阐述、总结【动手学强化学习】章节内容的学习情况,复现并理解代码。
文章目录
一、什么是动态规划?
1.1概念
**动态规划(dynamic programming)**是程序设计算法中非常重要的内容,能够高效解决一些经典问题,例如背包问题和最短路径规划。动态规划的基本思想是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。动态规划会保存已解决的子问题的答案,在求解目标问题的过程中,需要这些子问题答案时就可以直接利用,避免重复计算。
基于动态规划的强化学习算法主要有两种:一是策略迭代(policy iteration),二是价值迭代(value iteration)。
1.2适用条件
需要“白盒”环境(model-based)!!!基于动态规划的这两种强化学习算法要求事先知道环境的状态转移函数和奖励函数,也就是需要知道整个马尔可夫决策过程。策略迭代和价值迭代通常只适用于有限马尔可夫决策过程,即状态空间和动作空间是离散且有限的。
二、算法示例
2.1问题建模
CliffWalking悬崖漫步环境
- 目标:要求一个智能体从起点出发,避开悬崖行走,最终到达目标位置。
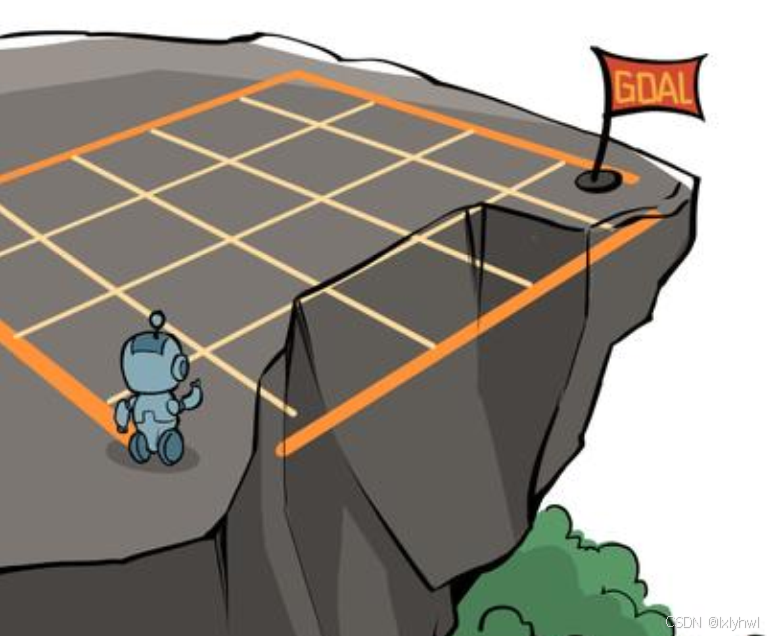
根据MDP过程进行建模:
- 状态空间:4×12 的网格世界,每一个网格表示一个状态。起点是左下角的状态,目标是右下角的状态。
- 动作空间:可以采取 4 种动作:上、下、左、右。
- 折扣因子:取0.9。
- 奖励函数:智能体采取动作后触碰到边界墙壁则状态不发生改变,否则就会相应到达下一个状态。环境中有一段悬崖,智能体掉入悬崖或
到达目标状态都会结束动作并回到起点,也就是说掉入悬崖或者达到目标状态是终止状态。智能体每走一步的奖励是 −1,掉入悬崖的奖励是−100。 - 状态转移函数:
2.2策略迭代(policyiteration)算法
2.2.1伪代码

- 算法流程简述:
①初始化:根据环境,初始化各state的state value,一般设置为0;policy同时也初始化,一般设置为每个state选取各action的概率相等
②价值评估(policy evaluation,PE):循环迭代计算,毕竟当前policy下稳态state value
③策略提升(policy improvement):依据当前statevalue值,根据环境模型( p ( r ∣ s , a ) p(r|s,a) p(r∣s,a)、 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a))计算各(s,a)对action value,并以greedy policy策略将各state中action value最大的值进行policy优化
④终止判断:判断最近两次policy是否相等,若是则停止算法输出policy,若否则重复执行②③步。
2.2.2完整代码
# =============================================================================
#
# 悬崖漫步是一个非常经典的强化学习环境,它要求一个智能体从起点出发,避开悬崖行走,最终到达目标位置。
# state:如图 4-1 所示,有一个 4×12 的网格世界,每一个网格表示一个状态,智能体的起点是左下角的状态,目标是右下角的状态.
# action:智能体在每一个状态都可以采取 4 种动作:上、下、左、右。
# goal:如果智能体采取动作后触碰到边界墙壁则状态不发生改变,否则就会相应到达下一个状态。环境中有一段悬崖,智能体掉入悬崖或
# 到达目标状态都会结束动作并回到起点,也就是说掉入悬崖或者达到目标状态是终止状态。
# reward:智能体每走一步的奖励是 −1,掉入悬崖的奖励是−100。
# =============================================================================
import copy
class CliffWalkingEnv:
""" 悬崖漫步环境"""
def __init__(self, ncol=12, nrow=4):
self.ncol = ncol # 定义网格世界的列
self.nrow = nrow # 定义网格世界的行
# 转移矩阵P[state][action] = [(p, next_state, reward, done)]包含下一个状态和奖励
self.P = self.createP()
def createP(self):
# =============================================================================
# 转移矩阵P[s][a] = [(p, next_state, reward, done)]包含下一个状态和奖励
# p:s到next_state的状态转移概率,在这里都取1
# reward:s到next_state的即时奖励
# done:是否到达终点或悬崖
# =============================================================================
# 初始化
P = [[[] for j in range(4)] for i in range(self.nrow * self.ncol)]
# 4种动作, change[0]:上,change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)
# 定义在左上角
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
for i in range(self.nrow):
for j in range(self.ncol):
for a in range(4):
# 位置在悬崖或者目标状态,因为无法继续交互,任何动作奖励都为0
if i == self.nrow - 1 and j > 0:
# 除了4行1列的元素的done状态都设置为True,其都为悬崖,除4行12列为终点
P[i * self.ncol + j][a] = [(1, i * self.ncol + j, 0,
True)]
continue
# 其他位置
next_x = min(self.ncol - 1, max(0, j + change[a][0]))
next_y = min(self.nrow - 1, max(0, i + change[a][1]))
next_state = next_y * self.ncol + next_x
reward = -1
done = False
# 下一个位置在悬崖或者终点
if next_y == self.nrow - 1 and next_x > 0:
done = True
if next_x != self.ncol - 1: # 下一个位置在悬崖
reward = -100
P[i * self.ncol + j][a] = [(1, next_state, reward, done)]
return P
class PolicyIteration:
""" 策略迭代算法 """
def __init__(self, env, theta, gamma):
self.env = env
self.v = [0] * self.env.ncol * self.env.nrow # 初始化价值为0
#初始策略是均匀分布的
self.pi = [[0.25, 0.25, 0.25, 0.25]
for i in range(self.env.ncol * self.env.nrow)] # 初始化为均匀随机策略
self.theta = theta # 策略评估收敛阈值
self.gamma = gamma # 折扣因子
def policy_evaluation(self): # 策略评估
cnt = 1 # 计数器
while 1:
max_diff = 0
new_v = [0] * self.env.ncol * self.env.nrow
for s in range(self.env.ncol * self.env.nrow):
qsa_list = [] # 开始计算状态s下的所有Q(s,a)价值。4x12各state,4个action
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
# 这里在计算action value
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
# 本章环境比较特殊,奖励和下一个状态有关,所以需要和状态转移概率相乘
qsa_list.append(self.pi[s][a] * qsa)
# 这里更新state value
new_v[s] = sum(qsa_list) # 状态价值函数和动作价值函数之间的关系
max_diff = max(max_diff, abs(new_v[s] - self.v[s])) #这里判断阈值是否继续进行迭代
self.v = new_v
if max_diff < self.theta: break # 满足收敛条件,退出评估迭代
cnt += 1
print("策略评估进行%d轮后完成" % cnt)
def policy_improvement(self): # 策略提升
for s in range(self.env.nrow * self.env.ncol):
qsa_list = []
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(qsa)
maxq = max(qsa_list) #选取当前state下maxQ(s,a)
cntq = qsa_list.count(maxq) # 计算有几个动作得到了最大的Q值
# 让这些动作均分概率,考虑到了最大qsa可能存在多个的情况
self.pi[s] = [1 / cntq if q == maxq else 0 for q in qsa_list]
print("策略提升完成")
return self.pi
def policy_iteration(self): # 策略迭代
while 1:
self.policy_evaluation()
old_pi = copy.deepcopy(self.pi) # 将列表进行深拷贝,方便接下来进行比较
new_pi = self.policy_improvement()
print_agent(agent, action_meaning, list(range(37, 47)), [47])
if old_pi == new_pi: break
def print_agent(agent, action_meaning, disaster=[], end=[]):
print("状态价值:")
for i in range(agent.env.nrow):
for j in range(agent.env.ncol):
# 为了输出美观,保持输出6个字符
print('%6.6s' % ('%.3f' % agent.v[i * agent.env.ncol + j]), end=' ')
print()
print("策略:")
for i in range(agent.env.nrow):
for j in range(agent.env.ncol):
# 一些特殊的状态,例如悬崖漫步中的悬崖
if (i * agent.env.ncol + j) in disaster:
print('****', end=' ')
elif (i * agent.env.ncol + j) in end: # 目标状态
print('EEEE', end=' ')
else:
a = agent.pi[i * agent.env.ncol + j]
pi_str = ''
for k in range(len(action_meaning)):
pi_str += action_meaning[k] if a[k] > 0 else 'o' #action存在概率就打印
print(pi_str, end=' ')
print()
env = CliffWalkingEnv()
action_meaning = ['^', 'v', '<', '>']
theta = 0.001 #policy iteration的迭代终止的阈值判断
gamma = 0.9
agent = PolicyIteration(env, theta, gamma)
agent.policy_iteration()
# print_agent(agent, action_meaning, list(range(37, 47)), [47])
2.2.3运行结果
策略评估进行60轮后完成
策略提升完成
状态价值:
-27.23 -28.51 -29.62 -30.30 -30.63 -30.71 -30.57 -30.14 -29.22 -27.47 -24.65 -21.45
-33.63 -36.89 -38.79 -39.68 -40.04 -40.13 -40.01 -39.59 -38.59 -36.33 -31.53 -23.34
-47.27 -58.58 -61.78 -62.77 -63.10 -63.17 -63.09 -62.79 -61.93 -59.42 -51.38 -22.98
-66.15 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
^o<o oo<o oo<o oo<o oo ooo> ooo> ooo> ooo> ooo> ^oo>
^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ooo> ^ooo
^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
策略评估进行72轮后完成
策略提升完成
状态价值:
-10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00
-10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00
-10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -1.900 -1.000
-10.00 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
^v<> ^v<> ^v<> ^v<> ooo> ^vo> ^v<> ^v<> ^v<> ^v<> ^v<> ^v<>
^v<> ^v<> ^v<> ^v<> ooo> ^vo> ^v<> ^v<> ^v<> ^v<> ovoo ovoo
^v<> ^o<> ^o<> ^o<> ooo> ^oo> ^o<> ^o<> ^o<> ooo> ooo> ovoo
^v<o **** **** **** **** **** **** **** **** **** **** EEEE
策略评估进行44轮后完成
策略提升完成
状态价值:
-9.934 -9.902 -9.826 -9.678 -9.405 -9.338 -9.168 -8.718 -7.913 -6.729 -5.429 -4.817
-9.934 -9.898 -9.816 -9.657 -9.357 -9.285 -9.075 -8.499 -7.363 -5.390 -2.710 -1.900
-9.937 -9.891 -9.800 -9.622 -9.280 -9.200 -8.935 -8.173 -6.474 -2.710 -1.900 -1.000
-9.954 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo ovoo ovoo
ooo> ooo> ooo> ooo> ovoo ooo> ooo> ooo> ooo> ovo> ovo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
策略评估进行12轮后完成
策略提升完成
状态价值:
-7.712 -7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710
-7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900
-7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900 -1.000
-7.458 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
策略评估进行1轮后完成
策略提升完成
状态价值:
-7.712 -7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710
-7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900
-7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900 -1.000
-7.458 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
2.2.4代码流程概述
(1)创建环境
env = CliffWalkingEnv()
设置环境行列数,以及设置环境奖励及状态转移概率,都存存储在P(3维list[48,1,4])中,其中最小元组代表(s,a)对的信息(P[s][a] = [(p, next_state, reward, done)]),即状态转移概率、下一状态、即时奖励、是否完成标志(掉入悬崖或走至终点都视为“完成”)。
(2)设置参数
theta = 0.001 #policy iteration的迭代终止的阈值判断
gamma = 0.9
theta为PE过程停止的阈值判断,即“if max_diff < self.theta: break”,gamma 为奖励折扣率。
(3)价值评估(PE)
def policy_evaluation(self): # 策略评估
cnt = 1 # 计数器
while 1:
max_diff = 0
new_v = [0] * self.env.ncol * self.env.nrow
for s in range(self.env.ncol * self.env.nrow):
qsa_list = [] # 开始计算状态s下的所有Q(s,a)价值。4x12各state,4个action
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
# 这里在计算action value
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
# 本章环境比较特殊,奖励和下一个状态有关,所以需要和状态转移概率相乘
qsa_list.append(self.pi[s][a] * qsa)
# 这里更新state value
new_v[s] = sum(qsa_list) # 状态价值函数和动作价值函数之间的关系
max_diff = max(max_diff, abs(new_v[s] - self.v[s])) #这里判断阈值是否继续进行迭代
self.v = new_v
if max_diff < self.theta: break # 满足收敛条件,退出评估迭代
cnt += 1
print("策略评估进行%d轮后完成" % cnt)
①遍历所有(s,a),计算q(s,a),再累加得到v(s)=Σq(s,a)
v
π
k
(
j
+
1
)
(
s
)
=
∑
a
π
k
(
a
∣
s
)
[
∑
r
p
(
r
∣
s
,
a
)
r
+
γ
∑
s
′
p
(
s
′
∣
s
,
a
)
v
π
k
(
j
)
(
s
′
)
]
v_{\pi_{k}}^{(j+1)}(s)=\sum_{a}\pi_{k}(a|s)\left[\sum_{r}p(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_{\pi_{k}}^{(j)}(s')\right]
vπk(j+1)(s)=∑aπk(a∣s)[∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vπk(j)(s′)]
等同于
q
π
(
s
,
a
)
=
∑
r
p
(
r
∣
s
,
a
)
r
+
γ
∑
s
′
p
(
s
′
∣
s
,
a
)
v
π
(
s
′
)
\begin{aligned}q_\pi(s,a)=\sum_rp(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_\pi(s')\end{aligned}
qπ(s,a)=r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)
v
π
(
s
)
=
∑
a
π
(
a
∣
s
)
q
π
(
s
,
a
)
v_{\pi}(s)=\sum_{a}\pi(a|s)q_{\pi}(s,a)
vπ(s)=∑aπ(a∣s)qπ(s,a)
②通过比较max_diff 和theta 的差值,判断是否完成策略评估
(4)策略提升(PI)
def policy_improvement(self): # 策略提升
for s in range(self.env.nrow * self.env.ncol):
qsa_list = []
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(qsa)
maxq = max(qsa_list) #选取当前state下maxQ(s,a)
cntq = qsa_list.count(maxq) # 计算有几个动作得到了最大的Q值
# 让这些动作均分概率,考虑到了最大qsa可能存在多个的情况
self.pi[s] = [1 / cntq if q == maxq else 0 for q in qsa_list]
print("策略提升完成")
return self.pi
①遍历所有(s,a),根据PE估计的v(s)值计算各q(s,a)值
②根据q(s,a)优化policy,若存在q(s,a)相同的情况,则policy中多个action概率相等
a
k
∗
(
s
)
=
arg
max
a
q
π
k
(
s
,
a
)
a_{k}^{*}(s)=\arg\max_{a}q_{\pi_{k}}(s,a)
ak∗(s)=argmaxaqπk(s,a)
(5)终止判断
if old_pi == new_pi: break
最近两次policy一致时,终止循环。
2.3价值迭代(value iteration)算法
2.3.1伪代码

- 算法流程简述:
①值初始化:根据环境,初始化各state的state value,一般设置为0
②更新Q值:进入循环,根据bellman方程计算各state下所有action的action value
③策略更新(policy update):以最大的action value更新policy(greedy policy)
④价值更新(value update):估计新一轮的state value
⑤阈值判断:判断最近两轮的state value差值是否小于阈值,若是则跳出循环输出policy;若否则继续重复②~④步
2.3.2完整代码
import copy
class CliffWalkingEnv:
""" 悬崖漫步环境"""
def __init__(self, ncol=12, nrow=4):
self.ncol = ncol # 定义网格世界的列
self.nrow = nrow # 定义网格世界的行
# 转移矩阵P[state][action] = [(p, next_state, reward, done)]包含下一个状态和奖励
self.P = self.createP()
def createP(self):
# =============================================================================
# 转移矩阵P[s][a] = [(p, next_state, reward, done)]包含下一个状态和奖励
# p:s到next_state的状态转移概率,在这里都取1
# reward:s到next_state的即时奖励
# done:是否到达终点或悬崖
# =============================================================================
# 初始化
P = [[[] for j in range(4)] for i in range(self.nrow * self.ncol)]
# 4种动作, change[0]:上,change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)
# 定义在左上角
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
for i in range(self.nrow):
for j in range(self.ncol):
for a in range(4):
# 位置在悬崖或者目标状态,因为无法继续交互,任何动作奖励都为0
if i == self.nrow - 1 and j > 0:
# 除了4行1列的元素的done状态都设置为True,其都为悬崖,除4行12列为终点
P[i * self.ncol + j][a] = [(1, i * self.ncol + j, 0,
True)]
continue
# 其他位置
next_x = min(self.ncol - 1, max(0, j + change[a][0]))
next_y = min(self.nrow - 1, max(0, i + change[a][1]))
next_state = next_y * self.ncol + next_x
reward = -1
done = False
# 下一个位置在悬崖或者终点
if next_y == self.nrow - 1 and next_x > 0:
done = True
if next_x != self.ncol - 1: # 下一个位置在悬崖
reward = -100
P[i * self.ncol + j][a] = [(1, next_state, reward, done)]
return P
class ValueIteration:
""" 价值迭代算法 """
def __init__(self, env, theta, gamma):
self.env = env
self.v = [0] * self.env.ncol * self.env.nrow # 初始化价值为0
self.theta = theta # 价值收敛阈值
self.gamma = gamma
# 价值迭代结束后得到的策略
self.pi = [None for i in range(self.env.ncol * self.env.nrow)]
def value_iteration(self):
cnt = 0
while 1:
max_diff = 0
new_v = [0] * self.env.ncol * self.env.nrow
for s in range(self.env.ncol * self.env.nrow):
qsa_list = [] # 开始计算状态s下的所有Q(s,a)价值
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(qsa) # 这一行和下一行代码是价值迭代和策略迭代的主要区别
new_v[s] = max(qsa_list)
max_diff = max(max_diff, abs(new_v[s] - self.v[s]))
self.v = new_v
if max_diff < self.theta: break # 满足收敛条件,退出评估迭代
cnt += 1
print("价值迭代一共进行%d轮" % cnt)
self.get_policy()
def get_policy(self): # 根据价值函数导出一个贪婪策略
for s in range(self.env.nrow * self.env.ncol):
qsa_list = []
for a in range(4):
qsa = 0
for res in self.env.P[s][a]:
p, next_state, r, done = res
qsa += p * (r + self.gamma * self.v[next_state] * (1 - done))
qsa_list.append(qsa)
maxq = max(qsa_list)
cntq = qsa_list.count(maxq) # 计算有几个动作得到了最大的Q值
# 让这些动作均分概率
self.pi[s] = [1 / cntq if q == maxq else 0 for q in qsa_list]
def print_agent(agent, action_meaning, disaster=[], end=[]):
print("状态价值:")
for i in range(agent.env.nrow):
for j in range(agent.env.ncol):
# 为了输出美观,保持输出6个字符
print('%6.6s' % ('%.3f' % agent.v[i * agent.env.ncol + j]), end=' ')
print()
print("策略:")
for i in range(agent.env.nrow):
for j in range(agent.env.ncol):
# 一些特殊的状态,例如悬崖漫步中的悬崖
if (i * agent.env.ncol + j) in disaster:
print('****', end=' ')
elif (i * agent.env.ncol + j) in end: # 目标状态
print('EEEE', end=' ')
else:
a = agent.pi[i * agent.env.ncol + j]
pi_str = ''
for k in range(len(action_meaning)):
pi_str += action_meaning[k] if a[k] > 0 else 'o' #action存在概率就打印
print(pi_str, end=' ')
print()
env = CliffWalkingEnv()
action_meaning = ['^', 'v', '<', '>']
theta = 0.001
gamma = 0.9
agent = ValueIteration(env, theta, gamma)
agent.value_iteration()
print_agent(agent, action_meaning, list(range(37, 47)), [47])
2.3.3运行结果
价值迭代一共进行14轮
状态价值:
-7.712 -7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710
-7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900
-7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900 -1.000
-7.458 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
2.4截断策略迭代(Truncated policy iteration)
2.4.1伪代码
在policy iteration的基础上增加了一个截断因子j,用于提升PE的效率,最终也能收敛。

小结
- 动态规划算法是强化学习的基础,其中应用的贝尔曼方程是估计state value,action value的“渠道”
- 必须是在“白盒”环境下应用,即为model-based算法,适用范围有限
- Truncated policy iteration中,截断步数取1,即为value iteration;截断步数取∞,即为policy iteration
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【动手学强化学习】part2-动态规划算法

发表评论 取消回复