PostgreSQL(以下简称PSQL)因其灵活性和强大的功能深受欢迎。本文将详细介绍PSQL的内部结构,特别是页面缓冲机制,包括表结构、TOAST技术、大对象(BLOB/CLOB),以及页面缓冲表的工作原理。同时,我们将探讨TOAST与大对象存储的区别与应用场景,并结合优化建议提升数据库性能。
1. PostgreSQL表结构
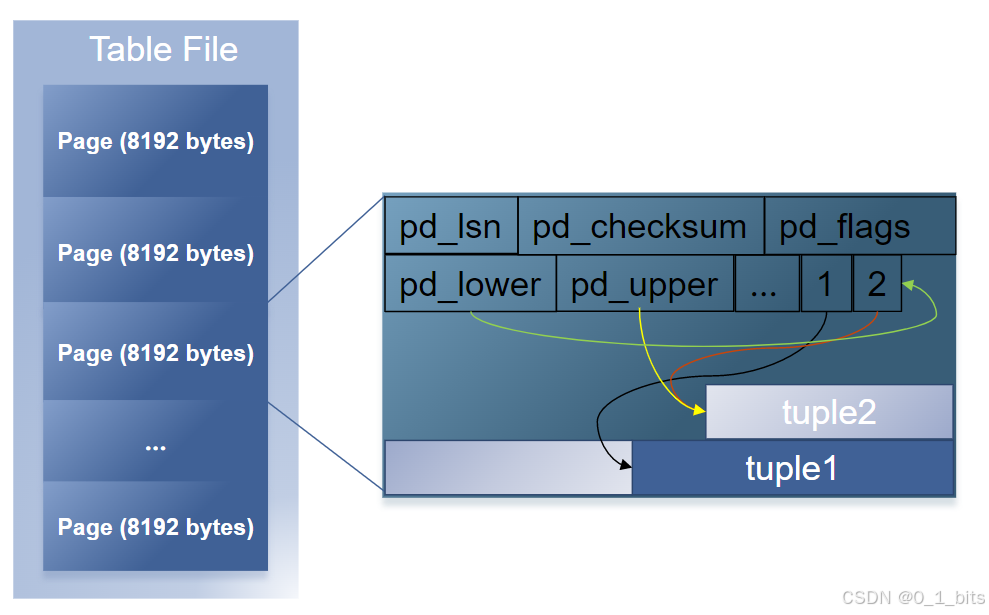
在PSQL中,表由固定大小的页面(Page)组成,每个页面通常为8KB。页面是数据读写的最小单位,其内部结构包括:
1.1 页面内部结构
-
首部数据:存储页面的元数据信息。
-
pd_lsn(Log Sequence Number):表示页面最近一次变更的日志序列号(LSN)。
示例:假设我们执行一个更新操作,将一个用户的名字从“John”改为“Jonathan”。这个操作会生成一个新的LSN,并记录在受影响页面的pd_lsn中,确保可以在崩溃后通过日志恢复该操作。 -
pd_checksum:页面校验和,用于验证页面的完整性。
示例:当读取页面时,PSQL会计算页面的校验和并与pd_checksum进行比较,以确保数据未被损坏。 -
pd_lower:指向元组指针数组的末尾位置。
示例:在一个页面中,pd_lower指向元组指针数组的末尾。如果我们插入一个新行,pd_lower将向下移动。 -
pd_upper:指向最新元组的起始位置。
示例:如果我们在页面中添加一个新元组,pd_upper将向上移动,标识空闲空间的减少。
-
-
指向元组的指针:用于定位页面中的各个元组(行数据)。
-
空闲空间:用于存储新的元组或更新现有元组。
-
元组数据:实际的行数据,不能跨页面存储。
PSQL采用32位寻址, 所以PSQL单表最大容量为2^32*8K,为32TB
1.2 表结构优化建议
为了提升表的性能和存储效率,以下是一些优化建议:
-
适当的索引设计:
- 为频繁查询的列创建索引,但要避免为每个列都创建索引,以免增加写操作的开销。
- 使用覆盖索引(Covering Index)来减少对表的访问次数,特别是在读取密集型应用中。
示例:假设有一个用户表
users,经常通过email查询用户信息,可以为email列创建索引:CREATE INDEX idx_users_email ON users(email); -
合理的表分区:
- 对于大表,考虑使用表分区(Partitioning)来提高查询性能。根据常用查询条件对表进行分区,例如按日期分区以加快时间范围查询。
示例:按年份分区存储日志数据:
CREATE TABLE logs ( id SERIAL PRIMARY KEY, log_date DATE, message TEXT ) PARTITION BY RANGE (log_date); CREATE TABLE logs_2023 PARTITION OF logs FOR VALUES FROM ('2023-01-01') TO ('2024-01-01'); CREATE TABLE logs_2024 PARTITION OF logs FOR VALUES FROM ('2024-01-01') TO ('2025-01-01'); -
使用合适的数据类型:
- 根据数据的实际用途选择合适的数据类型。例如,对于固定长度的字符串,使用
CHAR(n)而不是VARCHAR(n)。 - 使用
INTEGER代替BIGINT,除非确实需要存储非常大的整数。
示例:如果用户的姓氏长度固定为50个字符,可以使用:
CREATE TABLE users ( id SERIAL PRIMARY KEY, first_name VARCHAR(100), last_name CHAR(50) ); - 根据数据的实际用途选择合适的数据类型。例如,对于固定长度的字符串,使用
-
优化数据存储格式:
-
通过配置合适的
fillfactor来优化页面利用率。较低的填充因子可以减少页面分裂,但会增加磁盘空间使用。 -
fillfactor 的值是一个百分比,范围从 10 到 100,表示数据库在每个数据页面中预留的空间比例。例如:
fillfactor=100 表示页面将被完全填满,不预留空闲空间。
fillfactor=70 表示页面将在 70% 的空间被填满时停止插入数据,剩余 30% 的空间被保留。
使用 fillfactor 可以帮助控制表或索引的更新效率,特别是在有大量更新的表或索引中: -
高更新表:当表中有频繁的更新操作时,设置较低的 fillfactor 会为未来的更新操作留出足够的空间,避免数据行更新时需要进行页面拆分(Page Split)或在页面之间移动数据,从而提高性能。
-
只读表:对于插入后不经常更新的表,可以将 fillfactor 设置为 100,最大化页面的利用率,从而减少磁盘占用。
示例:为频繁更新的表设置较低的
fillfactor:CREATE TABLE orders ( id SERIAL PRIMARY KEY, order_data JSONB ) WITH (fillfactor = 70);
-
定期进行VACUUM操作:
- 定期执行
VACUUM和ANALYZE命令,以清理死元组并更新统计信息,确保查询优化器能够生成高效的查询计划。
示例:
VACUUM ANALYZE; - 定期执行
-
监控和优化查询:
- 使用
EXPLAIN命令分析查询计划,识别潜在的性能瓶颈。 - 使用查询日志和慢查询日志来监控性能,识别需要优化的查询。
示例:
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'example@example.com'; - 使用
2. TOAST技术
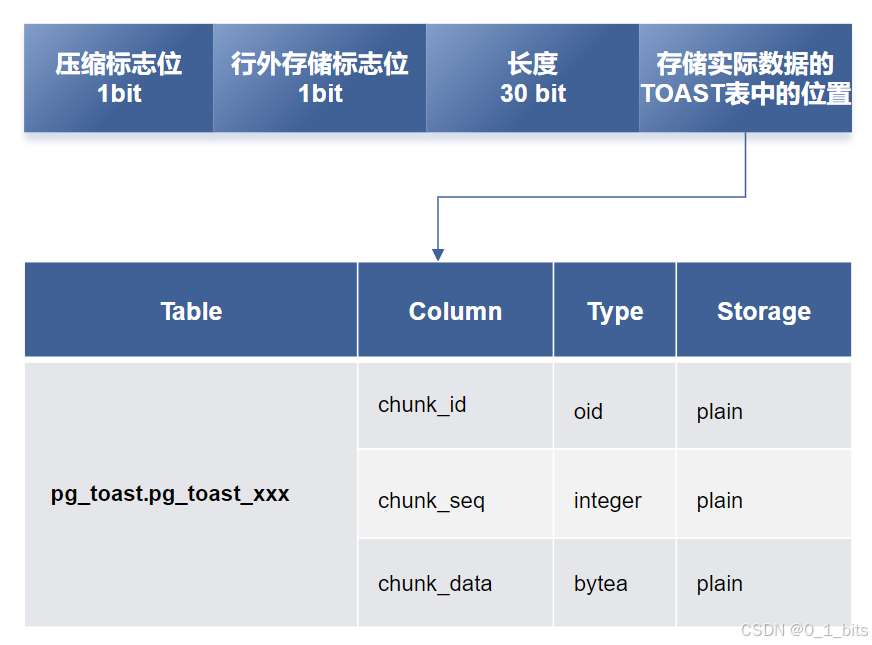
TOAST(The Oversized-Attribute Storage Technique)用于处理超大数据属性。PSQL通过TOAST技术将大数据分成较小块存储,具体策略如下:
- 压缩:如果策略允许,TOAST优先对数据进行压缩,尤其是小于
TOAST_TUPLE_THRESHOLD(约2KB)的数据。 - 行外存储:对于超过2KB的数据,启用行外存储。
- 30位长度限制:在TOAST中,单个字段的最大大小实际上受到30位偏移量的限制。这是因为TOAST使用一个30位的整数来表示这些块的偏移量。理论上,这意味着最大字段大小大约是1GB
示例:假设我们有一个包含大量文本的列,如文章内容。默认情况下,PSQL会尝试压缩并存储超过2KB的部分在TOAST表中。
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
content TEXT
);
当content列的内容超过2KB时,TOAST会自动处理,将数据分块存储在TOAST表中。
2.1 TOAST策略
TOAST策略包括:
- PLAIN:避免压缩和行外存储。
- EXTENDED:允许压缩和行外存储(默认策略)。
- EXTERNAL:允许行外存储,但禁止压缩。
- MAIN:允许压缩,但禁止行外存储。
示例:为content列设置不同的TOAST策略:
CREATE TABLE articles_plain (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
content TEXT
) WITH (toast_tuple_target = 2048);
ALTER TABLE articles_plain ALTER COLUMN content SET STORAGE EXTERNAL;
CREATE TABLE articles_extended (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
content TEXT
) WITH (toast_tuple_target = 2048);
ALTER TABLE articles_extended ALTER COLUMN content SET STORAGE EXTENDED;
3. 大对象(BLOB/CLOB)存储
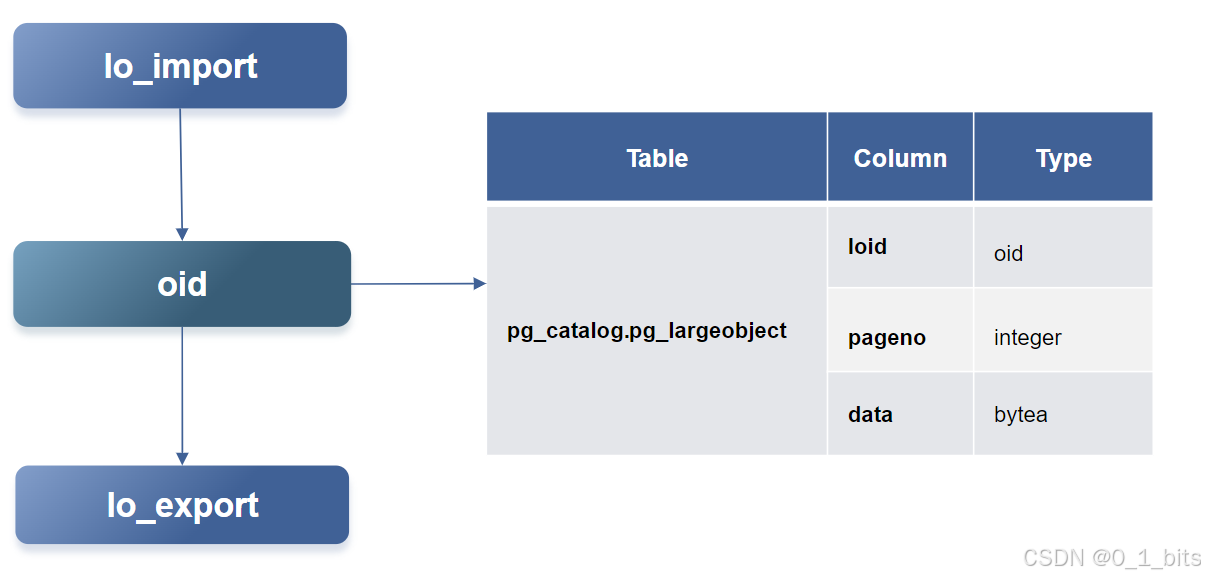
BLOB(Binary Large Object)和CLOB(Character Large Object)用于存储大型二进制和文本数据。
- 最大容量:每个对象最大可达4TB。
- 存储位置:数据存储在
pg_largeobject系统表中。 - 数量限制:最多支持 (2^{32}) 个大对象,因为OID(对象标识符)为32位。
示例:如果我们要存储一个4GB的视频文件,可以将其作为BLOB存储在PSQL中,每段数据被分成多个片段存储在pg_largeobject中。
BEGIN;
-- 创建大对象
SELECT lo_create(0) AS oid;
-- 假设获取的oid是 12345
-- 打开大对象
SELECT lo_open(12345, 131072) AS fd;
-- 写入数据到大对象(假设数据为 'video_data')
SELECT lowrite(fd, 'video_data');
-- 关闭大对象
SELECT lo_close(fd);
COMMIT;
3.1 大对象存储与TOAST的区别
-
使用场景:
- TOAST适用于自动管理大数据的表列,如存储超长的文本或JSON数据。
- 大对象适用于需要程序手动管理的数据块,如存储视频、音频等大型二进制文件。
-
存取方式:
- TOAST数据存取是自动的,用户看不到TOAST表,操作透明。
- 大对象需要应用程序显式读写,需使用PostgreSQL提供的函数进行管理。
-
大小限制:
- TOAST处理的数据大小受限于表行的存储容量。
- 大对象可处理更大的数据块,支持高达4TB的存储。
总结:TOAST适合无需手动管理的大数据列,而大对象适合需要精细控制和管理的超大数据存储。
4. 页面缓冲表
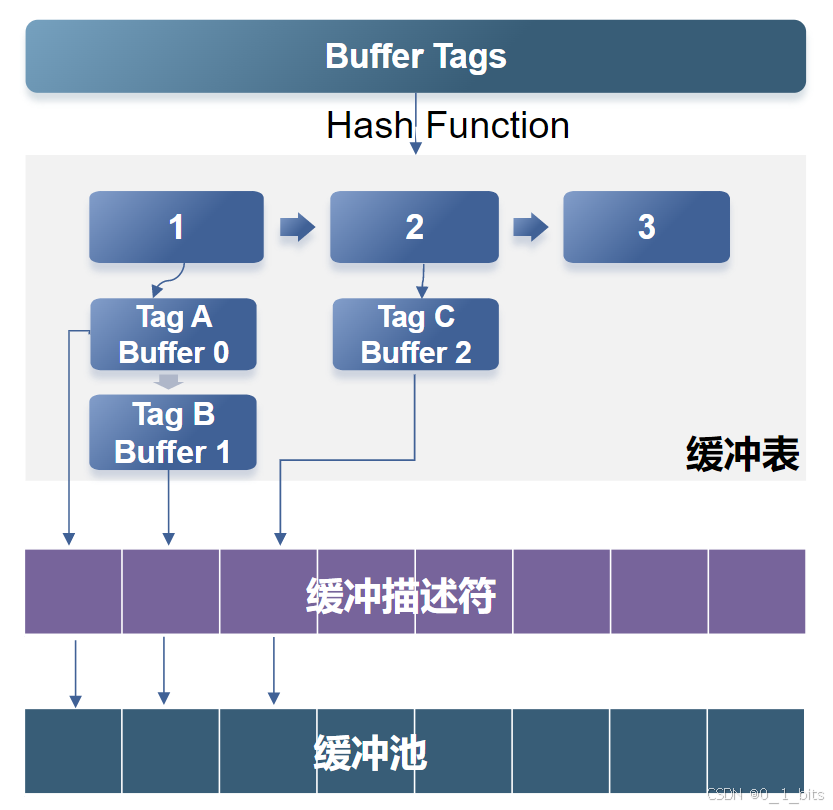
页面缓冲机制是PSQL性能优化的关键组件,确保数据在内存中的高效访问。页面缓冲表的结构如下:
4.1 页面缓冲机制概述
-
缓冲区标签 (Buffer Tag):唯一标识一个页面。
-
RelFileNode:文件节点,标识特定的数据库对象。
示例:一个数据库文件在存储系统中的唯一标识符。 -
Table space node:表空间节点。
示例:如果我们有不同的表空间用于存储数据,Table space node将帮助区分这些空间。 -
dbNode:数据库节点。
示例:用于标识具体的数据库,如生产数据库或测试数据库。 -
relNode:关系节点。
示例:标识具体的表或索引。 -
forkNum:标识页面类型,如表、FSM(自由空间映射)、VM(可见性映射)。
示例:用于区分不同的页面用途,如存储数据或索引。 -
blockNum:页面索引。
示例:指定在文件中的具体页码。
-
-
缓冲区描述符:
- Buffer Tag和Buffer Id:标识和定位缓冲区内的页面。
- 多分区缓冲区锁:用于并发访问控制。
- Reference Count:当前访问此页面的进程数。
- Usage Count:页面被访问的次数。
4.2 描述符状态
- 空:
Ref & usage count == 0,表示页面未被使用。 - 未钉住:
Ref count == 0 && usage count > 0,页面在缓冲区中但未被锁定。 - 钉住:
Ref count > 1 && usage count > 1,页面被多个进程访问且被锁定。
示例:如果一个页面在短时间内被频繁访问,其Usage Count将递增,提高其在缓冲区中的优先级,减少被淘汰的可能性。
4.3 页面缓冲机制的优化
为了提升页面缓冲机制的效率,可以采取以下优化措施:
-
调节缓冲区大小:
- 根据服务器内存和工作负载调整
shared_buffers参数,以确保足够的缓冲区用于热点数据。
示例:
shared_buffers = 4GB - 根据服务器内存和工作负载调整
2.监控缓冲区命中率:
- 通过监控缓冲区命中率(buffer hit rate)来评估缓冲区配置的有效性,调整参数以优化性能。
示例:
SELECT
sum(blks_hit) / sum(blks_read + blks_hit) AS hit_rate
FROM
pg_stat_database;
5. TOAST与大对象存储的综合应用解析
在PostgreSQL数据库中,处理大数据时常会遇到TOAST与大对象存储的选择问题。了解它们的区别与应用场景,有助于在数据库设计中做出明智的选择。
5.1 使用场景对比
-
TOAST:
- 适用于表列内自动管理的大数据,如存储超长文本、JSON、数组等。
- 自动处理,无需用户干预,适合简单应用场景。
-
大对象:
- 适用于需要程序手动管理的数据块,如视频、音频、图像等大型二进制文件。
- 提供更细粒度的控制,适合需要精细数据操作的复杂应用场景。
5.2 存取方式对比
-
TOAST:
- 数据存取是透明的,用户通过常规的SQL语句操作表数据,TOAST在背后自动处理。
-
大对象:
- 需要应用程序通过PostgreSQL提供的函数显式读写,如
lo_create、lo_open、lowrite、lo_read等。
示例:
BEGIN; -- 创建大对象 SELECT lo_create(0) AS oid; -- 假设获取的oid是 12345 -- 打开大对象 SELECT lo_open(12345, 131072) AS fd; -- 写入数据到大对象(假设数据为 'binary_data') SELECT lowrite(fd, 'binary_data'); -- 关闭大对象 SELECT lo_close(fd); COMMIT; - 需要应用程序通过PostgreSQL提供的函数显式读写,如
5.3 大小限制对比
-
TOAST:
- 处理的数据大小受限于表行的存储容量,通常适用于单列数据超过2KB但不至于极大的数据。
-
大对象:
- 支持高达4TB的存储,适合存储非常大的数据块。
5.4 选择建议
- 如果数据的大小和访问模式适合表列自动处理,且无需精细控制,选择TOAST更为简便高效。
- 如果需要存储和管理极大的数据块,并且需要对数据的读写进行精细控制,选择大对象更为合适。
结论
通过深入理解PSQL的内部结构和页面缓冲机制,以及掌握TOAST与大对象存储的区别与应用场景,用户可以显著提高数据库的性能和响应速度。这不仅支持更高效的应用程序开发和运行,还能在复杂的数据处理需求中提供卓越的支持。
综合优化建议
- 合理设计表结构和索引,确保数据存取高效。
- 根据数据特点选择合适的存储机制,如TOAST或大对象。
- 优化缓冲区配置,提升内存利用率和数据访问速度。
- 定期维护数据库,通过
VACUUM和ANALYZE保持数据健康和查询优化。 - 监控数据库性能,通过日志和统计信息发现并解决潜在的性能瓶颈。
希望本文为您提供了有价值的见解。如有疑问或需进一步探讨,欢迎交流!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » PostgreSQL的奥秘:表结构、TOAST与大对象

发表评论 取消回复