| paper | code |
|---|---|
| https://pmg.csail.mit.edu/papers/osdi99.pdf | https://github.com/luckydonald/pbft |
- 其他相关实现:
- This is an implementation of the Pracltical Byzantine Fault Tolerance protocol using Python
- An implementation of the PBFT consensus algorithm using rust-libp2p as the networking layer.
- Network simulation for PBFT (Practical Byzantine Fault Tolerance) consensus algorithm in Python
- go Sample implementation of PBFT consensus algorithm
- https://github.com/vonwenm/pbft/blob/master/bft-simple/Makefile
PBFT相关简述
1. 拜占庭将军问题
- 拜占庭将军问题描述了一组将军(或节点)需要协同完成任务,但其中一部分将军可能会背叛或发出错误信息。问题是如何确保即使有一些将军是不可靠的,剩下的将军仍然能够达成一致并完成任务。
2. 拜占庭容错的核心目标
-
拜占庭容错的核心目标是确保系统即使在部分节点故障或恶意行为的情况下,也能继续正确地运作。这包括:
-
一致性:所有正常节点对系统状态达成一致。
-
可用性:系统能够在节点故障的情况下继续运行。
-
容错性:系统能够容忍一定数量的故障或恶意节点,而不会影响整体功能。
拜占庭容错和非拜占庭容错
-
拜占庭容错(Byzantine Fault Tolerance, BFT)和非拜占庭容错(Non-Byzantine Fault Tolerance)是两种不同的容错机制,用于确保系统在存在错误或故障的情况下仍然能够正常运行。
-
拜占庭容错的核心思想是
应对系统中存在的不确定性和不诚实节点,尤其是面对可能的恶意攻击和节点故障。这个概念来源于拜占庭将军问题(Byzantine Generals Problem),这个问题描述了在一个系统中,如何确保即使存在部分节点故障或恶意节点,系统仍能达成一致意见并保持正常运行。BFT能够处理和容忍节点的恶意行为,包括虚假信息、拒绝服务等。常见的BFT算法如Practical Byzantine Fault Tolerance (PBFT)、Delegated Byzantine Fault Tolerance (DBFT)等,能够在存在恶意节点的情况下达成一致。 实现BFT机制的系统通常需要更多的通信开销和计算资源,因为算法要处理复杂的协议以确保一致性。 -
拜占庭容错关注的是在节点故障、网络问题等正常的故障情况下保证系统的正确性和一致性,但不处理恶意行为。
容忍的是普通的故障,如崩溃、掉线等,而不是恶意行为。(更偏向封闭系统内部)。常见的非拜占庭容错算法如Paxos、Raft,这些算法假设所有的节点都遵循协议,没有恶意行为。 相对于BFT,非拜占庭容错的算法通常更简单,性能开销较低,因为不需要考虑恶意节点的情况。
3. BFT算法的基本要求
- 拜占庭容错算法通常要求系统中正常节点的数量至少是故障节点数量的三倍加一。也就是说,如果系统中有
n个节点,最多可以容忍f个故障节点,且f满足f < (n - 1) / 3。例如,在一个总共有 7 个节点的系统中,最多可以容忍 2 个故障节点。
4. BFT算法的实现:Practical Byzantine Fault Tolerance (PBFT)
- PBFT 由 Castro 和 Liskov 于1999年提出,广泛用于分布式系统。PBFT将原始的。PBFT 算法通过三阶段的协议(预备阶段、准备阶段和提交阶段)来确保系统的一致性。
- 如图所示算法分为5个部分
- 某个节点收到了 2 3 \frac{2}{3} 32以上的相同消息码,就认为网络达成了共识,可以进行下一步了。所以定义 f 表示最多可能的恶意节点的个数
request
- client向“主节点”发起服务调用请求
pre-request
- “主节点”将请求广播给其他“副本节点”
prepare
- “副本节点”间互相广播
- 收集满2f*1个prepare签名包,广播Commit包确认
commit
- 收集满2f*1个Commit包,区块落盘,回复给客户端
reply
- 返回响应本次请求的结果
注意:
- 以上的过程中没有考虑,主节点为恶意节点的状况。
视图切换协议确保了当主节点出现问题时及时替换。发现主节点有问题的节点会广播给所有其他节点。所有节点在收到请求后,会验证其合法性并准备进入新的视图。在接收到足够多的视图切换请求后(通常是超过三分之二的节点同意),节点会开始正式切换到新视图。每个节点会更新其视图编号,并通知其他节点它已进入新视图。在新视图中,新的领导者会被选出(通常是根据视图编号来轮流选择领导者),然后系统继续在新的视图下进行正常操作。
代码实现
client.py
- client.py的作用是设置并初始化用于节点和客户端之间通信的基础设施,以及定义一个客户端类
- 客户端的通信是同步的:在最后一个请求得到答复之前,它无法发送请求。
main.py
from PBFT import *
from client import *
import threading
import time
# 1.Parameters to be defined by the user
waiting_time_before_resending_request = 200 # 客户端在重新发送请求前等待的时间。如果没有收到响应,它会广播请求到所有节点
timer_limit_before_view_change = 200 # 视图切换的时限,论文中没有提到这个值,所以设为200秒
checkpoint_frequency = 100 # 检查点创建频率,根据原始文章的建议设为100
# 2.Define the nodes we want in our network + their starting time + their type
nodes={} # 这是我们在网络中想要的节点的字典。键是节点类型,值是一个包含启动时间和节点数量的元组列表
#nodes[starting time] = [(type of nodes , number of nodes)]
nodes[0]=[("faulty_primary",0),("slow_nodes",0),("honest_node",4),("non_responding_node",0),("faulty_node",0),("faulty_replies_node",0)] # Nodes starting from the beginning
#nodes[1]=[("faulty_primary",0),("honest_node",1),("non_responding_node",0),("slow_nodes",1),("faulty_node",1),("faulty_replies_node",0)] # Nodes starting after 2 seconds
#nodes[2]=[("faulty_primary",0),("honest_node",0),("non_responding_node",0),("slow_nodes",2),("faulty_node",1),("faulty_replies_node",0)]
# Running PBFT protocol
run_APBFT(nodes=nodes,proportion=1,checkpoint_frequency0=checkpoint_frequency,clients_ports0=clients_ports,timer_limit_before_view_change0=timer_limit_before_view_change)
time.sleep(1) # Waiting for the network to start...
# Run clients:
requests_number = 1 # The user chooses the number of requests he wants to execute simultaneously (They are all sent to the PBFT network at the same time) - Here each request will be sent by a different client
clients_list = []
for i in range (requests_number):
globals()["C%s" % str(i)]=Client(i,waiting_time_before_resending_request)
clients_list.append(globals()["C%s" % str(i)])
for i in range (requests_number):
threading.Thread(target=clients_list[i].send_to_primary,args=("I am the client "+str(i),get_primary_id(),get_nodes_ids_list(),get_f())).start()
time.sleep(0) #Exécution plus rapide lorsqu'on attend un moment avant de lancer la requête suivante
PBFT.py
run_APBFT函数
def run_APBFT(nodes, proportion, checkpoint_frequency0, clients_ports0, timer_limit_before_view_change0):
# 定义一个函数 run_APBFT,它接受以下参数:
# - nodes: 所有节点的列表 详见main.py
# - proportion: 节点的比例,本次运行值为1
# - checkpoint_frequency0: 检查点的频率
# - clients_ports0: 客户端端口列表 由clinet.py确定,本次运行值为[30000, 30001, 30002, 30003, 30004, 30005, 30006, 30007, 30008, 30009, 30010, 30011, 30012, 30013, 30014, 30015, 30016, 30017, 30018, 30019, 30020, 30021, 30022, 30023, 30024, 30025, 30026, 30027, 30028, 30029, 30030, 30031, 30032, 30033, 30034, 30035, 30036, 30037, 30038, 30039, 30040, 30041, 30042, 30043, 30044, 30045, 30046, 30047, 30048, 30049, 30050, 30051, 30052, 30053, 30054, 30055, 30056, 30057, 30058, ...]
# - timer_limit_before_view_change0: 视图更改之前的定时器限制,本次运行值为200
# 设置全局变量 p 为传入的比例值
global p
p = proportion
global number_of_messages
number_of_messages = {}
# 初始化一个空字典,用于存储每个请求从 preprepare 到 reply 之间的消息数量
# 格式: number_of_messages={"request":number_of_exchanged_messages, ...}
global replied_requests
replied_requests = {}
# 初始化一个空字典,用于记录请求是否已回复
# 比如在reply_received函数中 request='I am the client 0',replied_requests[request] = 1
global timer_limit_before_view_change
timer_limit_before_view_change = timer_limit_before_view_change0
# 设置全局变量 timer_limit_before_view_change 为传入的值
global clients_ports
clients_ports = clients_ports0
# 设置全局变量 clients_ports 为传入的客户端端口列表
global accepted_replies
accepted_replies = {}
# 初始化一个空字典,用于存储每个请求的客户机接受的回复
# 格式: accepted_replies={"request":reply}
global n
n = 0
# 初始化节点总数 n 为 0,每次实例化一个节点时都会递增
global f
f = (n - 1) // 3
# 计算允许的故障节点数量 f
# f 应随着节点总数 n 的变化而更新
global the_nodes_ids_list
the_nodes_ids_list = [i for i in range(n)]
# 初始化节点 ID 列表 the_nodes_ids_list,范围从 0 到 n-1
global j
j = 0
# 初始化下一个节点 ID j 为 0,每次实例化一个新节点时都会递增
global requests
requests = {}
# 初始化一个空字典,用于存储每个客户端 ID 及其最后请求的时间戳
# 格式: requests={"client_id":timestamp}
global checkpoint_frequency
checkpoint_frequency = checkpoint_frequency0
# 设置全局变量 checkpoint_frequency 为传入的检查点频率值
global sequence_number
sequence_number = 1
# 初始化序列号 sequence_number 为 1,每当有新请求时递增
# 选择 1 以便在开始时有一个稳定的检查点,必要时可以用于视图更改
global nodes_list
nodes_list = []
# 初始化一个空列表,用于存储所有节点的列表
global total_processed_messages
total_processed_messages = 0
# 初始化已处理的消息总数 total_processed_messages 为 0
# 这是在处理请求时通过网络发送的消息总数
# 节点评估指标:
global processed_messages
processed_messages = []
# 初始化一个空列表,用于记录每个节点处理的消息数量
global messages_processing_rate
messages_processing_rate = []
# 初始化一个空列表,用于记录所有节点的消息处理率
# 计算为节点发送的消息与所有节点通过网络发送的消息的比例
###################
global consensus_nodes
consensus_nodes = []
# 初始化一个空列表,用于存储参与共识的节点 ID
# 启动一个新的线程来运行节点
threading.Thread(target=run_nodes, args=(nodes,)).start()
# 创建并启动一个新线程,执行 run_nodes 函数,传入所有节点列表作为参数
run_nodes函数
def run_nodes(nodes):
# 声明全局变量,以便在函数中修改它们
global j
global n
global f
# 初始化总节点数
total_initial_nodes = 0
# 计算初始节点总数
for node_type in nodes[0]:
total_initial_nodes += node_type[1]
# 用于记录上一个等待时间的变量
last_waiting_time = 0
# 遍历节点的等待时间
for waiting_time in nodes:
# 遍历当前等待时间下的节点类型和数量
for tuple in nodes[waiting_time]:
# 根据数量循环创建节点
for i in range(tuple[1]):
# 等待指定的时间(根据当前和上一个等待时间的差值)
time.sleep(waiting_time - last_waiting_time)
last_waiting_time = waiting_time
# 获取节点类型
node_type = tuple[0]
# 根据节点类型创建相应的节点对象
if node_type == "honest_node":
node = HonestNode(node_id=j)
elif node_type == "non_responding_node":
node = NonRespondingNode(node_id=j)
elif node_type == "faulty_primary":
node = FaultyPrimary(node_id=j)
elif node_type == "slow_nodes":
node = SlowNode(node_id=j)
elif node_type == "faulty_node":
node = FaultyNode(node_id=j)
elif node_type == "faulty_replies_node":
node = FaultyRepliesNode(node_id=j)
# 启动一个新线程来处理节点的接收逻辑
threading.Thread(target=node.receive, args=()).start()
# 将节点添加到节点列表中
nodes_list.append(node)
the_nodes_ids_list.append(j)
# 初始化处理消息的计数器和处理率
processed_messages.append(0)
messages_processing_rate.append(0) # 初始化为0
# 将节点ID添加到共识节点列表中
consensus_nodes.append(j)
# 更新节点数量和容错数
n += 1
f = (n - 1) // 3
# 更新节点ID计数器
j += 1
# print(consensus_nodes)
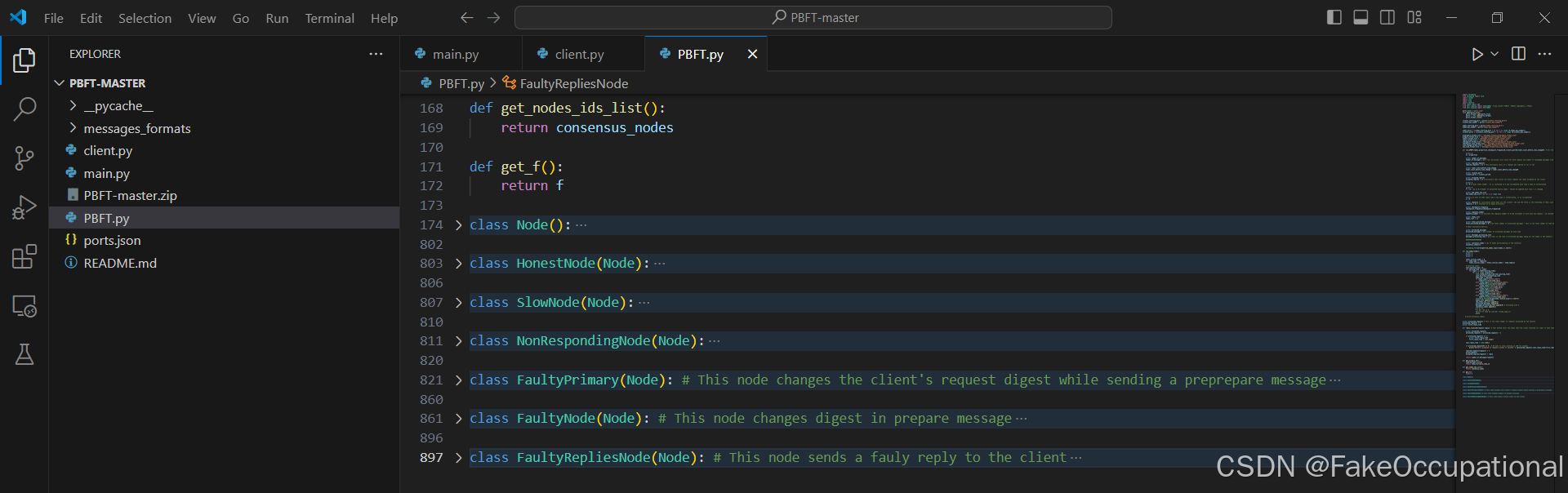
节点和相关衍生类型
CG
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【p2p、分布式,区块链笔记 分布式容错算法】: 拜占庭将军问题+实用拜占庭容错算法PBFT

发表评论 取消回复