上一篇博客做了关于“广州市2023年天气情况”的数据爬取,并保存为.csv文件。下一步是想用生成的.csv文件,直接调用大模型api进行分析,得出结论。通过调研,阿里云的通义千问大模型qwen-long可以实现对文件数据的分析。
通义千问大模型提供了 API,可以将数据预处理后传入模型进行分析和总结,实现步骤如下:
- 预处理 .csv 文件:使用 pandas 读取 .csv 文件,并将其内容格式化为适合传递给通义千问的自然语言描述,例如表格的结构、数值的统计信息、特征分布等。
- 调用 API:使用阿里云的 SDK 或直接通过 HTTP 请求调用通义千问的 API,将处理后的数据传入并询问模型得出结论。
- 处理 API 返回结果:通义千问会返回一个文本格式的结果,可以进一步提取关键信息,或根据需要再做数据可视化。
调用通义千问api
api-key的获取和配置
开通DashScope
前往控制台:模型服务灵积-总览 (aliyun.com)
获取api-key
- 进入网页:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
- 选择管理中心 → api-key管理 → 创建新的api-key(因为我已经创建了,所以图标是暗的)
- 可以点击“查看” → “复制”

配置api-key
- 通过环境变量设置
- 直接在代码中输入
验证api-key在代码中是否可用
这一步还蛮关键的,测试一下所配置的api-key是否可用。
import os
from openai import OpenAI
try:
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key="your_api_key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="your_model_name", # 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}
]
)
print(completion.choices[0].message.content)
except Exception as e:
print(f"错误信息:{e}")
print("请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code")输出有3种情况:
- 我是通义千问,由阿里云开发的AI助手。我可以回答各种问题、提供信息和与用户进行对话。有什么我可以帮助你的吗?
- 我是Qwen,由阿里云研发的超大规模语言模型。我能够生成各种类型的文本,如文章、故事、诗歌、故事等,并能根据不同的场景和需求进行调整和优化。此外,我还具备代码写作能力,可以辅助编程工作,解决技术问题。如果你有任何需要,欢迎随时向我提问!
- 我是Qwen,由阿里云研发的超大规模语言模型。我被设计用于生成各种类型的文本,如文章、故事、诗歌等,并能根据不同的场景和需求进行对话、提供信息查询、创作内容等服务。很高兴为您服务!
其他输出或者报错的话就是代码出问题了,总结了集中报错的方式:
- 我这里是采用直接输入api_key的方法,这种方法可能会导致分享的时候不小心泄露,可以导入环境变量中再引用,这会比较保险。
- 报“from openai import OpenAI”的错,说没有办法在openai库中引入OpenAI,这是openai版本过旧导致,需要更新一下:pip install --upgrade openai。
- 可能是model的名字没有写对,比如说我用的是qwen-long模型,最开始以为是model="qwen-long",查了一下模型列表才发现qwen-long对应的应该是"qwen-plus"。
模型选择
模型列表_大模型服务平台百炼(Model Studio)-阿里云帮助中心 (aliyun.com)
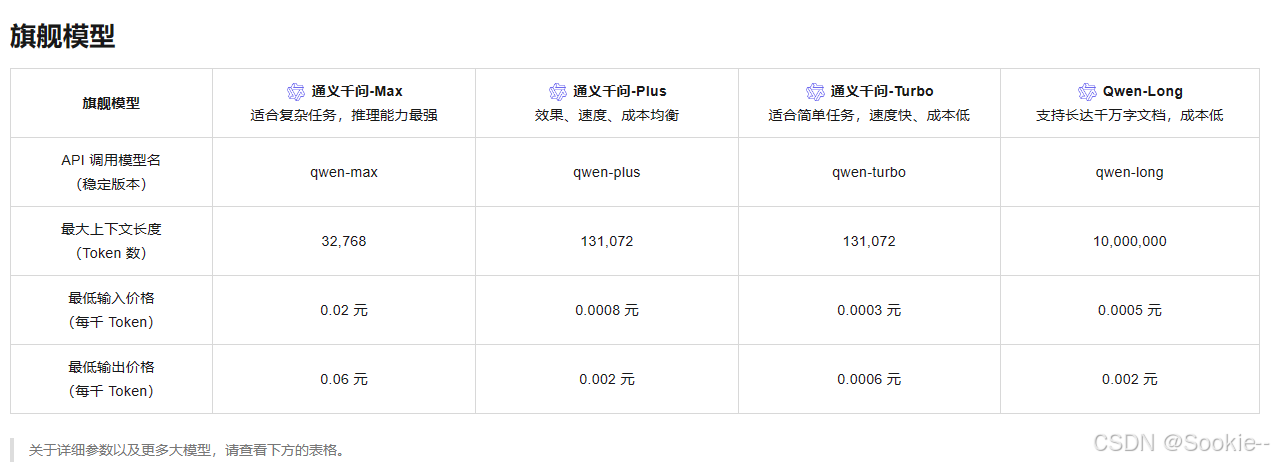
如果不知道任务与什么模型相匹配,可以去模型广场查阅:阿里云百炼 (aliyun.com)

根据任务需求,选择供应商、模型类型和上下文长度,我这里是需要分析.csv文件或者.xlsx文件,所以选择了“通义”、“文本生成”、“64k以上”的“Qwen-Long”模型。已经知道要用哪个模型的话,可以在搜索栏里直接搜索。
点击“查看详情”可以查看模型介绍和API示例。
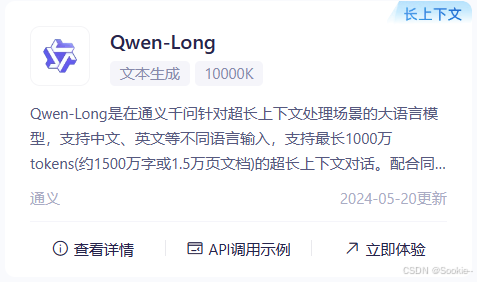
模型介绍
Qwen-Long是在通义千问针对超长上下文处理场景的大语言模型,支持中文、英文等不同语言输入,支持最长1000万tokens(约1500万字或1.5万页文档)的超长上下文对话。配合同步上线的文档服务,可支持word、pdf、markdown、epub、mobi等多种文档格式的解析和对话。 说明:通过HTTP直接提交请求,支持1M tokens长度,超过此长度建议通过文件方式提交。
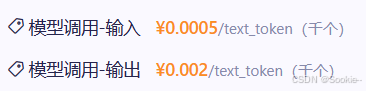
模型计费详情
写入代码
在试错过程中,为了方便操作,把爬取来的.csv文件转换为.xlsx
import pandas as pd
# 读取CSV文件
csv_file_path = 'your_csv_file_path' #
df = pd.read_csv(csv_file_path)
# 将DataFrame保存为Excel文件
excel_file_path = 'your_xlsx_file_name' # 指定输出的Excel文件名
df.to_excel(excel_file_path, index=False) # index=False表示不保存行索引
print(f"文件已成功转换并保存为: {excel_file_path}")调用通义千问的API进行分析
import pandas as pd
import requests
import json
# 读取 Excel 文件
file_path = 'your_xlsx_file_path'
df = pd.read_excel(file_path)
# 将 DataFrame 转换为 JSON 格式
data_dict = df.to_dict(orient='records')
# Qwen-long API 的配置
api_key = 'your_api_key' # 替换为你的 API 密钥
api_url = 'your_api_url' # 替换为你的 API 端点
# 构建请求体
payload = {
"model": "qwen-long", # 这里替换为你想要使用的模型ID
"messages": [
{"role": "user", "content": str(record)} for record in data_dict # 假设每条记录都是用户输入
]
}
# 设置请求头
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
try:
# 发送 POST 请求
response = requests.post(api_url, json=payload, headers=headers)
response.raise_for_status() # 如果响应状态不是 200 类型,抛出异常
except requests.exceptions.RequestException as e:
print(f"请求过程中发生错误: {e}")
if response.status_code == 400 and hasattr(response, 'text'):
print("详细错误信息:")
print(response.text) # 打印详细的错误信息
exit(1)
# 检查响应并提取 content 字段
result = response.json()
if result and 'choices' in result and len(result['choices']) > 0:
message_content = result['choices'][0]['message']['content']
else:
message_content = "没有找到有效的响应内容。"
output_file = 'your_save_path'
with open(output_file, 'w', encoding='utf-8') as file:
file.write(message_content)
print(f'结果已保存到 {output_file}')报错及其解决方式:
- 请求过程中发生错误: 400 Client Error: Bad Request for url:https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions 详细错误信息:{"error":{"code":"invalid_parameter_error","param":null,"message":"Single round file-content exceeds token limit, please use fileid to supply lengthy input.","type":"invalid_request_error"},"id":"chatcmpl-2276f596-e854-9cc9-8201-e0c31e0f1b27"}
- api_url输入错误
解决方式:
- 内容的长度超过了允许的token限制,对于这个报错,我是在如数的.xlsx文件做了删减。
- api_url我没有找到具体的查询方式,所以我是通过:阿里云控制台首页 (aliyun.com),有一个阿里云AI助理,在里面对他进行提问即可,比如说我用的是qwen-long模型,那么我提问的是:“Qwen-Long模型的API端点地址是什么”,得出答案后写入代码中
结果呈现
.xlsx文件:
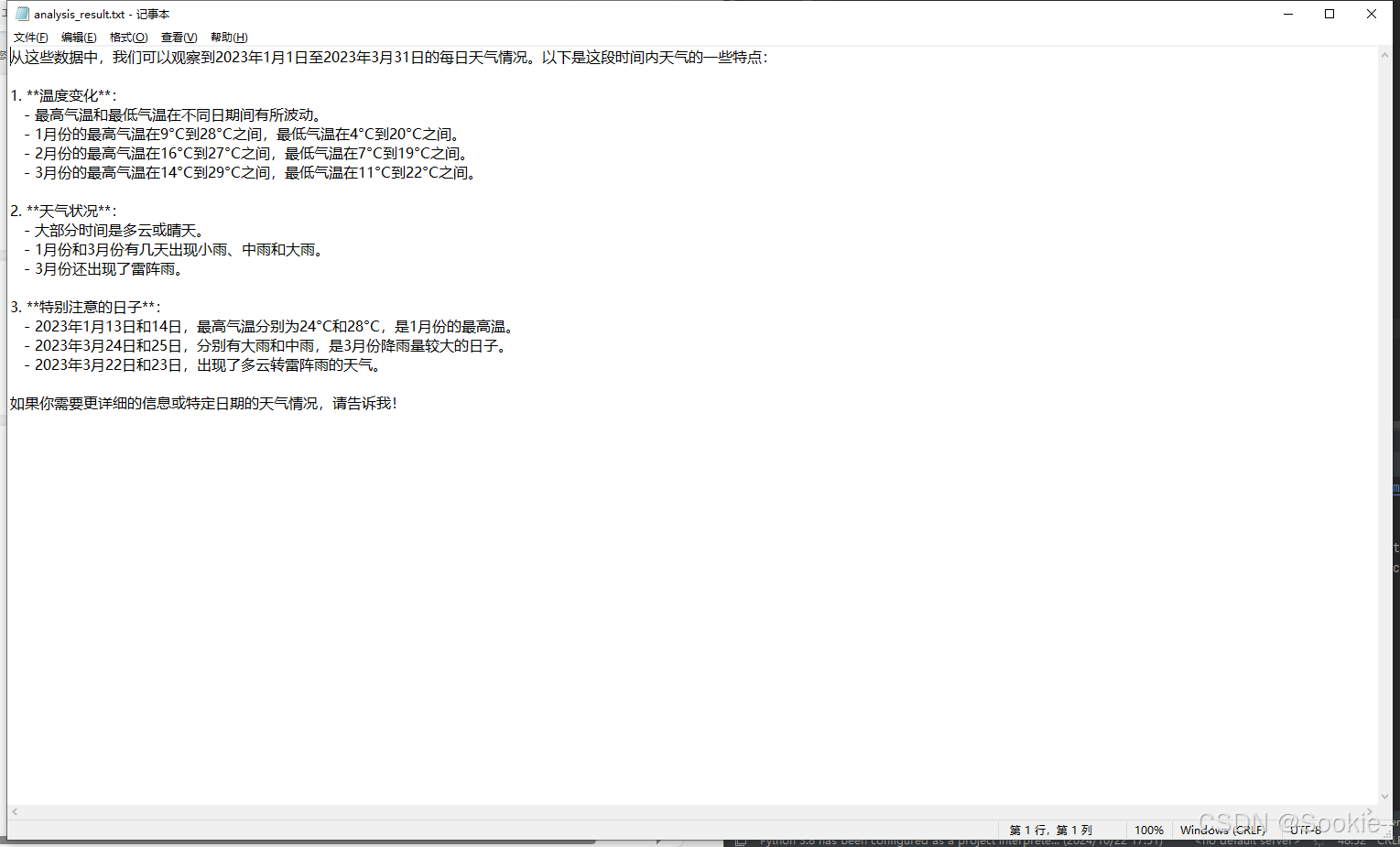
调用API-key生成的语句,保存到.txt文件:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于Pyecharts的数据可视化开发(二)调用通义千问api分析爬虫数据

发表评论 取消回复