
在之前的学习中,已经对时间序列预测的相关内容有了大致的了解。为了进一步加深理解,并能够将所学知识应用于实际中,我决定找一个完整的Python框架来进行深入学习。经过寻找,我终于找到了一篇非常具有参考价值的源代码,非常感激。
接下来,我将详细记录自己的学习过程和心得,以便更好地掌握和应用时间序列预测技术。
这个项目的目录结构如下,展示了一个使用不同深度学习框架(Keras、PyTorch 和 TensorFlow)来进行股票价格预测的 Python 框架,包含多个模型文件和预测图像。
stock_predict_with_LSTM-master
│
├── data # 存放数据集
│ └── stock_data.csv
│
├── figure # 存放预测结果的图像
│ ├── continue_predict_high_with_pytorch.png
│ ├── continue_predict_low_with_pytorch.png
│ ├── predict_high_with_pytorch.png
│ └── predict_low_with_pytorch.png
│
├── model # 存放不同框架下的模型文件
│ ├── __pycache__ # Python 缓存目录
│ │ ├── __init__.cpython-38.pyc
│ │ └── model_pytorch.cpython-38.pyc
│ ├── __init__.py # 包声明文件
│ └── model_pytorch.py # PyTorch 模型实现
│
├── .gitignore # Git忽略文件,列出不提交到仓库的文件类型
├── LICENSE # 项目的许可证
├── main.py # 项目的主入口,通常是执行的主程序
├── README.md # 项目说明文档,介绍如何运行和使用该项目
├── requirements.txt # 列出项目依赖的 Python 包
一、data文件
该文件夹主要用于存放数据集,这里只有一个数据集,是.csv文件,部分数据如下图所示。
| index_code | date | open | close | low | high | volume | money | change |
| sh000001 | 1990/12/20 | 104.3 | 104.39 | 99.98 | 104.39 | 197000 | 85000 | 0.044109 |
| sh000001 | 1990/12/21 | 109.07 | 109.13 | 103.73 | 109.13 | 28000 | 16100 | 0.045407 |
| sh000001 | 1990/12/24 | 113.57 | 114.55 | 109.13 | 114.55 | 32000 | 31100 | 0.049666 |
| sh000001 | 1990/12/25 | 120.09 | 120.25 | 114.55 | 120.25 | 15000 | 6500 | 0.04976 |
| sh000001 | 1990/12/26 | 125.27 | 125.27 | 120.25 | 125.27 | 100000 | 53700 | 0.041746 |
| sh000001 | 1990/12/27 | 125.27 | 125.28 | 125.27 | 125.28 | 66000 | 104600 | 7.98E-05 |
| sh000001 | 1990/12/28 | 126.39 | 126.45 | 125.28 | 126.45 | 108000 | 88000 | 0.009339 |
二、figure文件夹
该文件夹主要用于存放不同框架(如 PyTorch、Keras、TensorFlow)进行股票高价和低价预测的结果图像。
三、model文件夹
1、__pycache__文件夹
__pycache__ 目录是 Python 自动生成的,用于存储已编译的字节码文件(.pyc 文件)。这些文件通常不需要手动编辑或提交到版本控制系统中,但 .gitignore 文件(后面介绍)通常会包含规则来忽略这些文件。
2、__init__.py文件
主要是用于声明 model是一个 Python 包,可以被导入到其他模块中。文件夹里为空。
主要展示使用Keras的深度学习框架来构建 LSTM 模型进行股票预测
3、model_pytorch.py文件(主要学习)
主要展示使用PyTorch的深度学习框架来构建 LSTM 模型进行股票预测
(1)定义模型类
定义一个名为Net的类,包含了LSTM(长短期记忆)层和全连接层。这个模型通过LSTM层处理时间序列数据,捕获数据中的长期依赖关系,然后通过全连接层将LSTM的输出(形状是 [batch_size, sequence_length, hidden_size])映射到期望的输出大小(形状是[batch_size, hidden_size])。
# 定义模型类
class Net(Module):
'''
定义包含LSTM和全连接层的PyTorch模型,用于时间序列预测。
'''
# 其中,Config 是一个用于配置模型训练、验证和预测过程的参数集合,
# 通常定义在一个单独的配置文件或类中(这里定义在main.py)。它包含关于模型结构、训练设置、数据路径等的关键参数。
def __init__(self, config):
super(Net, self).__init__()
# 初始化LSTM层:输入为config.input_size,隐藏单元为config.hidden_size,层数为config.lstm_layers
# batch_first=True表示输入张量的第一个维度是批次大小,dropout=config.dropout_rate指定在LSTM层之间应用的dropout率,以防止过拟合。
self.lstm = LSTM(input_size=config.input_size, hidden_size=config.hidden_size,
num_layers=config.lstm_layers, batch_first=True, dropout=config.dropout_rate)
# 初始化全连接层 :用于将LSTM的最后输出映射为期望的输出大小
self.linear = Linear(in_features=config.hidden_size, out_features=config.output_size)
def forward(self, x, hidden=None):
# 前向传播
lstm_out, hidden = self.lstm(x, hidden)
# 提取LSTM的最后时间步输出,输入到全连接层
linear_out = self.linear(lstm_out[:, -1, :])
return linear_out, hidden lstm_out[:, -1, :] 仅提取了 LSTM 输出的最后一个时间步的数据。其中 : 表示选择所有样本(在第一个维度上);-1 表示选择最后一个时间步(在第二个维度上),这并不是说第二个维度“消失了”,而是说它在这个特定的索引操作中不再以原来的大小存在,被“压缩”了; : 表示选择该时间步的所有隐藏状态特征(在第三个维度上)。因此,这个操作的结果是一个形状为 [batch_size, hidden_size] 的张量。 属于单步预测。
(2)定义训练函数
def train(config, logger, train_and_valid_data): 这里的输入有三个:
Config 是用于配置模型的参数集合,logger 用于输出训练日志,train_and_valid_data 是包含训练和验证数据的元组或列表(train_X, train_Y, valid_X, valid_Y)
a、首先要分离数据,并创建数据加载器
分离成训练和验证两个数据集,这里使用DataLoader和TensorDataset创建数据加载器,可以分批次输入数据并计算损失,降低对计算资源的需求
# 创建DataLoader
train_loader = DataLoader(TensorDataset(train_X, train_Y), batch_size=config.batch_size)
valid_loader = DataLoader(TensorDataset(valid_X, valid_Y), batch_size=config.batch_size) TensorDataset(train_X, train_Y)将训练集特征和目标打包到一起,使得DataLoader能够一次性处理对应的输入和目标DataLoader用于将TensorDataset生成的小批次数据集,用config.batch_size指定每个批次的样本数量。
b、设置设备,并将模型移动到指定设备
device = torch.device("cuda:0" if config.use_cuda and torch.cuda.is_available() else "cpu") 这段代码用于检测用户配置和系统是否满足 GPU 的使用条件。如果满足(即use_cuda=True 且系统检测到 GPU),则选择 cuda:0(第一个 GPU)作为训练设备;否则,选择 cpu
之后将模型移动到指定设备
# 初始化模型并移动到指定设备
model = Net(config).to(device) 这里还涉及到 “增量训练”,
# 增量训练(如果配置中启用了增量训练) ,加载已保存的模型参数
if config.add_train:
model.load_state_dict(torch.load(config.model_save_path + config.model_name)) 具体介绍可参考这篇文章介绍:
时间序列预测(十三)——增量训练(Incremental Learning)-CSDN博客
c、初始化优化器和损失函数
使用Adam优化器来更新模型参数。使用均方误差(MSE)作为损失函数。
d、 训练循环
在所有的训练周期(epoch)内都要进行俩个模式:训练模式和评估模式。
model.train() # 设置模型为训练模式 在训练模式下,遍历训练数据加载器,进行前向传播、计算损失、反向传播和参数更新。根据配置决定是否清除隐藏状态的梯度。如果启用了可视化,则绘制训练损失。
这里损失计算时会有问题,需要将_train_Y 的形状与pred_Y 形状(二维)匹配,以便能够正确计算损失
_train_Y = _train_Y[:, -1, :] # 选择最后一个时间步的输出,形状为 [64, 2]结束后,设置模型为评估模式。
model.eval() # 设置模型为评估模式 遍历验证数据加载器,计算验证损失。计算并输出当前轮次的训练和验证损失。如果启用了可视化,则绘制每个轮次的训练和验证损失。
这里也有问题,需要将_valid_Y 的形状与pred_Y 形状(二维)匹配,以便能够正确计算损失
_valid_Y = _valid_Y[:, -1, :] # 选择最后一个时间步的输出,形状 [64, 2]最后还设置了早停机制。
if valid_loss_cur < valid_loss_min:
valid_loss_min = valid_loss_cur
bad_epoch = 0
# 保存最优模型
torch.save(model.state_dict(), config.model_save_path + config.model_name)
else:
bad_epoch += 1
if bad_epoch >= config.patience: # 若验证集损失未减小,则提前终止训练
logger.info(" The training stops early in epoch {}".format(epoch))
break 根据早停机制,如果验证损失达到新低(即当前验证损失小于之前记录的最小验证损失),则保存模型并重置早停计数器;否则(即,验证损失没有改善),则增加早停计数器,如果早停计数器超过了配置的耐心值(patience),则提前终止训练。
有关训练模式和评估模式的区别可以参考下面这篇文章:
时间序列预测(十二)——训练模式、评估模式和预测模式的区别-CSDN博客
(3)定义预测函数
def predict(config, test_X): 这里的输入有两个:
Config 是用于配置模型的参数集合,test_X:是测试数据集。
之后和训练函数有些相似
a、创建数据加载器
# 转换测试数据为Tensor
test_X = torch.from_numpy(test_X).float()
test_set = TensorDataset(test_X)
test_loader = DataLoader(test_set, batch_size=1)
b、设置设备,并将模型移动到指定设备
device = torch.device("cuda:0" if config.use_cuda and torch.cuda.is_available() else "cpu")
model = Net(config).to(device)
model.load_state_dict(torch.load(config.model_save_path + config.model_name)) c、进行预测
首先,将模型设置为评估模式
model.eval() 之后,遍历测试数据加载器,对于每个批次的数据:将数据移动到指定的设备上,使用模型进行预测,并更新隐藏状态。
这里还会使用 torch.squeeze(pred_X, dim=0) 移除预测结果中多余的维度(这是由于数据加载器 DataLoader 的批次大小设为1(batch_size=1),那么预测结果 pred_X 的形状会是 [1, sequence_length, features],其中第一个维度(批次维度)仅包含单个元素。为简化后续处理,可移除该批次维度,使 pred_X 形状变为 [sequence_length, features]。)。
也使用 torch.cat((result, cur_pred), dim=0) ,将每次预测的结果cur_pred在指定的维度(这里是维度0,即行的方向)上与result进行拼接,添加到result中,从而汇总所有的预测结果。
data_X = _data[0].to(device)
pred_X, hidden_predict = model(data_X, hidden_predict)
cur_pred = torch.squeeze(pred_X, dim=0) # 移除多余的维度
result = torch.cat((result, cur_pred), dim=0) # 拼接预测结果 最后使用 detach() 方法将 result从计算图中分离,并移动到CPU上,使用 .numpy() 方法将Tensor转换为NumPy数组,以便后续处理。
return result.detach().cpu().numpy() 四、剩下的文件
1、.gitignore:
用于告诉 Git 哪些文件或文件夹不应该提交到版本控制系统中。通常包含 .pyc 缓存文件、虚拟环境文件等。

2、LICENSE:
项目的开源许可证,指明项目的使用权利和限制。这里是一个宽松的开源许可证Apache许可证2.0

3、main.py:
该文件是项目的主入口,应该包含整个项目的运行逻辑。通常从这里加载数据、构建模型并进行训练和预测。
(1)配置类 (Config)
a、数据参数:
定义特征列和目标列的索引,设置预测的天数。
b、网络参数:
包括输入输出大小、LSTM层数、隐藏层大小、dropout概率和时间步长。
c、训练参数:
训练和验证的设置(如批量大小、学习率、训练周期等),并配置随机种子以确保结果可复现。
d、路径参数:
定义数据、模型、图形和日志文件的保存路径,并创建必要的目录。
(2)数据处理类 (Data)
a、数据读取:
def read_data(self):读取CSV文件,如果处于调试模式 (debug_mode),则只读取部分数据(debug_num 行)。否则,读取的数据包含特定的特征列 (feature_columns)。最后返回数据值和列名
b、获取训练和验证数据:
def get_train_and_valid_data(self):从归一化后的数据中提取特征数据和标签数据,根据是否连续训练 (do_continue_train),采用不同的方式(非连续训练模式和连续训练模式,都是滑动窗口)生成训练样本 (train_x 和 train_y),使用 train_test_split 方法划分训练集和验证集。
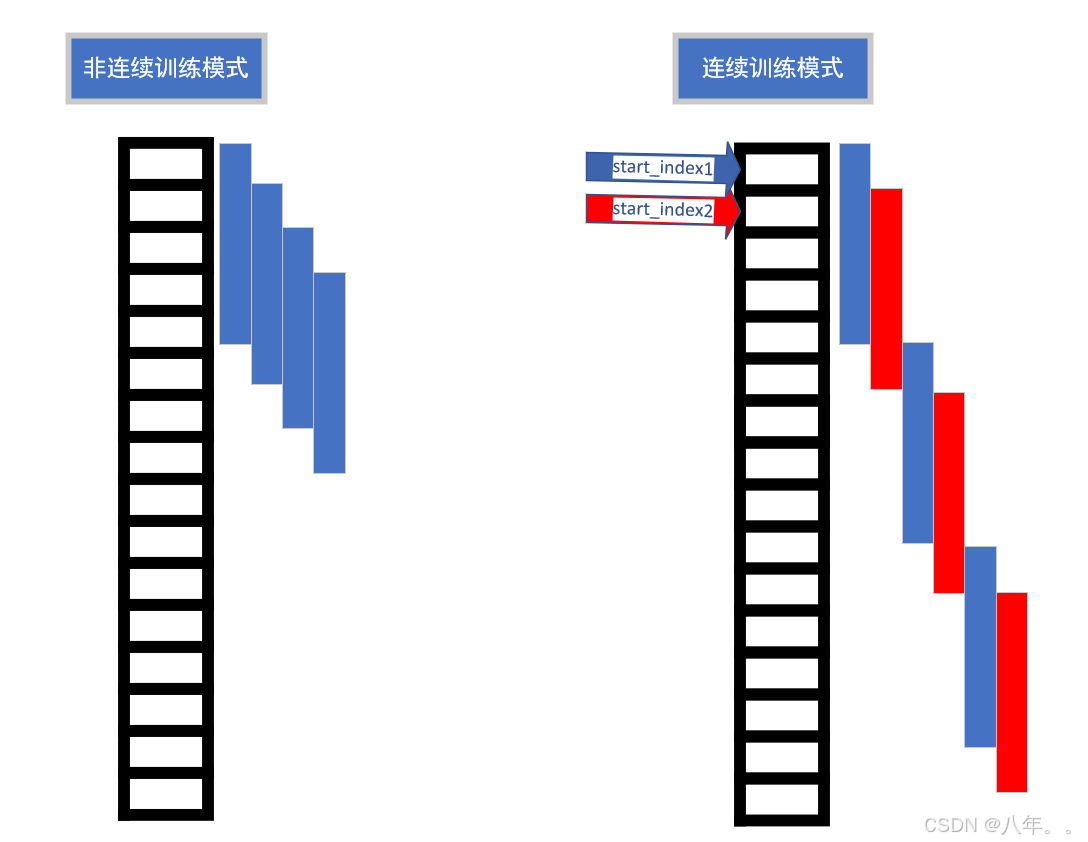
c、获取测试数据:
def get_test_data(self, return_label_data=False) -> np.ndarray:
这里取训练数据之后的所有数据作为测试特征数据,根据时间步长 (sample_interval) 生成测试样本 (test_x)。这里的样本之间是不重叠的,具体采样方式如下图所示。
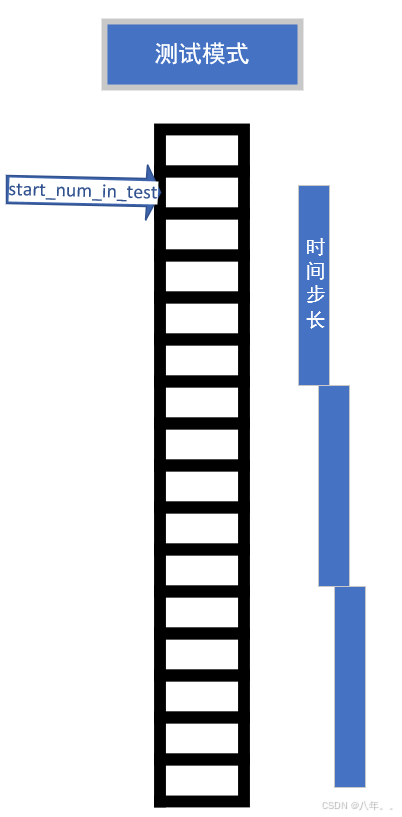
如果 return_label_data 为 True,则同时返回测试样本和标签数据,否则只返回测试样本。
(3) 日志记录函数 (load_logger)
def load_logger(config: Config) -> logging.Logger:创建和配置日志记录器,根据配置决定将日志输出到屏幕 (此时do_log_print_to_screen为True) 和文件 (此时do_log_save_to_file为True)。
(4)绘图函数 (draw)
def draw(config: Config, origin_data: Data, logger, predict_norm_data: np.ndarray):
用于绘制真实值和预测值的函数,便于可视化模型的预测效果。
可能是前面形状的修改,导致这里predict_data与label_data也出现了形状问题,做了一些修改的。
这里还有问题,在修改中,,,,,
(5)主函数(main)
def main(config):(6)if __name__ == "__main__"(最重要、必不可少)
这部分代码是Python脚本的标准做法,用于确保当脚本被直接运行时才执行某些代码。
a、导入 argparse库,
b、创建并配置 argparse 解析器
parser = argparse.ArgumentParser()
# 可以根据需要添加更多参数
args = parser.parse_args()创建一个 ArgumentParser 实例,并调用 parse_args 方法来解析命令行参数
c、创建配置实例并设置属性
con = Config() # 创建配置实例
for key in dir(args): # 遍历 args 的所有属性
if not key.startswith("_"): # 排除内部属性
setattr(con, key, getattr(args, key)) # 将属性值赋给配置创建了一个 Config 类的实例,用于存储配置信息。然后,遍历 args 对象的所有属性,将这些属性的值复制到 con 配置对象中。这里使用一个条件来排除以 _ 开头的属性,这些属性通常是 argparse 内部使用的。
d、运行主函数
main(con) # 运行主函数最后,这行代码调用 main 函数,并将配置对象 con 作为参数传递给它。
4、README.md:
这个文件通常提供项目的介绍和使用说明,帮助用户理解如何设置和运行项目。
5、requirements.txt:
该文件主要是列出项目的依赖包。本项目的依赖包如下:
pandas>=1.0.0
argparse
tensorflow>=2.5.0
matplotlib>=3.0.2
numpy>=1.14.6
scipy>=1.1.0
torch>=1.8.0
scikit-learn>=0.20.0
visdom要安装 requirements.txt 文件中列出的所有依赖,可以使用 Python 的包管理工具 pip
在命令行中,导航到包含 requirements.txt 文件的目录,并运行以下命令:
pip install -r requirements.txt这里的 -r 选项告诉 pip 从一个文件中读取依赖包列表,并进行安装。
到此就完全讲解结束了,以下是运行结果
五、运行结果
总结:
经过学习,可以做以下几点拓展:
- 多步预测:可以尝试为多步预测的时间序列预测模型。
- 更多模型:可以尝试加入更多的时间序列预测模型,如 GRU(Gated Recurrent Unit)或双向 LSTM,并观察它们与现有模型的表现对比。
- 新的数据集:可以尝试将该框架应用到其他时间序列数据集上,如温度预测、电力负荷预测等,以扩展其应用场景。
参考文章:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 时间序列预测(十五)——有关Python项目框架的实例分析

发表评论 取消回复