在音频处理领域,将音频中的人声和音乐分开是一个常见需求,尤其对于音乐制作、影视后期以及个人娱乐应用来说,这种分离技术显得尤为重要。随着科技的发展,现在已经有多种方法可以实现这一目的。

一、使用专业音频处理软件
市面上有许多专业的音频处理软件,如Adobe Audition、Audacity等,这些软件通常具备强大的人声和音乐分离功能。以Adobe Audition为例,用户可以通过软件内置的频谱分析工具,观察人声和音乐在频谱上的分布,然后利用软件的音频修复工具或者通过精确的剪辑操作,手动将人声和音乐分离开来。这种方法需要一定的专业知识和技能,但处理效果通常较好。

二、借助人工智能分离工具
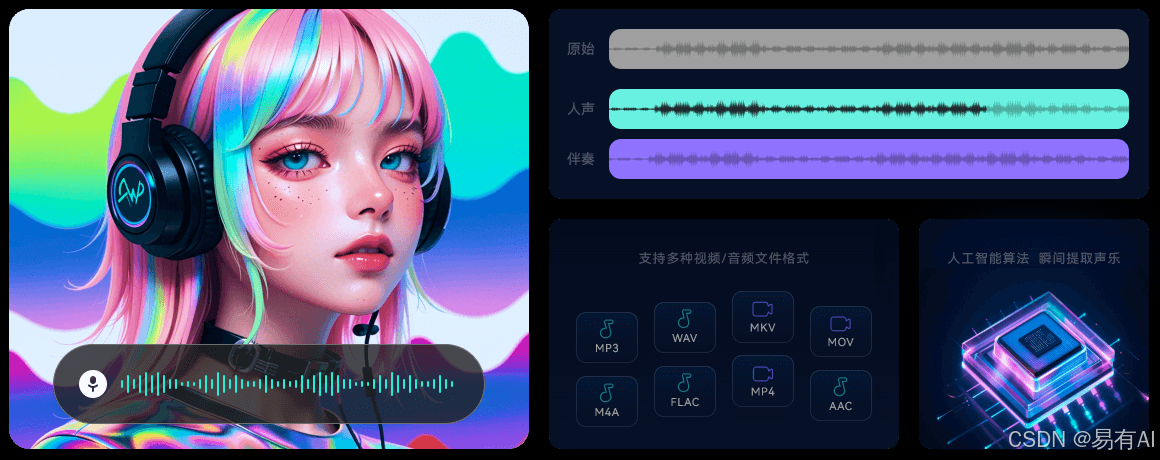
近年来,基于人工智能的音频分离技术取得了显著进展。一些在线平台或软件,比如易我人声分离就能够通过机器学习算法自动识别并分离音频中的人声和背景音乐。用户只需上传音频文件,选择分离模式,稍等片刻即可得到分离后的人声和音乐文件。这种方法操作简单,适合不具备专业音频处理知识的用户。
三、采用频域分析方法
频域分析是另一种有效的音频分离方法。由于人声和音乐在频域上具有不同的特征,因此可以通过快速傅里叶变换(FFT)等技术对音频信号进行频谱分析,然后根据人声和音乐在频谱上的差异进行分离。这种方法需要一定的信号处理知识,但可以实现较高质量的分离效果。
四、利用声源定位技术
声源定位技术是通过确定音频信号中声源的位置来实现人声和音乐的分离。这种方法通常需要借助麦克风阵列或多个麦克风来收集音频信号,然后通过声源定位算法来确定人声和音乐的位置信息,最后根据这些信息将人声和音乐分离开来。这种方法在特定场景下(如会议室、演讲厅等)具有较好的应用效果。
五、注意事项与操作建议
在进行人声和音乐分离时,需要注意以下几点:
1.选择合适的分离方法:根据实际需求和个人技能水平选择合适的分离方法。对于初学者,推荐使用基于人工智能的在线平台或软件;对于专业人士,可以选择专业音频处理软件或采用频域分析方法。
2.保证音频质量:在进行分离操作前,确保音频文件的质量较高,以减少分离过程中的误差和失真。
3.预览与调整:在分离完成后,务必预览分离结果,并根据需要进行微调,以达到最佳的分离效果。
4.备份原始音频:在进行任何分离操作前,务必备份原始音频文件,以防意外情况导致数据丢失。

六、总结
随着科技的不断发展,音频处理技术也在不断进步。无论是专业人士还是普通用户,都可以根据自己的需求选择合适的工具和方法来实现音频中人声和音乐的分离。希望本文的介绍能对大家有所帮助。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 想要音频里的人声,怎么把音频里的人声和音乐分开?

发表评论 取消回复