Mobilenetv
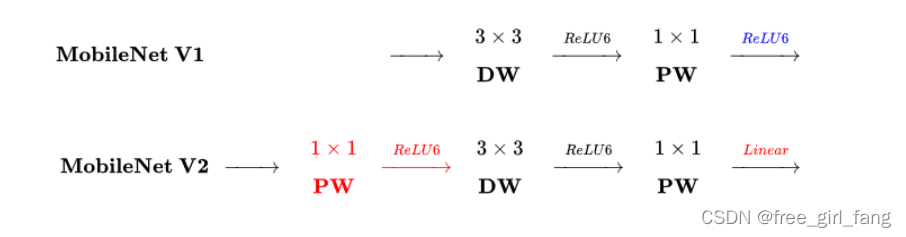
创新点
- 在于DW卷积与PW卷积
传统卷积是224-224-3 卷积核 5-5-3-K 输出为 117-117-K
DW卷积 224-224-3 卷积核 5-5-3 输出为 117-117-3 输入等于输出的通道数
PW卷积 224-224-3 卷积核 1-1-3-k 输出为 117-117-k
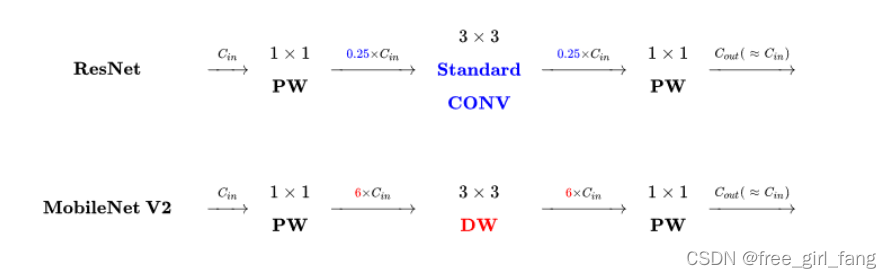
Mobilenet卷积:3x3 Depthwise Conv+BN+ReLU 和 1x1 Pointwise Conv+BN+ReLU - 使用快速通道残差,先升维再降维
- V2 激活函数 relu6
- V3 引入SE结构,使用新的H SWISH 激活函数 文章中最后一层模块使用线性激活函数
```bash
from torch import nn
import torch
def _make_divisible(ch,divisor=8,min_ch=None):
if min_ch is None:
min_ch=divisor
new_ch=max(min_ch,int(ch+divisor/2)//divisor*divisor)
if new_ch<0.9*ch
new_ch+=divisor
return new_ch
class ConvBNReLU(nn.Sequential):
def__init__(self,in_channel,out_channel,kernel_size=3,stride=1,group=1):
padding=(kernel_size-1)//2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel,out_channel,kernel_size,stride,padding,groups=groups,bias=False),
nn.BatchNormal2d(out_channel),
nn.ReLU6(inplace=True)
class InvertedResidual(nn.Module):
def __init__(self,in_channel,out_channel,stride,expand-ratio):
super(InvertedResidual,self).__init__()
hidden_channel=in_channel*expand_ratio
self.use_shortcut=stride==1 and inchannel==out_channel
layer=[]
if expand_ratio!=1:
#如果有扩大因子那么就使用1*1分离卷积
layers.append(ConvBNReLU(in_channel,hidden_channel,kernel_size=1))
layers.extend([ConvBNReLU(hidden_channel,hidden_channel,stride=stride,groups=hidden_channels),
#3*3卷积核卷积
nn.Conv2d(hidden_channel,out_channel,kernel_size=1,bias=False),
nn.BatchNorm2d(out_channel),])
#没有bn层
self.conv=nn.Sequential(*layers)
def forward(self,x):
if self.use_shortcut:
return x+self.conv(x)
else
return self.conv(x)
class MobileNetV2(nn.Module):
def__init__(self,num_classes=1000,alpha=1.0,round_nearest=8):
super(MobileNetV2,self).__init__()
block=InvertedResidual
input_channel=_make_divisible(32*alpha,round_nearest)
last_channel=_make_divisible(1280*alpha,round_nearest)
inverted_residual_setting=[
[1,16,1,1],
[6,24,2,2],
#第一个参数是扩大因子 第二个是层数输出的通道数 第三个是这样的模块个数 第四个是stride
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features=[]
features.append(ConvBNReLU(3,input_channel,stride=2))
for t,c,n,s in inverted_residual_setting:
output_channel=_make_divisible(c*alpha,round_nearest)
for i in range(n):
stride=s if i=i==0 else 1
features.append(block(input_channel,output_channel,stride,expand_radio=t)
input_channel=output_channel
features.append(ConvBNReLU(input_channel,last_channel,1))
self.features=nn.Sequential(*features)
self.avgpool=nn.AdaptiveAvgPool2d((1,1))
self.classifier=nn.Sequential(
nn.Dropout(0.2)
nn.Linear(last_channel,num_classes)
)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.zeros_(m.bias)
def forward(self,x):
x=self.features(x)
x=self.avgpool(x)
x=torch.flatten(x.1)
x=self.classifier(x)
return x
训练
import os
import json
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision import transforms, datasets
import tqdm import tqdm
from model_v2 import MobileNetV2
def mian():
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
batch_size=64
epochs=5
data_transform={
"train":transforms.Compose([transforms.RandomResizeCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5].[0.5,0.5,0.5]),
"val":transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])])
}
data_root=os.path.abspath(os.path.join(os.getcwd(),"../.."))
image_path=os.path.join(data_root,"data_set","flower_data")
assert os.path.exists(image_path),"{} path does not exist.".format(image_path)
train_dataset=datasets.ImageFolder(root=os.path.join(imge_path,"train",transform=data_transform["train"])
train_num=len(train_dataset)
flower_list=train_dataset.class_to_idx
cla_dict=dict((val,key) for key,val in flower_list.items())
json_str=json.dump(cla_dict,indent=4)
with open('class_indices.json','w') as json_file:
fson_file.write(json_str)
nw=min([os.cpu_count(),batch_size if batch_size>1 else 0,8])
print("using {} dataloader workers every process'.format(nw))
train_loader=torch.utils.data.DataLoader(train_dataset,batch_size=batch_size=batch_size,shuffle=True,num_workers=nw)
validate_dataset=datasets.ImageFolder(root=os.path.join(image_path,"val"),transform=data_transform["val"])
val_num=len(validate_dataset)
validate_loader=torch.util.data.DataLoader(validate_dataset.batch_size=batch_size,shuffle=False,num_workers=nw)
net=MobileNetV2(num_classes=5)
model_weight_path="./mobilenet_v2.pth"
assert os.path.exists(model_weight_path),"file {} dose not exist.".format(model_weight_path)
pre_weights=torch.load(model_weight_path,map_location=device)
pre_dict={k:v for k,v in pre_weights.items() if net.state_dict()[k].numel()==v.numel()}
missing_key,unexpected_keys=net.load_state_dict(pre_dict,strict=False)
for param in net.features.parameters():
param.requires_grad=False
net.to(device)
loss_function=nn.CrossEntropyLoss()
params=[p for p in net.parameters() if p.requires_grad]
optimizer=optim.Adam(params,lr=0.0001)
best_acc=0.0
save_path='./MobileNetV2.pth'
train_steps=len(train_loader)
for epoch in range(epochs):
net.train()
running_loss=0.0
train_bar=tpdm(train_loader)
for step,data in enumerate(train_bar):
images,labels=data
optimizer.zero_grad()
logits=net(image.to(device))
loss=loss_function(logits,label.to(device))
loss.backward()
optimizer.step()
running_loss+=loss.item()
train_bar.desc="trian epoch[{}/{}] loss:{:.3f}".format(epoch+1,epoches,loss)
net.eval()
acc=0.0
with torch.no_grad():
val_bar=tqdm(validate_loader)
for val_data in val_bar:
val_images,val_labels=val_data
outputs=net(image.to(device))
predict_y=torch.max(outputs,dim=1)[1]
acc+=torch.eq(predict_y,val_labels.to(device)).sum().item()
val_bar.desc="valid epoch[{}/{}]".format(epoch+1,epochs)
val_accurate=acc/val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch+1,running_loss/train_steps,val_accurate))
if val_accurate>best_acc:
best_acc=val_accurate
torch.save(net.state_dict(),save_path)
print('Finished Training')
if __name__=='__main__':
main()
预测
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model_v2 import MobileNetV2
def main():
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform=transforms.Compose(
[transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
img_path="../tulip.jpg"
assert os.path.exists(img_path),"file:'{}' dose not exist.".format(img_path)
img=Image.open(img_path)
plt.imshow(img)
img=data_transform(img)
img=torch.unsqueeze(img,dim=0)
json_file=open(json_path,"r")
class_indict=json.load(json_file)
model=ModileNetV2(num_classes=5).to(device)
model_weight_path="./MobileNetV2.pth"
model.load_state_dict(torch.load(model_weight_path,map_location=device))
model.eval()
with torch.no_grad():
output=torch.squeeze(model(img.to(device))).cpu()
predict=torch.softmax(output,dim=0)
predict_cla=torch.argmax(predict).numpy()
print_res="class:{} prob:{:.3}".format(class_indict[str(predict_cal)] ,predict[predict_cla].numpy()
plt.title(print_res)
print(print_res)
plt.show()
if__name__=='__main__':
main()
mobilenetv3
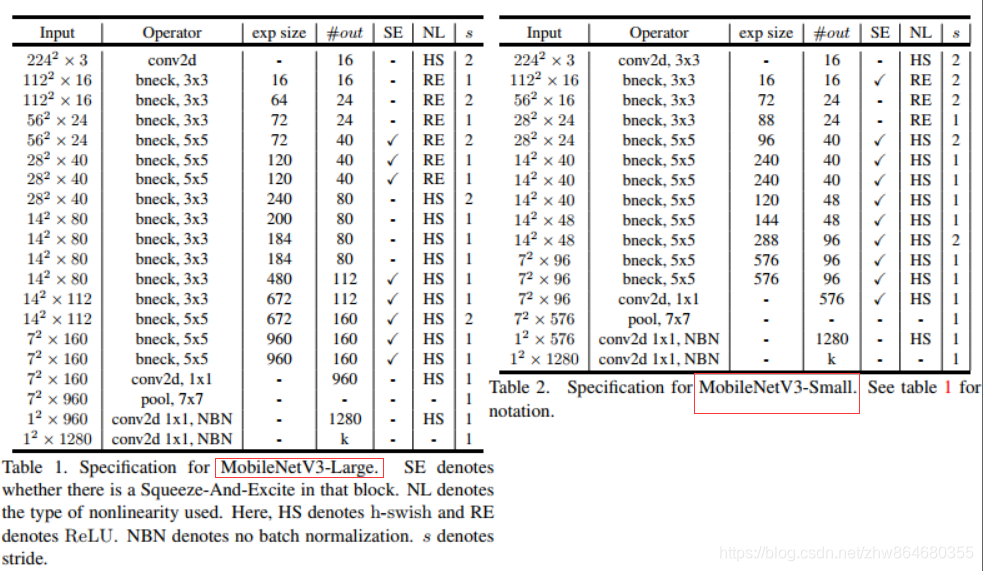
from typing import Callable,List,Optional
import torch
from torch import nn,Tensor
from torch.nn import function as F
from funtools import partial
def _make_divisible(ch,divisior=8,min_ch=None):
#使得channel 保持在8的倍数,更好的训练
if min_ch is None:
min_ch=divisor
new_ch=max(min_ch,int(ch+divisor/2)//divisor*divisor)
if new_ch<0.9 *ch
new_ch+=divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self,in_planes:int,out_planes:int=3,stride:int=1,group:int=1,norm_layer:Optional[Callable[...,nn.Module]]=None,activation_layer:Optional[Callable[...,nn.Module]]=None):#后两个是none
if norm_layer is None:
norm_layer=nn.BatchNorm2d
if activation_layer is None:
activeation_layer=nn.ReLU6
super(ConvBNActivation,self).__init__(nn.Conv2d(in_channels=in_planes,out_channels=out_planes,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bias=Flase), #group的使用是为了DW层
norm_layer(out_planes),
activation_layers(inplace=True))
#Mobilenetv3中的卷积层,带BN 与特殊激活函数的卷积层
class SqueezeExcitation(nn.Module):
#SE 模块 首先降维,默认参数是维度减少4倍,SE模块是两个全连接层,首先降维,之后升到与输入一样的维度,根据输出的重要程度与输入相乘得到输出
def __init__(self,input_c:int,squeeze_factor:int =4):
super(SqueezeExcitation,self).__init__()
squeeze_c=_make_divisible(input_c//squeeze_factor,8)
self.fc1=nn.Conv2d(input_c,squeeze_c,1)
self.fc2=nn.Conv2d(squeeze_c,input_c,1)
def forward(self,x:Tensor)->Tensor:
scale=F.adaptive_avg_pool2d(x,output_size=(1,1))
scale=self.fc1(scale)
scale=F.relu(scale,inplace=True)
scale=self.fc2(scale)
scale=F.hardsigmoid(scale,inpale=True)
return scale*x #重要程度与原输入相乘
#SE并非是一个并行模块而是一个串行模块
class InvertedResidualConfig:
#倒残差 se模块 残差就是输出与输入相加,所有卷积使用conBN
def__init__(self,input_c:int,kernet:int,expanded_c;int,
out_c:int,
use_se:bool,
activation:str,
stride:int,
width_multi:float):
self.input_c=self.adjust_channels(input_c,width_nulti)
self.kernel=kernel
self.expanded_c=self.adjust_channels(expanded_c,width_multi)
self.out_c=self.adjust_channels(out_c,width_multi)
self.use_se=use_se
self.use_hs=activation=="HS"
#是否使用新的激活函数
self.stride=stride
@staticmethod
def adjust_channels(channels:in,width_multi:float):
return _make_divisible(channels*width_muti,8)
class InvertedResidual(nn.Module):
def__init__(self,
cnf:InvertedResidualConfig,
norm_layer:Callable[...,nn.Module]):
super(InvertedResidual,self).__init__()
if cnf.stride not in [1,2]:
raise ValueError("illegal stride value.")
self.use_res_connect=(cnf.stride==1 and cnf.input_c ==cnf.out_c)
layers:List[nn.Module]=[] #类型是NN.module
activation_layer=nn.Hardswish if cnf.use_hs else nn.ReLU
if cnf.expanded_c!=cnf.input_c
#由于第一层输入输出一样 无扩大因子
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
#DW
norm_layer=norm_layer,
activation_layer=activation_layer))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
#SE
layers.append(ConvBNActivation(cnf.expanded_c,cnf.out_c,kernel_size=1,norm_layer=norm_layer,activation_layger=nn.Identity))
#PW
self.block=nn.Sequential(*layers)
self.out_channels=cnf.out_c
self.is_strided=cnf.stride>1
def forward(self,x:Tensor)->Tensor:
result=self.block(x)
if self.use_res_connect:
retult+=x
return result
class MobileNetV3(nn.Module):
def__init__(self,
inverted_residual_setting:List[InvertedResidualConfig],
last_channel:int,
num_classes:int=1000,
block:Optional[Callable[...,nn.Module]]=None,
norm_layer:Optional[Callable[...,nn.Module]]=None):
super(MobileNetV3,self).__init__():
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not(isinstance(inverted_residual_setting,List) and
all([isinstance(s,InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be
List[InvertedResidualConfig]")
if block is None:
block=InvertedResidual
if norm_layer if None:
norm_layer =partial(nn.BatchNorm2d,
eps=0.001,momentum=0.01) #存入默认参数
layers:List[nn.Module]=[]
firstconv_output_c=inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,firstconv_output_C,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
for cnf in inverted_residual_setting:
layers.append(block(cnf,norm_layer))
lastconv_input_c=inverted_residual_setting[-1].out_c
lastconv_output_c=6*lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features=nn.Sequential(*layers)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Sequential(nn.Linear(lastconv_output_c,last_channel,
nn.Hardwish(inpalce=True),
nn.Dropout(p=0.2,inplace=True),
nn.Linear(last_channel,num_classes))
for m in self.module():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode="fan_out")
if m.bias if not None:
nn.init.zeros_(m.bias)
elif isinstance(m,(nn.BatchNorm2d,nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self ,x:Tensor)->Tensor:
x=self.feature(x)
x=self.avgpool(x)
x=torch.flatten(x,1)
x=self.classifier(x)
return x
def forward(self,x:Tensor)->Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes:int=1000,reduced_tail:bool =False)->MobileNetV3:
width_multi=1.0
bneck_conf=partial(InvertedResidualConfig,width_multi=width_multh)
adjust_channels=partial(InvertedResidualConfig.adjust_channels,
width_multi=width_multi)
reduce_divider=2 if reducted_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
bneck_conf(16, 3, 16, 16, True, "RE", 2),
bneck_conf(16, 3, 72, 24, False, "RE", 2),
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 计算机视觉篇---图像分类实战+理论讲解(6)Mobilenet

发表评论 取消回复