Zookeeper和Eureka作为注册中心,在微服务架构中都扮演着重要的角色,但它们之间存在一些关键的区别:
-
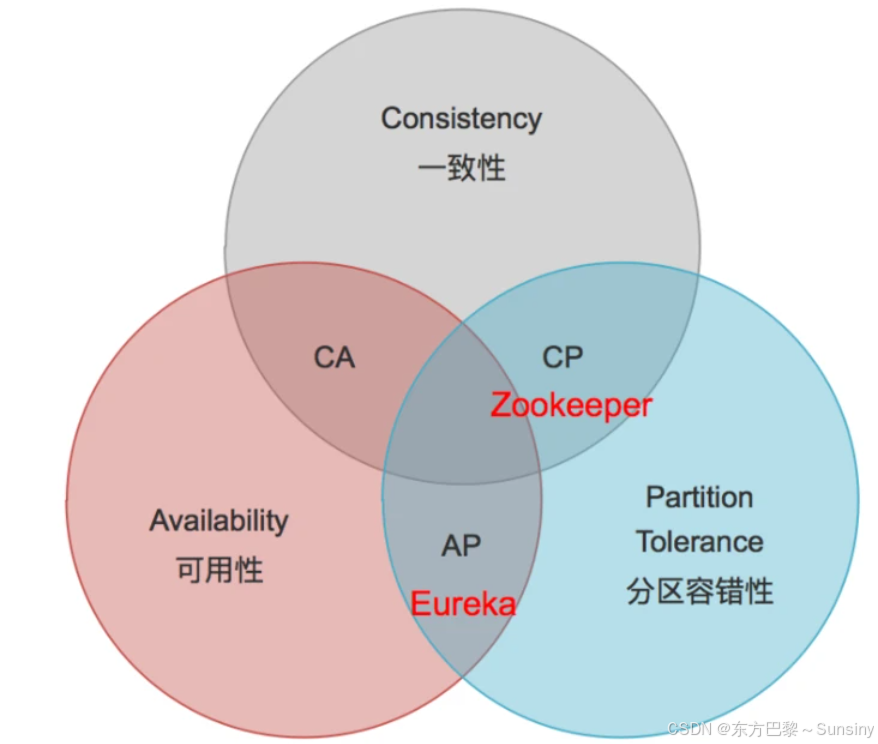
CAP原则的倾向不同:
- Zookeeper:遵循CP原则,即在网络分区发生时,Zookeeper保证一致性(Consistency)和分区容忍性(Partition tolerance),但不保证服务的可用性(Availability)。这意味着在网络分区的情况下,Zookeeper可能会丢弃一些请求,直到网络恢复。
- Eureka:遵循AP原则,即在网络分区发生时,Eureka保证可用性和分区容忍性,但可能会牺牲一致性。Eureka的设计目标是在发生网络分区的情况下仍然能够保持服务的可用性,即使某些节点不可达,服务注册与发现仍然可以正常运作。
-
集群模式不同:
- Zookeeper:采用主从架构,有一个Leader节点负责处理所有的写操作,其他节点(Followers)复制Leader的状态。这种架构适合对数据一致性要求较高的场景。
- Eureka:使用对等(peer-to-peer)的集群模式,所有的节点都是平等的,没有明确的Leader节点。这种架构适合需要高可用性和动态伸缩的场景。
-
服务发现机制不同:
- Zookeeper:利用其节点监听和znode临时节点的特性实现服务注册与发现。Zookeeper的客户端需要自己实现服务注册与发现的逻辑。
- Eureka:提供了完整的服务注册与发现机制,包括心跳机制和自我保护模式来保证注册中心的高可用性和稳定性。Eureka客户端和服务端都是开箱即用的,简化了服务注册与发现的实现。
-
使用场景不同:
- Zookeeper:更适合于大型分布式系统的协调服务需求,它的高可靠性和一致性特点使得它在需要强一致性和可靠性的场景下表现突出,比如Hadoop、Kafka等大数据领域。
- Eureka:适合于微服务架构中的服务注册与发现,尤其是在云环境下,例如AWS平台。它的设计目标是提供简单易用、高可用的服务注册与发现功能,适合于中小型分布式系统。
-
客户端缓存:
- Eureka:提供了客户端缓存功能,即使Eureka集群中所有节点都失效,或者发生网络分割故障导致客户端不能访问任何一台Eureka服务器,Eureka服务的消费者仍然可以通过Eureka客户端缓存来获取现有的服务注册信息。
- Zookeeper:所有节点不可能保证任何时候都能缓存所有的服务注册信息。如果Zookeeper下所有节点都断开了,或者集群中出现了网络分割的故障,那么外界就不能访问到这些节点了,即便这些节点本身是“健康”的。
总结来说,Zookeeper和Eureka在CAP原则的倾向、集群模式、服务发现机制、使用场景以及客户端缓存等方面都有所不同,选择合适的工具需要根据具体的业务需求和架构设计来决定。
如何在Zookeeper和Eureka之间做出选择?
在选择Zookeeper和Eureka作为注册中心时,可以根据以下几个关键点来进行决策:
-
CAP理论的倾向:
- Eureka倾向于AP(可用性和分区容错性),它牺牲了一定的一致性来保证高可用性。这意味着在网络分区发生时,Eureka能够继续提供服务,即使某些节点不可达。
- Zookeeper倾向于CP(一致性和分区容错性),它保证了强一致性,但在网络分区故障时可能导致部分节点不可用。
-
集群模式:
- Eureka使用对等(peer-to-peer)的集群模式,没有明确的Leader节点,适合需要高可用性和动态伸缩的场景。
- Zookeeper采用主从架构,有一个Leader节点负责处理所有的写操作,其他节点(Followers)复制Leader的状态,适合对数据一致性要求较高的场景。
-
服务发现机制:
- Eureka提供了完整的服务注册与发现机制,包括心跳机制和自我保护模式来保证注册中心的高可用性和稳定性。
- Zookeeper需要自己实现服务注册与发现的逻辑,它更倾向于作为一个分布式协调服务。
-
客户端缓存:
- Eureka提供了客户端缓存功能,即使Eureka集群中所有节点都失效,或者发生网络分割故障,Eureka服务的消费者仍然可以通过Eureka客户端缓存来获取现有的服务注册信息。
- Zookeeper下所有节点不可能保证任何时候都能缓存所有的服务注册信息。如果Zookeeper下所有节点都断开了,或者集群中出现了网络分割的故障,那么外界就不能访问到这些节点了,即便这些节点本身是“健康”的。
-
技术栈和生态:
- 如果你的技术栈是Java,并且使用Spring Cloud,Eureka可能是一个更自然的选择,因为它与Spring Cloud生态紧密集成。
- Zookeeper则更多被用于需要强一致性的场景,如分布式锁等,并且它在Dubbo框架中得到了广泛应用。
-
运维复杂度:
- Eureka由于其去中心化的特性,运维起来相对简单,节点间的数据同步是自发进行的。
- Zookeeper的运维相对复杂,需要管理Leader和Follower节点,以及处理Leader选举等问题。
综上所述,如果你的应用对服务可用性要求较高,并且希望简化运维复杂度,Eureka可能是更好的选择。而如果你的应用场景对数据一致性有严格要求,Zookeeper可能更适合。最终的选择应基于具体的业务需求和系统架构来决定。
如果我们的系统需要处理大量并发请求,Eureka和Zookeeper哪个更合适?
在处理大量并发请求的场景下,选择Eureka和Zookeeper作为注册中心时,需要考虑以下几个关键点:
-
CAP原则倾向:
- Eureka倾向于AP原则,即在网络分区发生时,优先保证服务的可用性和分区容忍性,可能会牺牲一致性。
- Zookeeper倾向于CP原则,即在网络分区发生时,优先保证一致性和分区容忍性,但可能牺牲服务的可用性。
-
服务发现机制:
- Eureka客户端会缓存服务注册信息,即使Eureka服务器出现问题,客户端仍然可以通过缓存获取服务的注册信息。
- Zookeeper在网络分区发生时,可能无法提供服务发现,因为它需要保证数据的一致性。
-
高可用性:
- Eureka设计了自我保护机制,在网络分区故障发生时,会阻止新服务注册,避免因网络故障导致的数据不一致问题,同时保留“心跳死亡”的服务注册信息不过期。
- Zookeeper在网络分区发生时,如果节点数达不到法定人数,会从Zookeeper中断开,不能提供服务发现服务。
-
读写性能:
- Eureka通过多级缓存和批量处理心跳请求来提高读写并发性能。
- Zookeeper使用内存数据库存储数据,快速响应读操作,并通过并行处理提高写操作的吞吐量。
-
集群容错能力:
- Eureka在服务器宕机时,客户端请求会自动切换到新的Eureka节点,宕机的服务器恢复后,Eureka会再次将其纳入到服务器集群管理之中。
- Zookeeper在集群中有节点宕机时,如果剩余节点数超过半数,仍然可以继续提供服务,如果不足半数,则集群可能失效。
-
网络分区处理:
- Eureka在网络分区发生时,每个节点会继续对外提供服务,接收新的服务注册同时将它们提供给下游的服务发现请求。
- Zookeeper在网络分区发生时,可能无法提供服务,因为它需要保证数据的一致性。
综上所述,在需要处理大量并发请求的场景下,Eureka由于其高可用性和对网络分区的容忍性,更适合作为服务注册中心。Eureka的设计允许在网络分区或其他故障情况下继续提供服务,而Zookeeper在这些情况下可能无法提供服务。因此,对于高并发和高可用性要求的场景,Eureka是更合适的选择。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Zookeeper 和 Eureka 做注册中心有什么区别?

发表评论 取消回复