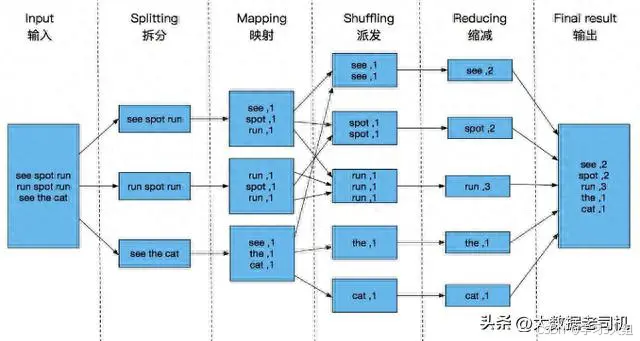
Spark和MapReduce都是处理大数据的工具,但在数据处理方式及速度上存在显著差异,以下进行详细对比:
Spark与MapReduce的主要差异点:
-
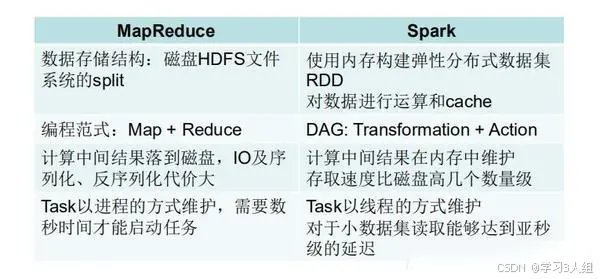
Spark是基于内存处理数据的,而MapReduce则是基于磁盘。MapReduce将中间结果保存在磁盘上,虽然减少了内存占用,但牺牲了计算效率。而Spark则将计算的中间结果保存在内存中,可以重复利用,从而提高数据处理效率。
-
Spark在数据处理过程中构建了DAG(有向无环图),有效减少了shuffle次数和数据落地磁盘的次数。其根本原因在于DAG计算模型,相较于MapReduce,它在大多数情况下都能减少数据交换次数。Spark的DAGScheduler类似于MapReduce的改进版,能在内存中一次性完成无需数据交换的操作,减少磁盘IO操作。然而,当计算涉及数据交换时,Spark也会将数据写入磁盘。
-
在资源申请方面,Spark采用粗粒度方式,而MapReduce则采用细粒度方式。粗粒度申请意味着Spark在提交任务时会提前向资源管理器申请所需资源,若资源不足则等待,资源充足则执行任务。而MapReduce则允许任务自行申请、使用和释放资源,虽然资源利用率高,但任务执行速度相对较慢。
Spark的优势主要表现在以下几个方面:
-
每个作业独立调度,Spark可以将多个作业整合为一个图进行调度,作业之间可以相互依赖,实现快速调度。
-
由于Spark的所有过程都基于内存进行,因此它也被视为基于内存的迭代式运算框架。
-
Spark提供了丰富的算子,使得数据处理操作更加便捷。
-
易于使用的API:支持Python、Scala和Java等多种编程语言。
尽管Spark内部也可以实现MapReduce的功能,但它并不仅仅是算法,而是提供了map阶段和reduce阶段的实现,并在这些阶段中集成了众多数据处理算法,如map、flatMap、filter、keyBy等map阶段操作,以及reduceByKey、sortByKey、mean、groupBy、sort等reduce阶段操作。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Spark和MapReduce场景应用和区别

发表评论 取消回复