作者:来自 Elastic Praveen Durairaju
GraphQL 提供了一种高效且灵活的数据查询方式。本博客将解释 Hasura DDN 如何与 Elasticsearch 配合使用,以实现高性能和元数据驱动的数据访问。
此示例的代码和设置可在此 GitHub 存储库 - elasticsearch-subgraph-example 中找到。
Hasura DDN 是一个为云构建的元数据驱动的数据访问层。它会自动生成支持事务和分析工作负载的 API。通过利用元数据(例如模型、关系、权限和安全规则),Hasura 创建了针对性能进行了优化的 API,提供低延迟响应并轻松处理高并发需求。
元数据驱动(Metadata-driven) API 在搜索 AI 世界中的作用
元数据驱动 API 使用声明式方法,而不是手动编码每个端点及其相关逻辑。数据源(如 Elasticsearch 索引)的结构以标准化格式描述。定义不同实体之间的关系。权限和安全规则以细粒度级别指定,全部使用配置。
基于此元数据,API 层会自动配置并与数据源保持同步。
对于 Elasticsearch,使用 Hasura DDN 的元数据驱动 API 可提供统一且一致的数据访问。数据的变化会立即反映在 API 中,这对于实时搜索和 AI 应用程序至关重要。
架构
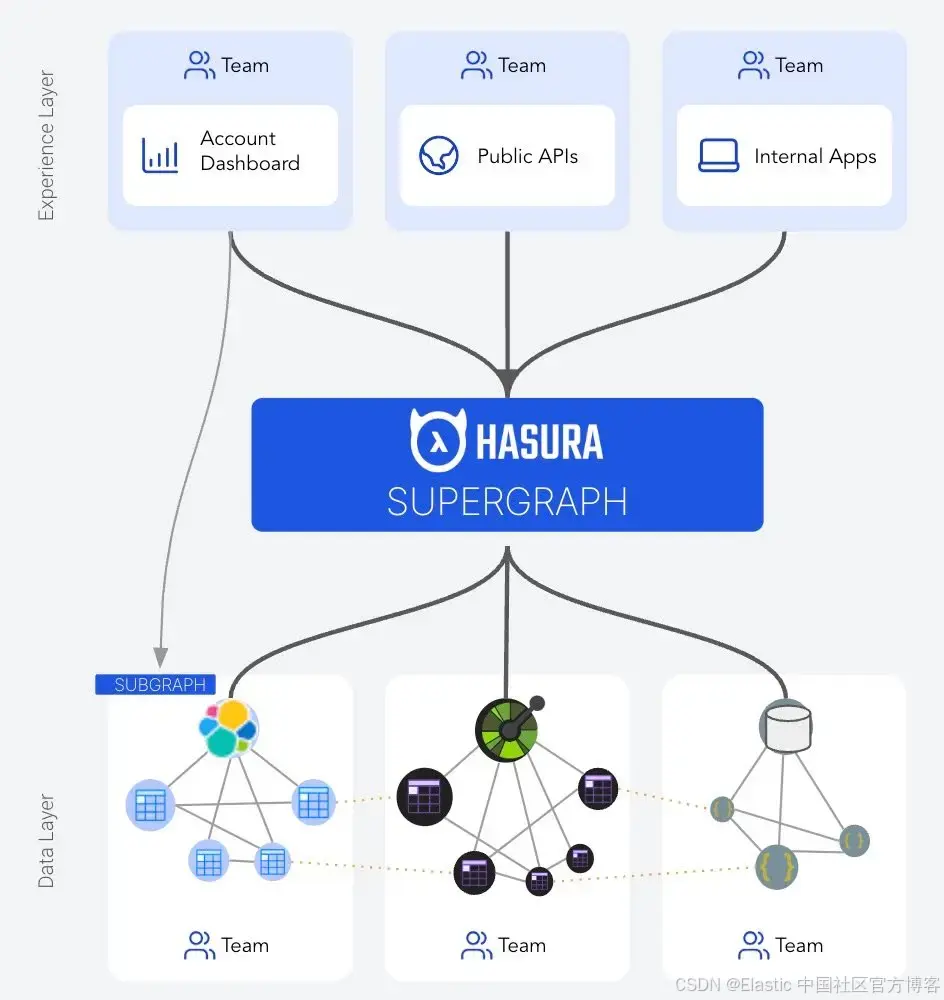
在上面的架构中,Hasura 是连接多个子图的超级图,Elasticsearch 是子图中的数据源之一。
为 Elasticsearch 设置 GraphQL API
此设置将引导你使用 Docker 将 Hasura DDN 连接到本地运行的 Elasticsearch 实例。但是,你可以通过使用正确的凭证更新环境变量轻松切换到 Elastic Cloud。使用 Elastic Cloud 是在生产环境中体验 Elasticsearch 的推荐方式,它提供可管理、可扩展且安全的部署。
设置:加载示例数据集
git clone https://github.com/hasura/elasticsearch-subgraph-example将 .env.example 复制到 .env 并设置 ELASTICSEARCH_PASSWORD 的值。
使用示例索引在本地启动 elasticsearch:
docker compose up -d访问 http://localhost:9200 以验证 Elasticsearch 是否正在使用示例数据运行。
Elasticsearch 的 GraphQL 子图
在本节中,我们将设置一个 GraphQL 子图(subgraph),将 Hasura DDN 连接到你的 Elasticsearch 实例。子图允许你将 Elasticsearch 公开为可查询的 API,从而提供一种灵活而高效的方式通过 GraphQL 执行复杂的搜索、聚合和过滤。
先决条件:
- Hasura CLI [从此处安装]
- 使用 ddn auth login 登录并进行身份验证
初始化超级图:
ddn supergraph init .初始化 Elasticsearch 连接器:
ddn connector init -i在快速启动向导中,输入以下环境变量值:
ELASTICSEARCH_URL=http://local.hasura.dev:9200
ELASTICSEARCH_USERNAME=elastic
ELASTICSEARCH_PASSWORD=elasticpwd要使用 Elastic Cloud 而不是本地实例,只需修改 .env 文件中的环境变量。将 ELASTICSEARCH_URL、ELASTICSEARCH_USERNAME 和 ELASTICSEARCH_PASSWORD 值替换为 Elastic Cloud 部署中的相应凭据。
Hasura DDN 连接到 Elasticsearch 以进行自检和生成 GraphQL API。
自检 Elasticsearch 实例并跟踪所有索引和集合:
ddn connector introspect elasticsearch --add-all-resources本地启动 Supergraph:
ddn run docker-start在本地构建 Supergraph:
ddn supergraph build local访问 https://console.hasura.io/local/graphql?url=http://localhost:3000 开始探索本地 supergraph。
用于搜索的 GraphQL 查询
现在我们已经设置了 Hasura DDN 并将元数据驱动的 API 应用于 Elasticsearch,让我们来编写 GraphQL 查询来执行搜索操作。
以下查询重点介绍了 Hasura 如何将复杂的搜索和聚合要求转化为简单的声明式 GraphQL 操作。这些示例不仅展示了 GraphQL 的灵活性,还展示了 Hasura 带来的标准化,从而实现了跨不同数据源的一致 API 访问。
获取 5 个产品(简单查询)
query searchProducts {
products(limit: 5) {
id
price
name
productId
}
}获取 5 个产品名称与术语 “shoes”匹配的产品(使用词组匹配的搜索查询)
query searchProducts {
products(limit: 5, where: {name: {match_phrase: "shoes"}}) {
id
price
name
productId
}
}获取符合过滤条件的产品集合(聚合查询)
query aggregateOfProducts {
productsAggregate(filter_input: {where: {name: {match_phrase: "shoes"}}}) {
name {
_count
}
}
}注意:此集成不仅限于搜索 API,还可以扩展到 Elasticsearch 中的日志记录和可观察性数据用例。
Hasura 对可组合性和标准 API 的支持使得将多个数据源(Postgres、MongoDB、REST 等)与 Elasticsearch 连接起来成为可能,从而构建一个更大的 Supergraph 来满足跨团队的需求。这种可组合性允许不同的团队以一致、标准化的方式访问相同的 API 端点和数据源,从而减少技术债务。
无论你是构建搜索体验还是高级分析仪表板,Hasura 都能让你的团队专注于应用程序逻辑而不是 API 管理,从而提高上市速度并降低运营复杂性。
大规模性能考虑
将 Hasura 和 Elasticsearch 结合使用的主要优势之一是通过谓词下推(predicate pushdown)来优化性能。Hasura DDN 能智能地编译并将过滤、限制和排序操作直接推送到 Elasticsearch,减少 N+1 查询的开销,避免数据过度抓取。
例如,以下 GraphQL 查询:
query searchProducts {
products(limit: 5, where: { name: { match_phrase: "shoes" } }) {
id
price
name
productId
}
}
生成类似于以下内容的 Elasticsearch 查询:
{
"_source": [
"_id",
"price",
"name",
"product_id"
],
"query": {
"match_phrase": {
"name": "shoes"
}
},
"size": 5
}通过仅请求必要的字段 (_source) 并限制获取的文档数量 (size),Hasura 可确保 Elasticsearch 达到最佳性能。与传统的手动编码 API 相比,这是一个显著的改进,因为在传统的 API 中,每个新需求都需要额外的手写查询。
总结
正如本文所探讨的那样,用于 Elasticsearch 的 Hasura DDN 连接器为加速 Elasticsearch 的 GraphQL API 和在组织中构建更大的 Supergraph 开辟了新的可能性,并与多个团队合作。
Hasura 的元数据驱动方法简化了 API 开发,为通过 GraphQL 访问 Elasticsearch 数据提供了一个快速、一致且安全的层。通过利用谓词下推,Hasura 可确保最佳搜索性能。详细了解 Hasura 针对 Elasticsearch 的功能。
我们很高兴看到你将构建什么!
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证?了解下一期 Elasticsearch 工程师培训何时开始!
原文:https://www.elastic.co/search-labs/blog/builing-ai-ready-apps-with-hasura-dnn-elasticsearch
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » GraphQL 与 Elasticsearch 相遇:使用 Hasura DDN 构建可扩展、支持 AI 的应用程序

发表评论 取消回复