
}
/**
* 解析桶数据
* @return
*/
private List<String> parseAggreData(SearchResponse response, String sum) {
Aggregations aggregations = response.getAggregations();
Terms aggregation = aggregations.get(sum);
if(aggregation==null||CollectionUtils.isEmpty(aggregation.getBuckets())){
return null;
}
ArrayList<String> list = new ArrayList<>();
for (Terms.Bucket bucket : aggregation.getBuckets()) {
String key = bucket.getKeyAsString();
list.add(key);
}
return list;
}
/**
* 组装dsl查询语句
* @param params 前端封装类
* @param request 查询请求对象
*/
private void assembleBasicQuery(RequestParams params,SearchRequest request){
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//1.判断key是否为空
if(StringUtils.isBlank(params.getKey())){
boolQuery.must(QueryBuilders.matchAllQuery());
}else{
boolQuery.must(QueryBuilders.matchQuery("all",params.getKey()));
}
//品牌名不为空,对品牌过滤
if(StringUtils.isNotBlank(params.getBrand())){
boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));
}
//城市
if(StringUtils.isNotBlank(params.getCity())){
boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));
}
//星级
if(StringUtils.isNotBlank(params.getStarName())){
boolQuery.filter(QueryBuilders.termQuery("startName",params.getStarName()));
}
//价格范围
if(params.getMaxPrice()!=null&¶ms.getMinPrice()!=null){
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//定义算分函数
//设置排名,根据算分设置level排名
FieldValueFactorFunctionBuilder functionBuilder = ScoreFunctionBuilders.fieldValueFactorFunction("value").modifier(FieldValueFactorFunction.Modifier.NONE).factor(1.5F).missing(1);
FunctionScoreQueryBuilder.FilterFunctionBuilder[] functions = new FunctionScoreQueryBuilder.FilterFunctionBuilder[] {
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAD",true),
//ScoreFunctionBuilders.weightFactorFunction(10) // 权重因子,乘以基础得分
functionBuilder
)
};
FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(boolQuery, functions).boostMode(CombineFunction.SUM);
request.source().query(functionScoreQuery);
}
/**
* 解析es响应的数据
*/
private PageResult ParseResponse(SearchResponse response,Boolean isEnableKm) {
SearchHits hits = response.getHits();
//1.获取总命中文档数
long size = hits.getTotalHits().value;
SearchHit[] hits1 = hits.getHits();
ArrayList<HotelDoc> docs = new ArrayList<>();
if(ArrayUtils.isNotEmpty(hits1)){
for (SearchHit searchHit : hits1) {
String jsonData = searchHit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(jsonData, HotelDoc.class);
if(isEnableKm) {
//获取排序后的距离
Object[] sortValues = searchHit.getSortValues();
if (ArrayUtils.isNotEmpty(sortValues)) {
hotelDoc.setDistance(sortValues[0]);
}
}
//获取高亮
Map<String, HighlightField> fieldMap = searchHit.getHighlightFields();
if(!CollectionUtils.isEmpty(fieldMap)){
HighlightField highlightField = fieldMap.get("name");
String highName = highlightField.getFragments()[0].string();
//替换hotel实体类的name属性
hotelDoc.setName(highName);
}
docs.add(hotelDoc);
}
}
return new PageResult(size,docs);
}
}
结果
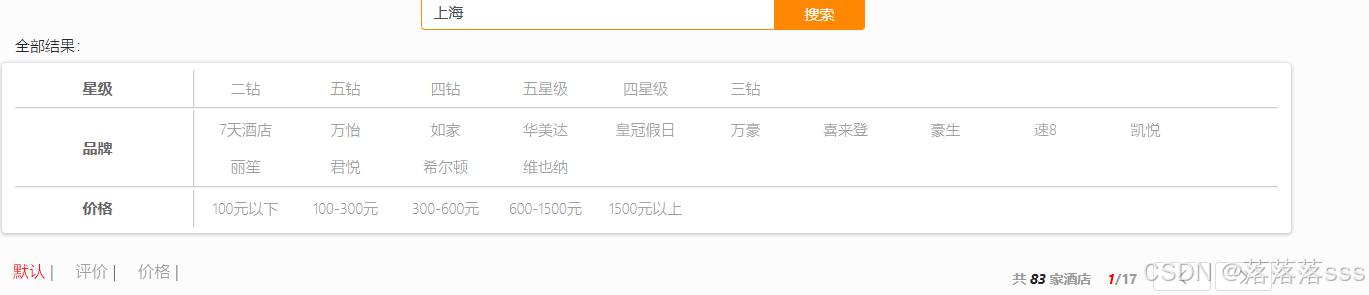
输入上海进行搜索时,会根据hotel/list获取全文检索匹配的文档信息,然后根据/hotel/filters获取过滤出的city,brand,price,但是根据上海匹配出来的文档,经过city字段进行聚合时,citySum桶内只有一个数据就是上海,只有一个数据时,直接在前端不显示其他城市的选择即可,因为没必要
然后brandSum桶内有所有品牌的名字,和 starSum桶内所有的星级都会显示出来(因为桶内的数量大于1)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » es实现桶聚合

发表评论 取消回复