Auto-encoder(自编码器)
1 基本概念
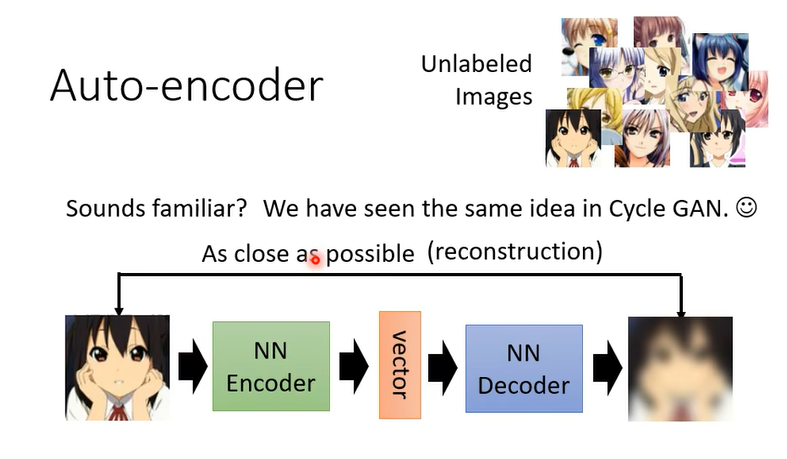
自编码就和之前的cycle GAN的概念很像,假設你有非常大量的圖片,在 Auto-Encoder 裡面你有兩個 Network,一個叫做 Encoder,一個叫做 Decoder,他們就是兩個 Network,
Encoder 把一張圖片讀進來,它把這張圖片變成一個向量,
Encoder 它可能是很多層的 CNN,把一張圖片讀進來它的輸出是一個向量,接下來這個向量會變成 Decoder 的輸入,Decoder 會產生一張圖片,所以 Decoder 的 Network 的架構可能會像是 GAN 裡面的 Generator,吃一个向量輸出一張圖片,不管是 Encoder 還是 Decoder反正就是多層的 Network,那現在訓練的目標是什麼,訓練的目標是希望Encoder 的輸入跟 Decoder 的輸出越接近越好。
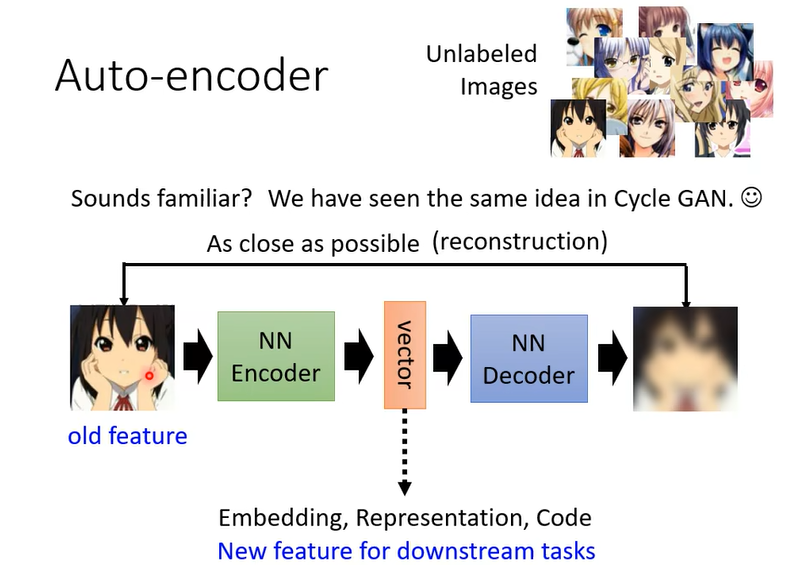
中间的这个vector,這個 Encoder 的輸出有時候我們叫它 Embedding,那有的人叫它 Representation,有的人叫它 Code,因為 Encoder 是一個編碼嘛,那其實指的都是同一件事情
那這個 Auto-Encoder 的技術要怎麼用呢,怎麼把 Train 的 Auto-Encoder用在 Downstream 的任務裡面呢
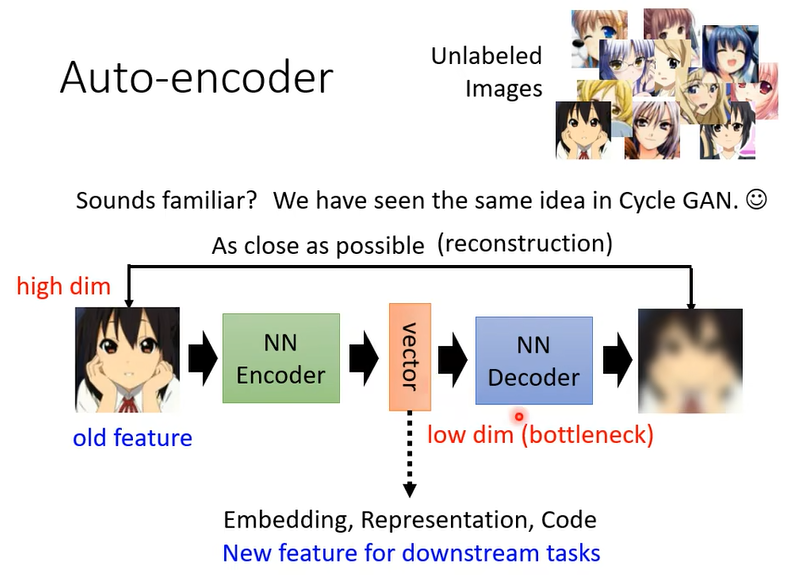
常見的用法就是原來的圖片你也可以把它看作是一個很長的向量,但這個向量太長了 不好處理那怎麼辦呢,你把這個圖片丟到 Encoder 以後輸出另外一個向量,這個向量你會讓它比較短,比如說只有 10 維 只有 100 維,那你拿這個新的向量來做你接下來的任務
而 Encoder 做的事情是把本來很高維度的東西轉成低維度的東西,把高維度的東西轉成低維度的東西又叫做 Dimension Reduction

那 Auto-Encoder 到底好在哪裡,當我們把一個高維度的圖片變成一個低維度的向量的時候到底帶來什麼樣的幫助
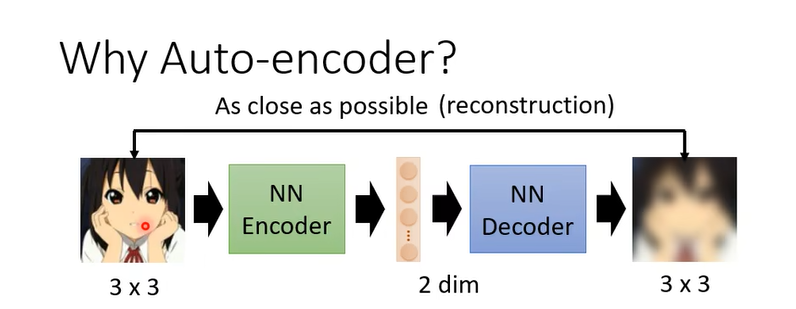
Auto-Encoder 這件事情它要做的是把一張圖片壓縮又還原回來
,但是還原這件事情為什麼能成功呢
能夠做到這件事情是因為對於影像來說並不是所有 3×3 的矩陣都是圖片,圖片的變化其實是有限的,你隨便 Sample 一個 Random 的 Noise,隨便 Sample 一個矩陣出來,它通常都不是你會看到的圖片。(高维空间有冗余的信息)流形空间
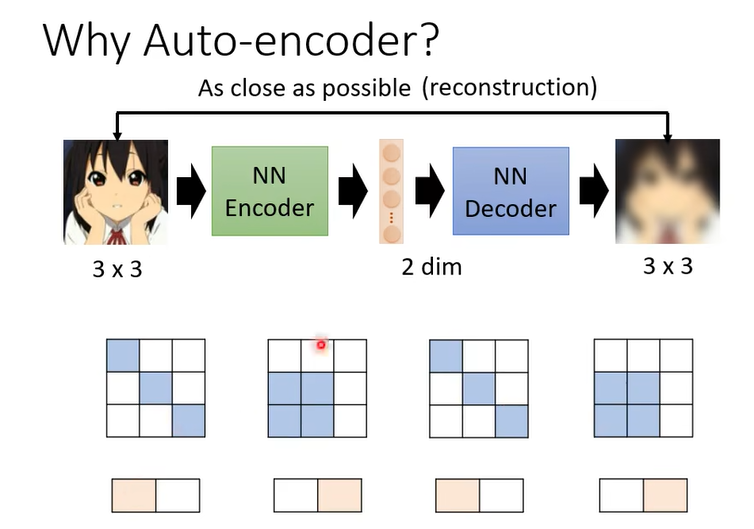
變化也許只有兩種類型,那你就可以說看到這種類型(对角线)我就左邊這個維度是 1 右邊是 0,看到這種類型(左下角)就左邊這個維度是 0,右邊這個維度是 1
而 Encoder 做的事情就是化繁為簡,本來比較複雜的東西它只是表面上比較複雜,事實上它的變化其實是有限的
如果我們可以把複雜的圖片用比較簡單的方法來表示它,那我們就只需要比較少的訓練資料在下游的任務裡面,我們可能就只需要比較少的訓練資料就可以讓機器學到我們本來要它學的事情,這個就是 Auto-Encoder 的概念
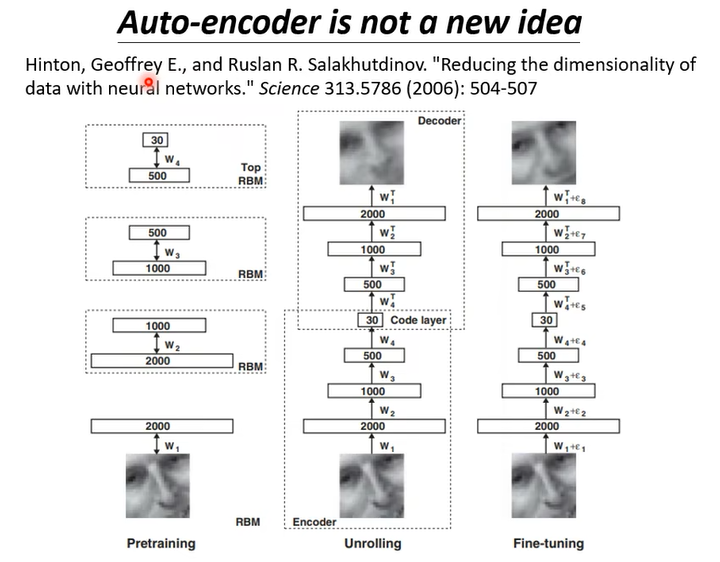
那 Auto-Encoder它從來都不是一個新的想法,它真的是非常非常地有歷史,Hinton(Deep Learning 之父) 在 06 年的 Science 的 Paper 裡面就有提到 Auto-Encoder 這個概念,只是那個時候用的 Network跟今天用的 Network當然還是有很多不一樣的地方。
那 Auto-Encoder 還有一個常見的變形叫做 De-Noising 的 Auto-Encoder
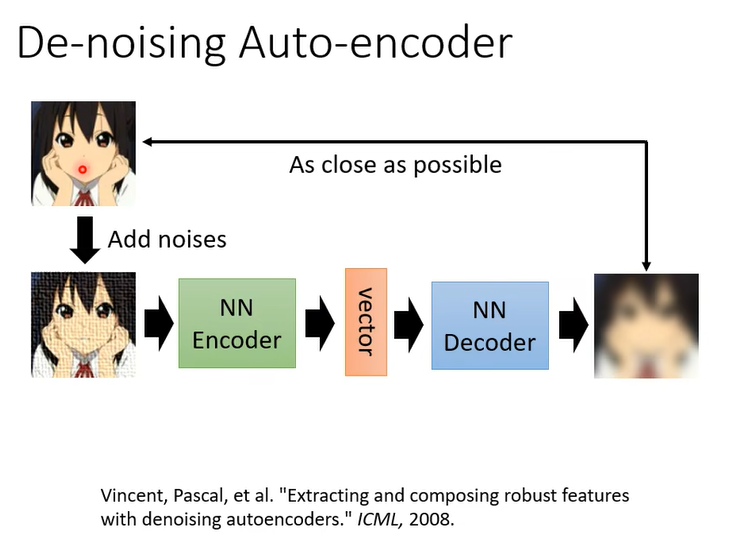
我們把原來要輸進去給 Encoder 的圖片加上一些雜訊。所以你會發現說現在 Encoder 跟 Decoder除了還原原來的圖片這個任務以外它還多了一個任務,這個任務是什麼,這個任務就是它必須要自己學會把雜訊去掉。
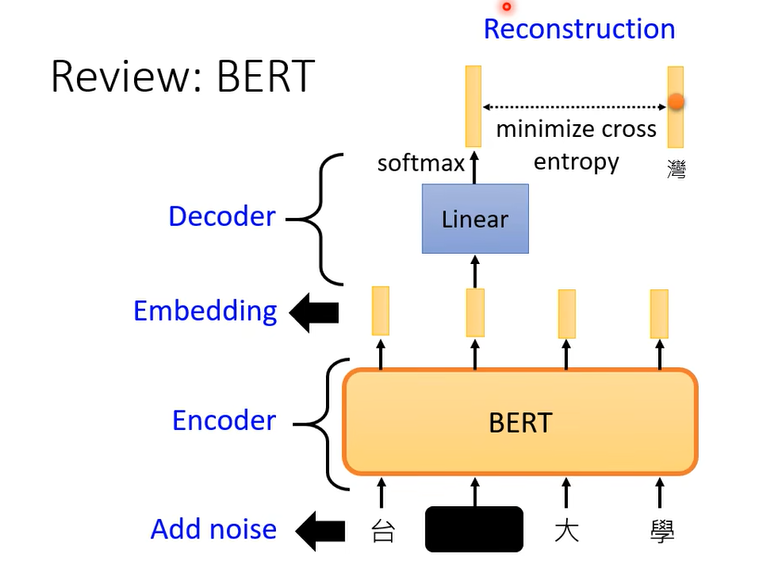
但是如果你看今天的 BERT 的話,其實你也可以把它看作就是一個De-Noising 的 Auto-Encoder,輸入我們會加 Masking,那些 Masking 其實就是 Noise,BERT 的模型就是 Encoder,它的輸出就是 Embedding,接下來有一個 Linear 的模型就是 Decoder,Decoder 要做的事情就是還原原來的句子,也就是把填空題被蓋住的地方把它還原回來。
有同學可能會問說為什麼這個 Decoder 一定要 Linear 的呢,它不一定要是 Linear,它可以不是 Linear
2 临结变声器与更多应用
除了 Aauto-Encoder可以用來做當Downstream的任務以外,我還想跟大家分享一下Auto-Encoder 其他有意思的應用
Feature 的 Disentanglement 是什麼意思呢,什麼是 Disentangle 呢,Disentangle 的意思就是把一堆本來糾纏在一起的東西把它解開。
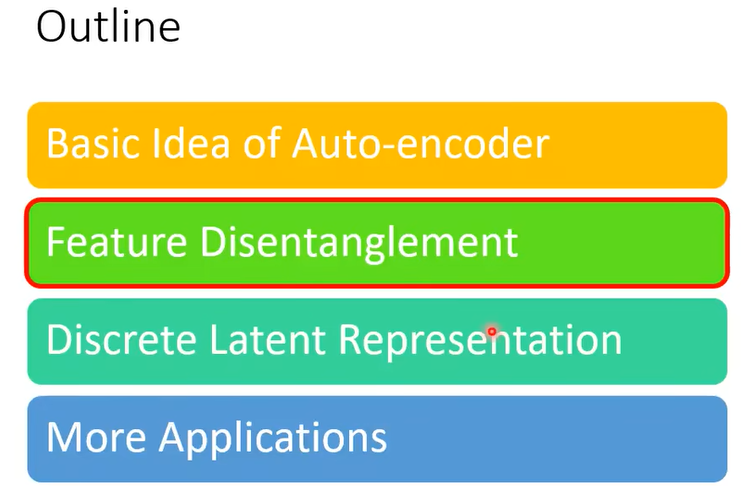
Code 裡面啊有很多的資訊,包含圖片裡面所有的資訊,舉例來說圖片裡面有什麼樣的東西啊,圖片的色澤紋理啊等等,Aauto-Encoder 這個概念也不是只能用在影像上
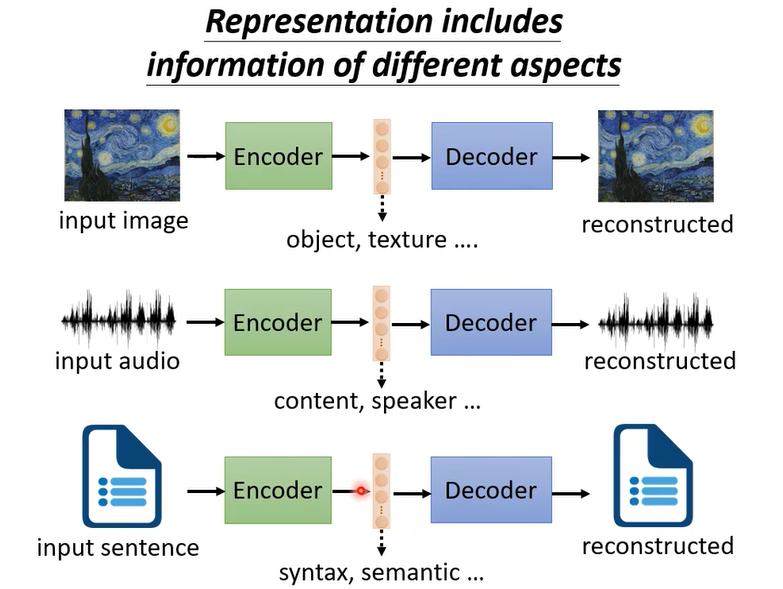
一篇文章丟到 Encoder 裡面變成向量,這個向量通過 Decoder 會變回原來的文章,那這個向量裡面有什麼,它可能包含文章裡面文句的句法的資訊,也包含了語意的資訊,但是這些資訊是全部糾纏在一個向量裡面,我們並不知道一個向量的哪些維代表了哪些資訊
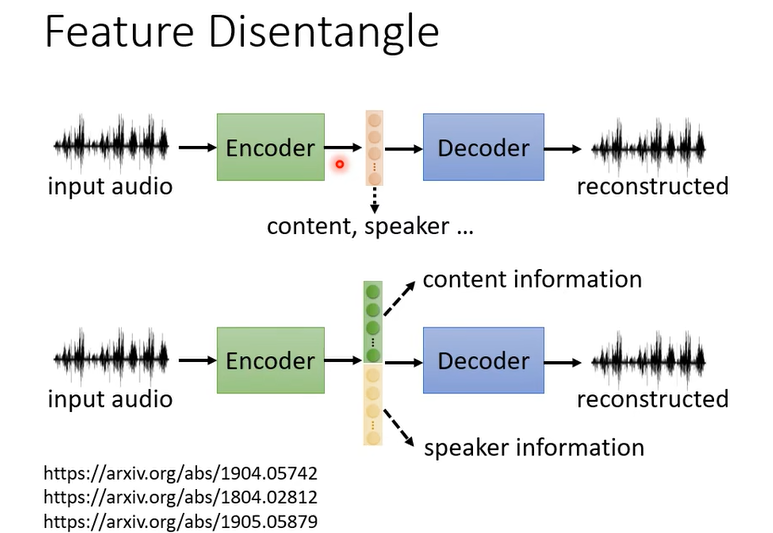
而 Feature Disentangle 想要做到的事情就是,我們有沒有可能想辦法在 Train 一個 Aauto-Encoder 的時候同時有辦法知道這個 Embedding的哪些維度代表了哪些資訊呢
那製作 Feature Disentangle有什麼樣的應用呢,這邊舉一個語音上的應用這個應用叫做 Voice Conversion
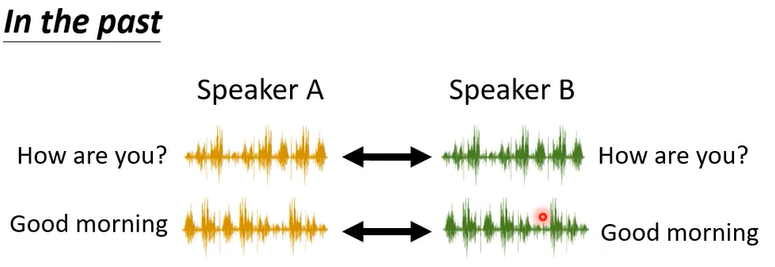
那只是過去在做這個 Voice Conversion 的時候啊我們需要成對的聲音訊號,也就是假設你要把 A 的聲音轉成 B 的聲音,你必須把 A 跟 B 都找來

今天有了 Feature Disentangle 的技術,以後也許我們期待機器可以做到就給它 A 的聲音 給它 B 的聲音,A 跟 B 不需要唸同樣的句子,甚至不需要講同樣的語言,機器也有可能學會把 A 的聲音轉成 B 的聲音
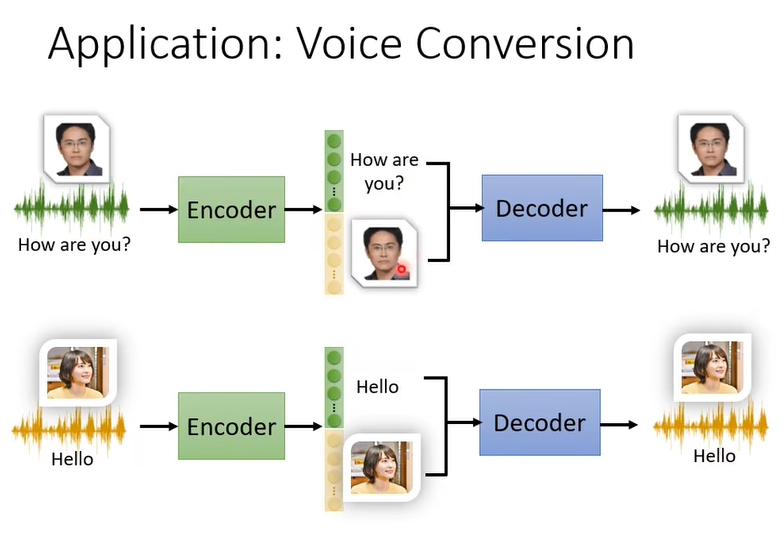
我們做了 Feature Disentangle 的技術,所以我們知道在 Encoder 的輸出裡面哪些維度代表了語音的內容,哪些維度代表了語者的特徵,接下來我們就可以做語音的轉換
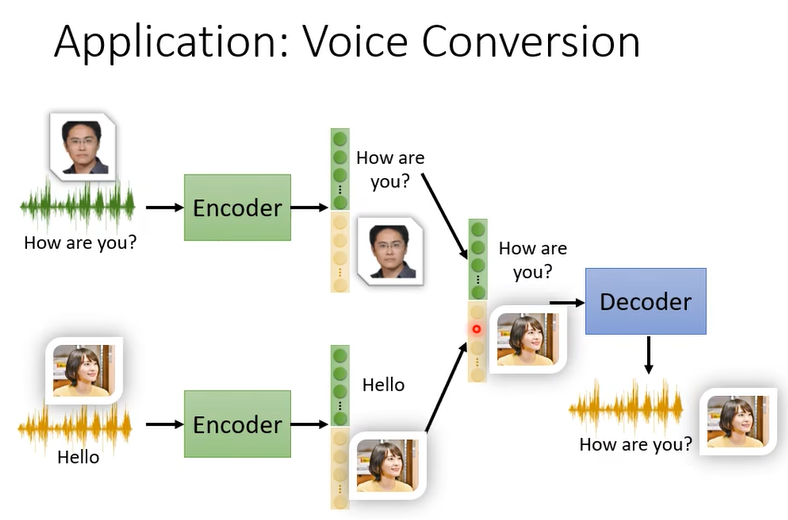
也可以反过来做
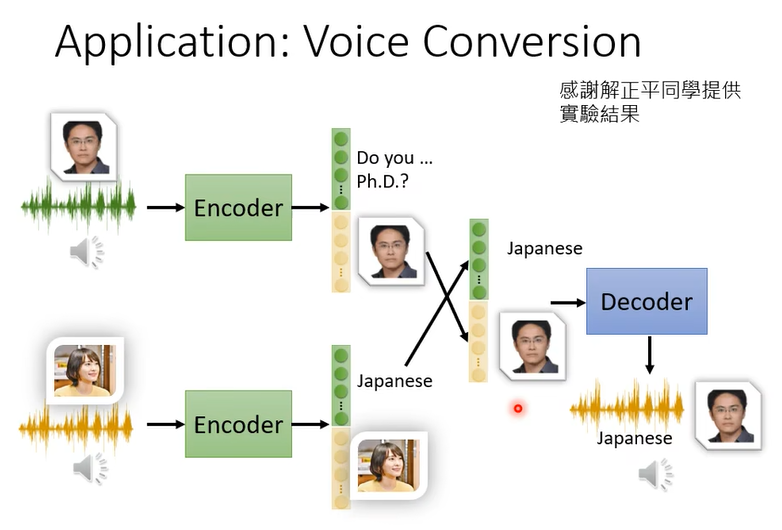
那其實在影像上,在 NLP 上也都可以有類似的應用,所以可以想想看Feature Disentangle 可以做什麼樣的事情
那下一個要跟大家講的應用叫做 Discrete Latent Representation
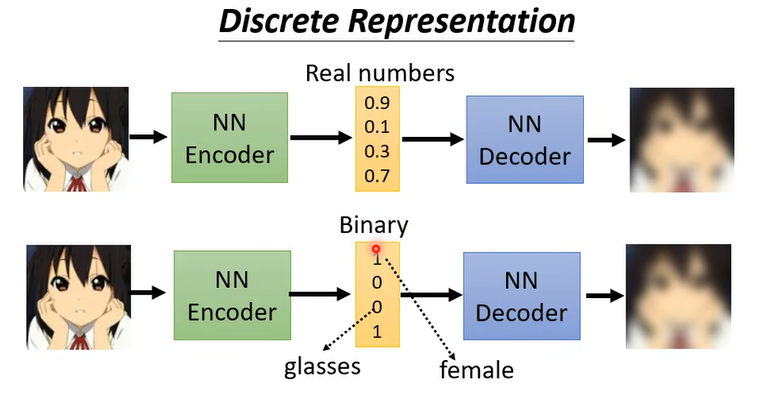
到目前為止我們都假設這個 Embedding它就是一個向量,就是一串數字,它是 Real Numbers,那它可不可以是別的東西呢
舉例來說它可不可以是 Binary,那 Binary 有什麼好處呢,Binary 的好處也許是說每一個維度它就代表了某種特徵的有或者是沒有
甚至有沒有可能這個向量強迫它一定要是 One-Hot 呢
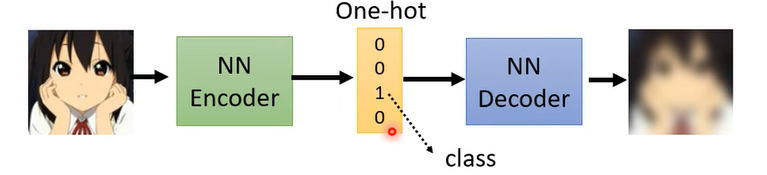
也許可以做到 unSupervised 的分類
舉例來說假設你有一大堆的手寫數字辨識,你有 0 到 9 的圖片,
Train 一個這樣子的 Auto-Encoder,然後強迫中間的這個 Code 啊一定要是 One-Hot Vector,那你這個 Code 正好設個 10 維,所以這 10 維就有 10 種可能的 One-Hot 的 Code,也許每一種 One-Hot 的 Code正好就對應到一個數字也說不定。
所以今天如果用 One-Hot 的 Vector來當做你的 Embedding 的話,也許就可以做到在完全沒有Label Data 的情況下讓機器自動學會分類。
Discrete 的 Representation 的這個技術裡面啊其中最知名的就是 VQVAE
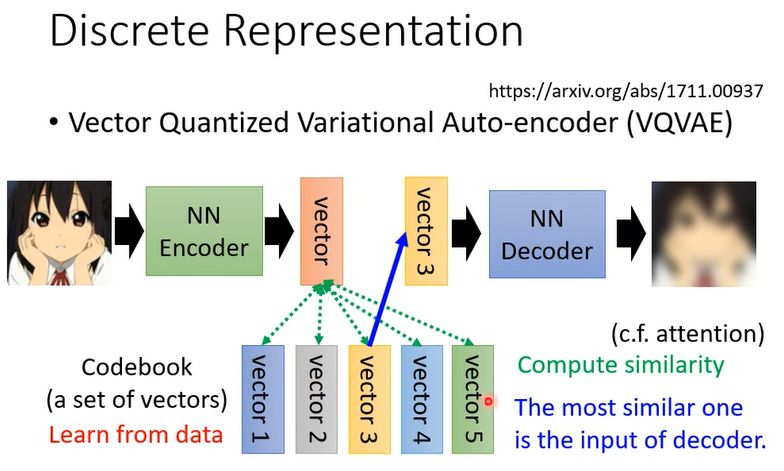
去算個相似度,那你發現這件事情啊其實跟 Self-attention 有點像 ,vector就是query,vector1-vector5就是key(同时也是value)
這樣做的好處也就是說這邊 Decoder 的輸入一定是這邊這個 Codebook裡面的向量的其中一個,假設你 Codebook 裡面有 32 個向量,那你 Decoder 的輸入就只有 32 種可能,你等於就是讓你的這個 Embedding它是離散的,它沒有無窮無盡的可能,它只有 32 種可能而已
那其實像這樣子的技術啊如果你拿它 把它用在語音上,你就是一段聲音訊號輸進來,通過 Encoder 以後產生一個向量,接下來呢你去計算這個相似度,把最像的那個向量拿出來丟給 Decoder,再輸出一樣的聲音訊號,這個時候你會發現說你的 Codebook 啊可能可以學到最基本的發音部位
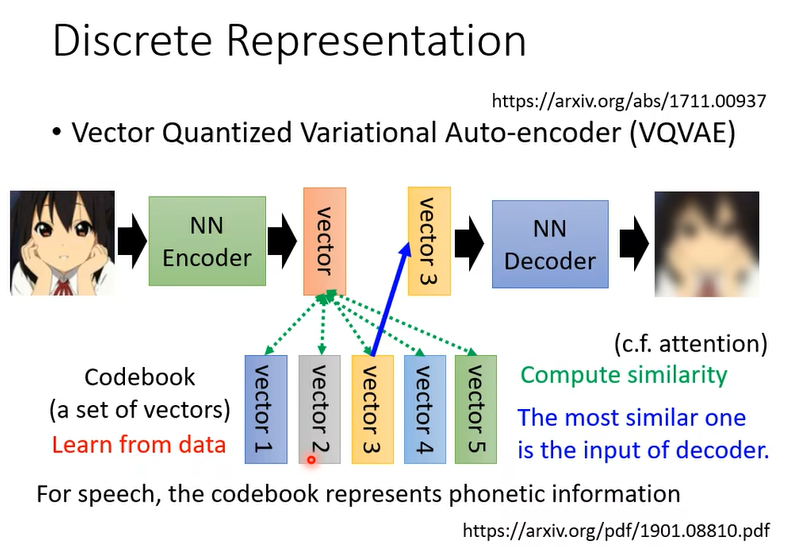
這個最基本的發音單位啊又叫做 Phonetic ,那如果你不知道 Phonetic 是什麼的話,你就把它想成是 KK 音標,這個 Codebook 裡面每一個 Vector它就對應到某一個發音,就對應到 KK 音標裡面的某一個符號。
那其實還有更多瘋狂的想法,Representation 一定要是向量嗎,能不能是別的東西,舉例來說它能不能是一段文字
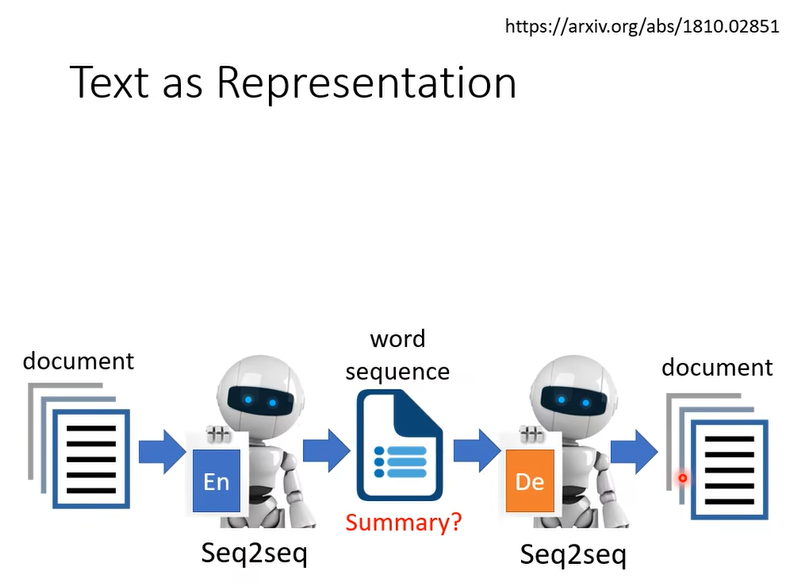
我們現在可不可以不要用向量來當做 Embedding,我們可不可以說我們的 Embedding就是一串文字呢,如果把 Embedding 變成一串文字有什麼好處呢,也許這串文字就是文章的摘要,因為你想想看把一篇文章丟到 Encoder 的裡面它輸出一串文字而這串文字可以通過 Decoder 還原回原來的文章,那代表說這段文字是這篇文章的精華
不過啊 輸入一串文字 輸出一串文字所以 Encoder 跟 Decoder顯然都必須要是一個 Seq2seq 的 Model,比如說 Transformer
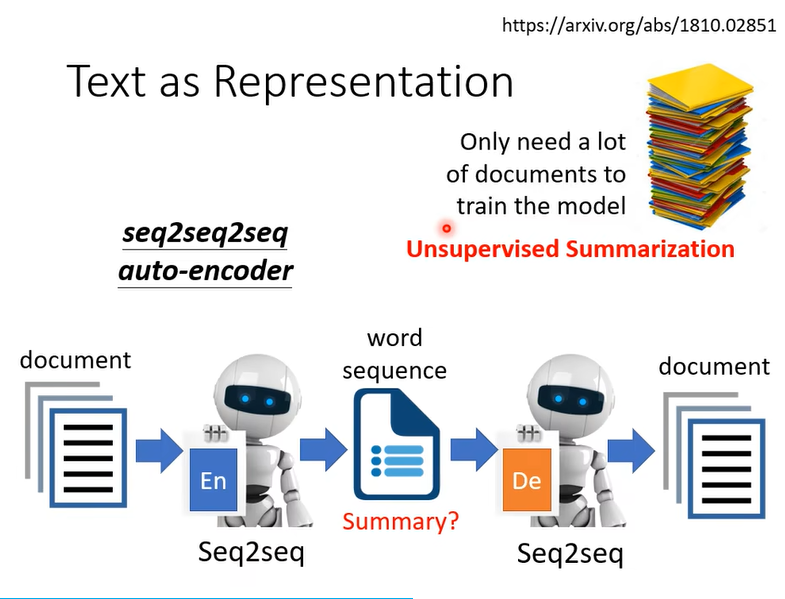
而這個 Auto-Encoder 大家訓練的時候不需要標註的資料,因為訓練 Auto-Encoder只需要蒐集大量沒有標註的資料
讓機器自動學會做unSupervised 的 Summarization,但是真的有這麼容易嗎
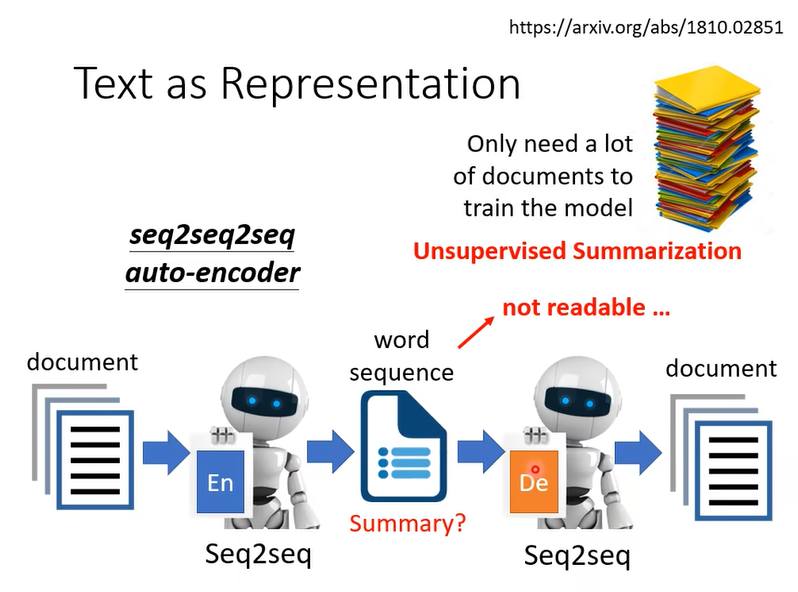
實際上這樣 Train 起來以後發現是行不通的,為什麼,因為這兩個 Encoder 跟 Decoder 之間會發明自己的暗號啊,所以它會產生一段文字那這段文字是你看不懂的文字,這 Decoder 可以看得懂,它還原得了原來的文章,但是人看不懂,所以它根本就不是一段摘要。
所以怎麼辦呢再用 GAN 的概念,加上一個 Discriminator,Discriminator 看過人寫的句子,所以它知道人寫的句子長什麼樣子
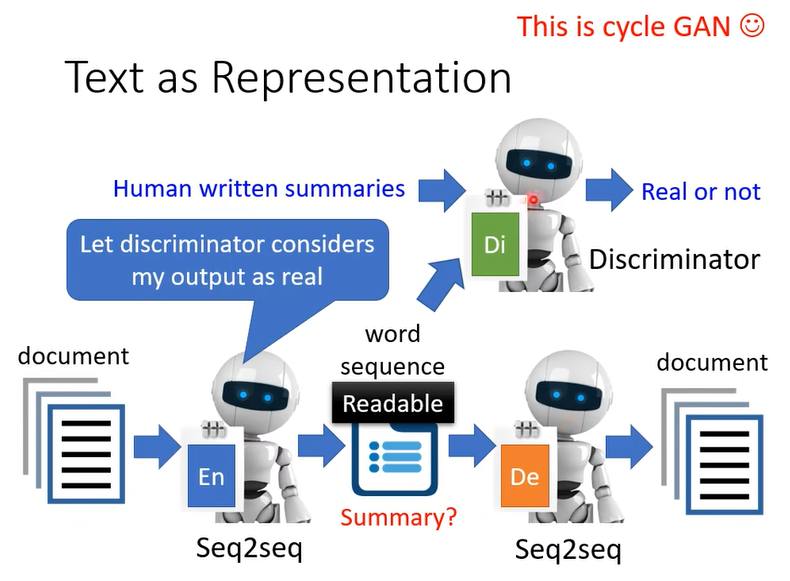 這個 Network 要怎麼 Train 啊,這個 encoder的 Output 是一串文字,那這個文字要怎麼接給 Discriminator 跟這個 Decoder 呢,告訴你看到你沒辦法 Train 的問題就用 RL 硬做,這樣這邊就是 RL 硬做就結束了這樣子
這個 Network 要怎麼 Train 啊,這個 encoder的 Output 是一串文字,那這個文字要怎麼接給 Discriminator 跟這個 Decoder 呢,告訴你看到你沒辦法 Train 的問題就用 RL 硬做,這樣這邊就是 RL 硬做就結束了這樣子
以下是真正 Network 輸出的結果,啦你給它讀一篇文章然後它就用 Aauto-Encoder 的方法,拿 300 萬篇文章做訓練以後

當然很多時候它也是會犯錯的
 所以這個例子只是想要告訴你說我們確實有可能拿一段文字來當做 Embedding。
所以這個例子只是想要告訴你說我們確實有可能拿一段文字來當做 Embedding。
其實還有更狂的,我還看過有拿 Tree Structure當做 Embedding
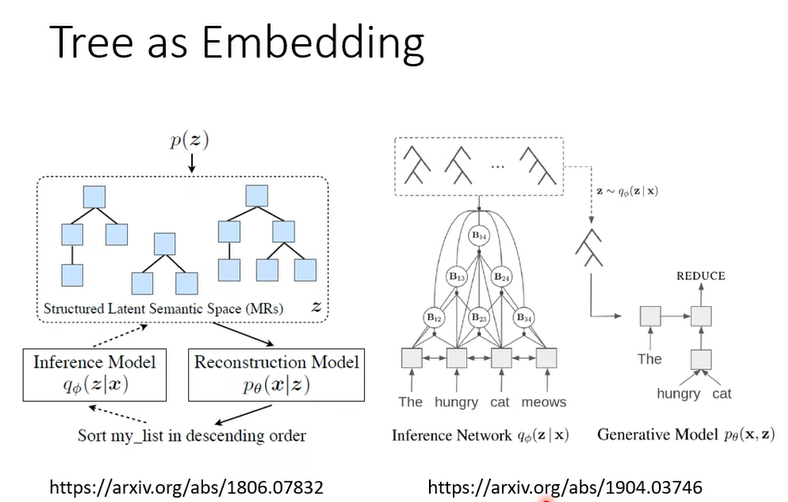 好 接下來啊還有 Aauto-Encoder 更多的應用
好 接下來啊還有 Aauto-Encoder 更多的應用
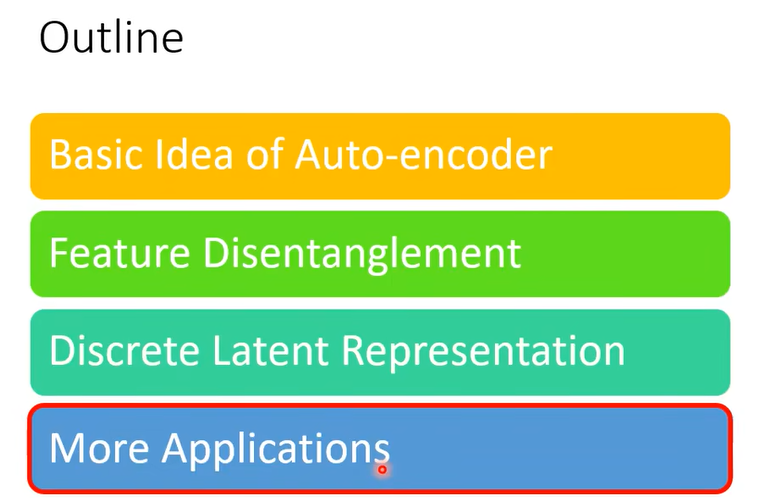
Aauto-Encoder 還可以拿來做些什麼事情呢,舉例來說我們剛才用的都是 Encoder,那其實 Decoder 也有作用,你把 Decoder 拿出來這不就是一個 Generator 嗎
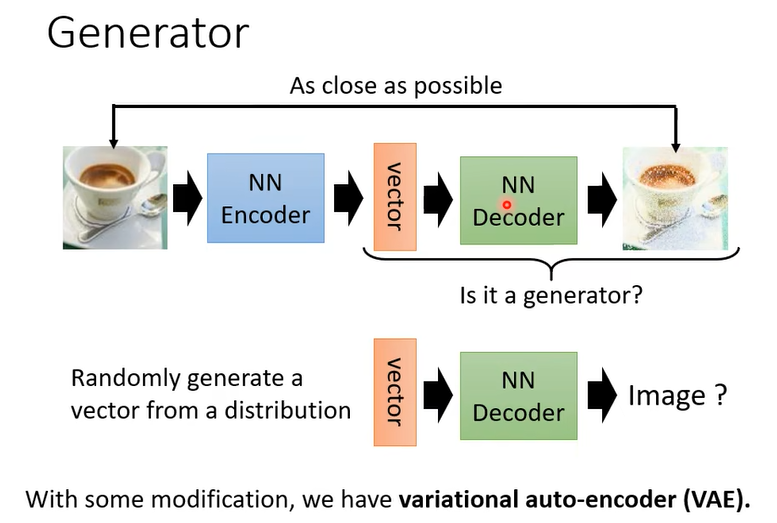
所以 Decoder你可以把它當做一個 Generator 來使用,你可以從一個已知的 Distribution比如說 Gaussian Distribution,Sample 一個向量丟給 Decoder,看看它能不能夠輸出一張圖。
事實上在我們之前在講這個 Generative Model 的時候其實有提到說除了 GAN 以外還有另外兩種 Generative 的 Model,其中一個就叫做 VAE,Variarional 的 Auto-Encoder,它其實就是把 Aauto-Encoder 的 Decoder 拿出來當做 Generator 來用,那實際上它還有做一些其他的事情啊,至於它實際上做了什麼其他的事情就留給大家自己研究,所以 Auto-Encoder Train 完以後
也順便得到了一個 Decoder。
Aauto-Encoder 可以拿來做壓縮,我們今天知道說你在做圖片,我們圖片如果太大的話也會有一些壓縮的方法比如說 JPEG 的壓縮,而 Aauto-Encoder 也可以拿來做壓縮,你完全可以把 Encoder 的輸出當做是一個壓縮的結果
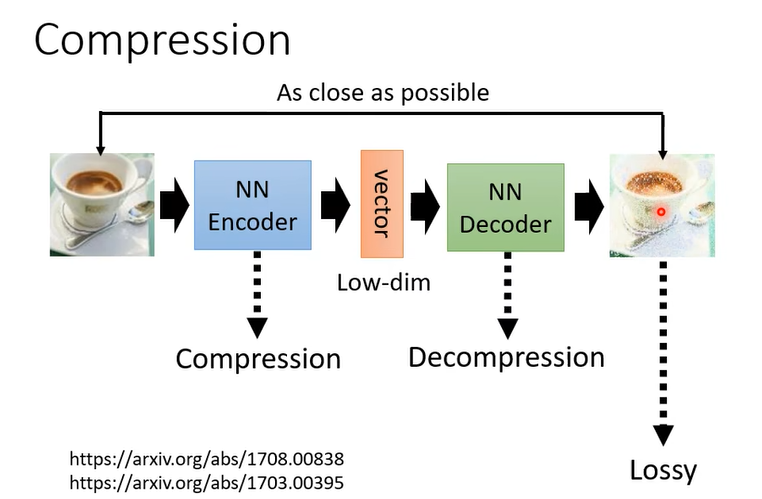
它是那種 lossy 的壓縮,所謂 lossy 的壓縮就是它會失真,因為在 Train Aauto-Encoder 的時候你沒有辦法 Train 到說輸入的圖片跟輸出的圖片100% 完全一模一樣啦,它還是會有一些差距的
那接下來就是我們在作業裡面要使用的技術,在作業裡面我們會拿 Aauto-Encoder來做 Anomaly 的 Detection(異常檢測)
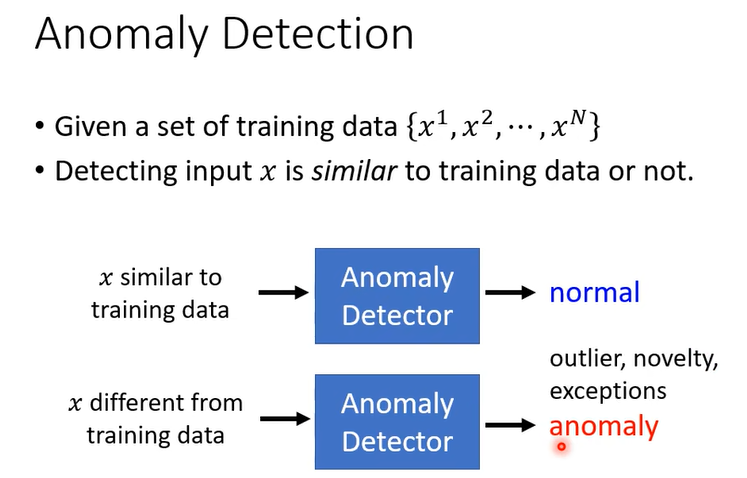
Anomaly 這個詞啊有很多不同的其他的稱呼, Outlier,Novelty,Exceptions但其實指的都是同樣的事情
但是所謂的相似這件事啊其實並沒有非常明確的定義,它是見仁見智的,會根據你的應用情境而有所不同

所以我們並不會說某一個東西它一定就是 Normal一定就是 Anomaly,它是正常或異常取決於你的訓練資料長什麼樣子

它可以來做詐欺偵測

假設你的訓練資料裡面有一大堆信用卡的交易紀錄,那我們可以想像說多數信用卡的交易都是正常的,那你拿這些正常的信用卡訓練的交易紀錄來訓練一個異常檢測的模型,那有一筆新的交易紀錄進來你就可以讓機器幫你判斷說這筆紀錄算是正常的 還是異常的
或者是它可以拿來做網路的這個侵入偵測,舉例來說你有很多連線的紀錄資料,那你相信多數人連到你的網站的時候他的行為都是正常的,多數人都是好人,你蒐集到一大堆正常的連線的紀錄,那接下來有一筆新的連線進來你可以根據過去正常的連線訓練出一個異常檢測的模型,看看新的連線它是正常的連線 還是異常的連線,它是有攻擊性的 還是正常的連線
或者是它在醫學上也可能有應用,你蒐集到一大堆正常細胞的資料拿來訓練一個異常檢測的模型,那也許看到一個新的細胞它可以知道這個細胞有沒有突變
那講到這邊有人可能會想說Anomaly Detection 異常檢測的問題
我們能不能夠把它當做二元分類的問題來看啊,你說你要做詐欺偵測,你就蒐集一大堆正常的信用卡紀錄一堆詐欺的信用卡紀錄訓練一個 Binary 的 Classifier就結束啦,就這樣子不是嗎
但是這種異常檢測的問題它的難點正在就在蒐資料上面,通常你比較有辦法蒐集到正常的資料你比較不容易蒐集到異常的資料,

所以在這一種異常檢測的問題裡面我們往往假設我們有一大堆正常的資料,但我們幾乎沒有異常的資料,所以它不是一個一般的分類的問題,這種分類的問題又叫做 One Class 的分類問題,就是我們只有一個類別的資料,那你怎麼訓練一個模型
因為你想你要訓練一個分類器你得有兩個類別的資料你才能訓練分類器啊,如果只有一個類別的資料那我們可以訓練什麼東西,這個時候就是 Aauto-Encoder可以派得上用場的時候了
舉例來說假設我們現在想要做一個系統,這個系統是要偵測說一張圖片它是不是真人的人臉
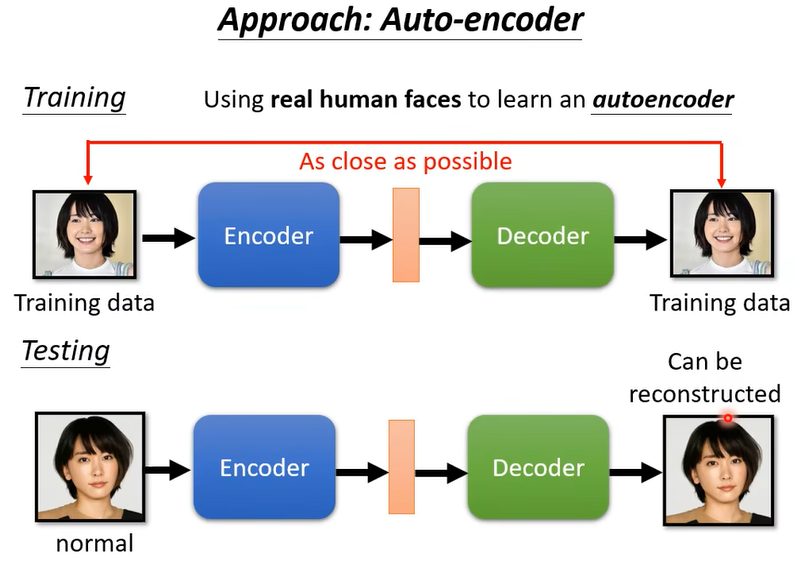
那因為在訓練的時候有看過這樣的照片,所以它可以順利地被還原回來。不過反過來說假設有一張照片是訓練的時候沒有看過的
,舉例來說不是真人是一個動畫的人物
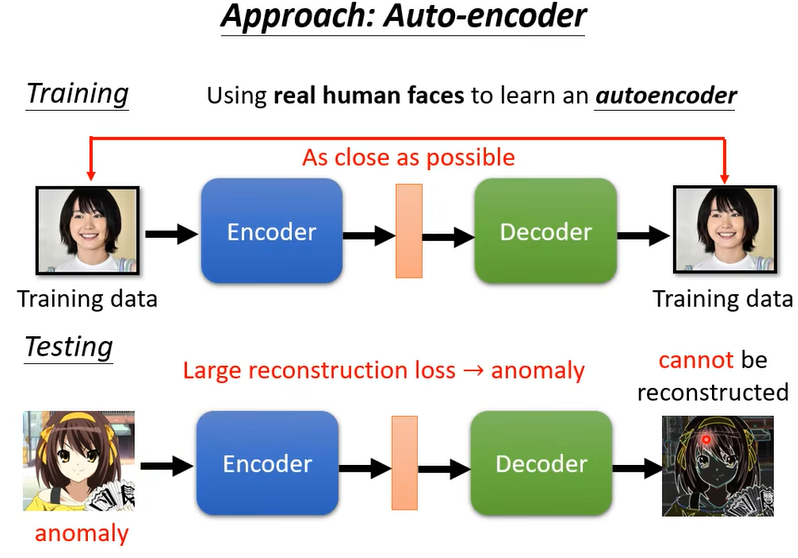
這是訓練的時候沒有看過的照片,那你的 Decoder就很難把它還原回來,如果你計算輸入跟輸出的差異,發現差異非常地大,那就代表說現在輸入給 Encoder 的這張照片可能是一個異常的狀況

那這個異常檢測啊其實也是另外一門學問,那我們課堂上就沒有時間講了,異常檢測不是只能用 Auto-Encoder 這個技術,Auto-Encoder 這個技術只是眾多可能方法裡面的其中一個
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Auto-encoder(自编码器)

发表评论 取消回复