文章目录
1、理论基础
在计算机科学领域,分布式一致性是一个相当重要的问题。
分布式系统要解决的一个重要问题是数据复制。
数据复制为分布式系统带来了高可用、高性能,但也同时带来了分布式一致性挑战:在对一个副本数据进行更新时,必须确保也更新其他副本,否则不同副本的数据将不一致。
如何解决这个问题 ?
一种思路是:阻塞 “写” 操作,直到数据复制完成。
但这个思路在解决一致性问题的同时,又带来了 “写” 操作性能低的问题。
如果有高并发的 “写” 请求,则在使用这个思路之后,大量 “写” 请求阻塞,导致系统整体性能急剧下降。
如何既保证数据的一致性,又不影响系统运行的性能,是每一个分布式系统都需要重点考虑和权衡的问题。
如何实现一种既能保证ACID特性,又能保证高性能的分布式事务处理系统是一个世界性难题。
在技术演进过程中,出现了诸如CAP和BASE 这样的分布式系统理论。
2、CAP定理
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标。
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)
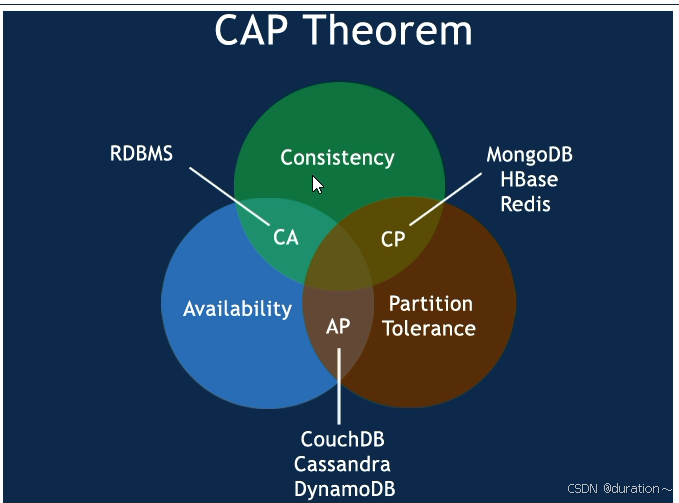
它们的第一个字母分别是 C、A、P。
Eric Brewer 说,这三个指标不可能同时做到,这个结论就叫做 CAP 定理。
CAP定理是分布式系统的指导理论,它指出:一个分布式系统不可能同时满足 一致性(C: Consistency)、可用性(A: Availability) 和 分区容错性(P: PartitionTolerance) 这3个需求,最多只能同时满足其中两项。
1_一致性
Consistency (一致性):指 "all nodes see the same data at the same time",即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致,这就是分布式的一致性。
一致性的问题在并发系统中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的问题。
从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
这里的一致性是指强一致性,一般关系型数据库就具有强-致性特性。
2_可用性
Availability (可用性):指 "Reads and writes always succeed",即服务一直可用,而且是正常响应时间。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
3_分区容错性
Partition Tolerance (分区容错性):指 "the system continues to operate despite arbitrary message loss or failure of part of the system",即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。
比如现在的分布式系统中有某一个或者几个机器宕掉或失联了,其他剩下的机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
因为分布式系统无法同时满足一致性、可用性、分区容错性这3个基本需求,所以我们在设计分布式系统时就必须有所取舍。
对于分布式系统而言,分区容错性是最基本的要求,因为既然是一个分布式系统,那么分布式系统中的组件必然会被部署到不同的节点,否则也就无所谓分布式系统了,因此必然会出现子网络。
而对于分布式系统而言,网络又必定会出现异常情况因此,分区容错性就成为了分布式系统必然需要面对和解决的问题。
4_总结
在分布式系统中,系统间的网络不能100%保证健康,一定会有故障的时候,而服务有必须对外保证服务。因此Partition Tolerance 不可避免。
当节点接收到新的数据变更时,就会出现问题了:
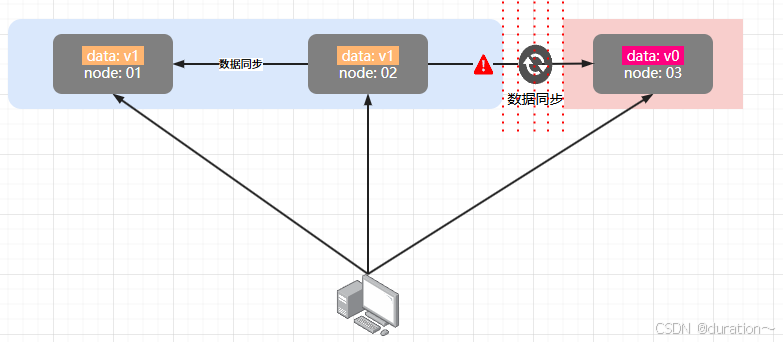
如果此时要保证一致性,就必须等待网络恢复,完成数据同步后,整个集群才对外提供服务,服务处于阻塞状态,不可用。
如果此时要保证可用性,就不能等待网络恢复,那 node01、node02 与 node03 之间就会出现数据不一致。
也就是说,在P一定会出现的情况下,A和C之间只能实现一个。
CP without A,即实现一致性和分区容错性。
-
此组合为数据强一致性模式,即要求在多服务之间数据一定要一致,弱化了可用性。
-
一些对数据要求比较高的场景(比如金融业务等)使用此模式,这种模式性能偏低。
-
常用方案有 XA 两阶段提交、Seata AT 模式的“读已提交”级别等。
AP without C,即实现可用性和分区容错性。
-
此组合为数据最终一致性模式,即要求所有服务都可用,弱化了一致性。
-
互联网分布式服务多数基于AP,这种模式性能高,可以满足高并发的业务需求。
-
常用方案有TCC、基于消息的最终一致性、Saga等。
CA without P,即实现一致性和可用性:
-
如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。
-
但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
系统架构师往往需要把精力花在如何根据业务特点在 C(一致性) 和 A(可用性) 之间做选择,即选择 CP 还是 AP。
3、BASE理论
BASE是 Basically Available(基本可用)、Soft State(软状态) 和 EventuallyConsistency(最终一致性) 这3个短语的缩写。
BASE理论是对CAP中的一致性及可用性进行权衡的结果,其核心思想是:无法做到强一致性,那么可以通过牺牲强一致性来获得可用性。
BASE理论是对CAP的一种解决思路,包含三个思想:
1_Basically Available(基本可用)
基本可用是对 A(可用性) 的一个妥协,即在分布式系统出现不可预知故障时,允许损失部分可用性。比如在秒杀场景和雪崩的业务场景下进行降级处理,使核心功能可用,而不是所有的功能可用。
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
2_Soft State(软状态)
软状态是相对于原子性而言的。
要求多个节点的数据副本是一致的,这是一种“硬状态”。
“软状态” 指的是:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本上存在数据延时。
在一定时间内,允许出现中间状态,比如临时的不一致状态。
3_Eventually Consistent(最终一致性)
不可能一直是 “软状态” ,必须有个时间期限。
在时间期限过后,应当保证所有副本保持数据一致性,从而达到数据的最终一致性。
这个时间期限取决于网络延时、系统负载、数据复制方案设计等因素。
虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
不只是分布式系统使用最终一致性,关系型数据库在某个功能上也使用最终一致性。
比如在备份时,数据库的复制过程是需要时间的,在这个复制过程中,业务读取的值就是“旧”的。
当然,最终还是达到了数据一致性。
4_总结
总体来说,BASE 理论面向的是大型高可用、可扩展的分布式系统。
不同于 ACID,BASE 理论提出通过牺牲强一致性来获得可用性,并允许在一定时间内的不一致,但是最终达到一致。
在实际的分布式场景中,不同业务对数据的一致性要求不一样。因此在设计时,往往结合使用 ACID 和 BASE 理论。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 分布式理论基础

发表评论 取消回复