#1024程序员节|征文#

在1024程序员节这个特别的日子里,首先,我想对每一位程序员表示最诚挚的祝贺!祝愿大家在未来的日子里,能够继续热爱编程、追求卓越,携手共创更美好的科技未来!让我们共同庆祝属于程序员的节日!
这篇主要讲解的是Linux命令、消息队列(RabbitMq等等)、Redis(击穿、穿透、雪崩等问题)
Liux命令
cd 切换目录
pwd 查看当前路径
mkdir 创建目录
mv 修改目录名称
ps -ef|grep java 查看java进程
kill -9 进程号 杀掉进程
tail -400f 文件名称 查看最后400行
tail -50f ./zookeeper.out |grep '/usr/local/src/java/' 搜索zookeeper.out日志包含的/usr/local/src/java/
vi 编辑文本
cat 查看文件
find文件
chmod 777 ./start.sh 给star.sh赋所有权限
top 查看服务器资源,比如内存,cpu使用情况
消息队列
RabbitMQ的死信队列和延时队列?
消息被拒,requeue设置 为 false
消息过期,队列达到最大程度 这时候会存放到死信队列中去。
设置消息过期时间:采用队列中的x-message-ttl 参数去设置,单位是毫秒
关于ActiveMQ、RocketMQ、RabbitMQ、Kafka一些总结和区别
为什么使用消息队列?
异步(发送手机验证码),
解耦(借款系统和风控系统),
削峰(秒杀,购买商品,放入消息队列排队)
使用消息队列有什么缺点?
(1).多了一个MQ服务,可能会出现单点故障,导致系统不可用(集群)
(2).消息队列重复消费幂等问题(一个操作无论执行多少次,都会自己业务没有任何影响)
(3).消息队列丢失问题
(4).消息队列顺序问题
消息队列如何选型?
ActiveMQ集群模式很复杂,它的集群模式是分片的,每个机器上只存了部分数据,万一服务挂了,数据就丢了,最高并发10万以内,社区活跃度比较低,对开发的系统安全有影响
RabbitMQ集群模式,可以保证服务挂了,不丢消息,最高并发10万以内,社区活跃度比较高
RocketMQ集群模式,可以保证服务挂了,不丢消息,最高并发10万以上,社区活跃度比较高
Kafka(集群模式,打点统计,日志统计),高并发100万
如何保证消息队列是高可用的?
集群
如何保证消息不被重复消费?
根据业务场景做幂等(1.比如唯一的信息我们可以建唯一索引,2.监听里面做校验幂等操作,3.每个消息分配一个唯一的id,uuid,消费完redis存一下,然后后面每次都进来校验下)
如何保证消息的顺序性?
1.保证一个生产者对应着一个消费者
2.监听器里面把消息消费放到JVM队列(LInkedBlockQueue),然后再消费本地队列
如何保证消息不丢失?
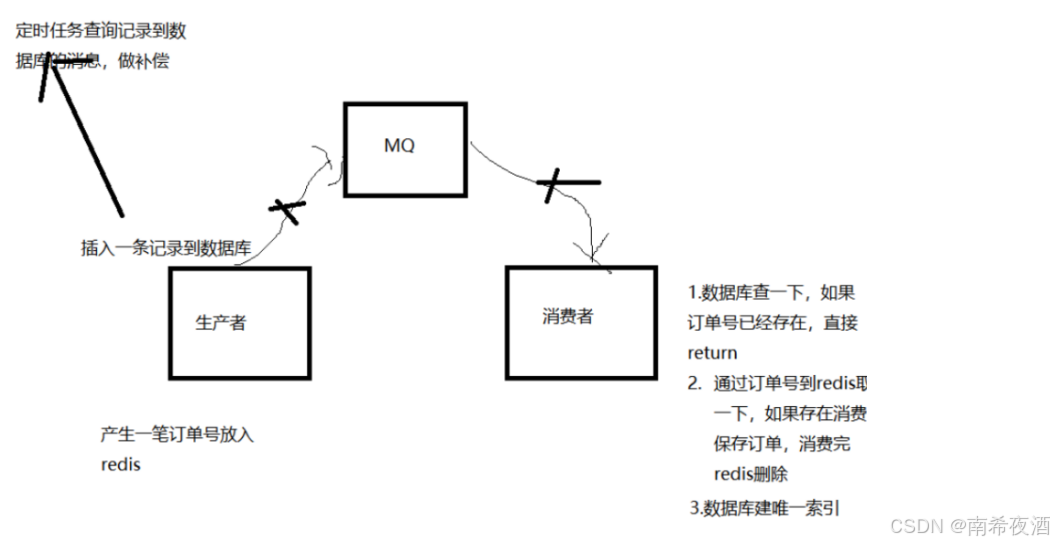
MQ发送消息到消费的整个过程分为3个阶段,生产者-MQ-消费者,
1.保证MQ服务的高可用,做集群,持久化
2.消费者在消费MQ里面的内容的时候,如果MQ保存了,MQ会有重试机制,重试还失败后会进入死信队列,然后消息丢失,这个过程可以采用ACK确认机制,手动签收消息,如果消费失败,让消息还是在MQ里面
如果消息在生产者发送到MQ的过程中,因为通讯网络问题,也可能会丢失,这个时候需要做消息持久化,我们会把消息存入到数据库,如果消费成功,把消息删除掉,当然删除消息可能会失败,后面我们可以通过定时任务轮询做补偿,然后继续忘消息队列里面发消息,那么这样可能会出现一个新问题,消息的重复消费,需要考虑幂等问题,我们消息持久化的时候都会分配一个msgId唯一标识,后面消费完了存入redis,消费之前校验一下就可以了
Redis
为什么使用redis?
1.支持高可用,3.0集群
2.丰富的数据类型
3.完全内存操作,速度快,支持持久化
4.存储数据大,单个key和value可以存储到1G
Redis 的持久化方式?
redis持久化方式有RDB和AOF ,RDB是方式是每过几秒保存的是redis数据的快照,但是可能会丢数据,AOF 保存的是所有在redis执行的命令,它会追加到一个文件里面,丢数据可能性小,但会导致文件很大,假如redis宕机了,恢复的时候会很慢,我们一般使用RDB,因为我们对redis的定位就是缓存服务器,很重要的数据我们不会存redis,比如与钱有关系。
Redis内存淘汰策略?
noeviction:直接返回错误,不淘汰任何已经存在的redis键
allkeys-lru:所有的键使用lru算法进行淘汰
volatile-lru:有过期时间的使用lru算法进行淘汰
allkeys-random:随机删除redis键
volatile-random:随机删除有过期时间的redis键
volatile-ttl:删除快过期的redis键
volatile-lfu:根据lfu算法从有过期时间的键删除
allkeys-lfu:根据lfu算法从所有键删除
redis有哪几种数据类型
string ,hash,list,set,zset
redis分布式锁底层原理?
redis分布式锁其实就是往redis设置一个key和value同时设置一个有效时间,并且redis是单线程的,不会并发操作,(执行任务完成后),再把redis的key删除掉(解锁),但是在使用的过程中可能有2个问题,使用过程中我们必须保证设置key和value和设置时间保证它的原子性(LUA),另外还是锁超时问题,比如:上锁2秒钟,但是任务执行超过2秒,我们一般用redission框架,它底层是lua脚本实现,可以保证设置值和时间的原子性,另外还有
看门狗的机制,watch dog,我们上锁3秒,但是任务执行5秒,它会自动加时间
为什么使用分布式锁?
因为我们的系统是分布式的,synchronized和lock锁只能是JVM级别的,这个时候需要分布式锁,它实现的思路: redis分布式锁其实就是往redis设置一个key和value同时设置一个有效时间,并且redis是单线程的,不会并发操作,(执行任务完成后),再把redis的key删除掉(解锁),这个过程需要注意的点是,必须保证设置key和value和设置时间保证它的原子性,不然可能出现死锁,另外一方面就是锁任务自动超时问题,所有我们一般用的redisson框架,它完美的帮我们封装了分布式锁,底层是基于LUA脚本实现保证原子性,同时redission
还有watch dog,比如我们上锁3秒,但是任务执行5秒,它会自动加时间
1.分布式锁{
redis查商品,3
校验随机码,
检验秒杀时间段,
商品id和随机码是不是一样,
检验每人限购数量,
检验库存,3
锁定库存(减库存)
下单消息队列
}
redis集群模式?
1.主从复制(缺点,主挂掉后,需要人工切换干预,不能保证服务的高可用)
2.哨兵模式(一主多从,主挂掉后,会自动选举主再提供服务,缺点:1.极端情况下网络不是很好的情况,选举需要花时间,可能服务不可用。2. 资源浪费,Redis 数据节点中 slave 节点作为备份节点 )
3.集群模式( Redis Cluster 是 3.0 版后推出的 Redis 分布式集群解决方案 )
1. 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
2. 可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除。
3. 高可用性:部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover
redis哨兵(Sentinel)模式?
redis节点之间通过心跳检测,从服务器(slave)每过一段时间向主服务器(master)发送一个ping命令,主服务器的响应,如果主服务器挂了,所有从服务器通信,有一种算法选举为主,再提供服务
redis cluster原理?
所有的redis结点都是彼此互联的
客户端连接集群的时候不需要关心分片的计算逻辑,客户端直接将key交给redis中的结点,最终由内部判断key值的正确存储位置
redis集群是吧所有的主节点都交给对应的卡槽去处理【0-16383】,由主节点去维护一批数据。数据主要是被哪个结点维护是判断对应key的取模运算,如果要迁移某个key值,必须将对应的slot(槽)一并迁移
redis脑裂问题?
redis集群由于网络的原因可能会出现脑裂的问题,脑裂就是因为主服务器、从服务器和哨兵不在同一个网络中,导致哨兵没有及时的检测到主服务的心跳,在这个时候会在从服务器中去选举一个新的主服务器,这样就有两个主服务器了就像大脑分裂一样,但是这样会导致客户依旧 在旧的主服务器中去写东西,而新的主服务器中没有东西。当网络恢复后,哨兵会把旧的主服务器变成从服务器,这个 时候在去同步数据,可能会造成一个数据的丢失
解决方法:
redis中需要加入两个配置
(旧版本)
min-slaves-to-write 3 最少有3个从服务器
min-slaves-max-lag 10 数据复制和同步的延迟不超过10秒
(新版本)
min-replicas-to-write 3
min-replicas-max-lag 10
如果加了这两个配置的话,原来的主服务器当客户端再次进行写操作的时候会拒绝接受,此时就发送到新的主服务器中去了
什么是缓存和数据库双写不一致?怎么解决?
数据的信息和缓存由于并发或者其中一个失败导致不一致
解决方案:我们一般是先修改数据库,再删除缓存,因为我们对redis的定位是缓存,redis可能会丢数据,首先保证我们的数据库必须更新,如果redis删除失败,我们采用补偿策略,比如错误了或失败了,把信息放MQ,做消费补偿
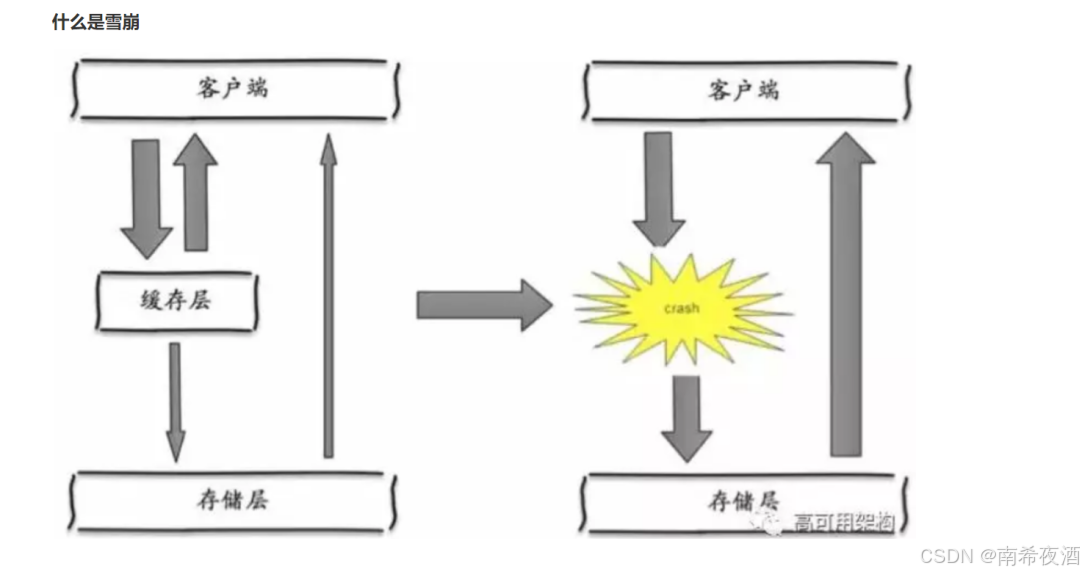
缓存雪崩是指:由于缓存中的数据一下子全部都在同一时间过期了,所以发送过来的全部请求都去请求数据库,导致数据库难以承受而宕机。
解决方法:
- 可以保证 redis高可用,建集群;
- 设置不同的过期时间,防止全部在同一时间过期
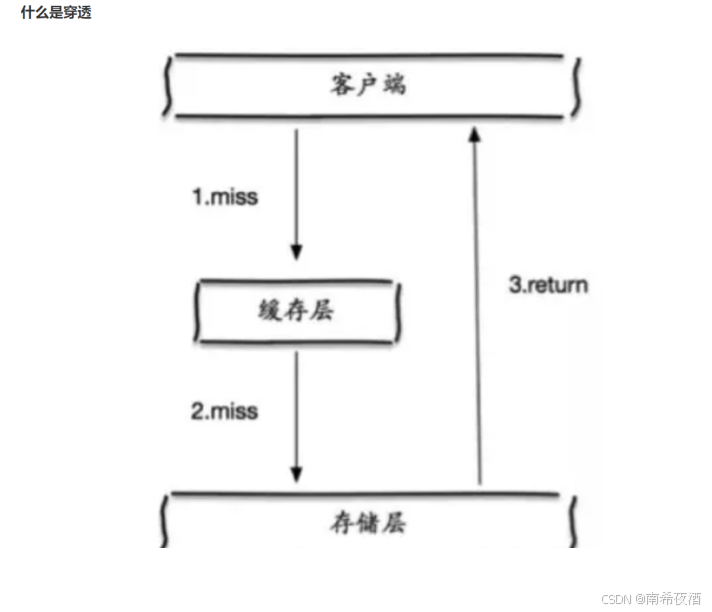
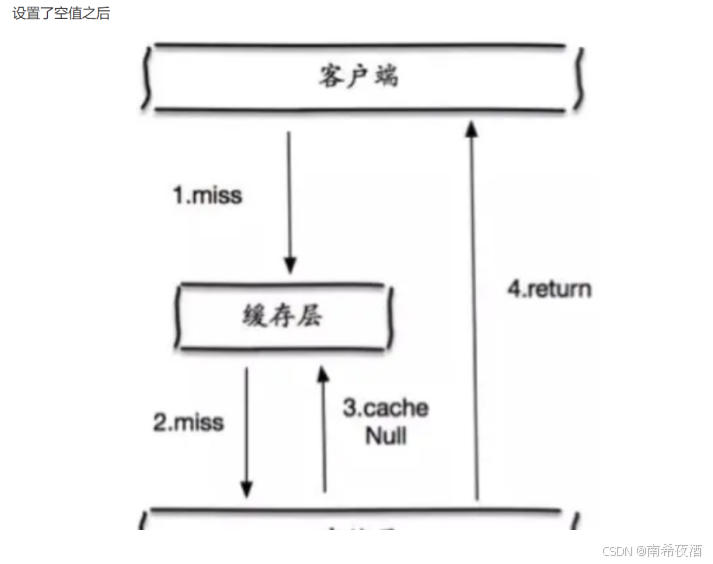
缓存穿透是指:缓存和数据库中都没有数据,如果有人恶意访问的会先去缓存查询,此时缓存中无数据,后在去数据库中去查询,数据库中也没有,这个时候就会导致数据库宕机
解决方法:
可以在缓存中设置一个null值,让恶意的请求不会直接击垮数据库,每次访问的时候都去访问此缓存。
可以设计一个过滤器,常用的就是布隆过滤器(可以缓解,为什么是缓解,因为使用过滤器还会造成误判的情况)
缓存击穿是指:一条数据在查询的时候突然过期了,那么就所有的请求都打在数据库上
解决方法:
加锁,只让一个人去访问数据库并且将访问的数据存入缓存中,供其他的请求来访问
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » JAVA面试八股文(五)

发表评论 取消回复