目录
所以就只多了一步: 直接恍然大悟,豁然开朗,就犹如听君一席话,就是一句话
栈_队列_优先级队列
栈、队列相信大家肯定都不陌生,就是基本的数据结构,那么这一章主要就是对于这些基本数据结果的灵活使用,在哪些算法题内能够更好的,更快速的相当目前这一节的知识,来用上栈、队列可以更好的解决问题。有效的优化算法。
那么我们还是先来回顾一下栈、队列、和优先级队列的基础接口,方便我们后续快速操作,不用再回头重现查找。
栈:

可以看到一个class T模板参数:
stack<char> st;
stack<int> st;
常用接口:

哪个不熟点哪里:
empty:
st.empty(); //是空就返回true;非空返回false
size:
st.size(); //返回栈中元素个数
top:这个重点记忆
st.top(); //栈不同于队列,取栈顶元素就是取顶部元素,叫top;
push:
st.push( x ); //添加新元素入栈
pop:
st.pop(); //删除栈顶元素;
swap:
stack a , b;
a.swap(b); //交换两个栈内的元素
队列:

也同样是一个class T 模板参数;
常用接口:

跟stack大差不差,就要差别就是数据结构的功能不同,队列是先进先出
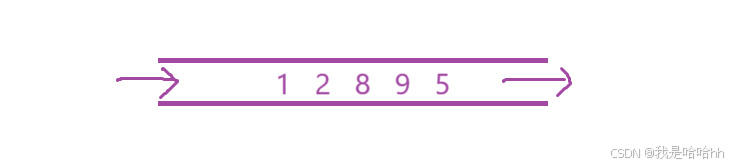
empty、size、push、pop、swap 都跟栈一个样,下面支队front 和 back进行比较
myqueue.push(77);
myqueue.push(16);
myqueue.front() -= myqueue.back(); // 77-16=61可以看出front就是队头的意思,back就是队尾的意思,分别可以取到对应的值;
优先级队列:
优先级队列,在这之前,我就写过一篇专门详解优先级队列的文章,还是十分推荐大家直接去了解的:一个题目带你了解优先级队列的全套知识和接口


唯一需要注意的就是,优先级队列这里是q.top()取队首元素
了解前奏知识后直接进入秒杀环节:
1. 删除字符中的所有相邻重复项(easy)

解析:
虽然我们这个专题是栈专题,但是像这种题目就是一眼要用栈来实现的,比如从题目意思出发,用暴力的办法来解决添加两个指针去便利这个数组,然后遇到相邻且相同的字符就进行删除,那么还要进行移动元素,这样算下来时间复杂度得O(N^2)肯定会超时,所以要借助一个容器来完成删除和移动元素的操作。
就要想借助一个什么样的容器能够实现一个元素被添加后只用和上一个添加的元素进行比较,其实这里就已经可以想到只有stack、vector两个容器可以实现,但是每次vector添加新元素后还要记录下标,有点繁琐,直接就用栈实现就好啦。
实现思路:
每次只用判断在遍历到当前字符之前,栈顶里面存入的字符和我当前的字符是否相等,如果是相等的,就说明栈顶的元素跟我当前的字符又相邻又重复,满足要被删除的条件。否则就直接入栈就好啦。
最后就进行出栈,然后添加到一个新的字符串内。但是注意此时的字符串是倒转过后的字符串,要进行反转后返回。
class Solution {
public:
string removeDuplicates(string s) {
stack<char> st;
int n=s.size();
string ret;
for(int i=0;i<n;i++)
{
if(!st.empty()&&s[i]==st.top())
{
st.pop();
continue;
}
st.push(s[i]);
}
while(!st.empty())
{
ret+=st.top();
st.pop();
}
reverse(ret.begin(),ret.end());
return ret;
}
};总结:
虽然第一个题目比较简单,但是是掌握的熟练一点比较好,对于栈和队列的使用能想到什么时候派上用场就能解决很多暴力麻烦的问题。
2. ⽐较含退格的字符串(easy)

解析:
读完题目后发现,这题简直就是跟上一题一模一样,只是换了个说法,换汤不换药直接ac掉。
仍然是要比较当遇到字符‘#’的时候进行删除上一个字符,为了不进行元素的移动,那么我就要做到边遍历,边删除元素。那么用栈就是最合适的,因为我只用在乎当前元素和上一个添加进入的元素,并且如果上一个添加的元素被删除后,上上一个被添加进去的元素就要成为我的栈顶,是最完美的选择。
算法思路:
就是创建两个栈st1 和 st2 然后对齐字符串s 和 t 分别进行遍历,添加到栈内,一旦遇到字符‘#’就要删除上一个被添加到的字符,所以这里就是要注意的是,先判断,后添加。
细节问题:就是当遇到‘#’ 并且栈为空要特判一下,continue当前位置,进入下一个循环。
最后就是判断两个栈内剩余的字符是否完全相等即可。
class Solution {
public:
bool backspaceCompare(string s, string t) {
stack<char> st1,st2;
int n=s.size(),m=t.size();
for(int i=0;i<n;i++)
{
if(s[i]=='#'&&!st1.empty()) st1.pop();
else if(s[i]=='#'&&st1.empty()) continue;
else st1.push(s[i]);
}
for(int i=0;i<m;i++)
{
if(t[i]=='#'&&!st2.empty()) st2.pop();
else if(t[i]=='#'&&st2.empty()) continue;
else st2.push(t[i]);
}
string a,b;
while(!st1.empty())
{
a+=st1.top();
st1.pop();
}
while(!st2.empty())
{
b+=st2.top();
st2.pop();
}
if(a==b) return true;
cout<<a<<" "<<b<<endl;
return false;
}
};总结:
题目并不难,主要是要学会总结,理解题目要求后,不要急于写代码,只需要搞懂题目意思然后理清思路和解题方法在进行书写。
3. 基本计算器 II(medium)

解析:
解法一:利用双栈实现将所有数字都转换成+法存入st1内。
其实本来开始的时候我一直都想采用逆波兰表达式的办法,但是写了一个多小时,实在忘记中缀怎么转后缀了,没办法,只能用普通的简便办法来实现。但是我肯定不会放弃的,等会我一定会把逆波兰表达式的解法补上去,如果我补上来了,说明我已经学会了,两种办法来解决这道题。
我离成功就差那么一点点,只差a-b,a/b 将所有运算符存入st2 的时候老是报错,运算顺序一直装都是反的,所以最终还是放弃了,采用这种写法:
算法思路:
模拟计算过程:
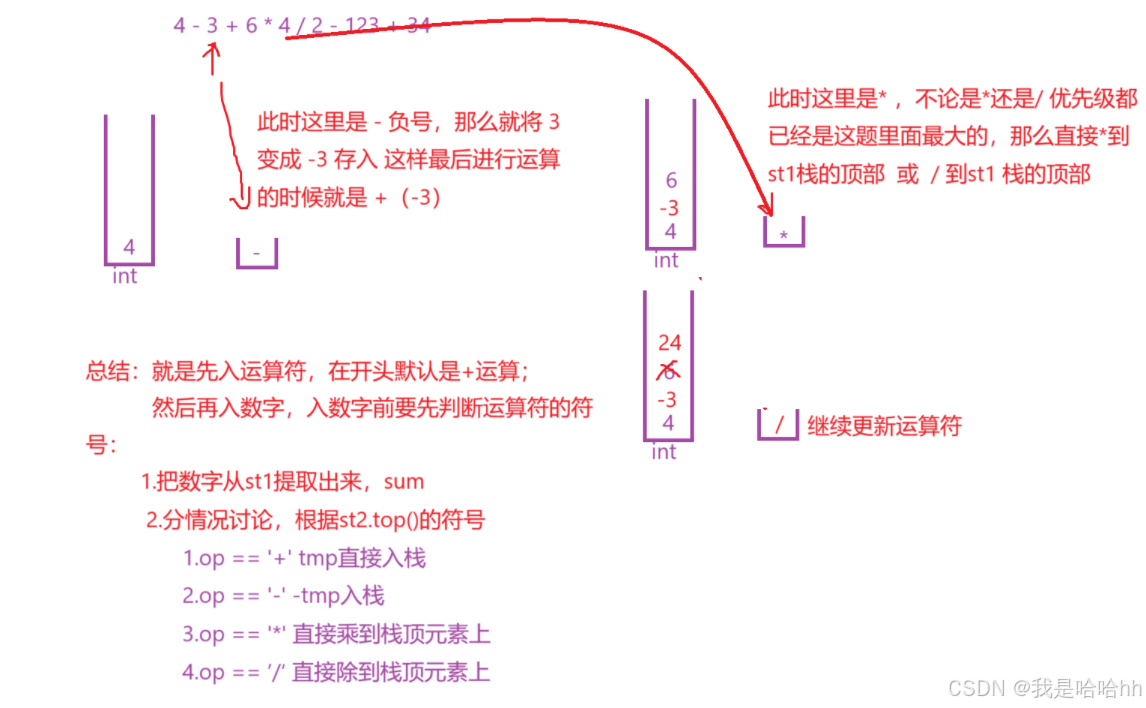
总结:就是先入运算符,在开头默认是+运算;
然后再入数字,入数字前要先判断运算符的符号:
1.把数字从st1提取出来,sum
2.分情况讨论,根据st2.top()的符号
1.op == '+' tmp直接入栈
2.op == '-' -tmp入栈
3.op == '*' 直接乘到栈顶元素上
4.op == ’/‘ 直接除到栈顶元素上
精简版:
class Solution {
public:
int calculate(string _s) {
stack<int> st1;
stack<char> st2;
string s;
for(auto e : _s) if(e!=' ') s+=e;
//判断运算符优先级
for(int i=0;i<s.size();)
{
if(s[i]>='0'&&s[i]<='9')
{
int j=0;
int sum=0;
while(s[i]>='0'&&s[i]<='9')
{
sum*=10;
sum+=s[i++]-'0';
}
if(!st2.empty()&&st2.top()=='-') st1.push(-sum);
else if(!st2.empty()&&st2.top()=='+') st1.push(sum);
else if(st2.empty()) st1.push(sum);
else if(st2.top()=='*')
{
int a=st1.top();
st1.pop();
st1.push(a*sum);
}
else
{
int a=st1.top();
st1.pop();
st1.push(a/sum);
}
}
else
{
if(st2.empty()) st2.push(s[i]);
else st2.pop(),st2.push(s[i]);
i++;
}
int num=0;
while(!st1.empty())
{
num+=st1.top();
st1.pop();
}
return num;
}
};
抓破脑袋版:
class Solution {
public:
int calculate(string _s) {
stack<int> st1;
stack<char> st2;
string s;
for(auto e : _s) if(e!=' ') s+=e;
//判断运算符优先级
for(int i=0;i<s.size();)
{
if(s[i]>='0'&&s[i]<='9')
{
int j=0;
int sum=0;
while(s[i]>='0'&&s[i]<='9')
{
sum*=10;
sum+=s[i++]-'0';
}
if(!st2.empty()&&st2.top()=='-') st1.push(-sum);
else if(!st2.empty()&&st2.top()=='+') st1.push(sum);
else if(st2.empty()) st1.push(sum);
else if(st2.top()=='*')
{
int a=st1.top();
st1.pop();
st1.push(a*sum);
}
else
{
int a=st1.top();
st1.pop();
st1.push(a/sum);
}
}
else
{
if(st2.empty()) st2.push(s[i]);
else st2.pop(),st2.push(s[i]);
i++;
}
// else
// {
// if(s[i]=='+') st2.push(s[i]);
// if(st2.empty()||priority(s[i],st2.top())) st2.push(s[i]);
// else
// {
// int a=st1.top();
// st1.pop();
// int b=st1.top();
// st1.pop();
// st1.push(operation(a,b,st2.top()));
// st2.pop();
// st2.push(s[i]);
// }
// i++;
// }
}
int num=0;
while(!st1.empty())
{
num+=st1.top();
st1.pop();
}
// //最后进行清空st1
// int n=st2.size();
// for(int i=0;i<n;i++)
// {
// int a=st1.top();
// st1.pop();
// int b=st1.top();
// st1.pop();
// st1.push(operation(a,b,st2.top()));
// st2.pop();
// }
// int m=st1.size();
// if(m==1)
// return st1.top();
// int num=0;
// for(int i=0;i<m;i++)
// {
// num+=st1.top()*pow(10,i);
// st1.pop();
// }
return num;
}
int operation(int a, int b, char x)
{
int ret = 0;
if (x == '+') ret = a + b;
else if (x == '-') ret = a - b;
else if (x == '*') ret = a * b;
else ret = b / a;
return ret;
}
bool priority(char x,char y)
{
unordered_map<char,int> hash;
hash['-']=1;
hash['+']=1;
hash['*']=2;
hash['/']=2;
return (hash[x]-hash[y])>=0;
}
};解法二:逆波兰表达式
这种办法也是最原始,最好用,最常用的求解表达式方面计算的办法,先把中缀表达式转换成后缀表达式,然后对后缀表达式进行两个栈的运算得到结果,这种情况会考虑到存在括号的优先级的问题:
后期补上;
总结:
这题真的非常建议手敲多变,深刻理解这题算法,相信我就算是画整整半天时间学习这个算法也不亏,主要是真的理解了,就赚到了。
4. 字符串解码(medium)

解析:

算法原理:
解析后继续检查int栈,如果里面仍然存在数字就说明char栈内仍然存在 '['左括号,说明继续往后遍历还会有 ‘]’ 右括号。
因为char栈内再栈底部还会有'[' 这样会让已经被解析的字符加入到char栈内后,继续被重复解析倘若int栈内没有数字,说明char内不会存在‘[’左括号,就可以直接继续往后遍历

原本我是将所有被解析后的字符全部存入char栈内,不管后面还有没有左括号,但是后续经过优化,可以看到,如果后续没有左括号,就不需要再加入char栈内,直接将已经解析好的字符串加入到_ret内即可。
细节问题:
唯一需要注意的就是,再添加到int栈内的时候,就是要单独判断,当前的数字是不是大于10,如果大于10,就说明不是一个字符,是由多个字符组成的的一个大于10的数字:
int sum=0;
while(s[i]>='0'&&s[i]<='9')
{
sum*=10;
sum+=s[i++]-'0';
}
in.push(sum);
那么对于i的计数就要单独进行判断,不能一味的进行i++,单独再每次判断结束后进行i++;
class Solution {
public:
string decodeString(string s) {
int n = s.size();
stack<char> st;
stack<int> in;
string _ret;
for (int i = 0; i < n; )
{
if (s[i] >= '0' && s[i] <= '9')
{
int sum=0;
while(s[i]>='0'&&s[i]<='9')
{
sum*=10;
sum+=s[i++]-'0';
}
in.push(sum);
}
else if (s[i] == ']')
{
string ret;
while (st.top() != '[')
{
ret += st.top();
st.pop();
}
st.pop();
reverse(ret.begin(), ret.end());
int a = in.top();
in.pop();
string end;
for (int i = 0; i < a; i++) end += ret;
if(in.size()!=0)
{
int _size = end.size();
for (int i = 0; i < _size; i++)
{
st.push(end[i]);
}
}
else
{
_ret+=end;
cout<<_ret<<endl;
}
i++;
}
else if(!in.empty())
{
st.push(s[i++]);
}
else _ret+=s[i++];
}
int m = st.size();
string s_;
for (int i = 0; i <m; i++)
{
s_+= st.top();
st.pop();
}
reverse(s_.begin(), s_.end());
_ret+=s_;
return _ret;
}
};总结:
写多了就会发现,这种关于配对的问题,都是用栈来解决,只需要通过配对的思路一步一步的走,肯定就没有问题的。
5. 验证栈序列(medium)

解析:
相信大家在学习数据结构的还是一定遇到过这种问题,判断一个栈序列的合法性。
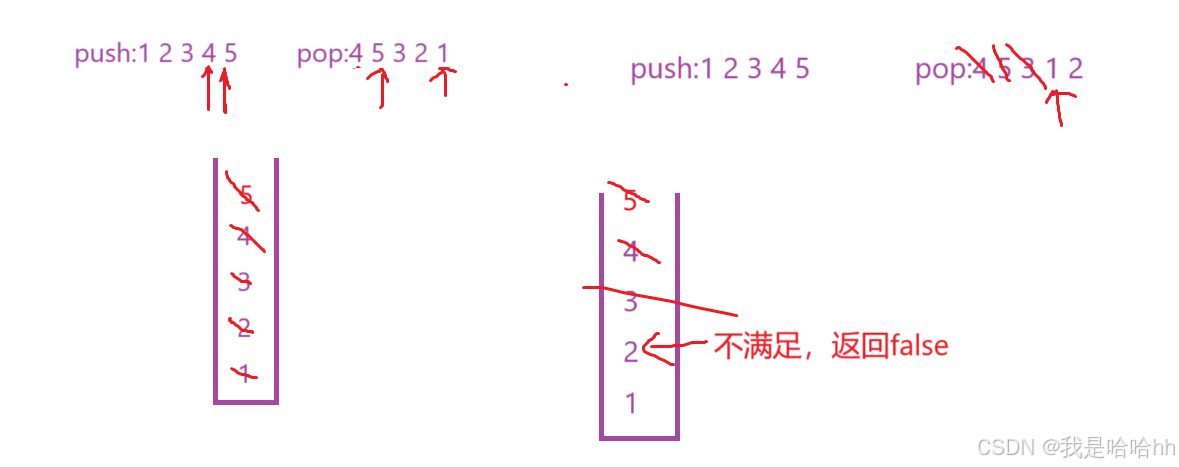
那么再实际遍历的过程就是要让push的元素不同的入栈,直到有跟pop相同的元素就开始进行出栈,但是这里就是要一直进行出栈,直到再次不满足条件为止。让后用计数器i来记录当前已经pop了多少个元素,直到i==n-1 将所有的元素全部都pop完为止。
细节问题:出栈的时候一定要保证栈内有元素,这样就不会出现越界访问的情况。
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
int i=0;
stack<int> st;
int n=pushed.size();
for(auto e : pushed)
{
st.push(e);
while(!st.empty()&&st.top()==popped[i])
{
st.pop();
i++;
}
}
return i==n;
}
};总结:
这题很简单,但是还是要多加联系,做到看题目就能想到解法,还是要熟能生巧才行。
后面就是,队列 + 宽搜(BFS)的小专题:
6. N 叉树的层序遍历(medium)
解析:
学过数据结构,了解到队列肯定知道,队列不会说单独来出某一个算法题,而是某个算法内的一小步,而BFS层序遍历,就正好要用到队列,只有队列先进先出的原则,可以满足只有进入一个节点,然后当该节点出去的时候,就将该节点的所有字节进行加入即可。
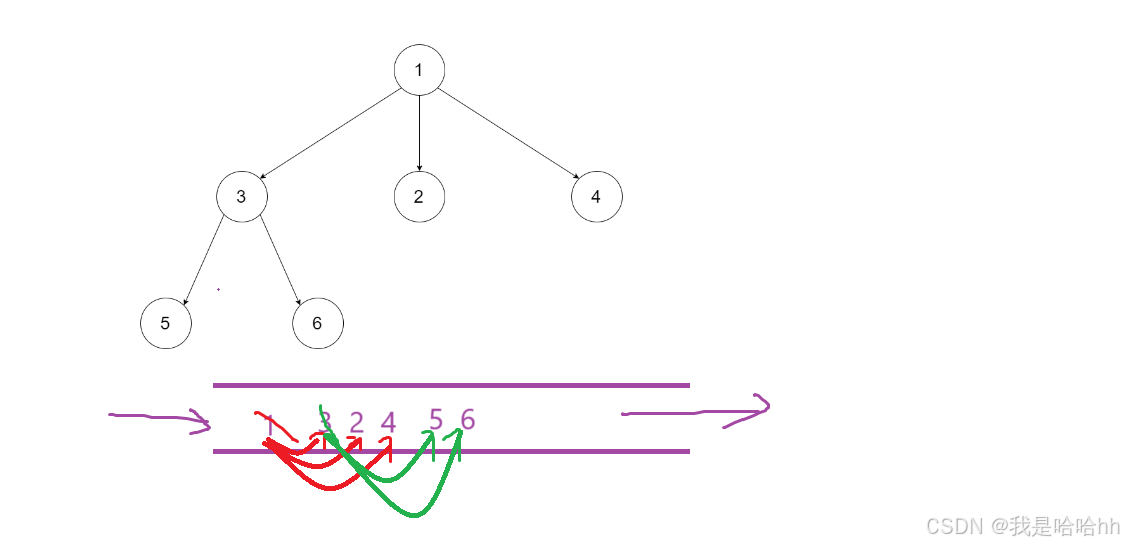
细节问题:
就是什么时候要注意是一层已经被出完了,存入tmp数组内,然后再添加到ret内,那么这里就要进行计数,在每次准备出一层或已经出完一层的节点时就要统计当时队列的节点数,那么这些节点数就是当前层的节点个数。
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
queue<Node*> q;
vector<vector<int>> ret;
vector<vector<int>> levelOrder(Node* root) {
if(root==nullptr) return ret;
q.push(root);
while(q.size())
{
int sz=q.size();
vector<int> tmp;
for(int i=0;i<sz;i++)
{
Node* t=q.front();
q.pop();
tmp.push_back(t->val);
for(auto e : t->children)
if(e) q.push(e);
}
ret.push_back(tmp);
}
return ret;
}
};总结:
像这种比较经典的入门题就应该牢牢的记住它,倒背如流,上手就能写,加油!
7. ⼆叉树的锯⻮形层序遍历(medium)
题目意思很简单,就是第一层从左往右遍历,第二层从右往左遍历,跟上一题大差不差。
解析:
虽然是标了一个中等题,但是跟上一题简直就是一模一样,就只多了一个步骤:
算法原理:
看这道题,还是要进行层序遍历
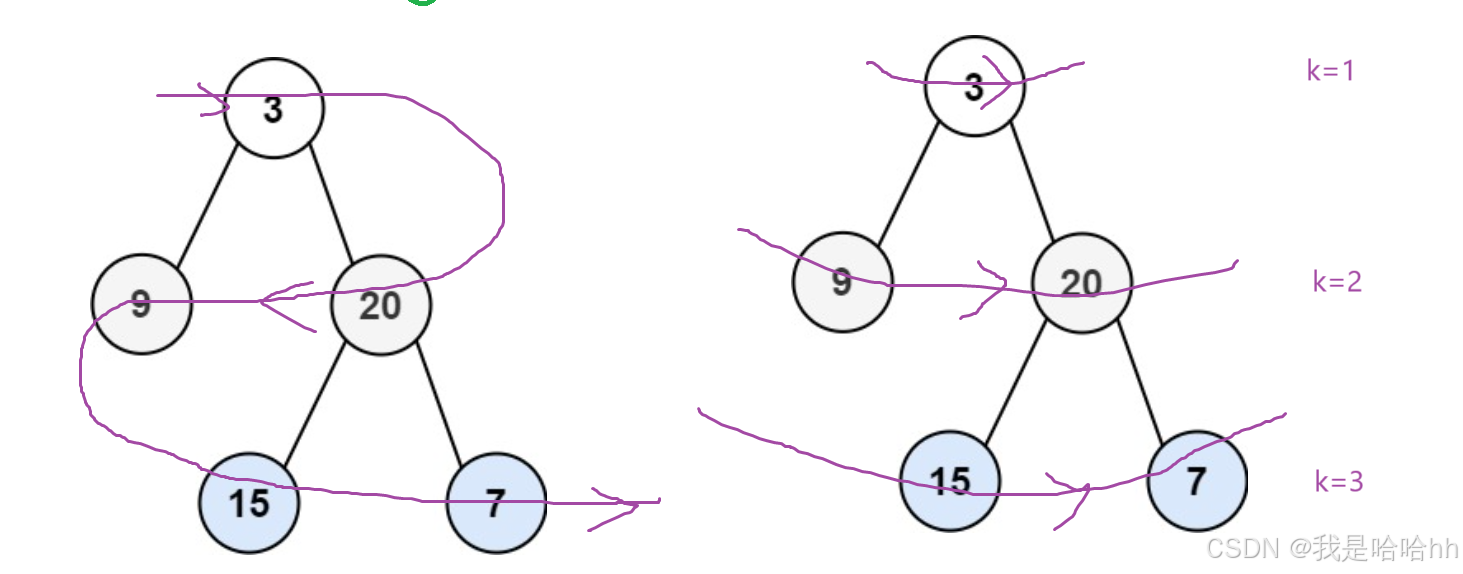
那么如图就是两个层序遍历的比较,那么这时我们就可以发现,他们的唯一区别就是再层数k是偶数层的时候进行反转,那么我就想到是不是可以想上一题一样进行简单的层序遍历,然后用k来记录我当前的层数,只要满足当前层是偶数层那么就进行反转。
所以就只多了一步: 直接恍然大悟,豁然开朗,就犹如听君一席话,就是一句话
if(k%2==0) reverse(tmp.begin(),tmp.end());
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {
queue<TreeNode*> q;
vector<vector<int>> ret;
if(root==nullptr) return ret;
q.push(root);
int k=1;
while(q.size())
{
int sz=q.size();
vector<int> tmp;
for(int i=0;i<sz;i++)
{
TreeNode* t=q.front();
q.pop();
if(t->left) q.push(t->left);
if(t->right) q.push(t->right);
tmp.push_back(t->val);
}
if(k%2==0) reverse(tmp.begin(),tmp.end());
k++;
ret.push_back(tmp);
}
return ret;
}
};总结:
这题主要考察自己的反应能力,大家都知道这题肯定是要用层序遍历用队列来完成,那么唯一的思路就是要记录应该反转的层数,当前层就进行反转。
8. ⼆叉树的最⼤宽度(medium)
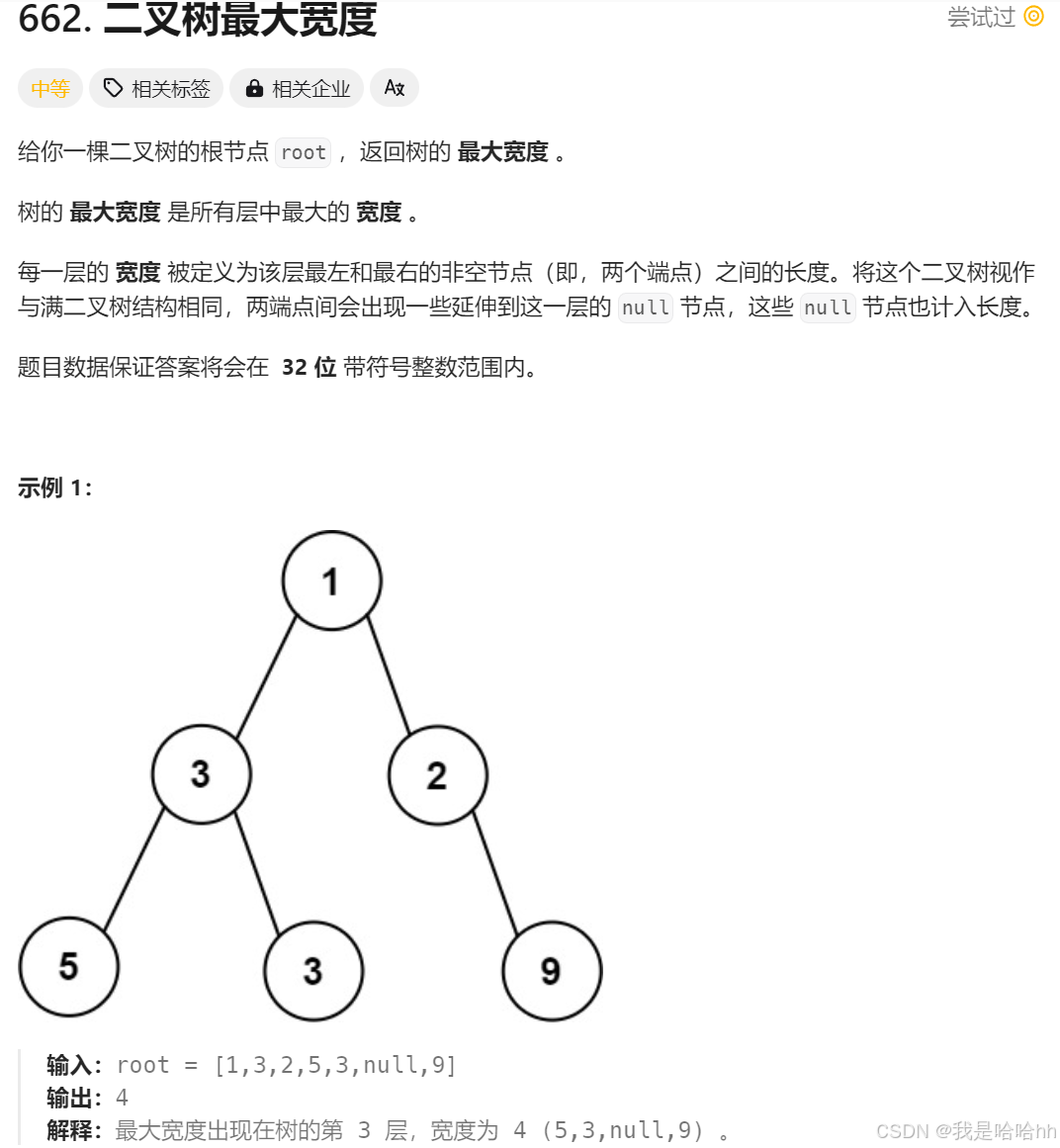
解析:
看到题目就是要说关于求每一层两个节点之间的最大宽度,两个节点存在空节点也要补上。那么就说明如果每一层直接暴力遍历的话,一定空间超出,还会超时:
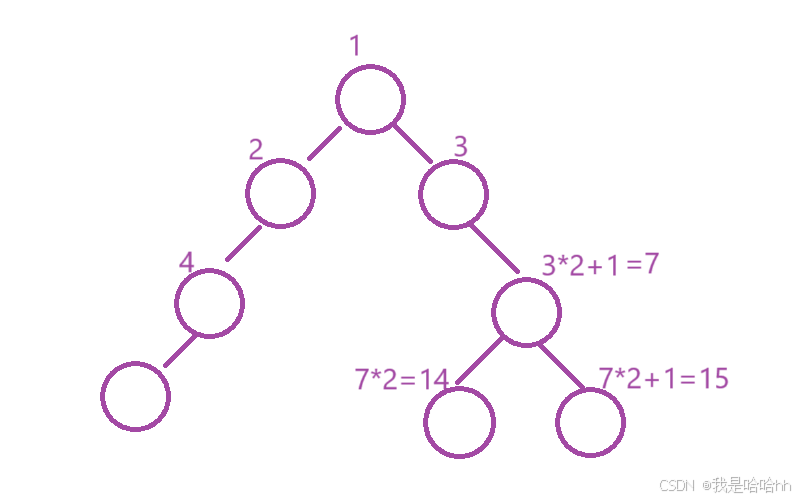
那么就要想题目只是要我们救出两个节点之间的最大宽度,那就只用对下标下手呀,只用求出每一层最左的节点和最右的节点存入一个新的队列,因为只有这样,每次添加完一层新的队列,最右边的元素一定是最后添加的,就是qq.back()再队列的尾部,而头上的元素就是最左边的元素qq.front()就是这一层最左边的元素。然后二者相减即可。
ret=max(ret,qq.back()-qq.front()+1);
细节问题:
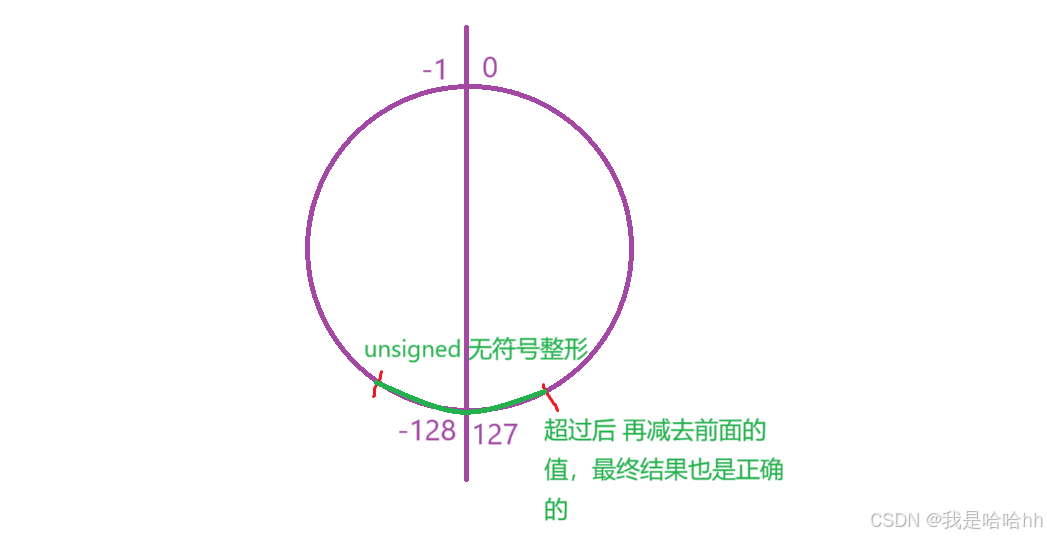
另外,如果是按照题目3000个节点,左右都是1500个,那么数据绝对会暴,用int double long 都是存不下去的,但是题目说是题目数据保证答案将会在 32 位 带符号整数范围内。 就说明如果按照无符号的要求来存取数据,哪怕数据暴了,但是相减后也是不会出现问题的,因为相减后还是正确的答案。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int widthOfBinaryTree(TreeNode* root) {
queue<TreeNode*> q;
queue<unsigned> qq;
unsigned ret=0;
if(root==nullptr) return 0;
q.push(root);
qq.push(1);
while(q.size())
{
int sz=q.size();
ret=max(ret,qq.back()-qq.front()+1);
for(int i=0;i<sz;i++)
{
TreeNode* t=q.front();
q.pop();
unsigned k=qq.front();
qq.pop();
if(t->left)
{
q.push(t->left);
qq.push(k*2);
}
if(t->right)
{
q.push(t->right);
qq.push(k*2+1);
}
}
}
return ret;
}
};总结:
对于这题有一个小优化,就是要想到利用下标去求解,因为如果光只是暴力的添加空节点是一定会超时的,再就是注意无符号整形就算是爆数据了,相减也是正确的结果。
9. 在每个树⾏中找最⼤值(medium)
这题是真简单,就是返回每一行里面的最大值
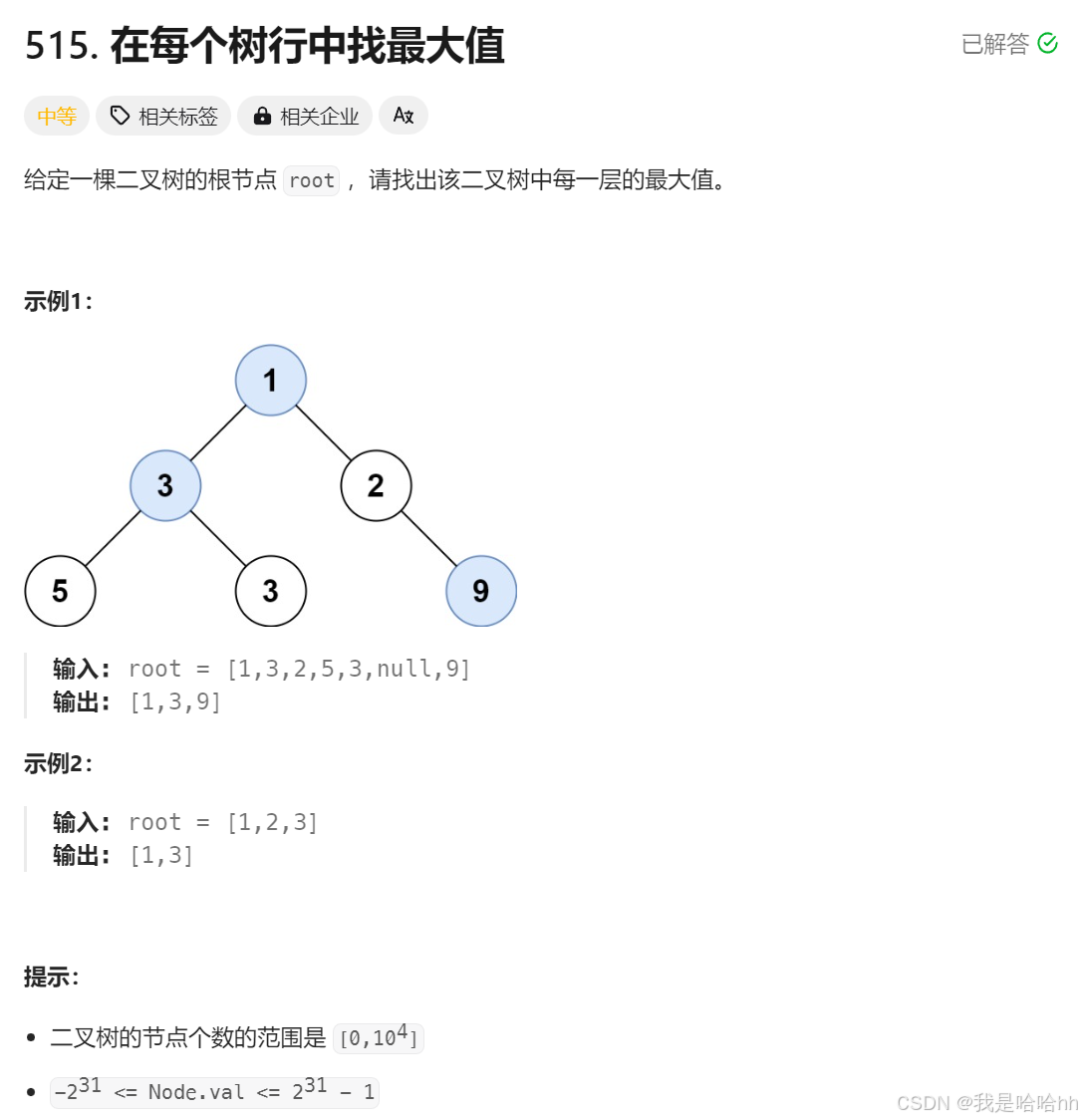
解析:
题目意思是跟每一行有关,就是要遍历每一行,然后求出每一行的最大值,那么可想而知,就是遍历每一行,然后对每一行的节点的值进行比较,那么就要采用层序遍历的方式,用队列结构进行每次出节点的时候就都将子节点带上,遍历当层每一个节点的时候就进行比较判单,只留下当前层的最大值即可。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> largestValues(TreeNode* root) {
queue<TreeNode*> q;
vector<int> ret;
if(root==nullptr) return ret;
q.push(root);
while(q.size())
{
int sum=q.front()->val;
int sz=q.size();
for(int i=0;i<sz;i++)
{
TreeNode* t=q.front();
q.pop();
sum=max(sum,t->val);
if(t->left) q.push(t->left);
if(t->right) q.push(t->right);
}
ret.push_back(sum);
}
return ret;
}
};总结:
做到这里,上面的bfs就足够秒杀这题了,加油!~
10. 最后⼀块⽯头的重量(easy)
这是一道简单的模拟题,只需要知道两个石头相撞,然后剩下最后一块石头的最后的质量返回即可

解析:
最开始我以为就是简单的两个石头相撞,取差值就可以了,可是最后的结果并不是:
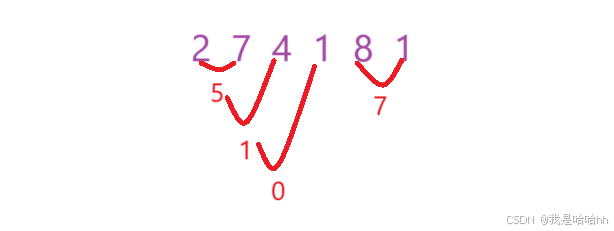
但是最终的结果并不是,这样,要按照排序的大小,每次都把最大的石头进行碰撞才是正确的结果:
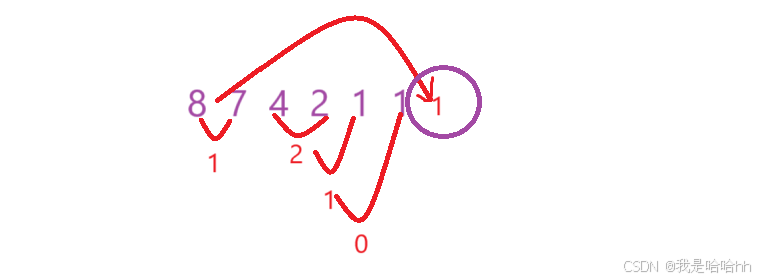
由图可以看出,每次都将最大的两个数字进行相减能得到最后正确的结果;
那么就要想办法对这个数组进行排序,如果每次都相减完后,将相减的结果放入数组重新排列整个数组也太过于麻烦,其实我们只需要调整这一个被添加进来的数字的位置,因为其他的数字都是有序的,所有可以采用插入法,或堆排序,那么插入法是O(N) 而堆排序只跟树的高度有关,所以时间复杂度最优,那么就可以才用堆排序;也就是优先级队列,每次都将最大的元素放在对头
class Solution {
public:
int lastStoneWeight(vector<int>& stones) {
priority_queue<int> q;
for(auto e : stones) q.push(e);
while(q.size()>1)
{
int a=q.top();
q.pop();
int b=q.top();
q.pop();
int c=abs(a-b);
q.push(c);
}
return q.top();
}
};总结:
从暴力到优化的思考过程必不可少,谁也不知道上来就用什么容器来实现,一步一步走一定可以实现的。
11. 数据流中的第 K ⼤元素(easy)
读完题目还是很好理解的,就是每次再完成添加一个数字后,整个数组里面的第K大的数字

解析:
很经典的topK问题,用堆或者快速选择算法来实现!
解法一:
只是将所有的元素都进行存入priority_queue<int> q;内,然后每次进行删除k-1一个元素最后这个q的堆顶就是剩下的第K大的元素,很好理解;
但是这样就有一个弊端,不管新加入的元素会不会影响我这个第K大的元素,我都要进行重新排序,在数据量极大的时候,我的空间复杂度暴增,那么要将一个数字存入q内,并且每次都要进行重复的操作,就是删除前k-1个数字,取k大的顶部数字,这样很繁琐,每一次都在经过相同的操作。时间复杂度暴增,最后就是超时。
class KthLargest {
public:
priority_queue<int> q;
int k;
KthLargest(int _k, vector<int>& nums) {
for(auto e : nums) q.push(e);
k=_k;
}
int add(int val) {
q.push(val);
priority_queue<int> _q=q;
for(int i=0;i<k-1;i++) _q.pop();
return _q.top();
}
};
/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest* obj = new KthLargest(k, nums);
* int param_1 = obj->add(val);
*/解法二:
求第K大问题,向上面就是大根堆,那么堆顶全是最大的数字,那么反过来想,如果我用小根堆,那么堆顶全是最小的数字,而堆底的大数字往下沉,如果位置设置这个堆的大小是k,就是容易只为k,那么不管我怎么添加数字,只有前k大的数字能够留下来,就是第K大的数字就是k个数字里面最小的一个数,那么每次返回值的时候就直接返回堆顶即可。
class KthLargest {
public:
priority_queue<int,vector<int>,greater<int>> q;
int k;
KthLargest(int _k, vector<int>& nums) {
for(auto e : nums)
{
q.push(e);
if(q.size()>_k) q.pop();
}
k=_k;
}
int add(int val) {
q.push(val);
if(q.size()>k) q.pop();
return q.top();
}
};
/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest* obj = new KthLargest(k, nums);
* int param_1 = obj->add(val);
*/总结:
要记住!topK问题只将堆的容量设置为k,没有必要浪费其他空间,一定要记住,不然空间复杂度和时间复杂度都要变大。
12. 前 K 个⾼频单词 (medium)

解析:
这题是一道很经典的priority_queue<> 堆 和 unordered_map<>哈希表 结合的题目,一定要弄懂吃透。
解法一:
首先要求出每个单词出现的次数,才能进一步求解最高次数下代表的单词是什么,那么就会最先想到hash表 hash<stirng,int> : hash[string] ++;

得到所对应的字符串跟次数后就要考虑下一步,按照次数来排序,但是map<string,int> hash;又是按照键值对的first来排序的,那么我就要考虑,是不是要重新创建一个hash表
map<int,string> hash1;按照int,即出现的次数来进行排序,这样就能得到出现次数最多的字符串。
但是问题又来了,如果这样存,那么又要考虑遇到次数想等的字符串怎么办,又要单独判断题目的字典序,这样一想实在太麻烦,根本实现不了。
解法二:在解法一上做优化:
那么就要考虑有没有容器,能够实现,将hash<string,int> 里面的内容按照int进行排序,然后在返回给我,在所有学到的能排序的容器有:map<>、set<>、priority_queue<>
经过解法一可以看出再用一个map已经不可能了,set更不可能,那么就只剩priority_queue<>这个容器进行排序了,正好这个优先级队列的容器可以实现改变第三个参数,返回的类型,按照你想要进行比较的大小进行返回,来构成大小堆:

在最开始我只是设置了func的比较函数,但是这是不合法的,必须要进行返回类型才可以,即:
struct func
{
bool operator()(const pair<string, int>& a, const pair<string, int>& b)
{
if(a.second == b.second) return a.first < b.first;
return a.second > b.second;
}
};构成小根堆,实现容量大小只为k的优先级队列,这样不会造成多余的空间浪费,堆内只保留了出现次数最多的单词沉底。这样出现单词次数最多的就一直在堆底不会被删除。
构建堆的参数:按照int出现的次数来进行比较。
priority_queue<pair<string, int>, vector<pair<string, int>>, func> q;
细节问题:
因为要构成字典序列,那么就当二者出现次数想等的时候返回顺序较小的就是true;
当容量为K的小根堆构建完成后,要加入ret内,此时就是将出现次数最少的先加入到ret,那么正好顺序被反过来了,那么就要逆转一下ret:
reverse(ret.begin(),ret.end());
class Solution {
public:
struct func
{
bool operator()(const pair<string, int>& a, const pair<string, int>& b)
{
if(a.second == b.second) return a.first < b.first;
return a.second > b.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
priority_queue<pair<string, int>, vector<pair<string, int>>, func> q;
unordered_map<string, int> hash;
for (int i = 0; i < words.size(); i++) hash[words[i]]++;
for (auto e : hash)
{
q.push(e);
if(q.size()>k) q.pop();
}
vector<string> ret;
for(int i=0;i<k;i++)
{
ret.push_back(q.top().first);
q.pop();
}
reverse(ret.begin(),ret.end());
return ret;
}
};总结:
学会了灵活运用堆的仿函数参数构造,能够自己设置堆容器的排序过程,已经map和priority_queue之间的联合使用。
13. 数据流的中位数(hard)

解析:
解法一:快排
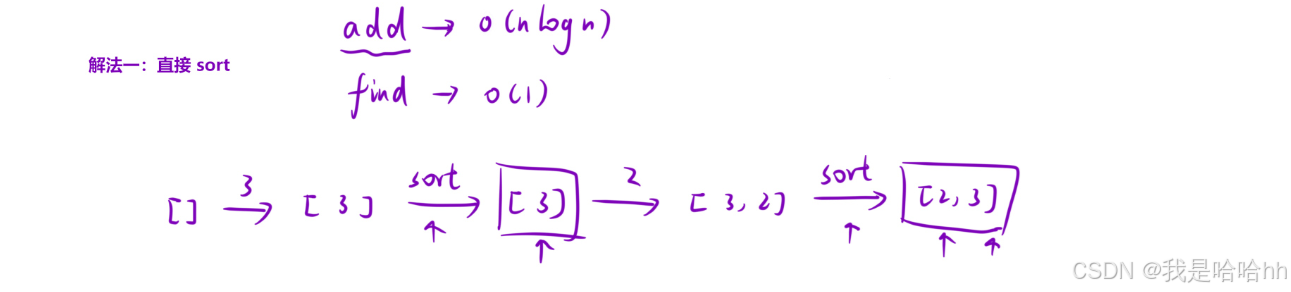
每次添加一个数字,就排一下序,然后进行find查找中间值,但是每次排序的时间复杂度O(nlogn)是绝对会超时的。
解法二:插入排序
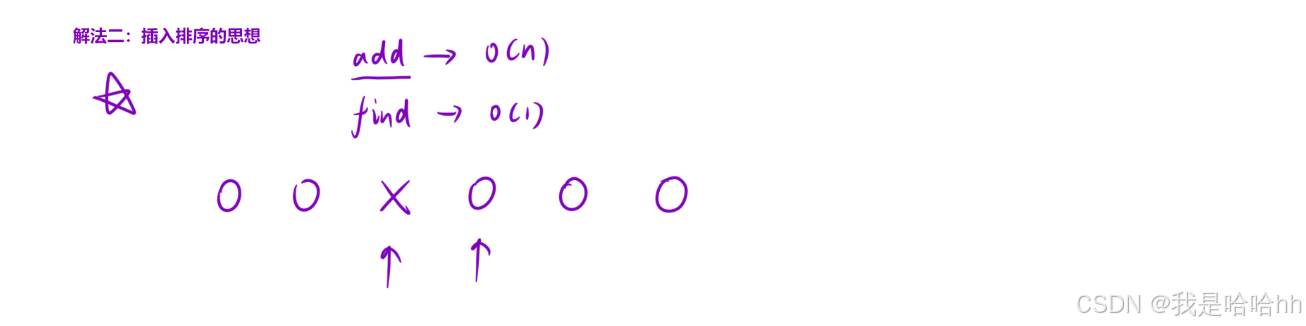
对快排进行优化,因为快排时间复杂度是O(nlogn)但是每次只是插入一个数字,其他的数字已经被排好了,那么快排的消耗就比较大,那么就可以采用插入排序,只是将一个数字进行插入即可,时间复杂度是O(N) ,然后对他找中间值即可。这两种代码都很好写,但是时间复杂度都是会超时的。
解法三:分别构建大小堆进行选择插入
继续进行优化,但是实在想不到也是可以理解的,纯属就是有没有见过这种算法有关,跟智商可没关系嗷。
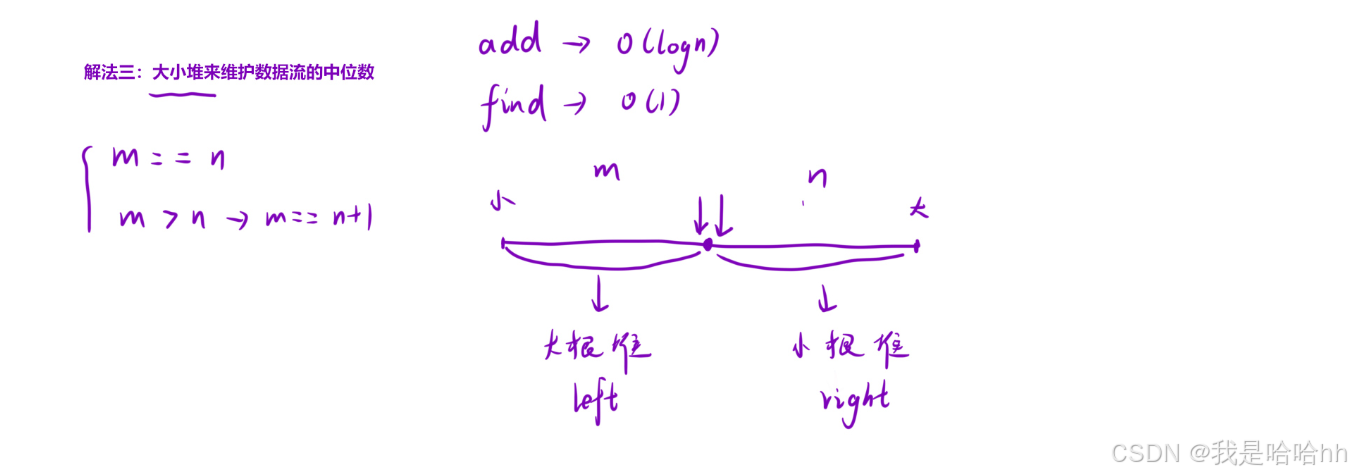
将一个数组进行存入的时候,在对上的存入方式进行改变一半存大根堆,一般存小根堆,那么这样时间复杂度就直接被讲到O(logn)是一个极度优化的算法,因为插入数字num只用跟堆顶的一个数字进行比较,然后只用插入两个堆中的某一个堆即可。
那么就会有很多插入时候的细节问题:
假设左半边是大根堆,堆顶全是最大的元素,右半边是小根堆,堆顶全是最小的元素。
然后每次进行插入num的时候只需要对大根堆的堆顶x与num进行比较即可。那么就会存在下面的几种情况:还是非常全面的。

class MedianFinder {
public:
priority_queue<int> left;
priority_queue<int,vector<int>,greater<int>> right;
MedianFinder() {
}
void addNum(int num) {
//分类讨论即可
if(left.size()==right.size())
{
if(left.empty() || num <= left.top()) //放left里面
{
left.push(num);
}
else
{
right.push(num);
left.push(right.top());
right.pop();
}
}
else
{
if(num<=left.top())
{
left.push(num);
right.push(left.top());
left.pop();
}
else
{
right.push(num);
}
}
}
double findMedian() {
if(left.size()==right.size()) return (left.top()+right.top())/2.0;
else return left.top();
}
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/总结:
这里代码很清晰了,根据上图的讨论方式一步一步的进行描写,还是可以很轻松的拿下这一题,但是没写出来也没关系,只是第一次见到这种题,记住他就好啦,下次就不会再错了。
总结一下吧~这一章对我的收获巨大,希望对你也是!!!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 专题十六_栈_队列_优先级队列_算法专题详细总结

发表评论 取消回复