目录
7.非成员功能重载(non-member function overloads)
一.auto和范围for
在了解string类之前,我们先以学会auto和范围for的使用作为铺垫。
auto
1.在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,后来这个不重要了。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
2.用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&。
3.当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
4.auto不能作为函数的参数,可以做返回值,但是建议谨慎使用。
5.auto不能直接用来声明数组。
int func1()
{
return 10;
}
int main()
{
int a = 0;
auto b = a;
auto c = 'a';
auto d = func1();
// 编译报错:rror C3531: “e”: 类型包含“auto”的符号必须具有初始值设定项
//auto e;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
int x = 10;
auto y = &x;
auto* z = &x;
auto& m = x;
cout << typeid(y).name() << endl;
cout << typeid(z).name() << endl;
cout << typeid(m).name() << endl;
auto aa = 1, bb = 2;
cout << typeid(aa).name() << endl;
cout << typeid(bb).name() << endl;
// 编译报错:error C3538: 在声明符列表中,“auto”必须始终推导为同一类型
//auto cc = 3, dd = 4.0;
//
// 编译报错:error C3318: “auto []”: 数组不能具有其中包含“auto”的元素类型
//auto array[] = { 4, 5, 6 };
return 0;
}范围for
1.对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号”:”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被选代的范围,自动迭代,自动取数据,自动判断结束。
2.范围for可以作用到数组和容器对象上进行遍历。
3.范围for的底层很简单,容器遍历实际就是替换为迭代器,这个从汇编层也可以看到。
#include<iostream>
#include <string>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
// C++98的遍历
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
{
array[i] *= 2;
}
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
{
cout << array[i] << endl;
}
// C++11的遍历
for (auto& e : array)
e *= 2;
for (auto e : array)
cout << e << " " << endl;
string str("hello world");
for (auto ch : str)
{
cout << ch << " ";
}
cout << endl;
return 0;
}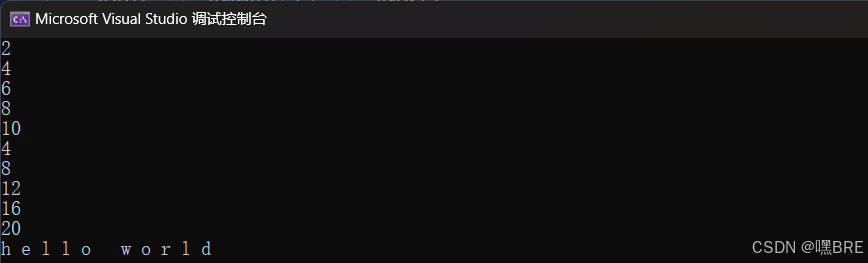
范围for语句冒号之后的值会自动赋值给前面的变量,所以冒号前面的值的改变不会改变要遍历的容器的值。当然如果想要改变所要遍历的值,也有办法,就是在auto后面加一个引用就可以对其进行改变。
二.string类的常用接口介绍
1.成员函数(Member functions)
a.构造(constructor)
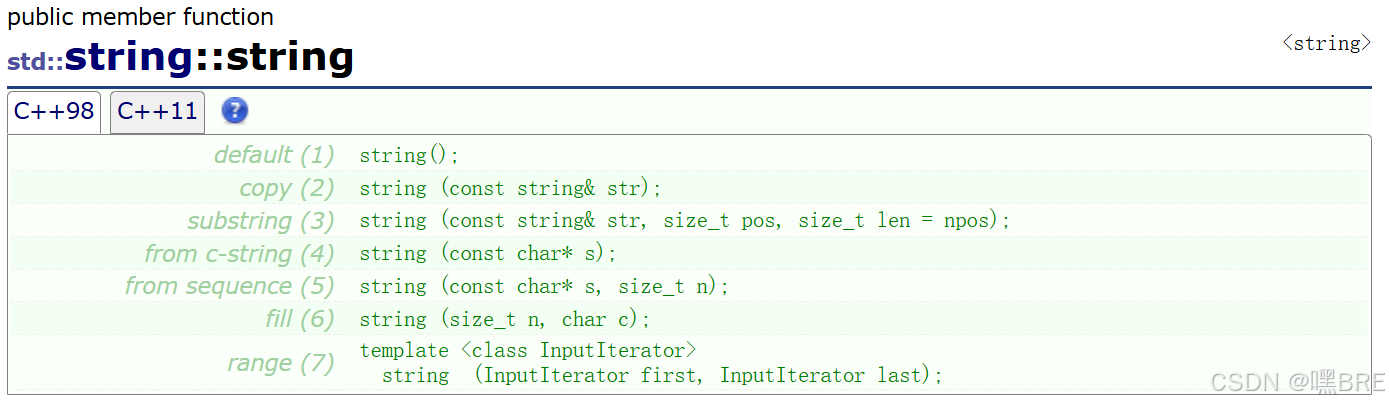
在C++98中一共提供了7个接口。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("hello world");
string s2(s1);
string s3(s1, 1, 4);
string s4("hehe");
string s5("hehe", 2);
string s6(10, 'x');
string s7(s1.begin(), s1.end());
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << s4 << endl;
cout << s5 << endl;
cout << s6 << endl;
cout << s7 << endl;
return 0;
}在substring接口中,参数len的缺省值是npos。
那么npos是什么意思呢?

参考文档,我们可以知道npos是size_t的最大值。
npos是一个静态成员常量值,对于 size_t 类型的元素具有最大可能的值。
当此值用作字符串成员函数中 len (或 sublen) 参数的值时,表示"直到字符串的未尾”。作为返回值,它通常用于指示没有匹配项。
此常量定义为值 -1,因为 size_t是无符号整型,所以它是此类型的最大可能可表示值。
b.析构(destructor)

c.赋值运算符重载(operator=)
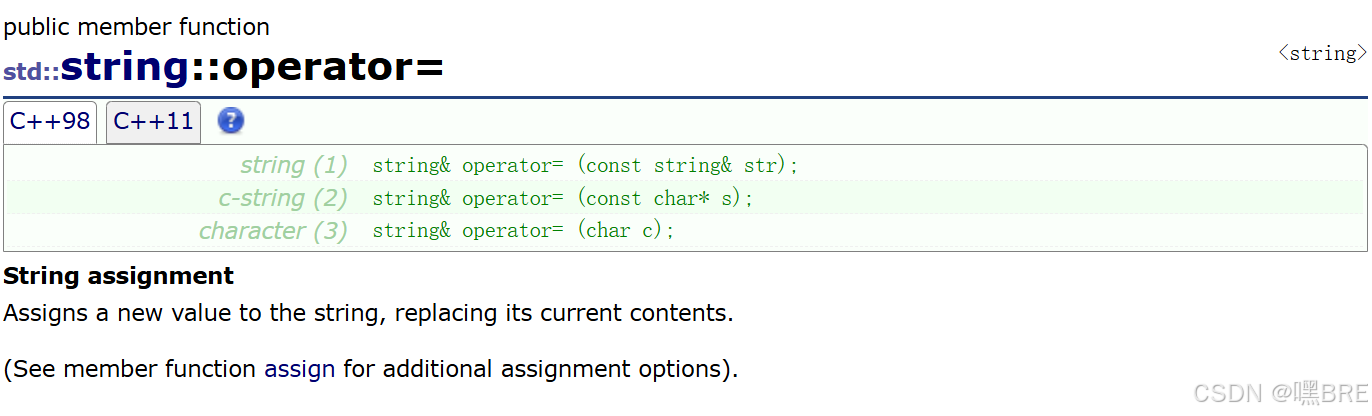
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1, s2, s3;
string s0("hello world");
s1 = s0;
s2 = "hehe";
s3 = '#';
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
return 0;
}2.迭代器(iterators)
a.begin和end

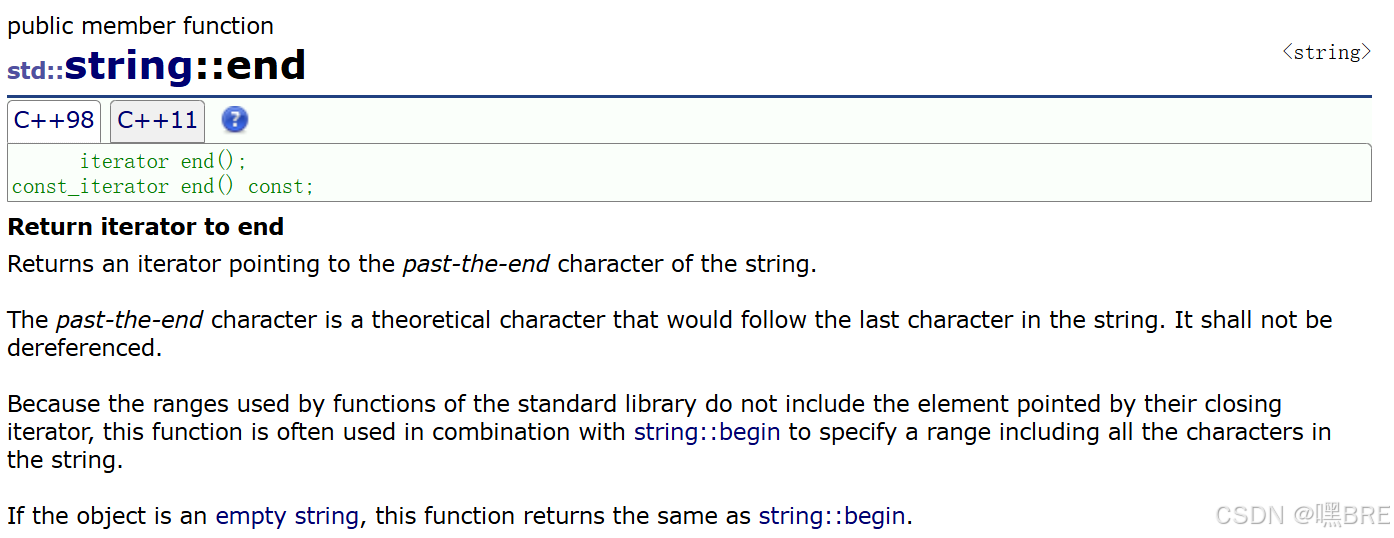
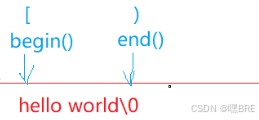
这是正向迭代器,有不含const和含const的两种用法,不含const可以对string实例化出来的对象进行改变,而含const则就只能对对象进行遍历。
begin返回一个指向字符串的第一个字符的位置,end返回字符串最后一个字符后一个字符的位置。
具体用法:
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("01234");
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it;
it++;
}
cout << endl;
it = s1.begin();
while (it != s1.end())
{
*it += 5;
cout << *it;
it++;
}
cout << endl;
return 0;
}b.rbegin和rend
这是反向迭代器,同样有不含const和含const的两种用法,不含const可以对string实例化出来的对象进行改变,而含const则就只能对对象进行遍历。
begin返回字符串中最后一个字符的位置,end返回字符串中第一个字符的前一个字符的位置。
具体用法:
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("01234");
string::reverse_iterator it = s1.rbegin();
while (it != s1.rend())
{
cout << *it;
it++;
}
cout << endl;
it = s1.rbegin();
while (it != s1.rend())
{
*it += 5;
cout << *it;
it++;
}
cout << endl;
return 0;
}3.容量(capacity)
a.size
返回字符串的长度
b.capacity
返回字符串的容量空间
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("hello");
cout << "s1.size:" << s1.size() << endl;
cout << "s1.capacity:" << s1.capacity() << endl;
cout << "s1实例化是所开辟的空间的大小:" << sizeof(s1) << endl;
string s2;
int old = s2.capacity();
cout << endl;
cout << "string的扩容:" << endl;
for (int i = 0; i < 100; i++)
{
s2 += 'x';
if (old != s2.capacity())
{
old = s2.capacity();
cout << s2.capacity() << endl;
}
}
return 0;
}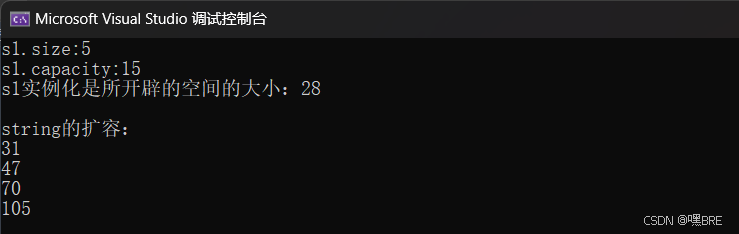
观察上面代码的扩容的问题,我们发现在VS编译器中除了第一次扩容是以二倍扩容以外,之后的步骤都是以差不多1.5倍扩容的,这是VS编译器独有的。
同时,我们还可以观察到,s2字符串就算没有给任何的初始值,编译器也会自动给s2字符串分配15个字节的空间,这是为什么呢?
其实,编译器为了做一些优化,会在string类成员变量里面多加一个16字节的buff数组,
如果字符串的大小是小于16个字节的话,它就会自动存在buff数组里面,同时,_str指针会指向一个空地址。
如果字符串的大小大于16个字节的话,他就会让_str的字符指针指向字符串在堆上所开辟的空间,同时使buff数组失效。
这样的设计就避免了在刚开始初始化字符串的时候,字符串大小太小而需要多次扩容导致的扩容效变低。
我们可以在调试的时候观察到buff数组的存储情况。
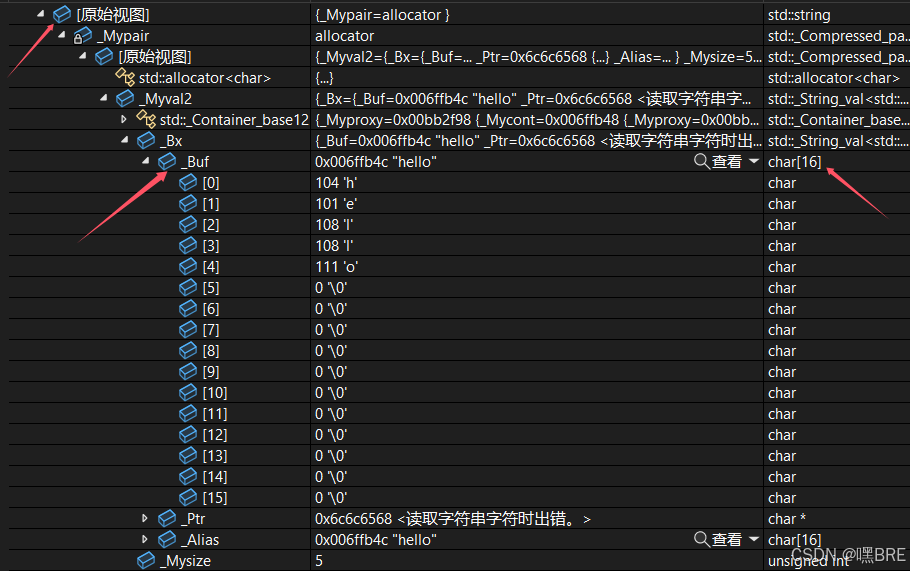
在VS监视窗口中观察s1字符串在原始视图的下面会有一个_buf的数组,我们还可以看到数组的类型是一个16字节的字符数组。
我们还要注意s1实例化所开辟空间的大小是28个字节,这又是为什么呢?
还是与buff数组有关系,在x86的环境中,指针的大小为4个字节,也就是_str指针的大小为4个字节。_size和_capacity两个整形的大小都为4个字节。再加上buff数组的16个字节的大小正好就是28个字节。
c.rsize

resize可以改变字符串的size值,如果n小于当前的字符串长度,size值会缩短至第一个n字符,然后移除掉第n个字符之后的内容。
如果n大于当前的字符串长度,当前的内容会直接延伸到第n个字符的位置,同时将c的值填充进去,如果没有指定c的值,会填充初始化值的字符,也就是'\0'。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("hello world");
cout << s1 << endl;
cout << s1.size() << endl;
s1.resize(20, '#');
cout << s1 << endl;
cout << s1.size() << endl;
return 0;
}
d.reserve

reserve起到了一个预留容量的作用。如果一个字符串的长度比较长,他就会不断的去扩容,这样就会造成开辟一块新的空间,在将原来空间的值拷贝给新的空间,最后再将原来的空间给释放掉,就会造成不必要的消耗。
reserve就可以解决这个问题。如果我们提前就知道要开辟的字符串的大小,那么我们就可以提前将字符串的大小预留出来,这样就减少了扩容的次数。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1;
s1.reserve(200);
cout << s1.capacity() << endl;
return 0;
}假如说 ,我们想要开辟一块200字节的空间,reserve就会为我们开辟一块大于等于200字节的空间。
e.clear

消除掉字符串中的内容,并将size置为0.
4.元素访问(element access)
a.oparetor[ ]

下标访问运算符的重载,分为带const(不能修改)以及不带const(可以修改)的两种接口。使用这个重载后的运算符可以直接访问字符串中指定下标的元素。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string str("hello world");
for (int i = 0; i < str.length(); ++i)
{
std::cout << str[i];
}
return 0;
}5.修改(modifiers)
a.operator+=
在字符串的后面增加内容,参数可以是string类型的对象,字符指针的变量以及字符。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string name("John");
string family("Smith");
name += " K. "; // c-string
name += family; // string
name += '\n'; // character
cout << name;
return 0;
}

b.append
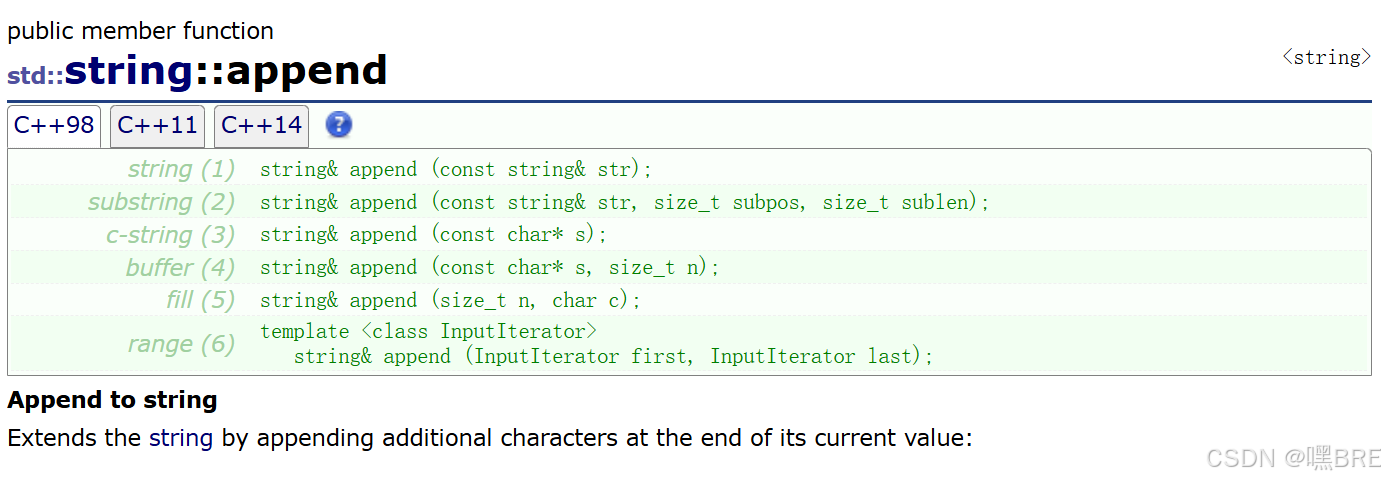
同样是一个尾插字符串的功能,支持迭代器。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str;
string str2 = "Writing ";
string str3 = "print 10 and then 5 more";
// used in the same order as described above:
str.append(str2); // "Writing "
str.append(str3, 6, 3); // "10 "
str.append("dots are cool", 5); // "dots "
str.append("here: "); // "here: "
str.append(10, '.'); // ".........."
str.append(str3.begin() + 8, str3.end()); // " and then 5 more"
cout << str << '\n';
return 0;
}

c.push_back

尾插一个字符。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1("hello world");
s1.push_back('#');
cout << s1 << endl;
return 0;
}d.insert
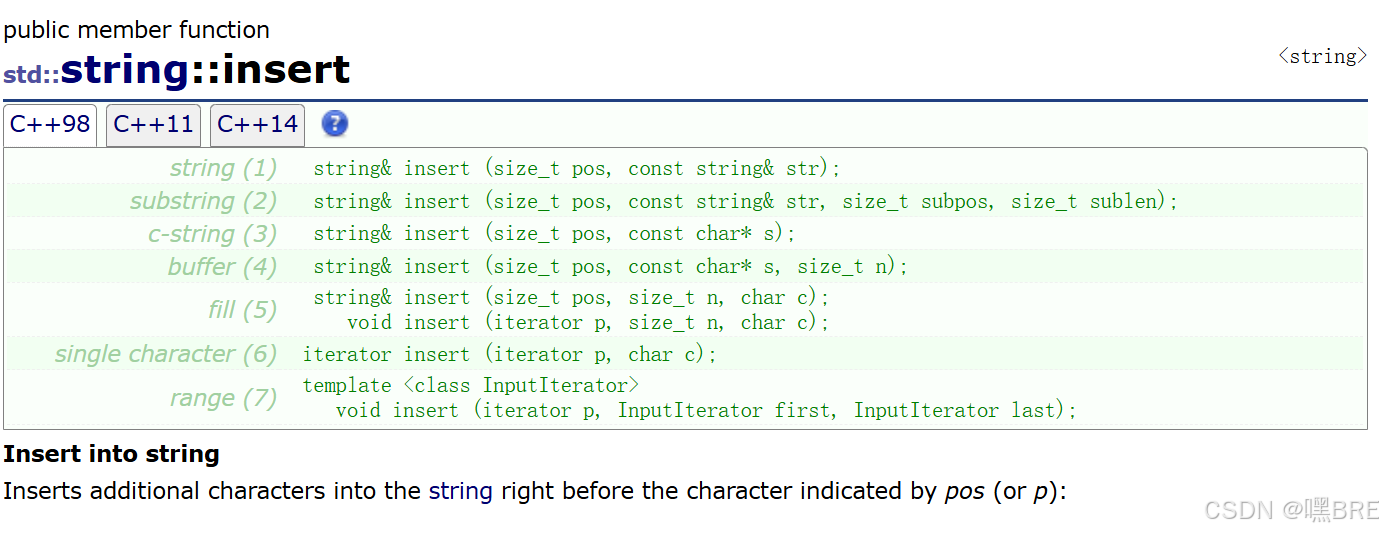
在指定位置插入字符串。
e.erase

删除指定位置的字符串。
f.replace

在一个字符串中的指定位置用另一个字符串取代其内容。 不建议多用,因为涉及到挪动数据,造成效率变低。
6.字符串操作(string operations)
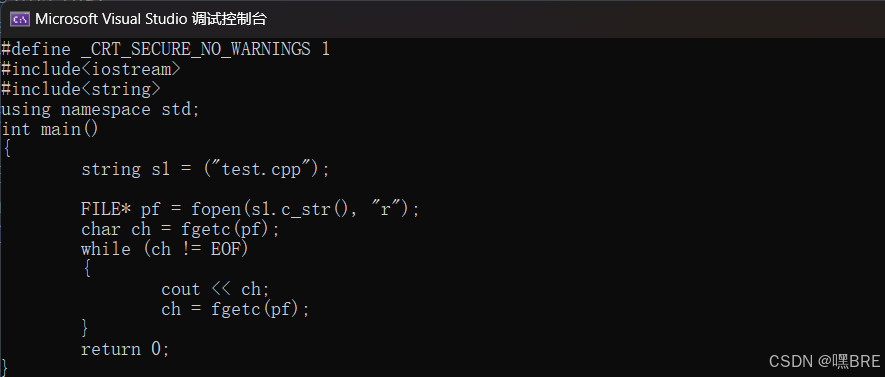
a.c_str

返回成员变量c_str的地址。
这里的c_str的作用是为了能和C语言保持兼容。
例如我们想用C语言中的文件操作,fopen接口的第一个参数就是一个字符指针类型。那么这时候我们想要将string类中的_str成员变量传进去就需要用到c_str()这个接口。

#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1 = ("test.cpp");
FILE* pf = fopen(s1.c_str(), "r");
char ch = fgetc(pf);
while (ch != EOF)
{
cout << ch;
ch = fgetc(pf);
}
return 0;
}
b.find

#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1("hello world dlx abcdefg");
cout << s1 << endl;
size_t i = s1.find(" ");
while (i != string::npos)
{
s1.replace(i, 1, "##");
i = s1.find(" ", i);
}
cout << s1 << endl;
return 0;
}

c.substr

在str中从pos位置开始,截取n个字符,然后将其返回。
7.非成员功能重载(non-member function overloads)
a.operator+

参考operator+=,这里参数里的string不会改变,因为是传值传参。尽量少用,因为传值返回,导致深拷贝效率低。
b.relation operators
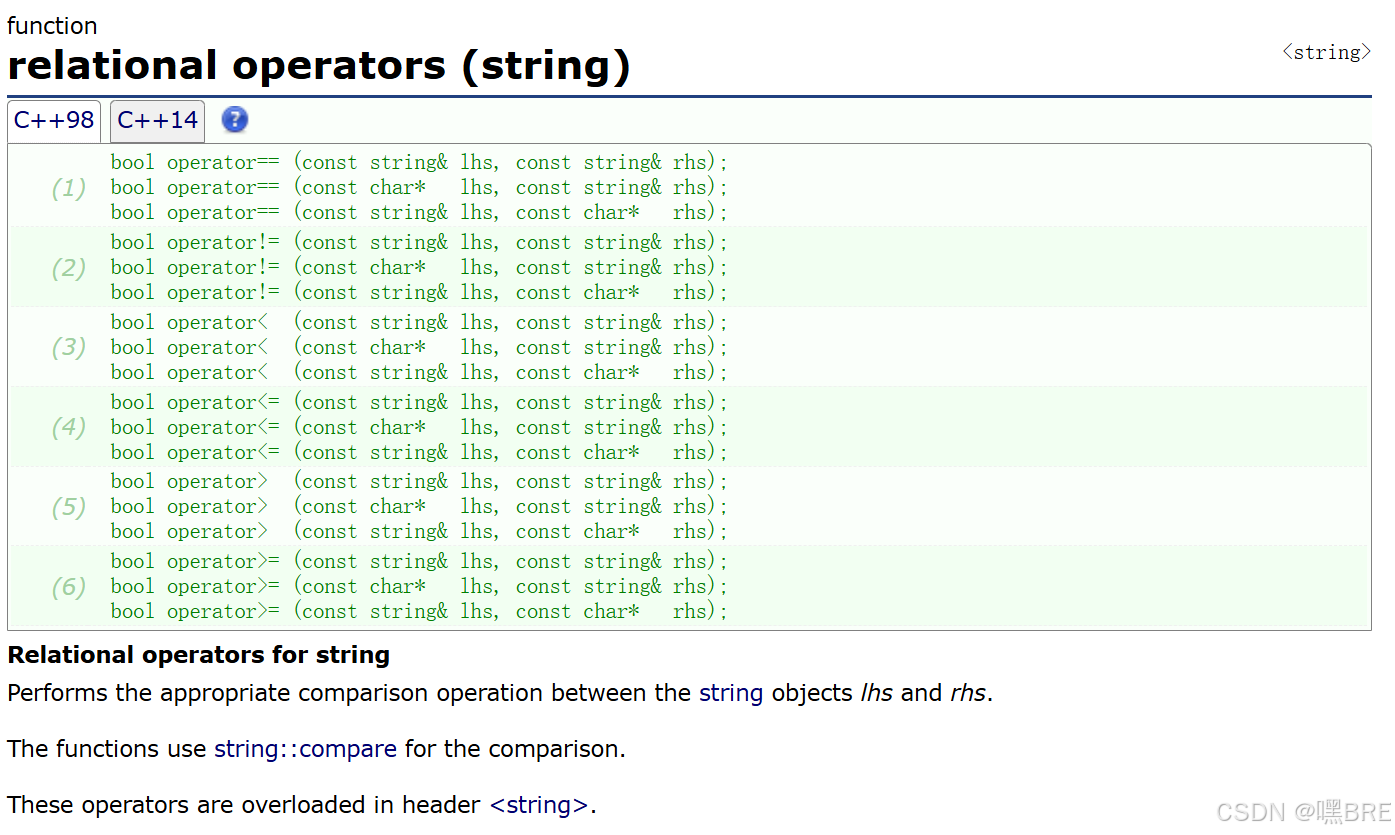
依次比较两个字符串的ASCII值、
int main()
{
string foo = "alpha";
string bar = "beta";
if (foo == bar) std::cout << "foo and bar are equal\n";
if (foo != bar) std::cout << "foo and bar are not equal\n";
if (foo < bar) std::cout << "foo is less than bar\n";
if (foo > bar) std::cout << "foo is greater than bar\n";
if (foo <= bar) std::cout << "foo is less than or equal to bar\n";
if (foo >= bar) std::cout << "foo is greater than or equal to bar\n";
return 0;
}c.operator<<

d.operator>>

e.getline
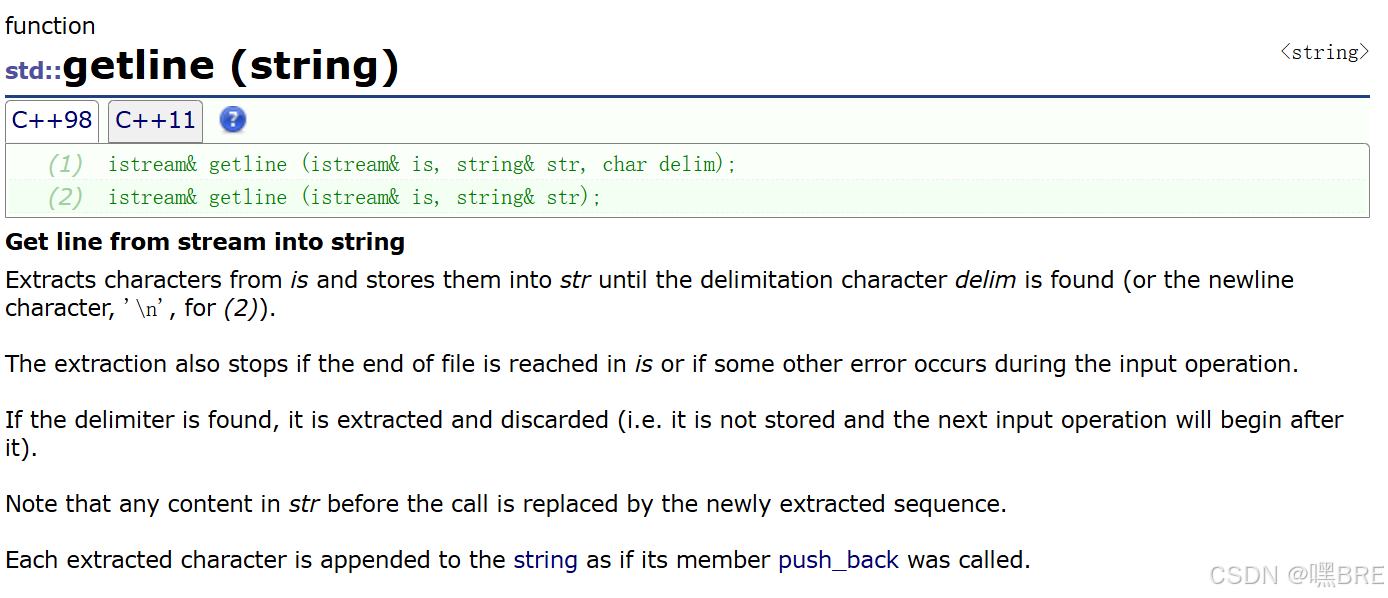
从 is 中提取字符并将其存储到 str 中,直到找到分隔符 delim(或换行符 '\n',对于 (2))。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1;
getline(cin, s1,'#');
cout << s1 << endl;
return 0;
}
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【C++】string的使用

发表评论 取消回复