本节课程地址:61 编码器-解码器架构【动手学深度学习v2】_哔哩哔哩_bilibili
本节教材地址:9.6. 编码器-解码器架构 — 动手学深度学习 2.0.0 documentation (d2l.ai)
本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>encoder-decoder.ipynb
编码器-解码器架构
正如我们在 9.5节 中所讨论的, 机器翻译是序列转换模型的一个核心问题, 其输入和输出都是长度可变的序列。 为了处理这种类型的输入和输出, 我们可以设计一个包含两个主要组件的架构: 第一个组件是一个编码器(encoder): 它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。 第二个组件是解码器(decoder): 它将固定形状的编码状态映射到长度可变的序列。 这被称为编码器-解码器(encoder-decoder)架构, 如 图9.6.1 所示。
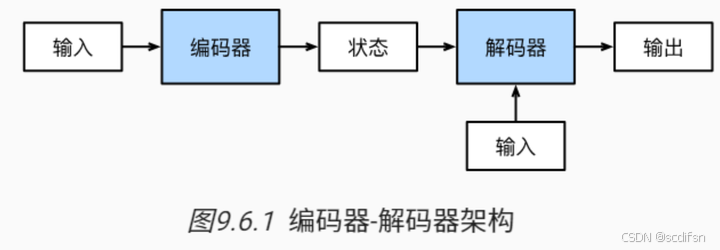
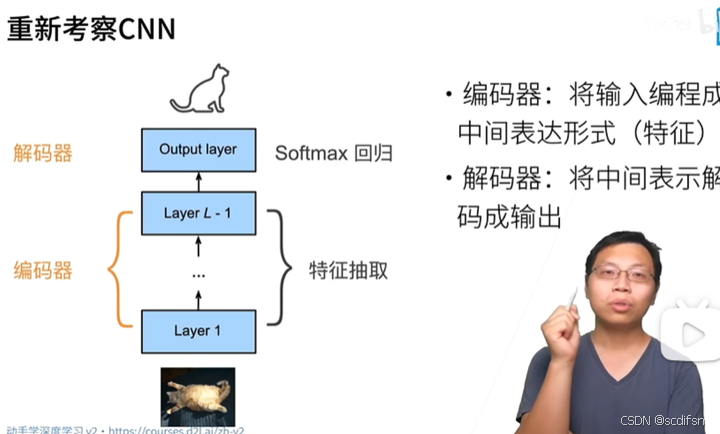
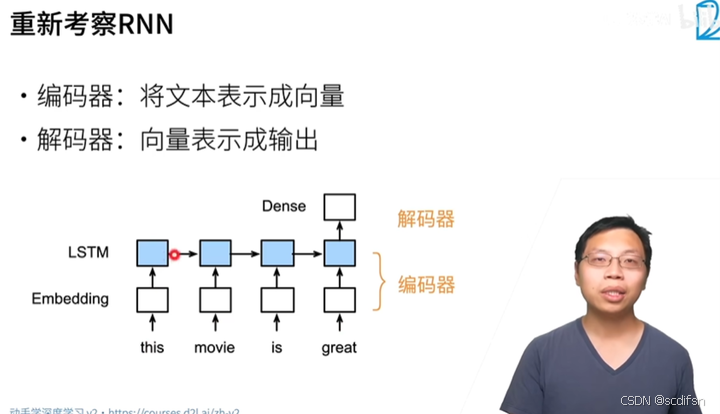
我们以英语到法语的机器翻译为例: 给定一个英文的输入序列:“They”“are”“watching”“.”。 首先,这种“编码器-解码器”架构将长度可变的输入序列编码成一个“状态”, 然后对该状态进行解码, 一个词元接着一个词元地生成翻译后的序列作为输出: “Ils”“regordent”“.”。 由于“编码器-解码器”架构是形成后续章节中不同序列转换模型的基础, 因此本节将把这个架构转换为接口方便后面的代码实现。
(编码器)
在编码器接口中,我们只指定长度可变的序列作为编码器的输入X。 任何继承这个Encoder基类的模型将完成代码实现。
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError[解码器]
在下面的解码器接口中,我们新增一个init_state函数, 用于将编码器的输出(enc_outputs)转换为编码后的状态。 注意,此步骤可能需要额外的输入,例如:输入序列的有效长度, 这在 :numref:subsec_mt_data_loading中进行了解释。 为了逐个地生成长度可变的词元序列, 解码器在每个时间步都会将输入 (例如:在前一时间步生成的词元)和编码后的状态 映射成当前时间步的输出词元。
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
# 来自Encoder的输出
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError[合并编码器和解码器]
总而言之,“编码器-解码器”架构包含了一个编码器和一个解码器, 并且还拥有可选的额外的参数。 在前向传播中,编码器的输出用于生成编码状态, 这个状态又被解码器作为其输入的一部分。
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)“编码器-解码器”体系架构中的术语状态 会启发人们使用具有状态的神经网络来实现该架构。 在下一节中,我们将学习如何应用循环神经网络, 来设计基于“编码器-解码器”架构的序列转换模型。
小结
- “编码器-解码器”架构可以将长度可变的序列作为输入和输出,因此适用于机器翻译等序列转换问题。
- 编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。
- 解码器将具有固定形状的编码状态映射为长度可变的序列。
练习
- 假设我们使用神经网络来实现“编码器-解码器”架构,那么编码器和解码器必须是同一类型的神经网络吗?
解:
编码器和解码器不用必须是同一类型的神经网络,根据具体的应用和设计需求,它们可以是不同类型的网络结构。 - 除了机器翻译,还有其它可以适用于”编码器-解码器“架构的应用吗?
解:
还有其他应用,比如:
- 在文本摘要任务中,编码器读取整个文档并将其编码成一个固定长度的向量,解码器则从这个向量生成摘要文本。
- 在自动语音识别系统中,编码器处理音频波形,将其转换成特征表示,解码器则将这些特征转换成文本。
- 编码器可以处理自然语言描述,解码器生成相应的代码片段。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 动手学深度学习9.6. 编码器-解码器架构-笔记&练习(PyTorch)

发表评论 取消回复