提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
一、 二分查找
1.二分查找的前提
库函数只能对数组进行二分查找,
对一个数组进行二分查找的前提是这个数组中的元素是单调的,一般为单调不减,当然如果是单调不增也可以(需要修改比较函数)
例如:
[1,5,5.9,18]是单调的
[1,9,9,7,15]不是单调的
[9,8,8.7,7,1]是单调的
2.binary_ search函数
binary_ search是C++标准库中的一个算法函数,用于在已排序的序列(例如数组或容器中查找特定元素。
容器:C++标准模板库(STL)提供了一系列预定义的容器类,这些容器类是用来存储和管理对象的集合。
它通过二分查找算法来确定序列中是否存在目标元素。
函数返回一个bool值,表示目标元素是否存在于席列中。
如果需要获取找到的元素的位置,可以使用
lower_ bound函数或upper_ bound函数
代码如下(示例):
vector<int> numbers = {1, 3, 5, 7};
int a = 5;
//使用binary_ search查找目标元素
bool found = binary_ search(numbers.begin(), numbers.end(),a);
if (found)
{
cout << "a element " << a << "found." << endl;
}
else
{
cout << "a element "<< a << " not found." << endl;
}
3.lower_bound和upper_bound
前提:数组必须为非降序。
如果要在非升序的数组中使用,可以通过修改比较函数实现(方法与sort自定义比较函数似)
lower_ bound(st,ed,x)返回地址[st,ed)中第一个大于等于x的元素的地址。
//st(起始地址)/ed(结束地址)
upper_ bound(st,ed,x)返回地址[st,ed)中第一个大于x的元素的地址。
//地址-首地址=下标
如果不存在则返回最后一个元素的下一个位置,在vector中即end()。
代码如下(示例):
//初始化v
vector<int> v = {5, 1, 3, 7, 9};
sort ( v.begin(), v.end () );
for (auto &i : v)
cout << i << ' ' :
cout << '\n' ;
//找到数组中第一个大于等于5的元素位置
cout << (lower_bound(v.begin(), v.end(), 5) - v.begin()) << '\n';
二、排序
1.sort概念
sort函数包含在头文件<algorithm>中:在使用前需要#include<algorithm>或使用万能头文件。sort是C++标准库中的一个函数模板,用于对指定范围内的元素进行排序。
sort算法使用的是快速排序(QuickSort)或者类似快速排序的改进算法,具有较好的平均时间复杂度,一般为O(nlogn)。
2.sort的用法
sort(起始地址, 结束地址的下一位, *比较函数);
代码如下(示例):
int a[100];
int n;
//读取数组大小
cin >> n;
//读取元素
for(int i = 1;i <= n; ++i)
cin >> a[i];
//对数组进行排序
sort(a + 1, a + n + 1);
//输出
for(int i = 1;i <= n; ++i)
//可以替换成 for(auto i : v)
cout << a[i] << ' ';
3.自定义比较函数
sort默认使用小于号进行排序,如果想要自定义比较规则,
可以传入第三个参数,可以是函数或lambda表达式。
代码如下(示例):
bool cmp(const int &u, const int &v)
{
return u > v;
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
//初始化v
vector<int> v = {5, 1, 3, 9};
//对数组进行排序,降序排列
sort(v.begin(), v.end(), cmp);
//输出
for(int i = 0,i < v.size(); ++ i)
cout << v[i] <<' ';
输出: 9 5 3 1
结构体可以将小于号重载后进行排序,当然用前面的方法
也是可行的。
代码如下(示例):
struct NO
{
int u, v;
bool operator < (const No &m)const
{
//以u为第一关键字,v为第二关键字排序
return u == m.u ? v < m.v : u < m.u;
}
三、全排列
1.next permutation函数
next permutation函数用于生成当前序列的下一个排列。它按照字典序对序列进行重新排列,如果存在下一个排列,则将当前序列更改为下一个排列,并返回true;如果当前序列已经是最后一个排列,则将序列更改为第一个排列,并返回false。
代码如下(示例):
vector<int> nums = {1, 2, 3};
cout << "initial permutation: ";
for (int num : nums)
{
cout << num << " ";
}
cout << endl;
//生成下一个排列
while(next_permutation(nums.begin(), nums.end())
{
cout << "next_permutation: ";
for (int num :nums)
cout << num << " ";
{
cout << endl;
}
输出:
| 1 | 2 | 3 |
| 1 | 3 | 2 |
| 2 | 1 | 3 |
| 2 | 3 | 1 |
| 3 | 1 | 2 |
| 3 | 2 | 1 |
2.prev_permutation()函数
prev_permutation函数与next permutation 函数相反,它用于生成当前序列的上一个排列。它按照字典序对序列进行重新排列,如果存在上一个排列,则将当前序列更改为上一个排列,并返回true;如果当前序列已经是第一个排列,则将序列更改为最后一个排列,并返回false。
代码如下(示例):
vector<int> nums2 = {3, 2, 1};
cout << "initial permutation: ";
for (int num : nums2)
{
cout << num << " ";
}
cout << endl;
//生成上一个排列
while(prev_permutation(nums2.begin(), nums2.end())
{
cout << "prev_permutation: ";
for (int num : nums2)
cout << num << " ";
{
cout << endl;
}
输出:
| 3 | 2 | 1 |
| 3 | 1 | 2 |
| 2 | 1 | 3 |
| 2 | 1 | 3 |
| 1 | 3 | 2 |
| 1 | 2 | 3 |
四、最值查找
1.min和max函数
min(a,b)返回a和b中较小的那个值,只能传入两个值,或传入一个列表。例如:
min(3, 5)=3
min({1,2,3,4})=1
max(a,b)返回a和b中较大的那个值,只能传入两个值,或传入一个列表。例如:
max(7,5)=7
min({1,2, 3,4})=4
时间复杂度为O(1),传入参数为数组时时间复杂度为0(n),n为数组大小。
min,max函数是在取最值操作时最常用的操作。
2.min element和max element
min_element(st,ed)返回地址[st,ed)中最小的那个值的地址(迭代器),传入参数为两个地址或迭代器。
max_element(st,ed)返回地址[st,ed)中最大的那个值的地址(迭代器),传入参数为两个地址或迭代器。
时间复杂度均为O(n),n为数组大小(由传入的参数决定)
代码如下(示例):
//初始化v
vector <int> v = (5,1,3,9,11};
//输出最大的元素,*表示解引用,即通过地址(迭代器)得到值
cout << ( *max_element(v. begin, v.end()) << '/n';
输出:11
3.nth_element函数
nth element(st, k, ed)
进行部分排序,返回值为void()
传入参数为三个地址或迭代器。其中第二个参数位置的元素将处于正确位置,其他位置元素的顺序可能是任意的,但前面的都比它小,后面的都比它大。时间复杂度O(n)。
代码如下(示例):
//初始化
vector<int>v={5,1,7,3, 10,18, 9};
//输出最大的元素,*表示解引用,即通过地址(达代器)得到值
nth_ element(v.begin(),v.begin()+ 3,v.end());
//这里v[3]的位置将会位于排序后的位置,其他的任意
for(auto &i :v)
cout << i << " ";、
输出:3 1 5 7 9 18 10
五、大小写转换
1.islower/isupper函数
islower和isupper是C++标准库中的字符分类函数,用于检查一个字符是否为小写字母或大写字母islower和isupper函数需要包含头文件<cctype>,也可用方能头包含。函数返回值为bool类型。
代码如下(示例):
char ch1='A ';
char ch2 ='b';
//使用 islower 函数判断字符是否为小写字母
if(islower(ch1))
{
cout << ch1 << " is a lowercase letter." << endl;
}
else
{
cout << ch1 << "is not a lowercase letter." << endl;
}
//使用 isupper 函数判断字符是否为大写字母
if (isupper(ch2))
{
cout << ch2 << " is an uppercase letter."<< endl;
}
else
{
cout << ch2 << "is not an uppercase letter." << endl;
}
2.tolower/toupper函数
tolower(charch)可以将ch转换为小写字母,如果ch不是大写字母则不进
行操作。toupper()同理。
代码如下(示例):
char ch1 ='A';
char ch2= 'b';
//使用tolower 函数将字符转换为小写字母
char lowercaseCh1 = tolower(ch1);
cout << "Lowercase of " << ch1 << " is " << lowercasech1 << endl;
//使用toupper 所数将字符转换为大写字母
char uppercasech2 = toupper(ch2);
cout <<"Uppercase of "<< ch2 <<" is " << uppercasech2 << endl;
3.ascii码
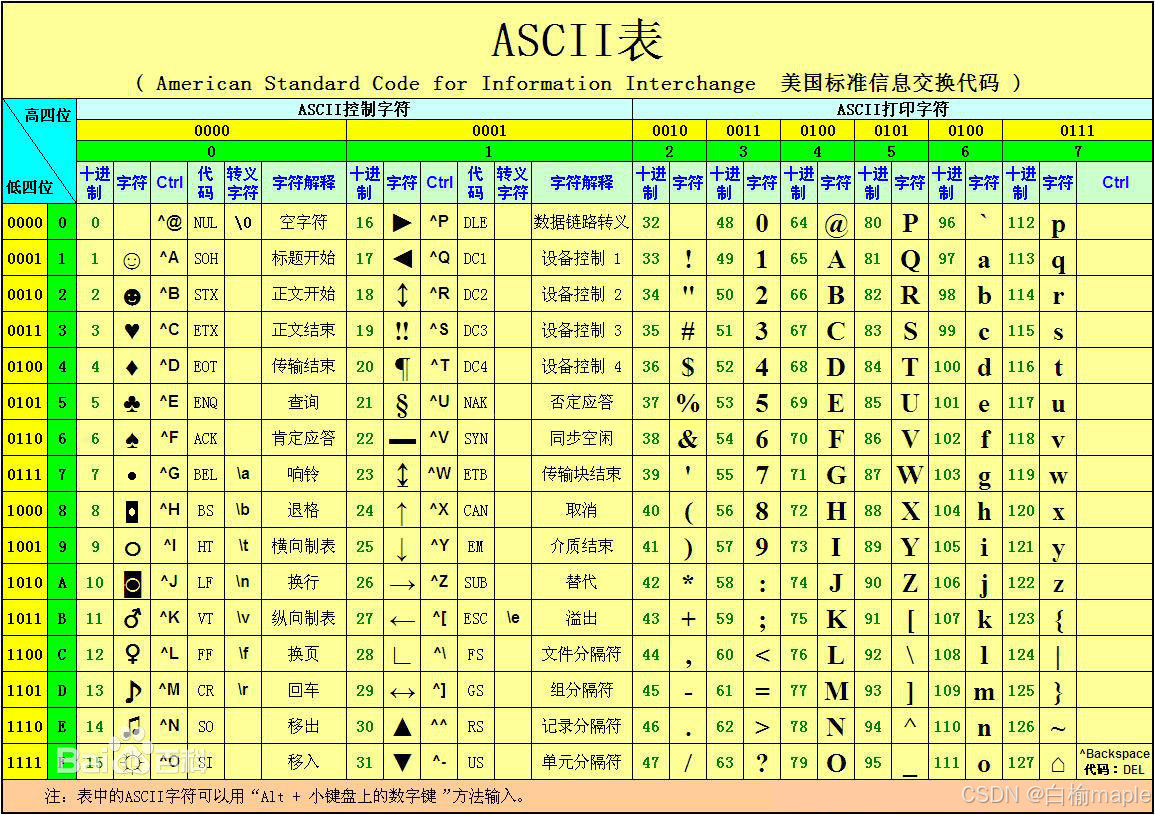
在了解了ascii码后,我们可以通过直接对英文字母进行加减运算计算出其大小写的字符。
在ASCI码表中,大写字母的编码范围是65(A)到90(Z),而小写字母的编码范围是97(a”)到122(z)。根据这个规则,可以使用ASCII码表进行大小写转换。
代码如下(示例):
char ch='A';//大写字母
char convertedch;
if (ch >= 'A’ && ch <= 'z')
{
//大写字母转换为小写字母
convertedch =ch+32;
cout << "converted character: " << convertedch << endl;
}
else if (ch>='a'88 ch<= 'z')
{
// 小写字母转换为大写字母
convertedch=ch-32;
cout << "converted character: " << convertedch << endl;
}
else
{
cout << "Invalid character!" << endl;
}
六、其他库函数
1.memset()
memset()是一个用于设置内存块值的函数它的原型定义在<cstring>头文件中,
函数的声明如下:
void* memset(void* ptr,int value, size t num);
memset0)函数接受三个参数:
1.ptr:指向要设置值的内存块的指针。
2.value:要设置的值,通常是一个整数。
3.num:要设置的字节数。
memset0函数将ptr指向的内存块的前num个字节设置为value的值。它返回一个指向ptr的指针。memset0函数通常用于初始化内存块,将其设置为特定的值。例如,如果要将一个整型数组的所有元素设置为0,可以使用memset0)函数如下
int arr[10];emset(arr,0,sizeof(arr));
在上述示例中,,memset(arr,0.sizeof(arr))将数组arr的所有元素设置为0,需要注意的是,memset()函数对于非字符类型的数组可能会产生未定义行为。在处理非字符类型的数组时,更好使用C++中的其他方法,如循环遍历来视memset会将每个byte设置为value。
2.swap()
swap(T&a,T&b)函数接受两个参数:
1.a:要交换值的第一个变量的引用
2.b:要交换值的第二个变量的引用
swap()函数通过将第一个变量的值存储到临时变量中,然后将第二个变量的值赋给第一个变量,最后将临时变量的值赋给第二个变量,实现两个变量值的交换。
swap()函数可以用于交换任意类型的变量,包括基本类型(如整数、浮点数等)和自定义类型(如结构体、类对象等)。
以下是一个示例,展示如何使用swap()函数交换两个整数的值:
int a= 10;int b= 20;std::swap(a, b);
3.reverse()
reverse()是一个用于反转容器中元素顺序的函数。它的原型定义在<algorithm>头文件中,函数的声明如下
template<class BidirIt>
void reverse(BidirIt first, BidirIt last);
reverse()函数接受两个参数:
1.first:指向容器中要反转的第一个元素的迭代器。
2.last:指向容器中要反转的最后一个元素的下一个位置的迭代器
reverse()函数将[first,last)范围内的元素顺序进行反转。也就是说,它会将[first,last)范围内的元素按相反的顺序重新排列。
reverse()函数可用于反转各种类型的容器,包括数组、向量、链表等。
以下是一个示例,展示如何使用reverse()函数反转一个整型向量的元素顺序:
代码如下(示例):
#include <iostream>
#include <vectar>
#include <algorith>
int main()
{
std::vector<int> vec = {1, 2, 3, 4, 5};
std::reverse(vec.begin(), vec .end( ));
for (int num : vec)
{
std::cout << num <<" ";
}
std::cout << std::endl;
return 0;
}
在上述示例中,std::reverse(vec.begin()vec.end())将整型向量vec中的元素顺序进行反转。最终输出的结果是54321。需要注意的是,reverse()函数只能用于一"向迭代器的容器,因为它需要能够向"后遍历容器中的元素。对于只支持单器的容器(如前向链表),无法使用rev函数进行反转。
4.unique()
unique()是一个用于去除容器中相邻重复元素的函数,它的原型定义在<algorithm>头文件中,
函数的声明如下
template<class ForwardIt>
ForwardIt unique(ForwardIt first, ForwardIt last);
unique(first, last)函数接受两个参数:
1.first:指向容器中要去重的第一个元素的迭代器,
2.last:指向容器中要去重的最后元素的下一个位置的迭代器
unique()函数将[first, last)范围内的相邻重复元素去除,并返回一指向去重后范围的尾后迭代器去重后的范围中只保留了第一个出现的元素,后续重复的元素都被移除。
unique()函数可用于去除各种类型的容器中的相邻重复元素,包括数组、向量、链表等。
以下是一个示例,展示如何使用unique()函数去除一个整型向量中的相邻重复元素:
int main()
{
std::vector<int> vec = {1, 1, 2, 2, 3, 3, 3.4, 4, 5)
auto it = std::unique(vec.begin(), vec.end( ));
vec.erase(it, vec.end());
for (int num : vec)
{
std: :cout << num << " ";
std::cout << std::endl;
return 0
}
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » (蓝桥杯C/C++)——常用库函数

发表评论 取消回复