这个问题排除了很久,其中更换了Flink版本,也更换了Hadoop版本一直无法解决,JobManager跑着跑着就异常退出了。资源管理器上是提示运行结束,运行状态是被Kill掉。

网上搜了一圈,都说内存不足、资源不足,配置错误。但是报错非常不明显。
最后终于看到了一条警告日志。
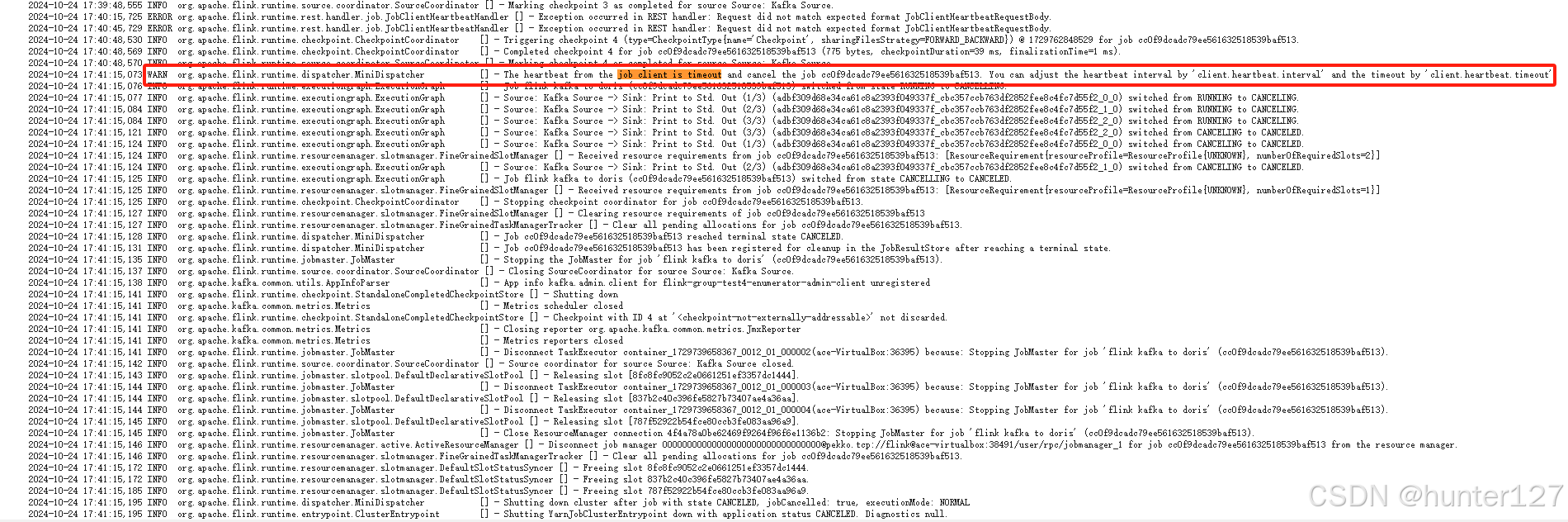
是客户端与jobmanager心跳超时,协商退出的jobmanager。后面就开始取消任务,回收资源逐步退出。除了这条关键退出日志,就没有明显的报错了。
2024-10-24 17:41:15,073 WARN org.apache.flink.runtime.dispatcher.MiniDispatcher [] - The heartbeat from the job client is timeout and cancel the job cc0f9dcadc79ee561632518539baf513. You can adjust the heartbeat interval by 'client.heartbeat.interval' and the timeout by 'client.heartbeat.timeout'
其实提交Flink on Yarn的Pro-Job程序,从开始到结束都有心跳异常的错误。最后超过默认的超时时间180s就开始协商退出了,所以程序每次跑3分钟后就开始退出了。
2024-10-24 17:40:15,725 ERROR org.apache.flink.runtime.rest.handler.job.JobClientHeartbeatHandler [] - Exception occurred in REST handler: Request did not match expected format JobClientHeartbeatRequestBody.
只在yarn-per-job与yarn-application模式下会触发,session模式下不会。因为session模式是一直存在jobmanager,他会接受任何客户端的任务。不需要用完就释放资源。
Flink 1.13.1、Flink1.15.2、Flink1.16.3都不存在以上问题
但是1.17.1和1.18.1、1.20都存在该问题。应该是1.17以上都存在
某大神说的1.17引入新的心跳机制:
The issue you're encountering is related to a new heartbeat mechanism between the client and job in Flink-1.17. If the job does not receive any heartbeats from the client within a specific timeout, it will cancel itself to avoid hanging indefinitely.To address this, you have two options: 1. Run your job in detached mode by adding the -d option in your command line 2. Increase the client heartbeat timeout setting to a larger value, the default value is 180 seconds
解决办法总结了下,大概三种
1、用旧点的Flink版本:例如Flink1.16.3以下;
2、分离模式,加 -d参数;
3、增加心跳超时时间;这个其实无法根本解决;
新版本还是多坑,其实很有一个可能flink1.17开始去除java代码,导致的bug问题
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Flink on yarn模式下,JobManager异常退出问题

发表评论 取消回复