阐述、总结【动手学强化学习】章节内容的学习情况,复现并理解代码。
文章目录
一、算法背景
1.1目标
给定“黑盒”环境,求解最优policy
1.2问题
蒙特卡罗方法(Monte Carlo,MC)估计中,对于每一个q(s,a)的估计需要采样N个episode才能进行,时间效率低。
采用greedy策略,可能会在与环境交互过程中,导致某些(s,a)状态动作对永远没有在episode中出现。
1.3解决方法
-
时序差分(Temporal Difference, TD)
MC估计的核心思想
E [ X ] ≈ x ˉ : = 1 N ∑ i = 1 N x i . \mathbb{E}[X]\approx\bar{x}:=\frac1N\sum_{i=1}^Nx_i. E[X]≈xˉ:=N1i=1∑Nxi.
令
w k + 1 = 1 k ∑ i = 1 k x i , k = 1 , 2 , … w_{k+1}=\frac{1}{k}\sum_{i=1}^{k}x_{i},\quad k=1,2,\ldots wk+1=k1i=1∑kxi,k=1,2,…
则可推导出:
w k + 1 = w k − 1 k ( w k − x k ) . w_{k+1}=w_k-\frac{1}{k}(w_k-x_k). wk+1=wk−k1(wk−xk).
同理,action value的定义式也为期望,那么则有:
q k + 1 = q k − 1 k ( q k − G k ) . q_{k+1}=q_k-\frac{1}{k}(q_k-G_k). qk+1=qk−k1(qk−Gk).
按定义而言 G k G_k Gk 为从(s,a)出发第k次采样episode的累计奖励值。因此基于上述推导,可以采取“增量式”的思想去估计q(s,a),不必再像MC算法中需等待N个episode都采样完再估计q(s,a)值,边采样就能边估计:
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha[r_t+\gamma Q(s_{t+1},a_{t+1})-Q(s_t,a_t)] Q(st,at)←Q(st,at)+α[rt+γQ(st+1,at+1)−Q(st,at)]
(这块的数学转换还有点没梳理清楚) -
额外说明:
① TD error的定义:
r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) r_t+\gamma Q(s_{t+1},a_{t+1})-Q(s_t,a_t) rt+γQ(st+1,at+1)−Q(st,at)
② TD_target的定义:
r t + γ Q ( s t + 1 , a t + 1 ) r_t+\gamma Q(s_{t+1},a_{t+1}) rt+γQ(st+1,at+1)
TD error中,两项因子是在两个时刻,这也是为什么被称作为“时序差分”的原因
TD的算法思路就是,让 Q ( s t , a t ) Q(s_t,a_t) Q(st,at)在不断更新的过程中不断向TD_target靠近。
③ 学习率α:
将1/k近似替换为α,α的大小影响每一步(算法内称之为step)的逼近TD_target的“步幅”,“步幅”越大,逼近速率越快,但过大可能导致无法收敛,但过小可能导致时间成本高,过犹不及,属于需调参的参数之一。 -
ε-greedy策略
π
(
a
∣
s
)
=
{
ϵ
/
∣
A
∣
+
1
−
ϵ
如果
a
=
arg
max
a
′
Q
(
s
,
a
′
)
ϵ
/
∣
A
∣
其他动作
\pi(a|s)=\begin{cases}\epsilon/|\mathcal{A}|+1-\epsilon&\quad\text{如果}a=\arg\max_{a^{\prime}}Q(s,a^{\prime})\\\epsilon/|\mathcal{A}|&\quad\text{其他动作}\end{cases}
π(a∣s)={ϵ/∣A∣+1−ϵϵ/∣A∣如果a=argmaxa′Q(s,a′)其他动作
有 1-ε的概率采用动作价值最大的那个动作,另外有 ε的概率从动作空间中随机采取一个动作。
二、SARSA算法
2.1伪代码

-
必要说明
(1)step:指的是agent基于当前policy采取action后,再与环境交互一次从而得到(s,a,r,s’)的过程。(s’为next_state)
(2)episode:指的是agent基于当前policy不断与环境进行交互,执行多步step后,达到terminal/goal state(或有其它终止条件,如限制episode长度)后,得到的(s,a,r,s’)链。有时候,将基于policy和s’采取的a’(next_action)也写在一起组成(s,a,r,s’,a’)五元组,这也是SARSA算法名称的由来。
(3)Q_table:用于存放各q(s,a)值的表格。 -
算法流程简述
从算法流程上来看,大体分为update q-value和update policy两步,其实还是可以理解为“基于PE(policy evaluation)和PI(policy improvement)”的框架。
①初始化:初始化state、ε-greedy policy与Q_table。
②价值更新(≈PE):设定episode周期数=n,开始循环,基于当前state与ε-greedy policy获取action,执行step,获取(s,a,r,s’),再基于s‘与ε-greedy policy获取a’,得到(s,a,r,s’,a’),基于TD更新q(s,a)值同步至Q_table。
③策略更新(≈PI):基于Q_table更新ε-greedy policy。
④终止判断:判断是否已产生n个episode,若是则退出循环输出policy;若否则继续②~③步。
2.2算法代码
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm # tqdm是显示循环进度条的库
class CliffWalkingEnv:
def __init__(self, ncol, nrow):
self.nrow = nrow
self.ncol = ncol
self.x = 0 # 记录当前智能体位置的横坐标
self.y = self.nrow - 1 # 记录当前智能体位置的纵坐标
def step(self, action): # 外部调用这个函数来改变当前位置
# 4种动作, change[0]:上, change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)
# =============================================================================
# 起点定义在左下角
# 将奖励定义为,每走一步,奖励-1,若走到cliff state奖励为-100,
# 走到cliff或者goal都为terminal state,都将更新done
# =============================================================================
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
self.x = min(self.ncol - 1, max(0, self.x + change[action][0]))
self.y = min(self.nrow - 1, max(0, self.y + change[action][1]))
next_state = self.y * self.ncol + self.x
reward = -1
done = False
if self.y == self.nrow - 1 and self.x > 0: # 下一个位置在悬崖或者目标
done = True
if self.x != self.ncol - 1:
reward = -100
return next_state, reward, done
def reset(self): # 回归初始状态,坐标轴原点在左上角
self.x = 0
self.y = self.nrow - 1
return self.y * self.ncol + self.x
class Sarsa:
""" Sarsa算法 """
def __init__(self, ncol, nrow, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros([nrow * ncol, n_action]) # 初始化Q(s,a)表格
self.n_action = n_action # 动作个数
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略中的参数
def take_action(self, state): # 选取下一步的操作,具体实现为epsilon-greedy
# 根据ε判断选择哪个action
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state): # 用于打印策略
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action): # 若两个动作的价值一样,都会记录下来
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1, a1):
td_error = r + self.gamma * self.Q_table[s1, a1] - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
ncol = 12
nrow = 4
env = CliffWalkingEnv(ncol, nrow)
np.random.seed(0)
'''如果你在代码中使用 np.random.seed(0) 并随后调用 np.random.rand() 生成随机数,
那么无论何时执行这段代码,只要种子值不变,生成的随机数序列都将完全相同。
这是因为在内部,随机数生成器会根据所提供的种子值计算出一个确定的起始点,从而产生相同的序列。'''
epsilon = 0.1
alpha = 0.1
gamma = 0.9
agent = Sarsa(ncol, nrow, epsilon, alpha, gamma)
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
for i in range(10): # 显示10个进度条
# tqdm的进度条功能
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数
episode_return = 0
state = env.reset()
action = agent.take_action(state) #根据ε-greedy policy与Q_table选取s的a
done = False
while not done:
next_state, reward, done = env.step(action) #根据s,a计算r与s'
next_action = agent.take_action(next_state) #根据ε-greedy policy与Q_table选取s'的a',由于a'的选取也是依据Q_table的,因此这个算法是on-policy的
episode_return += reward # 这里回报的计算不进行折扣因子衰减
agent.update(state, action, reward, next_state, next_action) #采用TD方法更新Q_table
state = next_state
action = next_action
return_list.append(episode_return) #即时奖励的累加,只是为了显示训练过程的奖励结果变化情况,不用于训练
if (i_episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Sarsa on {}'.format('Cliff Walking'))
plt.show()
def print_agent(agent, env, action_meaning, disaster=[], end=[]):
for i in range(env.nrow):
for j in range(env.ncol):
if (i * env.ncol + j) in disaster:
print('****', end=' ')
elif (i * env.ncol + j) in end:
print('EEEE', end=' ')
else:
a = agent.best_action(i * env.ncol + j)
pi_str = ''
for k in range(len(action_meaning)):
pi_str += action_meaning[k] if a[k] > 0 else 'o'
print(pi_str, end=' ')
print()
action_meaning = ['^', 'v', '<', '>']
print('Sarsa算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
2.3运行结果
Iteration 0: 100%|██████████| 50/50 [00:00<00:00, 1182.92it/s, episode=50, return=-119.400]
Iteration 1: 100%|██████████| 50/50 [00:00<00:00, 1597.70it/s, episode=100, return=-63.000]
Iteration 2: 100%|██████████| 50/50 [00:00<00:00, 1600.11it/s, episode=150, return=-51.200]
Iteration 3: 100%|██████████| 50/50 [00:00<00:00, 3199.56it/s, episode=200, return=-48.100]
Iteration 4: 100%|██████████| 50/50 [00:00<00:00, 1600.02it/s, episode=250, return=-35.700]
Iteration 5: 100%|██████████| 50/50 [00:00<00:00, 3542.31it/s, episode=300, return=-29.900]
Iteration 6: 100%|██████████| 50/50 [00:00<00:00, 3224.16it/s, episode=350, return=-28.300]
Iteration 7: 100%|██████████| 50/50 [00:00<00:00, 3198.34it/s, episode=400, return=-27.700]
Iteration 8: 100%|██████████| 50/50 [00:00<00:00, 2412.60it/s, episode=450, return=-28.500]
Iteration 9: 100%|██████████| 50/50 [00:00<00:00, 9523.85it/s, episode=500, return=-18.900]
Sarsa算法最终收敛得到的策略为:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo ooo> ^ooo ooo> ooo> ooo> ooo> ^ooo ^ooo ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
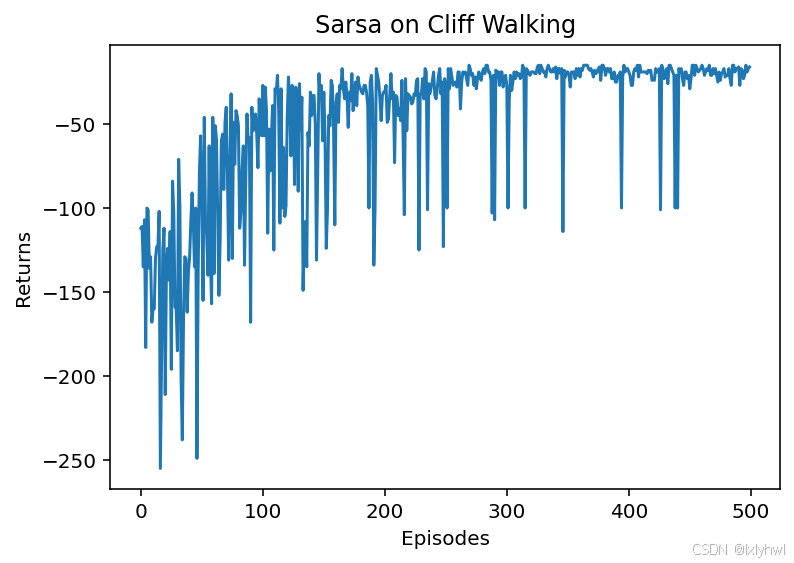
- 说明:
这里的return是episode每一个step的即时奖励的简单累加,并没有乘上折扣率γ。
episode_return += reward
...
return_list.append(episode_return)
2.4算法流程解释
创建环境+设置状态空间
ncol = 12
nrow = 4
env = CliffWalkingEnv(ncol, nrow)
...
self.x = 0 # 记录当前智能体位置的横坐标
self.y = self.nrow - 1 # 记录当前智能体位置的纵坐标
创建CliffWalkingEnv环境,状态空间为4x12,即48个state,并将初始state设置为4行1列
设置动作空间+奖励
def step(self, action): # 外部调用这个函数来改变当前位置
# 4种动作, change[0]:上, change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)
# =============================================================================
# 起点定义在左下角
# 将奖励定义为,每走一步,奖励-1,若走到cliff state奖励为-100,
# 走到cliff或者goal都为terminal state,都将更新done
# =============================================================================
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
self.x = min(self.ncol - 1, max(0, self.x + change[action][0]))
self.y = min(self.nrow - 1, max(0, self.y + change[action][1]))
next_state = self.y * self.ncol + self.x
reward = -1
done = False
if self.y == self.nrow - 1 and self.x > 0: # 下一个位置在悬崖或者目标
done = True
if self.x != self.ncol - 1:
reward = -100
return next_state, reward, done
step函数中将action空间设置为4,即总共有48x4=192个(s,a)对,Q_table的大小即为192;
奖励设置为“走入悬崖-100,每走一步-1”,cliff state和goal state都为terminal state,即done设置为true,以表示一个episode的探索(多步step)结束。
参数设置
epsilon = 0.1
alpha = 0.1
gamma = 0.9
ε-greedy中ε=0.1;学习率;折扣率。
采样episode
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
for i in range(10): # 显示10个进度条
# tqdm的进度条功能
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数
episode_return = 0
state = env.reset()
action = agent.take_action(state) #根据ε-greedy policy与Q_table选取s的a
done = False
while not done:
next_state, reward, done = env.step(action) #根据s,a计算r与s'
next_action = agent.take_action(next_state) #根据ε-greedy policy与Q_table选取s'的a',由于a'的选取也是依据Q_table的,因此这个算法是on-policy的
episode_return += reward # 这里回报的计算不进行折扣因子衰减
agent.update(state, action, reward, next_state, next_action) #采用TD方法更新Q_table
state = next_state
action = next_action
return_list.append(episode_return) #即时奖励的累加,只是为了显示训练过程的奖励结果变化情况,不用于训练
算法核心代码:设置episode周期数=500,依据算法流程跑完500个episode后输出policy。
价值更新
agent.update(state, action, reward, next_state, next_action) #采用TD方法更新Q_table
...
def update(self, s0, a0, r, s1, a1):
td_error = r + self.gamma * self.Q_table[s1, a1] - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
step和take action得到(s,a,r,s’,a’)五元组后,通过TD方法更新q(s,a)
策略更新
def take_action(self, state): # 选取下一步的操作,具体实现为epsilon-greedy
# 根据ε判断选择哪个action
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
没有显式更新policy的步骤,因为SARSA中是基于ε和Q_table去选取action的。
三、Q-learning算法
- 说明
policy作为算法优化的目标,在算法执行过程中有两处会涉及到policy:
①采样:在episode采样过程中,基于state去take action将使用policy
②更新:基于argmax(q(s,a))去更新policy。
因此衍生出两种学习策略:
①on-policy(在线策略学习):采样和更新使用同一个policy,使用在当前策略下采样得到的样本进行学习,一旦策略被更新,当前的样本就被放弃了。
②off-policy(离线策略学习):使用经验回放池将之前采样得到的样本收集起来再次利用。因此有两个policy,behavior policy与target policy不一致,behavior policy不断与环境进行交互得到大量experience,用这些experience不断改进另一个target policy以至最优。
(因此SARSA算法是on-policy的)
3.1伪代码
on-policy版本
算法流程上与SARSA无异,就是将TD target改为了
r
t
+
γ
m
a
x
a
(
Q
(
s
t
+
1
,
a
t
+
1
)
)
r_t+\gamma max_a(Q(s_{t+1},a_{t+1}))
rt+γmaxa(Q(st+1,at+1))

off-policy版本
算法流程上依旧还是“价值更新+策略更新”。
只是采样episode的policy为
π
b
\pi_b
πb,被更新的policy为
π
T
\pi_T
πT。
因此,behavior policy可以尽可能地增加“探索性”,如每个动作的概率都相等;target policy由于与采样episode无关,可以尽可能地专注于“最优性”,即采用greedy policy。

3.2算法代码
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm # tqdm是显示循环进度条的库
class CliffWalkingEnv:
def __init__(self, ncol, nrow):
self.nrow = nrow
self.ncol = ncol
self.x = 0 # 记录当前智能体位置的横坐标
self.y = self.nrow - 1 # 记录当前智能体位置的纵坐标
def step(self, action): # 外部调用这个函数来改变当前位置
# 4种动作, change[0]:上, change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)
# =============================================================================
# 起点定义在左下角
# 将奖励定义为,每走一步,奖励-1,若走到cliff state奖励为-100,
# 走到cliff或者goal都为terminal state,都将更新done
# =============================================================================
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
self.x = min(self.ncol - 1, max(0, self.x + change[action][0]))
self.y = min(self.nrow - 1, max(0, self.y + change[action][1]))
next_state = self.y * self.ncol + self.x
reward = -1
done = False
if self.y == self.nrow - 1 and self.x > 0: # 下一个位置在悬崖或者目标
done = True
if self.x != self.ncol - 1:
reward = -100
return next_state, reward, done
def reset(self): # 回归初始状态,坐标轴原点在左上角
self.x = 0
self.y = self.nrow - 1
return self.y * self.ncol + self.x
class QLearning:
""" Q-learning算法 """
def __init__(self, ncol, nrow, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros([nrow * ncol, n_action]) # 初始化Q(s,a)表格
self.n_action = n_action # 动作个数
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略中的参数
def take_action(self, state): #选取下一步的操作
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state): # 用于打印策略
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action):
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1):
#Q(s,a)的更新中,TD target采用s'下的max Q(s',a)
td_error = r + self.gamma * self.Q_table[s1].max(
) - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
ncol = 12
nrow = 4
env = CliffWalkingEnv(ncol, nrow)
np.random.seed(0)
epsilon = 0.1
alpha = 0.1
gamma = 0.9
agent = QLearning(ncol, nrow, epsilon, alpha, gamma)
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
for i in range(10): # 显示10个进度条
# tqdm的进度条功能
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done = env.step(action)
episode_return += reward # 这里回报的计算不进行折扣因子衰减
agent.update(state, action, reward, next_state) #与SARSA的不同就体现在Q_table的更新上
state = next_state
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Q-learning on {}'.format('Cliff Walking'))
plt.show()
def print_agent(agent, env, action_meaning, disaster=[], end=[]):
for i in range(env.nrow):
for j in range(env.ncol):
if (i * env.ncol + j) in disaster:
print('****', end=' ')
elif (i * env.ncol + j) in end:
print('EEEE', end=' ')
else:
a = agent.best_action(i * env.ncol + j)
pi_str = ''
for k in range(len(action_meaning)):
pi_str += action_meaning[k] if a[k] > 0 else 'o'
print(pi_str, end=' ')
print()
action_meaning = ['^', 'v', '<', '>']
print('Q-learning算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
3.3运行结果
Iteration 0: 100%|██████████| 50/50 [00:00<00:00, 996.24it/s, episode=50, return=-105.700]
Iteration 1: 100%|██████████| 50/50 [00:00<00:00, 819.00it/s, episode=100, return=-70.900]
Iteration 2: 100%|██████████| 50/50 [00:00<00:00, 1591.34it/s, episode=150, return=-56.500]
Iteration 3: 100%|██████████| 50/50 [00:00<00:00, 1597.78it/s, episode=200, return=-46.500]
Iteration 4: 100%|██████████| 50/50 [00:00<00:00, 3172.02it/s, episode=250, return=-40.800]
Iteration 5: 100%|██████████| 50/50 [00:00<00:00, 2933.94it/s, episode=300, return=-20.400]
Iteration 6: 100%|██████████| 50/50 [00:00<00:00, 3331.46it/s, episode=350, return=-45.700]
Iteration 7: 100%|██████████| 50/50 [00:00<00:00, 2685.52it/s, episode=400, return=-32.800]
Iteration 8: 100%|██████████| 50/50 [00:00<00:00, 5252.99it/s, episode=450, return=-22.700]
Iteration 9: 100%|██████████| 50/50 [00:00<00:00, 3046.15it/s, episode=500, return=-61.700]
Q-learning算法最终收敛得到的策略为:
^ooo ovoo ovoo ^ooo ^ooo ovoo ooo> ^ooo ^ooo ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ^ooo ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
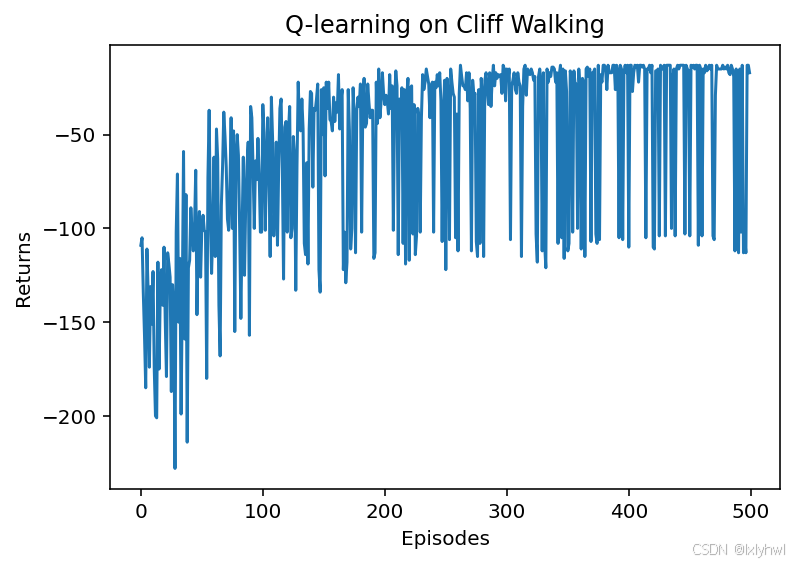
- 对比分析
(1)说明:这里的return是每个episode即时奖励的简单累加,并不是训练过程更行q(s,a)的折扣奖励,因此在不断与环境交互过程中return有波动是正常的。
(2)最终policy对比:Q-learning算法的policy更偏向于走在悬崖边上,这与 Sarsa 算法得到的比较保守的策略相比是更优的。
(3)收敛速度对比:Q-learning算法在“episode=300, return=-20.400”,而SARSA算法在“episode=450, return=-28.500”,Q-learning算法在收敛速度上有明显优势。
3.4算法流程解释
- 这里给出的q-laerning算法还是on-policy的,因此仅仅只是在“价值更新”步骤有区别。
价值更新
def update(self, s0, a0, r, s1):
#Q(s,a)的更新中,TD target采用s'下的max Q(s',a)
td_error = r + self.gamma * self.Q_table[s1].max(
) - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
TD target转换为了
r
t
+
γ
m
a
x
a
(
Q
(
s
t
+
1
,
a
t
+
1
)
)
r_t+\gamma max_a(Q(s_{t+1},a_{t+1}))
rt+γmaxa(Q(st+1,at+1))
总结
- MC和TD算法都是“黑盒”模型下的model-free算法,但TD算法应用了incremental(“增量式”)的思想去估计action value,等待成本更低,边更新q(s,a)估计值边更新policy。
- 强化学习中,“模型”和“数据”必有其一,不然无法求解。
- off policy相对于on policy的优势在于,采样数据可以充分利用,具有更小的样本复杂度,target policy是deterministic policy
- Q-laerning算法相对于SARSA算法在解的最优性和收敛速度上有明显优势。
(off-policy还是得与环境进行交互才能更新policy,而离线强化学习直接是基于样本集(数据)来直接训练policy,注意区别)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【动手学强化学习】part4-时序差分算法

发表评论 取消回复