导语
Pulsar Meetup 2024 北京站已经成功落下帷幕。在本次盛会中,腾讯云的高级工程师韩明泽和王震江为与会者带来了精彩的演讲。他们围绕多网接入、集群迁移以及高可用最佳实践这三大核心议题,深入剖析了《腾讯云上基于 Apache Pulsar 的大规模生产实践》,为听众呈现了一场知识与经验交织的盛宴。
作者介绍
王震江
腾讯研发工程师,负责腾讯云 TDMQ for Apache Pulsar 商业化开发,开源社区爱好者
韩明泽
腾讯高级工程师,负责腾讯云 TDMQ for Apache Pulsar 商业化开发
拥有7年消息队列开发经验,熟练掌握 Pulsar、 Kafka、RocketMQ 等主流消息队列
Apache Pulsar/BookKeeper/Zookeeper contributor,RoP maintainer
多网络接入
网络介绍
云环境中,我们常遇到三种网络类型:内网、VPC(虚拟私有云)以及公网。若 VPC 和公网需要访问集群,则必须通过网络寻址功能实现 IP 映射,从而打通这些网络。在以往的方案中,这一步骤是通过 AdvertisedListeners+ListenerName 来完成的,它负责将每个 IP 映射文件存放在 Broker 集群里。
然而,这种方法带来了三个显著的问题。
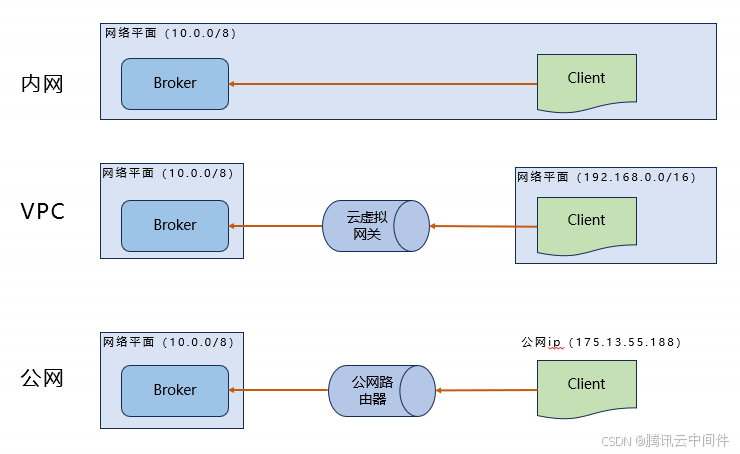
首先,配置过程变得相当复杂。由于每个接入点都对应一个 IP 映射,随着接入点的不断增加,这些映射文件会变得异常庞大,管理起来极为不便。同时,每个 Broker 所对应的文件可能并不一致,这进一步加剧了配置的复杂性。
其次,这种架构导致了职责的混淆。Broker 本应专注于消息的收发过程,但在此架构下,它还需承担网络寻址的职责,这使得其职责变得模糊不清。
最后,这种方法的维护成本也相对较高。配置文件频繁变动,修改起来既麻烦又容易出错。而且,如果不同节点之间的数据不一致,导致整体维护难度很大。
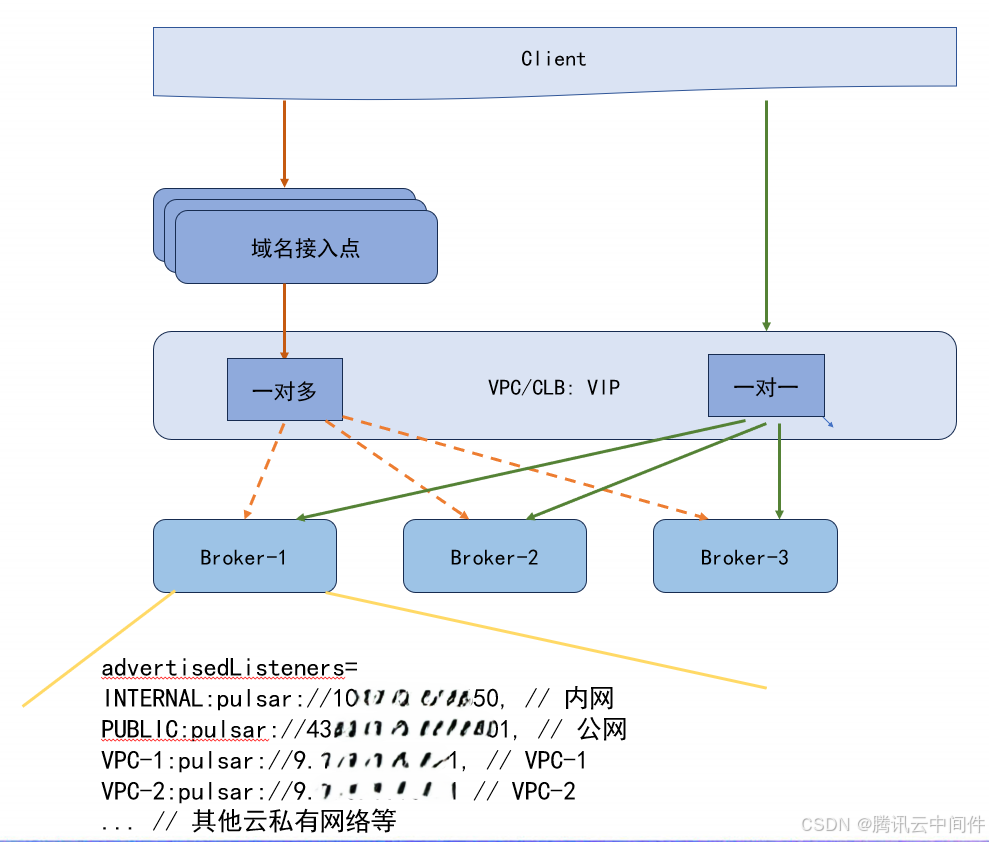
路由寻址
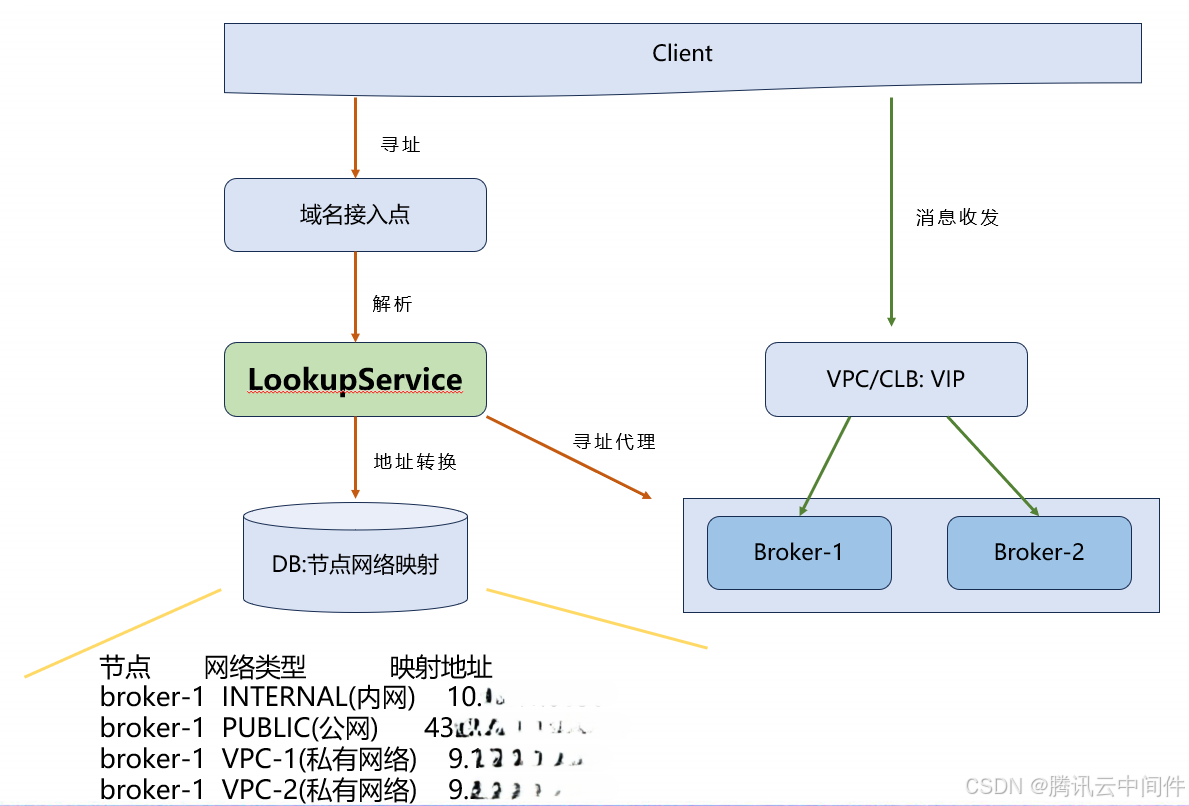
针对上述挑战,我们创新性地提出了路由寻址方案。这一改进方案的核心在于引入 LookupService 来执行路由寻址任务,通过数据库,集中管理和维护网络映射和寻址信息。
路由寻址方案带来了四大显著优势:
● 架构简化:从下图可以看出,整个系统结构更加简洁明了,避免了不必要的复杂性。
● 职责明确:在此方案下,Broker 得以专注于其核心任务——消息的收发,而无需再承担网络寻址的职责,实现了有效的解耦。
● 运维便捷:运维团队只需专注于管理工作,无需与 Broker 进行繁琐的交互,从而大大降低了运维成本和复杂性。
● 扩展性强:这一优势在多集群管理或集群迁移时尤为明显,它确保了业务的稳定性和连续性,为系统的未来发展奠定了坚实基础。
综上所述,路由寻址方案的提出,不仅有效解决了原有方案中的问题,还带来了诸多优势,为系统的优化和升级提供了有力支持。
集群迁移
产品形态
TDMQ Pulsar 主要有三种典型的产品形态。
第一种是 Broker 共享,Bookie 共享,这种的产品形态成本比较低,但是存在一些问题,主要面临隔离性问题和稳定性问题。
第二种是 Broker 独占,Bookie 独占,这种形态下,计算层、存储层资源独占。这种形态优点是隔离性好,缺点是成本相对较高
第三种是 Broker 独占,Bookie 共享。这种形态综合考虑了稳定性和成本,算是一种折中的方案。
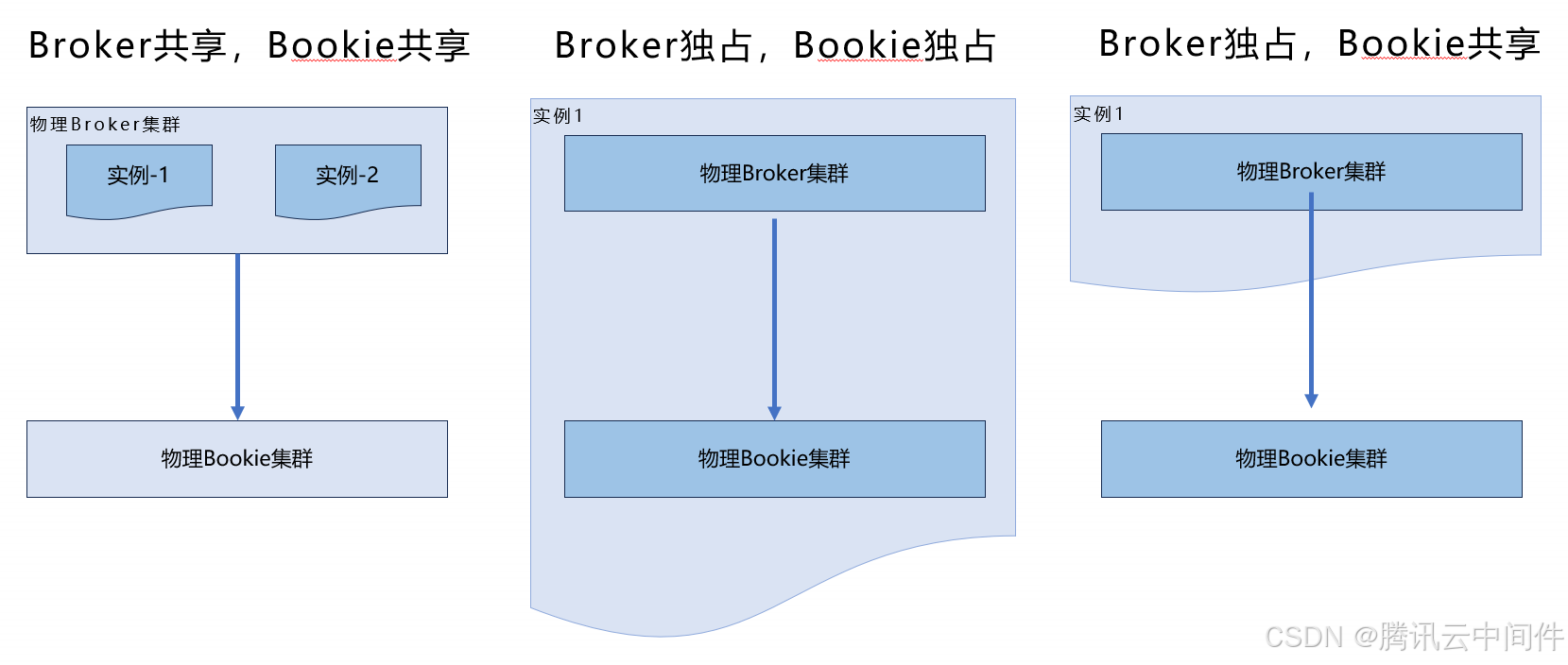
三种形态并无明显的优劣之分,更多的是要结合实际的应用场景做出选择。
整体架构
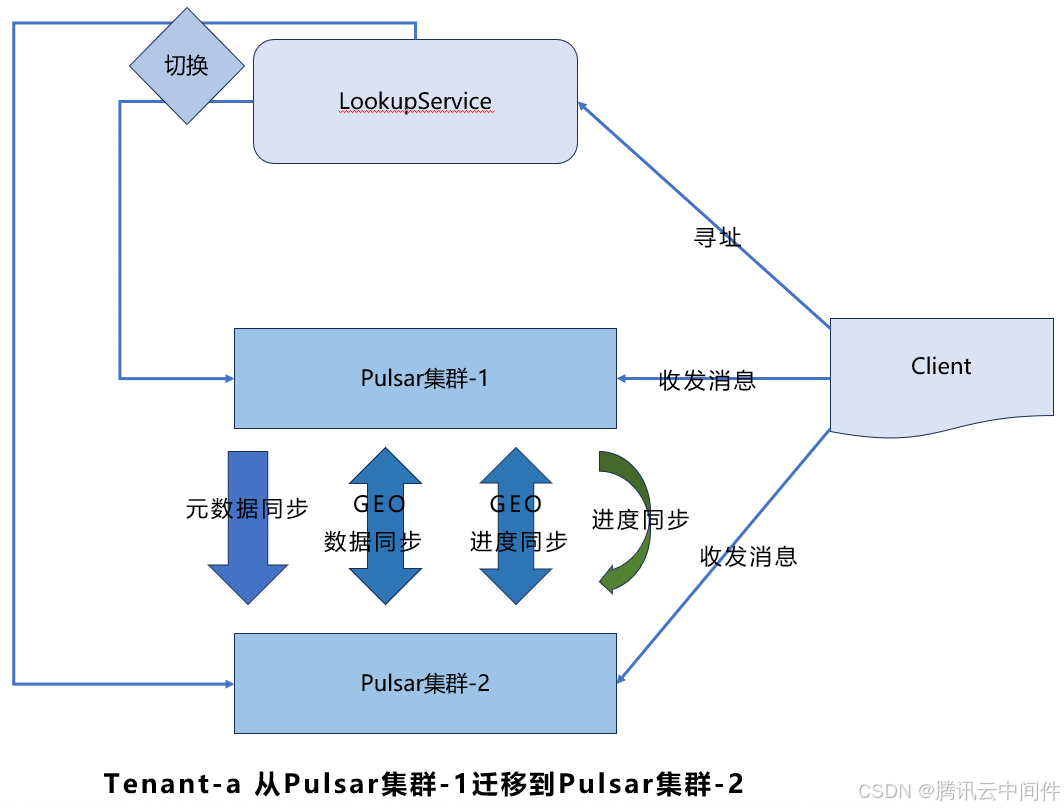
我们最初采用的都是共享的产品形态。但是,随着用户规模增加,对产品的稳定性提出更高的要求,共享形态并不能很好的满足业务的诉求。他们需要从共享模式迁移到更为适合的后两种模式。这时,集群迁移问题便随之而来。为了应对这一挑战,我们精心设计了集群迁移方案,该方案主要包含以下四个关键步骤:
● 元数据同步
● 数据同步(GEO)
● 订阅进度同步(GEO+补偿)
● 切换集群(Unload+寻址调整)
订阅进度说明
整体的集群迁移实现逻辑比较简单。主要的难点在于订阅进度的同步上。
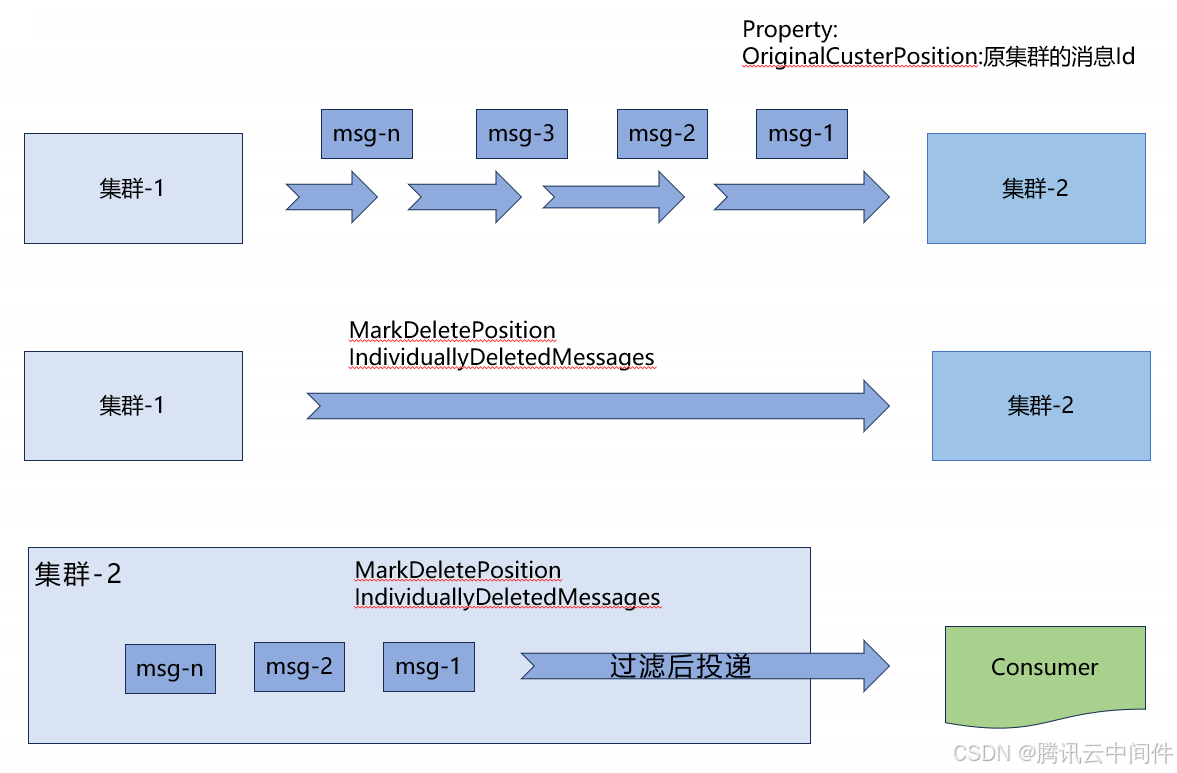
在使用社区 GEO 方案进行订阅进度同步时,我们发现存在一些问题。GEO 中的订阅进度只会同步 MarkDeletePosition,这样,会导致订阅进度并不完整。因为 Pulsar 中,订阅进度是由两部分组成的。这意味着,在实际迁移的过程中,用户可能会遇到消息大量重复处理的情况。

进度同步
为了解决集群迁移过程中可能出现的消息重复消费问题,我们创新性地提出了一个补偿方案。
1、 我们会在同步消息到目标集群的时候,在消息的元数据中,携带原集群的消息 ID。
2、 我们会将原集群中的订阅进度(MarkDeletePosition和IndividuallyDeleteMessages)同步到目标集群。
3、 当消费者迁移到目标集群后。在目标集群中,读取消息之后,如果消息是来自原集群,那我们将原集群中的消息 ID 和原集群的订阅集群进行比对,如果判断消息已经在原集群中消费完成,我们就将消息过滤掉,不再投递给消费者。
通过上面的机制,我们有效解决了消费进度同步不完整的问题。
高可用最佳实践
如今,公司对 TDMQ Pulsar 集群的基本要求已经远远超越了单点故障的防范,而是至少需要具备可用区级别的容错能力。更进一步,对集群能力乃至跨地域能力的需求也日益增长。
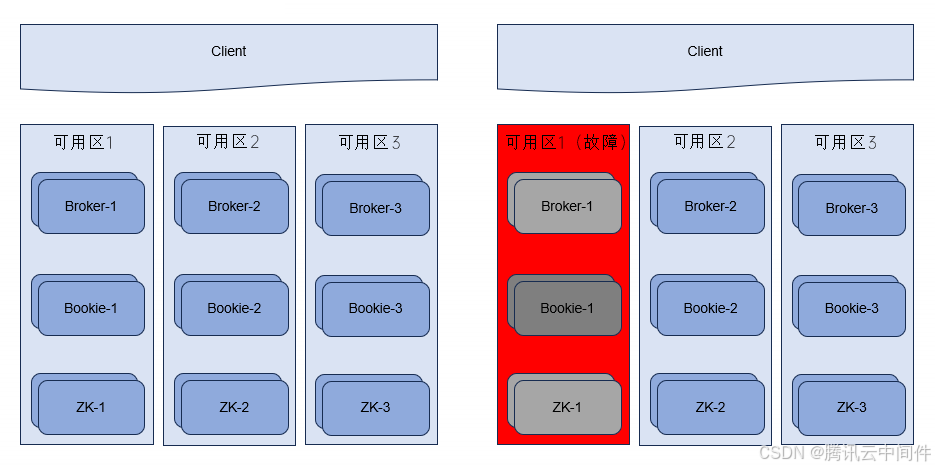
在此,我们将重点聚焦于可用区维度的探讨。特别是在存储层面,副本的分布策略显得尤为重要。
可用区容灾
在高可用存储系统中,副本分布是确保数据可靠性和系统稳定性的关键环节。其中,机架感知和跨可用区分布是副本分布策略的重要方面。
机架感知
机架感知是指系统能够识别并感知到不同服务器所在的机架,从而在分配副本时尽量将副本分散到不同的机架上。这样做的好处是,当某个机架出现故障时,其他机架上的副本仍然可用,保证了数据的可靠性和系统的稳定性。
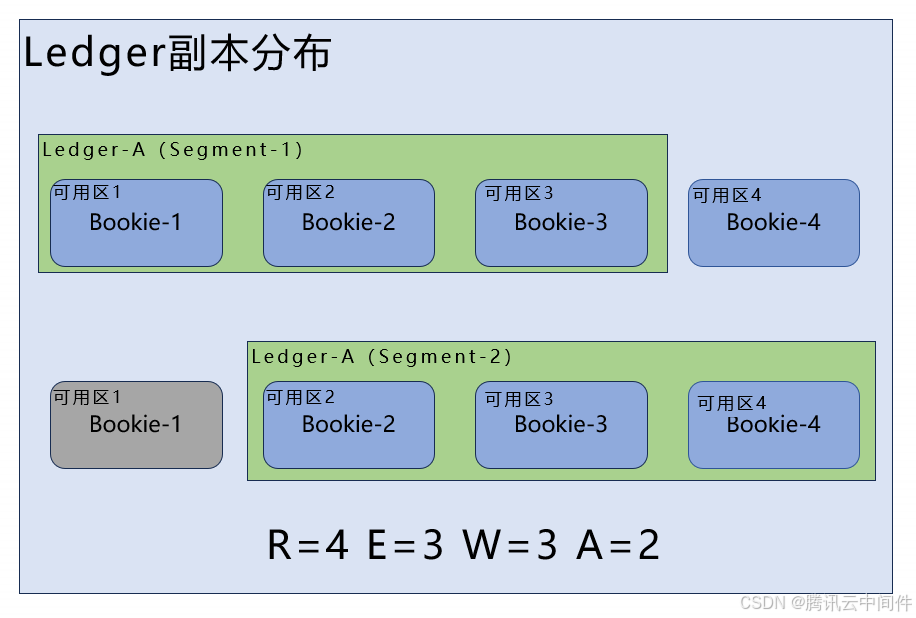
跨可用区分布
跨可用区分布是指将副本分散到不同的可用区(如不同的地理区域或数据中心)。这样做可以进一步提高数据的可靠性和系统的容错性。当某个可用区出现故障时,其他可用区上的副本可以接管并提供服务,确保系统的持续运行。
在实现跨可用区分布时,通常需要配置相关的参数来开启机架感知和跨可用区分布功能。这些配置通常包括指定副本的数量、分布方式以及可用区的选择等。
注意事项
尽管副本分布策略可以显著提高系统的可靠性和稳定性,但在实际执行过程中,仍需注意以下几点:
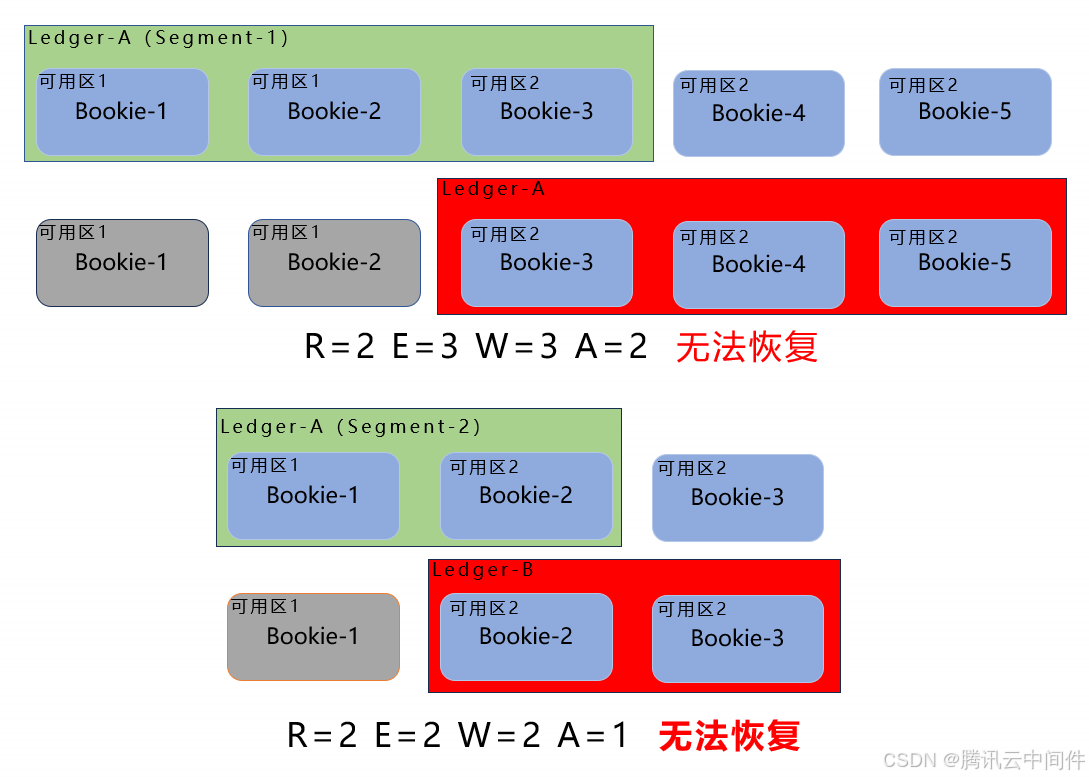
● 副本恢复过程的数据保证
在副本恢复过程中,需要保证剩余的副本数量大于等于w-a+1(w是写副本数,a是确认副本数)。这是为了确保在恢复过程中,即使出现部分副本丢失或不可用的情况,仍然有足够的副本可以恢复数据,保证数据的不丢失和高可靠性。
● 处理数据堆积和读取策略
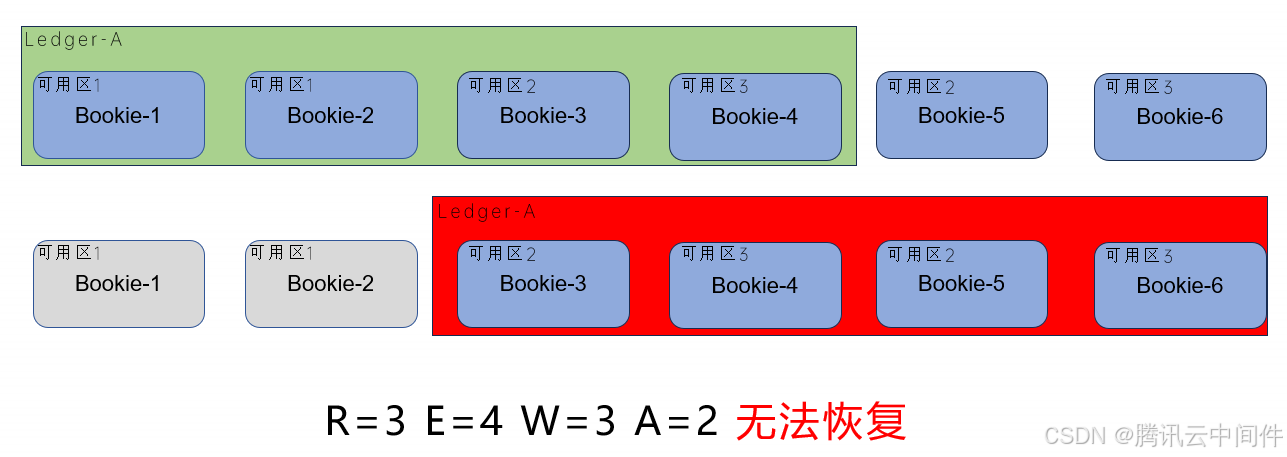
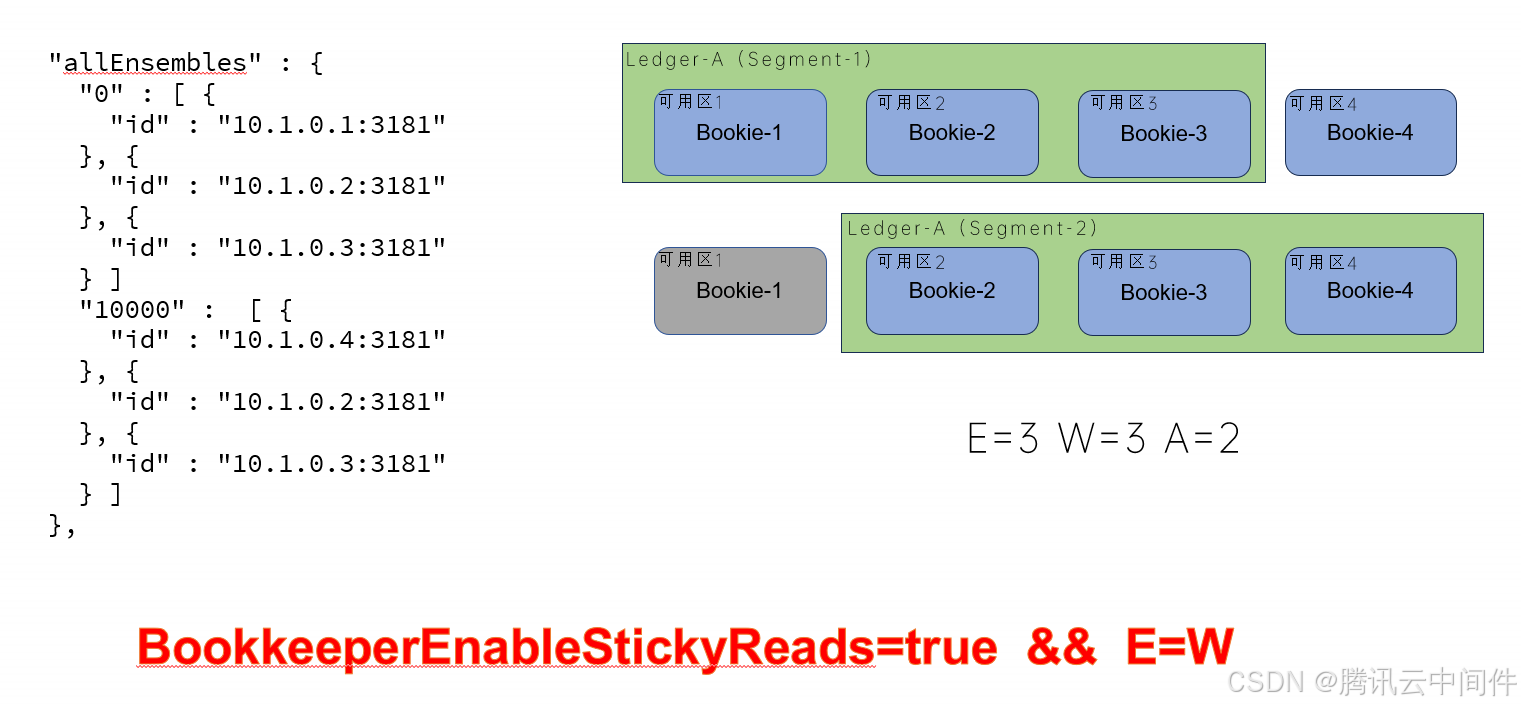
在某些情况下,可能会出现数据堆积和读取策略不当的问题。例如,当某个副本节点出现故障时,如果是读堆积消息,可能会导致读取速度变慢。因为读取的时候,默认是轮询读取每个副本节点,当读取到故障节点的时候,会出现超时的情况,造成读取性能明显下降。为了解决这个问题,可以优化读取策略或开启粘性读开关,使系统在选择读取节点时更加智能和高效。
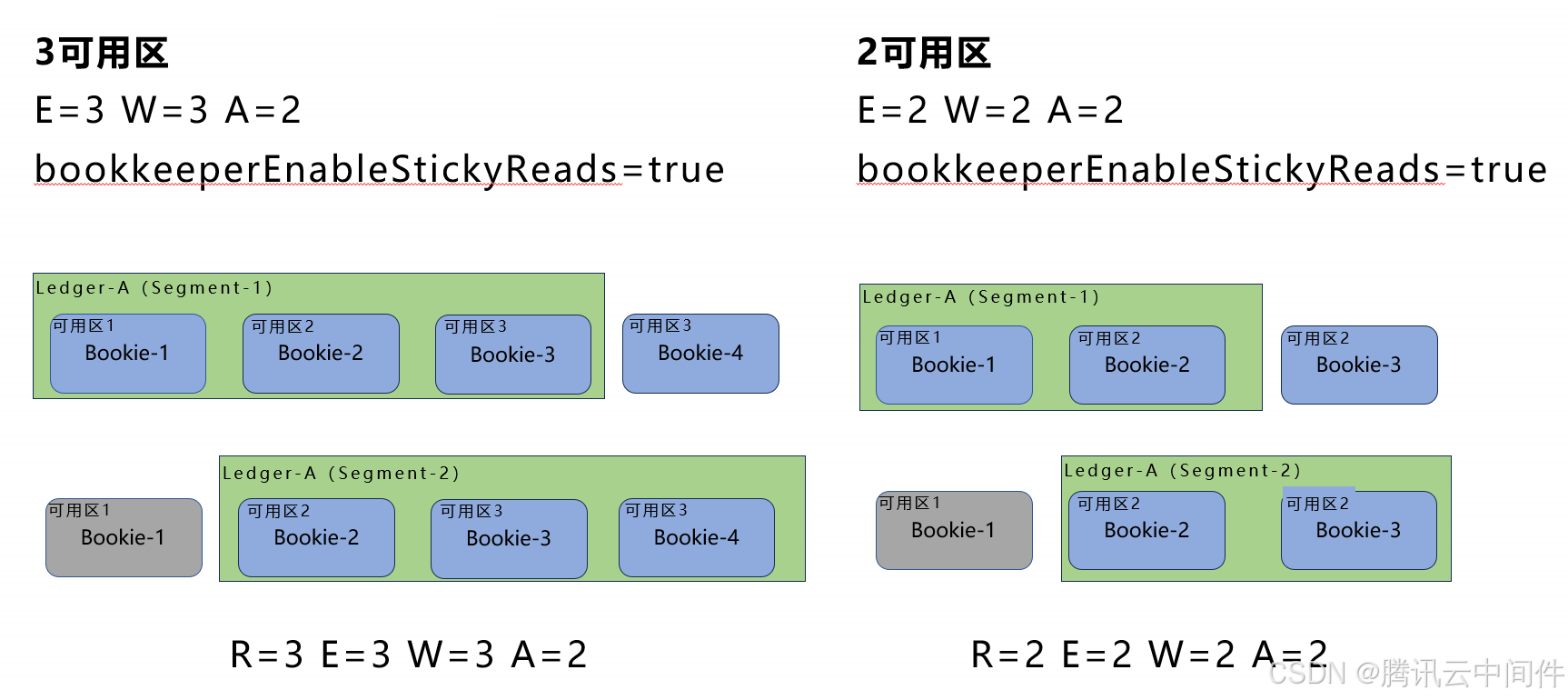
最佳实践
在3可用区和2可用区下,既能满足数据高可靠,又能满足服务可用性的部署形态。
地域容灾
除了副本分布策略外,容灾能力也是确保系统高可用性的重要方面。容灾能力是指系统在出现故障或灾难时能够快速恢复并提供服务的能力。
在实现容灾能力时,通常需要建立异地备份集群并定期同步数据。当主集群出现故障时,可以切换到备份集群提供服务。同时,还需要建立相应的运营切换机制和消息堆积处理机制以确保系统的持续运行和数据的一致性。
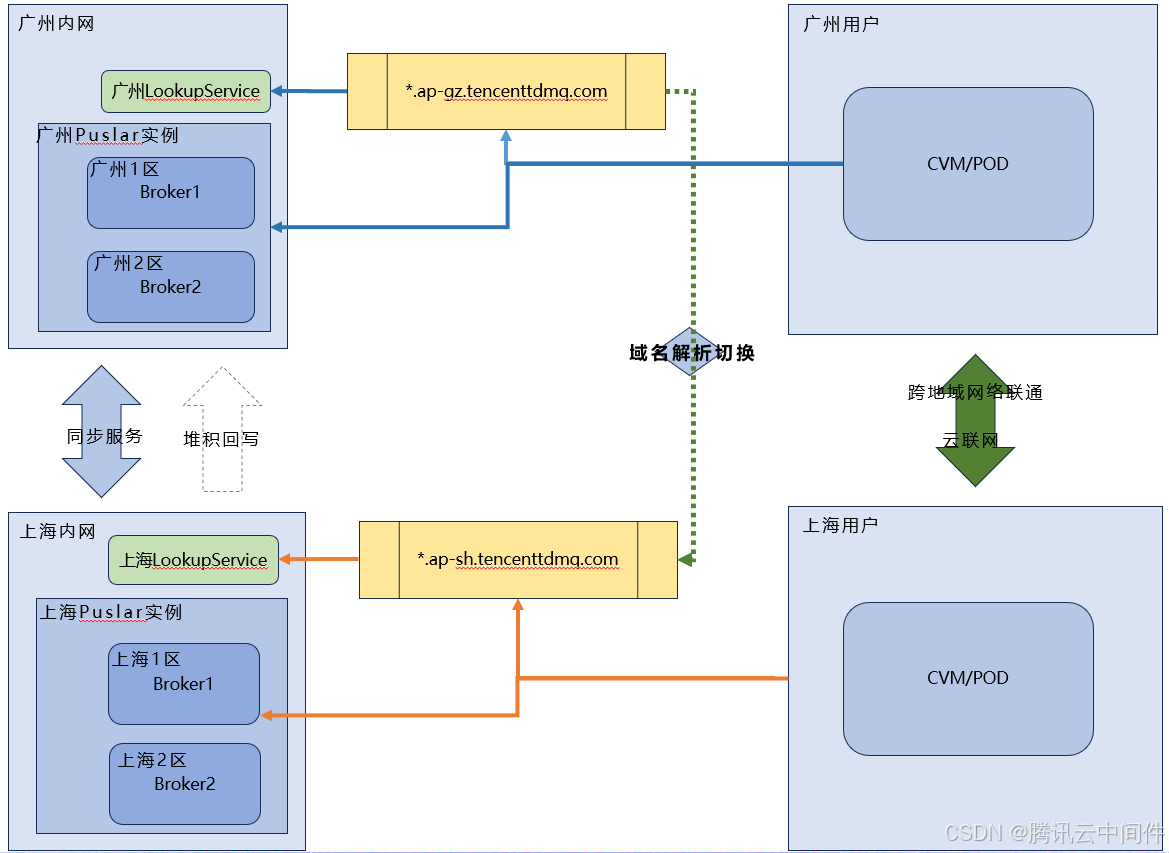
综上所述,高可用存储层的副本分布策略及注意事项是确保系统可靠性和稳定性的重要环节。在实际应用中,需要根据具体的业务场景和需求来选择合适的策略并注意相关的注意事项以确保系统的正常运行和数据的安全性。
总结
展望未来,我们将继续致力于优化 Apache Pulsar 在腾讯云上的应用,不断提升系统的性能、稳定性和可用性。我们将持续关注用户需求,不断推出更多创新性的解决方案,以满足用户在不同场景下的需求。同时,我们也将积极参与开源社区的建设,与更多开发者共同推动 Apache Pulsar 的发展,为消息队列技术的进步贡献我们的力量。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 腾讯云上基于 Apache Pulsar 的大规模生产实践

发表评论 取消回复