(一)借鉴
1. Transformer有很多变形,它和CNN、MLP基本现在都算是非常基础必用的内容了
2.如果你又双忘了self-attention的输入、输出为什么是一样的形状,请看看这个视频,这是我看过的解释得最清晰的一个了
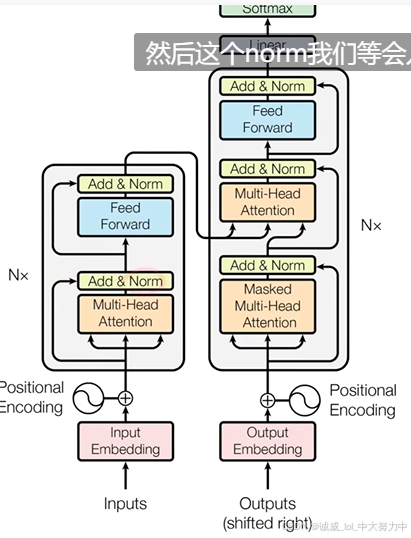
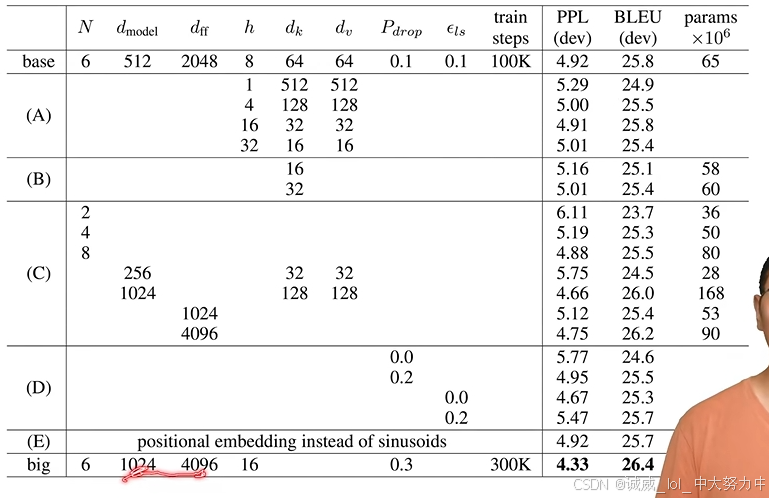
3.多做实验,每个实验都进行Table记录,才能有所发现
(二)启发
1.其实整个Transformer架构的超参数很少:有几个层xxxxx的,所以是一个很simple的架构,后来的Bert\GPT都是直接在上面扩展的
2.其实QKV本身没学到什么,真正学到的还是每面的MLP,指示QKV在更宏观的维度把握了数据之间的关系(这也是Transformer只有在数据量和模型足够大的情况下会优于CNN的原因之一)
3.对了,李沐说的multi-head的实现可以合并成一个矩阵的实现,其实就是当时刘海根学长在实验课上提到的做法,非常巧妙
4.做Mask这件事,其实是为了保证train的时候和infer的时候一样,看不到还没有输出的内容(不过,有一个小小的点,我其实没弄明白output Embedding那里输入的是什么?)
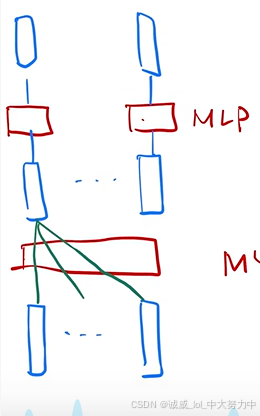
5.关于最后的MLP层的特殊之处,它只是对当个"词"做MLP,因为词与词之间的联系已经在之前的attention中抽取完了。
6.关于写作,这篇Attention is all you need的写作上,其实是没有故事的,每一句话都是一个做法。不过,我们写论文,最好是有创新,然后有理有据的讲述一个故事,让读者有代入感。
7.对于Transformer模型本身,是一个很通用的框架,就像是CNN对于计算机视觉的影响,而人其实都是从听、视、文本等多模态的感知,Transformer可以让多模态统一框架。——不同的领域都可以用这个
8.其实attention做的就是序列信息的aggregation —— (偏哪归置?一般化?)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 李沐读论文-启发与借鉴-3:Attention is all you need

发表评论 取消回复