上一篇的链接:
随机森林的改进方向1:
现有的随机森林中不同决策树中特征的选取是随机的,即先用哪个特征对样本进行分类,再用哪个特征对样本进行分类,特征的选取是随机的,因而,产生了对应的思考,对于两个类别的样本,如果先根据最难区分的两个样本(这两个样本分别属于两个类别),找到最大程度区分这两个样本的特征,将这个特征作为决策树的第一个区分特征,然后根据样本的难区分度依次选择特征作为决策树上的区分特征,是否可以增强决策树的决策能力,进而增强随机森林对不同类别的识别能力。
对应到随机森林,即多个决策树上,是否可以先通过对最难区分的样本区分性好的决策树进行决策,再依次通过对较难区分的样本、较容易区分的样本,即区分难度逐渐降低的样本的区分性较好的决策树进行决策,同时根据决策性赋予不同决策树不同的决策权重,决策性越大的决策树赋予越大的决策权重,进而增强随机森林对不同类别的识别能力。
前置知识 - 决策边界
决策边界即为能将想要分割的两个类别分割开来的界线。
简单决策边界
如下图图1所示:图1中有两个类别,一个类别为圆形,另一个类别为三角形,两个类别的决策边界为图中的蓝色虚线,图1中可以将两个类别分离开的决策边界不止一条,可以有多条。
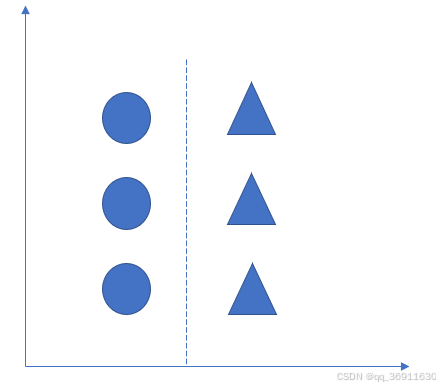
图1

图2
如图2所示,要想把两个类别区分开来,需要两条决策边界才能区分开来,对应到决策树上,需要两种特征才能将两个类别区分开来。
例如:两种缺陷,缺陷A和缺陷B,缺陷A中有两个样本,缺陷B中也有两个样本,有两个特征:灰度值和颜色值,如下列所示:A中的样本为A1和A2,B中的样本为B1和B2,A1通过灰度值可以与B类别中的两个样本区分开来,但A2区分不开,在A1区分开来的基础上,对于(A2、B1、B2)可以通过颜色值区分开来。
灰度值 颜色值
A1 90 80
A2 100 20
B1 98 79
B2 102 82
其中,可见,A1通过灰度值与B1、B2区分开来,其中A1灰度值为90,B1、B2灰度值为98和102,区分不大,但可以区分开来;而A2区分时,是通过颜色值区分的,A2颜色值为20,与B1、B2的颜色值79、82的区分较大;这种区分方案符合先区分不好区分的,再区分较好区分的改进方向的逻辑。此方案的区分率为100%。
反过来,我们先将颜色值作为区分特征,则A2的颜色值20较小,可以将A1先和类别B中的两个样本B1、B2的79和82区分开来,然后只能通过灰度值来区分A1和B类别中的样本,而A1的灰度值90在B类别中样本B1、B2的灰度值98和102之间,无法区分开来,导致将颜色值走位第一区分特征,将灰度值作为第二区分特征,只能将A类别中的A2和B类别样本区分开来,而A类别中的A1区分不开,即区分率为50%。初步验证了改进方案的正确性。
复杂决策边界
如下图图3所示,分割圆形和三角形两个类别的分割边界较为复杂,不是通过简单的直线就能达到分割效果。
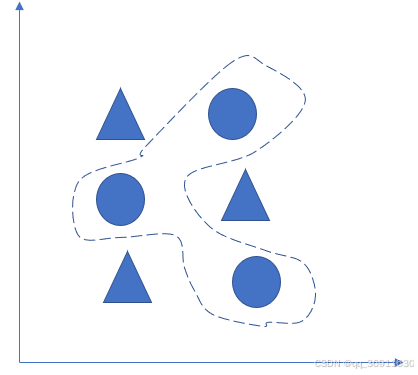
图3
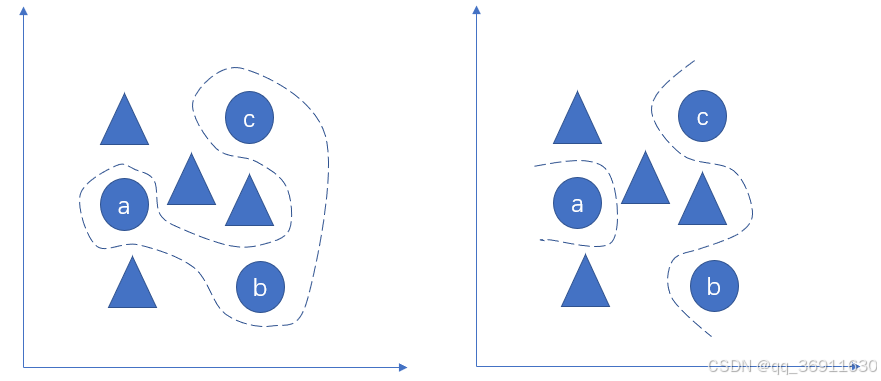
图4
如图4所示,左侧中的虚线为较为复杂的决策边界,对应到数学中,获得这条曲线的数学公式需要大量的计算等,而决策树中的一个个分割特征,可以看作是右图中一样,将作图中的分割边界拆分为一个个局部特征,进而避免了大量的计算才能得到最终的分割规则,即利用一个个的局部分割特征代替了连续的分割线,进而实际中更多使用决策树来进行分类,得到决策边界。
改进模块需实现功能:
1、通过误分率获得难区分类别
越难区分的类别,即容易互相错分的类别,先通过合适的特征将这些类别区分开来,然后通过其它特征对容易区分的类别进行区分,这样可以避免之决策树之前的分支对后面分支的牵制效果,例如:先通过某个特征将两个容易区分的类别区分开来,后面的决策边界就会收到前面的影响,进而难以得到较好的决策边界将两个较难区分的类别进行较好区分。如前面列举的缺陷A和缺陷B通过灰度值和颜色值进行区分的例子。
越难区分的类别,通过分类器分类时,误分率越大,因此这里采用误分率作为类别的难区分性,误分率越大,难区分性越大。
2、获得难区分类别的区分性较好的特征
即需要得到每个容易被误分的类别,当选择哪个特征进行区分时,错分率相对较小,则该特征对于易被误分类别而言的区分性较好。
3、根据每棵决策树的区分特征顺序训练决策树
由于每棵决策树的样本是从所有样本中随机挑选固定数量的样本,因此不同决策树的样本不同,进而可以根据步骤1、2获得每棵决策树的每个特征的区分能力,进而得到区分特征的顺序。
4、根据不同决策树的决策性赋予不同决策树不同的最终决策权重
不同决策树针对相同的样本时,决策能力即识别能力不同,有的决策树只能对较容易区分的样本进行较好识别,而有的决策树对较难区分的样本也可以进行较好识别,因此根据决策能力赋予不同决策树不同的最终决策权重。最终决策权重即该决策树的决策结果被采纳的程度。
代码和效果展示:
1、效果直方图
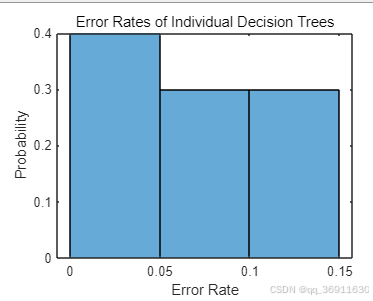
直方图表示的内容
-
横轴(X轴):
- 表示每棵树的错分率。这是计算每棵决策树在测试集上的预测错误率,反映了模型在分类任务中的性能。
-
纵轴(Y轴):
- 表示错分率的概率。也就是说,纵轴展示了不同错分率出现的相对频率,反映了在所有决策树中,各个错分率的出现情况。
目的
- 性能评估:通过观察直方图,可以评估模型的稳定性和各棵树的表现。如果大多数树的错分率较低,则表示模型整体性能良好。
- 由图可见,占比为0.4的决策树的错分率在0~0.05,占比为0.3的决策树的错分率在0.05~0.1,占比为0.3的决策树的错分率在0.1~0.15。
- 识别问题:如果某些树的错分率明显高于其他树,可以进一步分析这些树的结构,找出潜在的问题或特征重要性。
- 根据直方图可以对错分率较高的,即错分率在0.1~0.15的决策树进行进一步分析,进而对随机森林进行进一步优化。
2、预测结果和真实标签
预测结果Final Predictions即为通过修正后的随机森林对验证样本的类别识别结果,真实标签即为每个验证样本的真实类别。
| Final Predictions: | Actual Labels: |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "setosa" | {'setosa' } |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "virginica" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "virginica" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "versicolor" | {'versicolor'} |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
| "virginica" | {'virginica' } |
3、权重前10的决策树
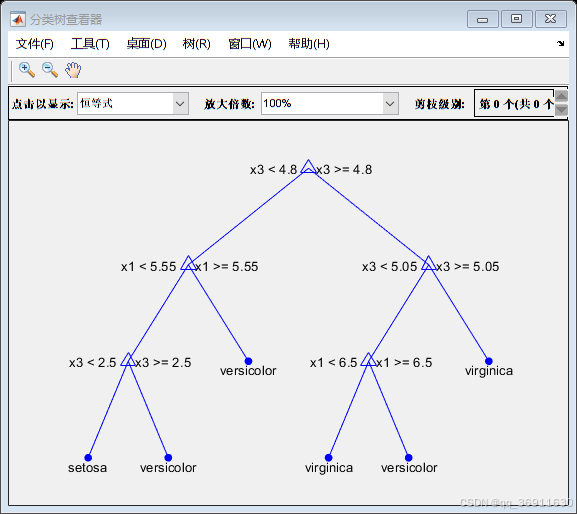
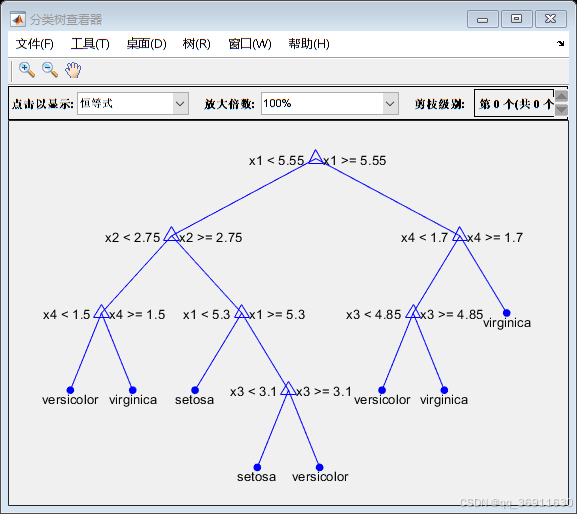
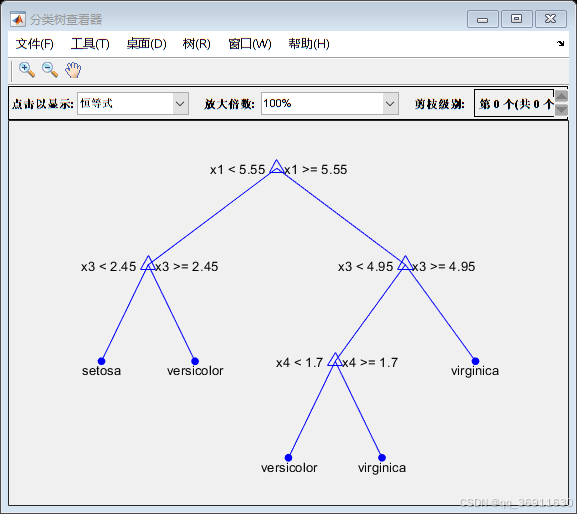
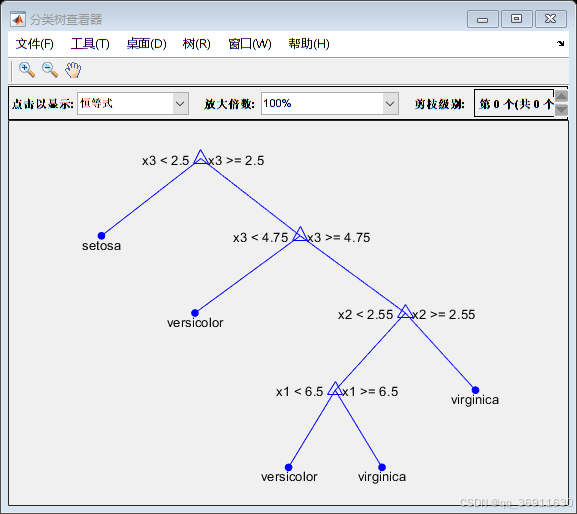
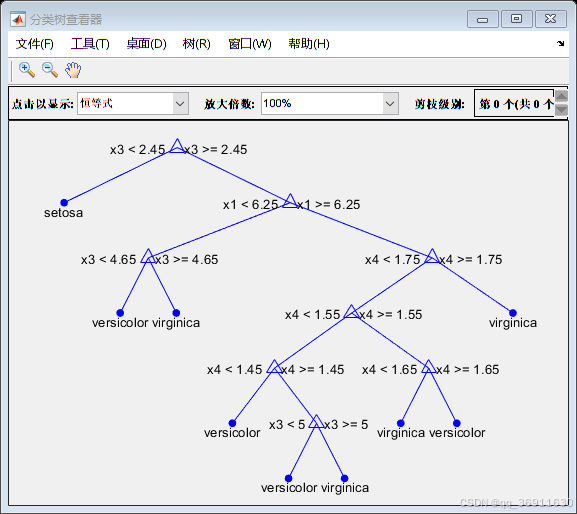
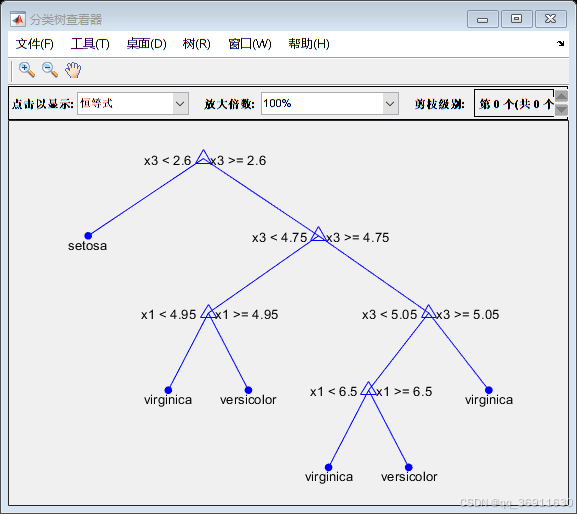
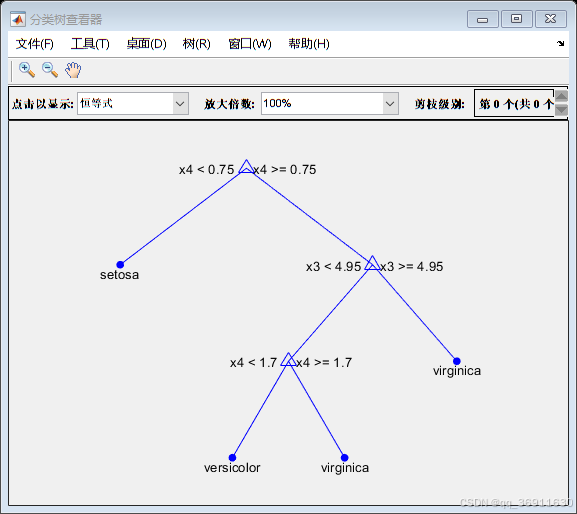
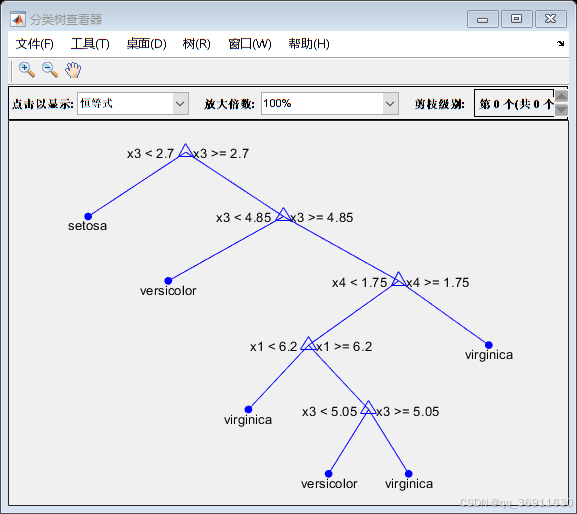
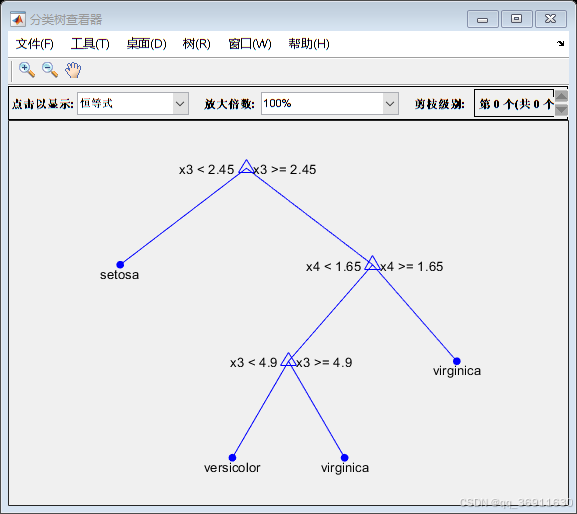
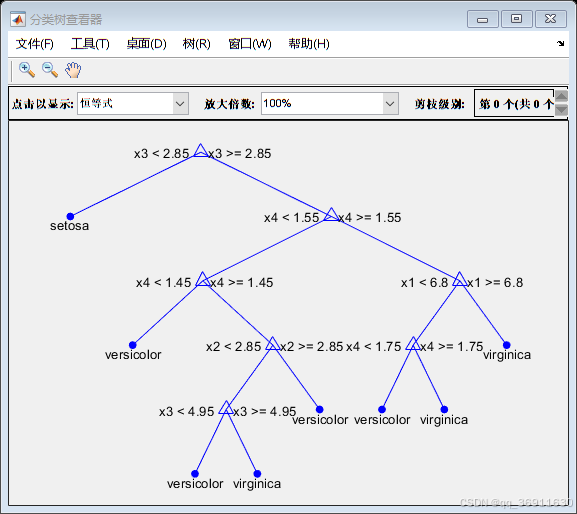
4、实现代码
% 1. 加载鸢尾花数据集
load fisheriris
X = meas; % 特征矩阵
Y = species; % 标签
% 2. 划分训练集和测试集
cv = cvpartition(Y, 'HoldOut', 0.3);
X_train = X(training(cv), :);
Y_train = Y(training(cv), :);
X_test = X(test(cv), :);
Y_test = Y(test(cv), :);
% 3. 训练随机森林模型
numTrees = 10; % 决策树的数量
rfModel = TreeBagger(numTrees, X_train, Y_train, 'Method', 'classification');
% 4. 特征区分率计算与排序
numFeatures = size(X_train, 2);
featureScores = zeros(numFeatures, numTrees); % 特征评分矩阵
for i = 1:numTrees
tree = rfModel.Trees{i}; % 获取第i棵决策树
% 计算每个特征的方差
for j = 1:numFeatures
featureVariance = var(X_train(:, j));
featureScores(j, i) = 1 - featureVariance; % 计算区分率
end
end
% 计算特征的平均区分率并排序
avgFeatureScores = mean(featureScores, 2);
[sortedScores, sortedIndices] = sort(avgFeatureScores, 'descend');
% 5. 计算每棵树的错分率
errorRates = zeros(numTrees, 1);
for i = 1:numTrees
% 预测测试集
predictions = predict(rfModel.Trees{i}, X_test);
% 计算错分率
errorRates(i) = sum(~strcmp(predictions, Y_test)) / length(Y_test);
end
% 计算权重
weights = 1 - errorRates; % 决策权重
[sortedErrorRates, sortedTreeIndices] = sort(errorRates, 'descend');
% 6. 决策结果
finalPrediction = strings(size(X_test, 1), 1); % 将 finalPrediction 初始化为字符串数组
uniqueClasses = unique(Y); % 提取唯一的类别
for i = 1:size(X_test, 1)
classVotes = zeros(length(uniqueClasses), 1); % 类别计数
for j = 1:numTrees
predictions = predict(rfModel.Trees{sortedTreeIndices(j)}, X_test(i, :));
classIdx = find(strcmp(uniqueClasses, predictions)); % 找到类别索引
classVotes(classIdx) = classVotes(classIdx) + weights(j); % 加权投票
end
[~, maxIdx] = max(classVotes); % 找到票数最多的类别
finalPrediction(i) = uniqueClasses(maxIdx); % 使用最大索引提取类别名称
end
% 7. 可视化误差直方图
figure;
histogram(sortedErrorRates, 'Normalization', 'probability');
title('Error Rates of Individual Decision Trees');
xlabel('Error Rate');
ylabel('Probability');
% 8. 可视化决策树
figure;
view(rfModel.Trees{1}, 'Mode', 'graph'); % 可视化第一棵树
title('Visualization of the First Decision Tree');
% 9. 输出最终预测结果
disp('Final Predictions:');
disp(finalPrediction);
disp('Actual Labels:');
disp(Y_test);
% 10. 可视化权重最大的前10棵树
numTreesToVisualize = 10; % 要可视化的树的数量
figure;
for i = 1:numTreesToVisualize
subplot(2, 5, i); % 创建一个 2x5 的子图布局
view(rfModel.Trees{sortedTreeIndices(i)}, 'Mode', 'graph'); % 可视化权重最大的树
title(['Tree ' num2str(i) ', Weight: ' num2str(weights(sortedTreeIndices(i)))]);
end本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习-树结构2-随机森林

发表评论 取消回复