1、历史上的二个版本
与生产者客户端一样,在Kafka的发展过程当中,消费者客户端主要有两个大的版本:
- 旧消费者客户端(Old Consumer):基于Scala语言开发的版本,又称为Scala消费者客户端。
- 新消费者客户端(New Consumer):从Kafka 0.9.0版本之后基于Java语言开发的版本,又称为Java消费者客户端。
2、必要的参数配置
-
bootstrap.servers
用来指定连接Kafka集群所需的broker地址清单,形式为:host1:port1,host2:port2,…,多个broker之间以“,”隔开。
不用将所有broker列出来,消费者可以根据一个broker查询到其他broker。
建议至少配置2个或2个以上的broker,防止只有一个broker的话,宕机的时候就无法连接到Kafka集群了。
-
group.id
消费者隶属消费组的名称。
-
key.deserializer 和 value.deserializer
与生产者客户端 KafkaProducer中的key.serializer和value.serializer参数对应。
用来将字节数组中的key和value反序列化还原为原来的对象格式。
3、订阅主题与分区
一个消费者可以订阅一个或多个主题。
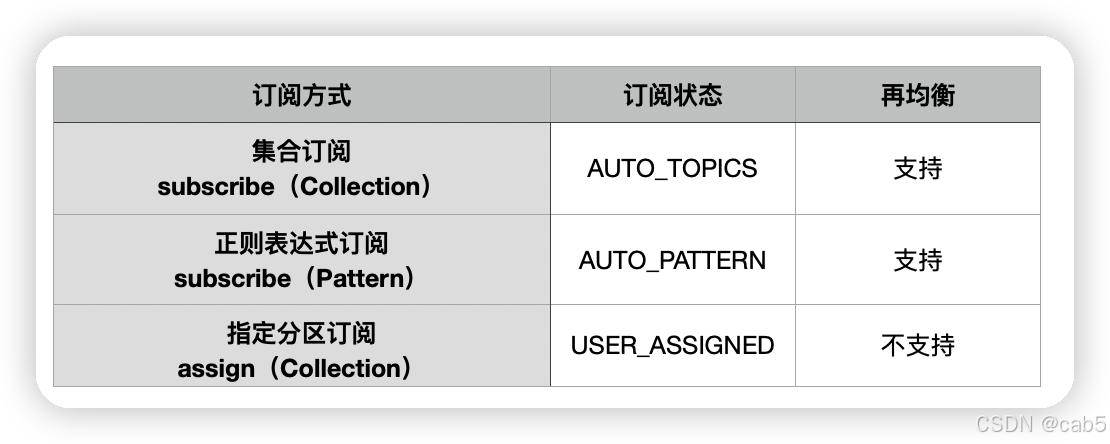
Kafka消费者客户端提供了三种订阅方式:集合订阅subscribe(Collection)、正则表达式订阅subscribe(Pattern)、指定分区订阅assign(Collection)。
这三种订阅方式分别代表了三种不同的订阅状态,依次为AUTO_TOPICS、 AUTO_PATTERN、USER_ASSIGNED。如果没有订阅,订阅状态为NONE。
其中的集合订阅subscribe(Collection)和正则表达式订阅subscribe(Pattern)这两种订阅方式有消费者自动再均衡的功能,可以根据分区分配策略自动的为消费者分配对应的分区。而指定分区订阅assign(Collection)方式则不具备消费者自动再均衡的功能。
综上所述梳理了一张关于订阅方式、订阅状态和再均衡功能的关系表:
4、消费消息
消息消费一般有两种方式:
- 推模式:服务器主动将消息推送给消费者。
- 拉模式:消费者主动向服务器发起请求来来取信息。
Kafka采用的消息消费模式是拉模式。
在拉取消息的时候有一个超时时间参数(timeout),如果消费者的缓存区中无可用数据(即没有要消费消息),我们可以通过这个timeout参数来设置等待的时长。如果timeout=0,则不管有无数据立刻返回结果。
5、位移提交
在Kafka的分区当中,每一个消息都有一个唯一的标识offset,我们可以用它来表示消息在分区中的位置。
对于消费者而言,也有一个offset的概念,我们可以用它来表示消费到分区中某消息的位置。
对于offset这个单词,我们既可以翻译为偏移量,也可以翻译为位移,并没有什么严格的区分。但是为了更好的区分不同的使用场景,我们可以将用来表示消息在分区中位置的offset称为偏移量。对于用来表示消费者消费到的消息所处位置的offset称为位移,更明确的话称为“消费位移”。
通过下图希望能够帮助大家更清晰的理解:偏移量、消费位移、位移提交。
通过上图我们可以了解到如下信息:
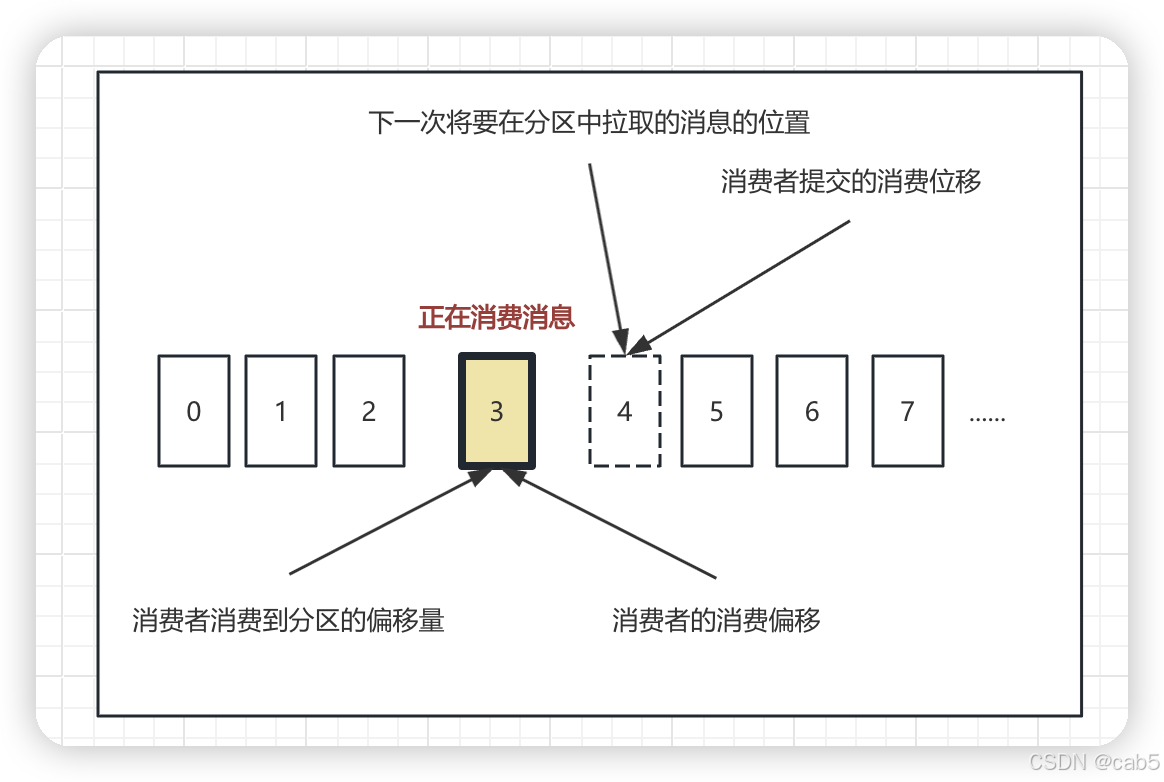
- 正在消费的消息下标为3。
- 所以对于分区来说,它的偏移量为3;对于消费者来说,它的消费位移也为3。
- 对于分区来说,下标4则作为下一个消息要写入的位置。
- 对于消费者来说,将要提交的消费位移(即位移提交)是下标4。
Kafka默认情况下,消费位移的提交方式为自动提交,提交间隔时间默认为5秒。
根据位移提交的具体情况,可能会出现重复消费和消息丢失的现象。我们通过下面一个例子更详细介绍下重复消费和消息丢失是如何出现的。让我们先来看一张图:
根据上图,我们假设本次拉取的消息为x+2 ~ x+7,x+2为上一次的提交的消费位移,x+8为下一次要提交的消费位移,目前正在处理x+5。
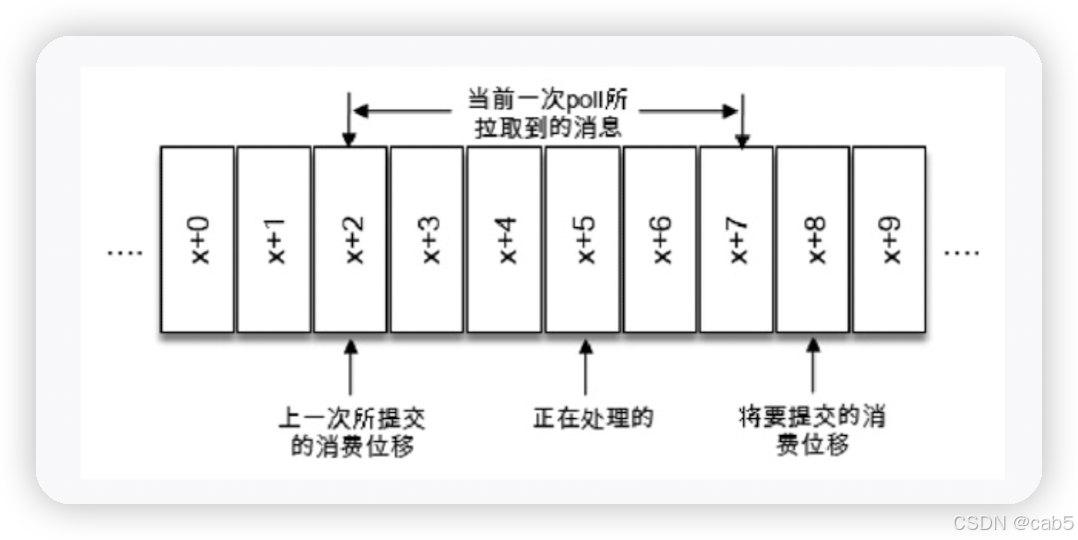
-
消息丢失
假设我们在处理x+5之前(即在处理x+0或x+1或x+2…)就提交了本次的消费位移(即x+8),当到处理x+5的时候出现了异常,恢复后,就要从x+8开始拉取了,此时x+5、x+6、x+7实际上并没有被消费,这样便发生了消息丢失的现象。(在消费消息出现异常之前就执行了位移提交)。
-
重复消费
假设我们在处理x+5的时候出现了异常,此时还没有提交本次的消费位移(即x+8),恢复后,就还需要从x+2开始拉取消息,这样x+2 ~ x+4就又得再消费一次,这种现象就是重新消费。(在消费消息出现异常之前没有执行位移提交)。
通过以上的描述我们还可以发现:拉取线程和消息处理线程完全是两个独立的线程。
6、指定位移消息
首先提出一个问题:当消费者遇到无法获取所记录的消费位移的时候该怎么办?
为了要解决这个问题,消费者客户端提供了auto.offset.reset参数,用来在遇到这种情况的时候告诉消费者客户端从哪里开始拉取消息消费,该参数的值有几种选择:
- latest:默认值,意为从分区末尾开始消费消息(即分区中下一条消息要写入的位置)。
- earliest:意为消费者会从起始处也就是0开始消费。
- none:直接抛出NoOffsetForPartitionException异常。
7、再均衡
所谓再均衡就是将一个分区的所属权从一个消费者转移到另外一个消费者。
再均衡的过程中,消费组内的消费者无法读取消息。
再均衡后,可能会出现重复消费的情况。因为再均衡的时候,消费者会丢掉当前的状态。如果在上一个消费者(即具有分区所属权的消费者)正在消费消息(已消费了一部分消息了)还没有来得及提交消费位移的时候就发生了再均衡,那么新的消费者(分区所属权转移后的消费者)会重新拉取曾经消费过的消息再消费一遍。
8、消费者拦截器
我们可以通过消费者拦截器在poll返回消息之前和消费位移提交之后进行一些特定的处理。
9、多线程实现
为了提高整体的消费能力,我们对消费者客户端采取多线程来实现。
有三种多线程的实现方式:
- 线程封闭,即为每一个线程实现一个KafkaConsumer对象,如下图:
- 多个消费线程同时消费一个分区,通过assign()、seek()等方法实现,打破了原有的消费线程的个数不能超过分区个数的限制。但是这种实现方式会使位移提交和顺序控制变得非常负责,实际场景中很少会用到。
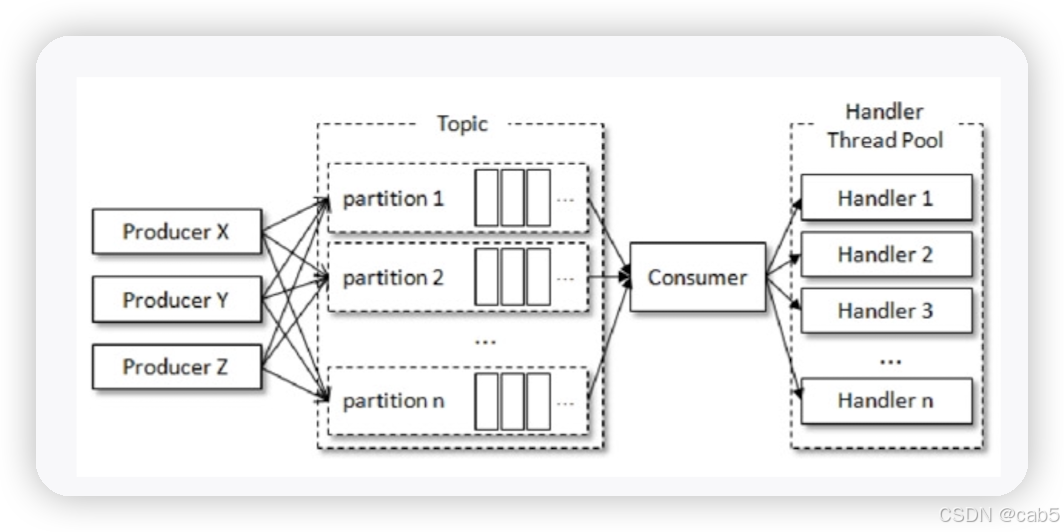
- 将处理消息的逻辑改为多线程实现,也就是在一个KafkaConsumer对象中有多个处理消息的handler线程,如下图:
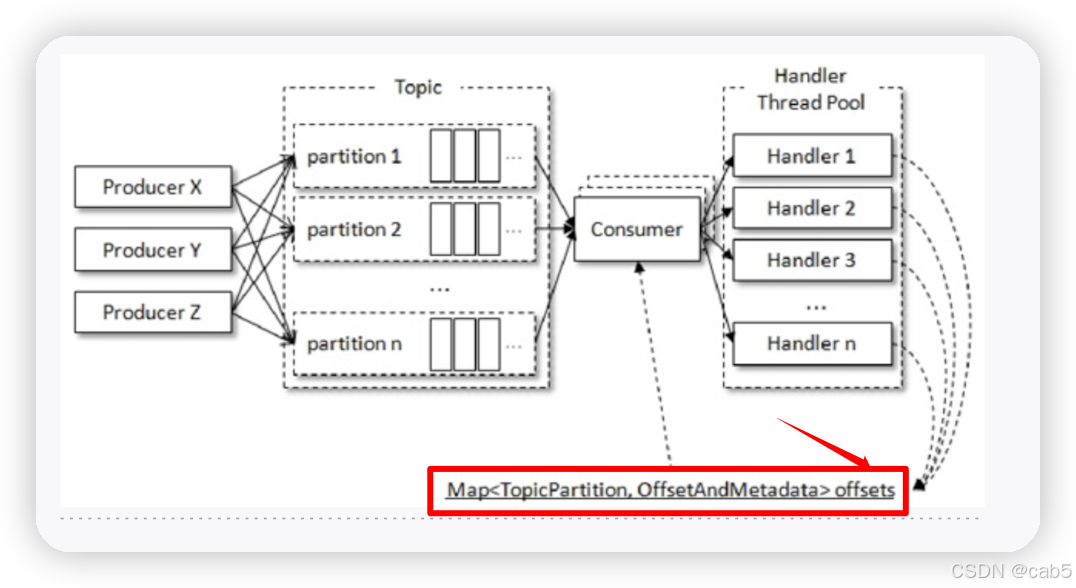
在这种实现方式中,为了能够正确的完成位移提交,引入了一个共享变量offsets来参与提交,如下图:
基于这种实现方式提供以下两种实现方案:- 通过消费者拉取一个批次的消息,然后再将这些消息交给多线程去处理。
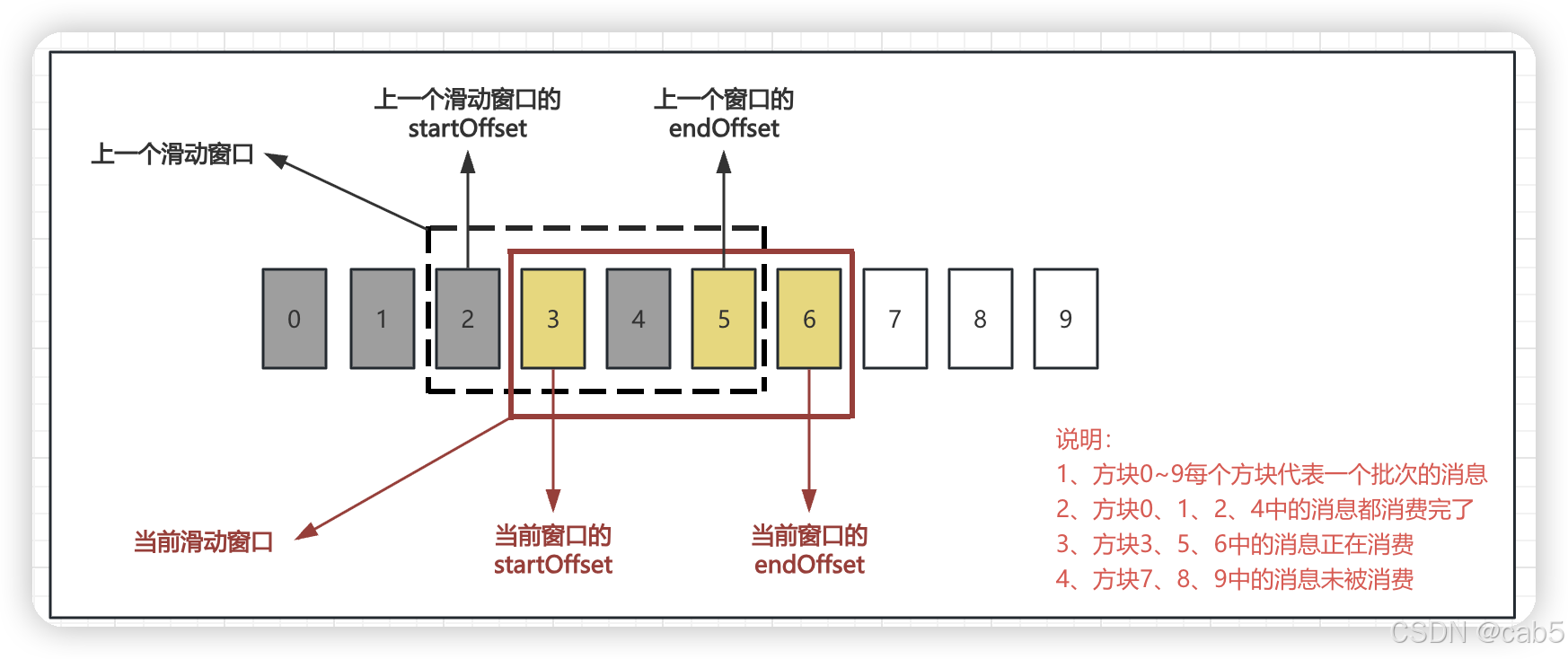
- 基于滑动窗口来实现,将拉取的消息以批次为单位暂存起来,多个消费线程拉取暂存的消息消费,如下图:
窗口滑动过程描述:上一次滑动窗口的范围是2 ~ 5,startOffset为2,当2中的消息都被消费完成后,提交2中的消费位移,窗口向前滑动一格,范围变为3 ~ 6,startOffset变为3。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Kafka之消费者客户端

发表评论 取消回复