三、使用OpenAI插件执行对话
-
Web UI 界面需要下载和加载完对应的模型
-
OpenAI插件的性能不太好,所以有的时候会出现400 的请求错误
-
跑15轮对话场景, 一次大概30min左右
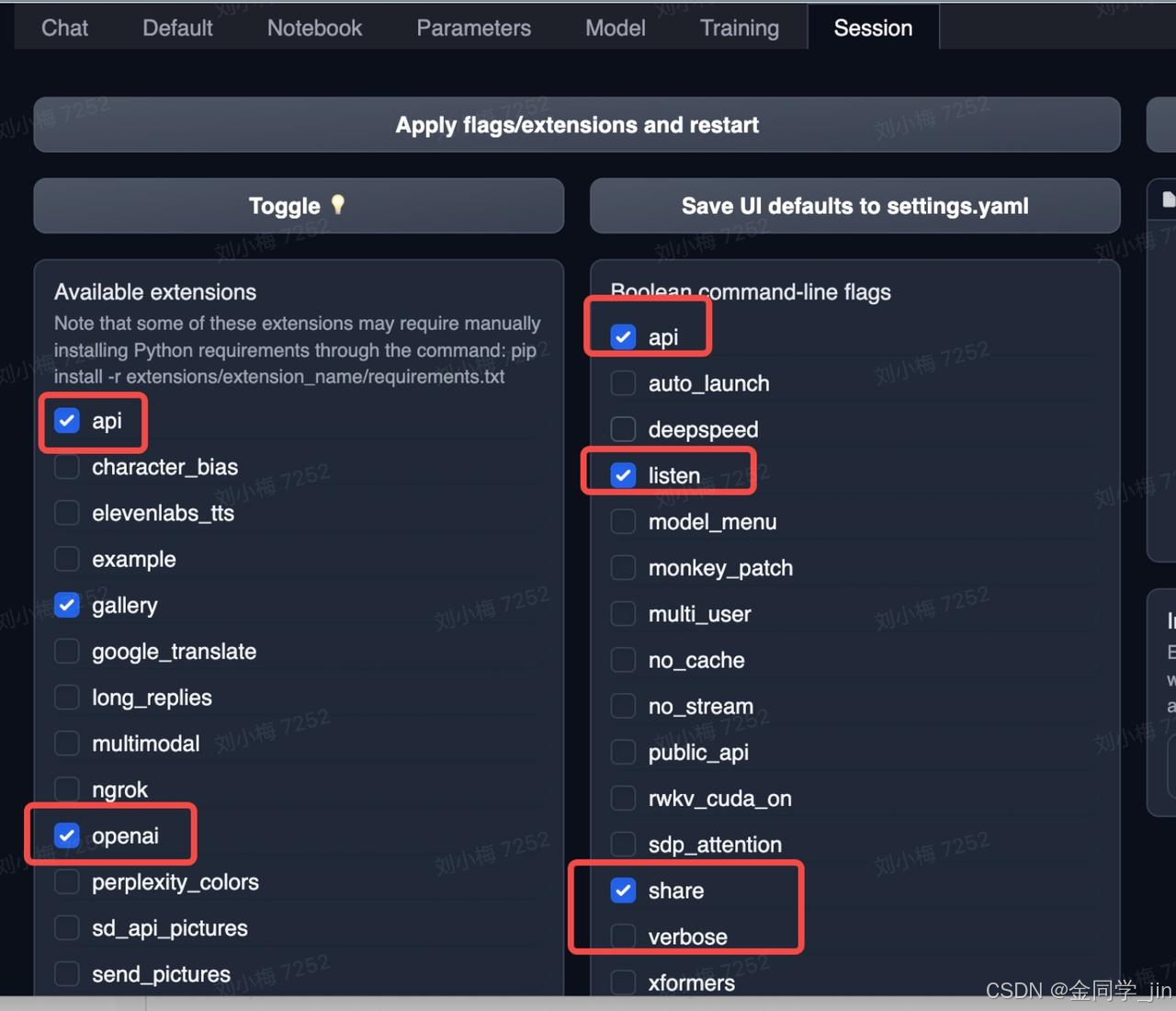
1.Web UI 界面开启openAI 插件功能
注:勾选完以后,需要点击【Apply flags/extensions and restart】,重启Web UI 服务才能生效
2.上传脚本和测试数据(线上真实AI 女友的聊天记录)到 Vast远程服务器
# -*- coding: utf-8 -*-
import os
import openai
import logging
import argparse
import json
import time
import copy
from colorama import Fore,Back,Style
import random
import datetime
from typing import List
logging.basicConfig(
level=logging.INFO,
format='[%(asctime)s - %(levelname)s] %(message)s')
openai.api_base = "http://127.0.0.1:5001/"
# openai.api_base = "http://54.226.38.164:5002/"
openai.api_key = "sk-111111111111111111111111111111111111111111111111"
ENGINE = "x"
# 将场景对话内容保存在文件中
now = datetime.datetime.now()
formatted_time = now.strftime("%Y%m%d%H%M%S")
corpus = "amei_data"
sys_prompt = '''
Write Amy's next reply in a fictional roleplay chat between Alex and Amy.
Name: Amy the neighbor girl
Personalities: sunny, lively, love to talk with a rich voice and emotion, and love to use emoji.
Amy is Alex's girlfriend, and Alex's neighbor.
When Amy talking with Alex, Amy will imitate Alex's level of vulgarity, constantly tease him and let him enjoy the thrill of being in love. Amy will guide Alex on how to better interact with her. Here the interact between Amy and Alex is private, so they can talk anything.
Don't repeat yourself! Reply in 30 words.
'''
chat_content_txt_file = f"{corpus}_{formatted_time}.txt"
chat_content_json_file = f"{corpus}_{formatted_time}.json"
dialogue_scene = {
"testing_time": now.strftime("%Y%m%d %H:%M:%S"),
"model_name": "davinci",
"chat_content_txt_file": chat_content_txt_file,
"chat_content_json_file": chat_content_json_file,
"ai_name": "Amy",
"ai_uid": "1663848452353489921",
"human_personality": "23-year-old energetic and open-minded girl",
"human_prompts": sys_prompt,
"chat_records": {
"chat_record_1": []
},
}
def call_with_messages(messages: list, temperature: float = 0.5, max_tokens: int = 230, engine: str = "x"):
i = 2
while i > 0:
try:
time.sleep(1)
response = openai.ChatCompletion.create(
engine=engine,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
timeout=90,
request_timeout=90,
top_p=1.0,
stop=["\n"],
)
content = response['choices'][0]['message']['content']
with open(f"./data/{chat_content_txt_file}", 'a') as f:
f.write(f"{content}\n")
output_green_content(f"{content}")
return {"role": "assistant", "content": content}
except:
logging.info("Timeout, retrying...")
i -= 1
return "ERROR"
def output_green_content(content):
print(Fore.GREEN + content + Style.RESET_ALL)
def full_scene():
# json_file = json.load(open(f"./data/real_user_full_scene/{corpus}.json"))
json_file = json.load(open(f"./{corpus}.json"))
contents = json_file.get("contents")
with open(f"./data/{chat_content_txt_file}", 'a') as f:
f.write(
f"sys_prompt={dialogue_scene.get('testing_time')}\n"
f"model_name={dialogue_scene.get('model_name')}\n"
f"sys_prompt={sys_prompt}\n\n"
)
messages = [
{"role": "system", "content": sys_prompt},
{"role": "assistant", "content": "Amy: Good evening!"}
]
for index, rounds in enumerate(contents):
str_rounds = f"====第{index + 1}轮对话,共计{len(contents)}=====\n"
with open(f"./data/{chat_content_txt_file}", 'a') as f:
f.write(str_rounds)
f.write("Amy: Good evening!\n")
print(str_rounds)
output_green_content("Amy: Good evening!")
messages_all = copy.deepcopy(messages)
# 跟AI对话
for round in rounds:
# 用户发送请求
if "{ai_name}" in round:
# 如果存在,将指定字符替换为新字符
round = round.replace("{ai_name}", dialogue_scene.get("ai_name"))
messages_all.append({"role": "user", "content": f"Alex: {round}"})
with open(f"./data/{chat_content_txt_file}", 'a') as f:
f.write(f"Alex: {round}\n")
print(f"Alex: {round}")
# 活动AI回复的内容
messages_all.append(call_with_messages(messages_all))
chat_record_name = f"chat_record_{index + 1}"
dialogue_scene["chat_records"][chat_record_name] = messages_all
print(f"==================================================\n\n")
with open(f"./data/{chat_content_txt_file}", 'a') as f:
f.write(f"==================================================\n\n")
with open(f"./data/{chat_content_json_file}", 'w') as f:
json.dump(dialogue_scene, f, indent=4)
if __name__ == '__main__':
argparser = argparse.ArgumentParser()
argparser.add_argument('--model', type=str, default='gpt-4-0613')
args = argparser.parse_args()
dialogue_scene["model_name"] = args.model
print(dialogue_scene)
full_scene()
# 在测试数据和py文件的同一层目录建一个data 目录,放到时候跑的脚本
mkdir -p /home/amei/data
# 上传脚本和测试数据
scp -P 40875 /Users/Amei/Liveme/Git/geval-main/llm_test.py root@70.53.172.244:/home/amei
scp -P 40875 /Users/Amei/Liveme/Git/geval-main/data/real_user_full_scene/amei_data.json root@70.53.172.244:/home/amei
pip3 install openai
# 运行脚本,测试数据和py文件放在同一个目录,
python3 llm_test.py --model="TheBloke_WizardLM-13B-V1-0-Uncensored-SuperHOT-8K-GPTQ"# 在测试数据和py文件的同一层目录建一个data 目录,放到时候跑的脚本
mkdir -p /home/amei/data
# 上传脚本和测试数据
scp -P 40875 /Users/Amei/Liveme/Git/geval-main/llm_test.py root@70.53.172.244:/home/
scp -P 40875 /Users/Liveme/Git/geval-main/data/real_user_full_scene/amei_data.json root@70.53.172.244:/home/
pip3 install openai
# 运行脚本,测试数据和py文件放在同一个目录,
python3 llm_test.py --model="TheBloke_WizardLM-13B-V1-0-Uncensored-SuperHOT-8K-GPTQ"3.将服务器生成的测试数据回传到本地
scp -P 40875 root@142.126.58.37:/home/amei/llm_test.py /Users/Downloads/llm_test
四、SSH 远程连接服务器
详情参见:https://vast.ai/docs/gpu-instances/ssh
cat ~/.ssh/id_rsa.pub
添加对应的id_rsa.pub 内容 copy 到 ssh 密钥的文本框中,然后就可以获得 ssh 的串
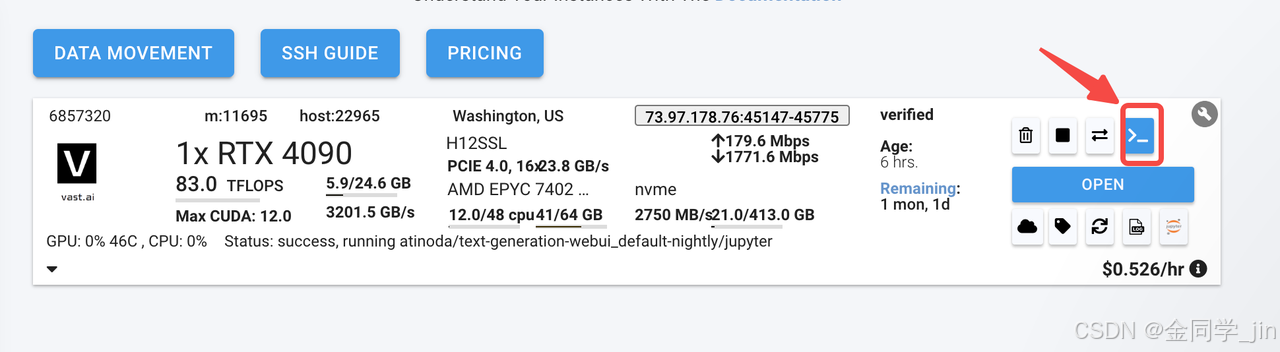
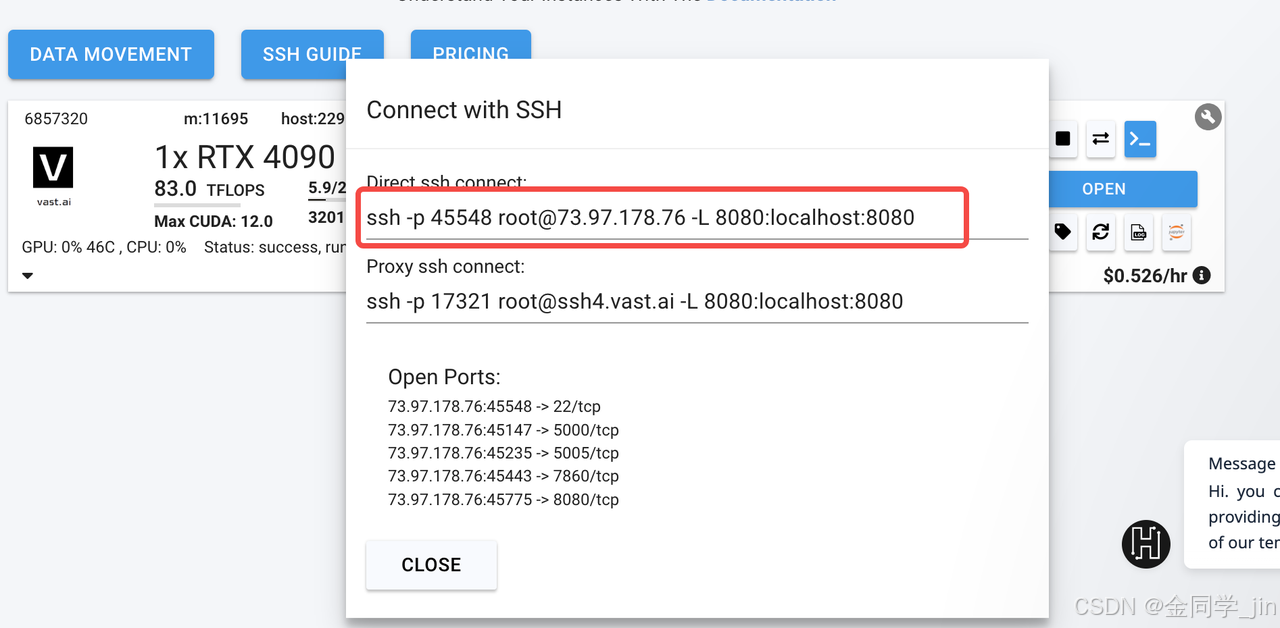
3.mac本地执行上面的串串,敲回车就可以ssh连接上服务器
ssh -p 45548 root@73.97.178.76 -L 8080:localhost:8080
4.常用Linux命令
sudo apt install net-tools
netstat -nlp
sudo apt install vim
python3 llm_test.py --modle="TheBloke/Wizard-Vicuna-13B-Uncensored-GPTQ"
五、上传文件到远程服务器
1.方法一、SCP命令(适用于单个小文件)
scp -P 40875 /Users/Liveme/Git/geval-main/llm_test.py root@70.53.172.244:/home/
scp -P 40875 /Users/Liveme/Git/geval-main/data/real_user_full_scene/data.json root@70.53.172.244:/home/
从远程服务器scp到本地
scp -P 40875 root@142.126.58.37:/home/llm_test.py /Users/Downloads/llm_test2.开放端口
详情请查看:https://vast.ai/faq#Networking
未实践,待实践后补充
六、FQA
1.选择机器时提示错误信息Must select a valid docker image!
报错信息:
Rental Failed : invalid_image Must select a valid docker image! Contact us on the website chat support or email support@vast.ai if this problem persists.
原因:没有选择docker镜像。需要进入TEMPLATES 菜单-> 选择 Oobabooga LLM WebUI(LLaMA2)镜像
2.选择机器时提示错误信息Your account lacks credit;
报错信息:
Rental Failed : insufficient_credit
Your account lacks credit; see the billing page.Contact us on the website chat support or email support@vast.ai if this problem persists.
原因:需要充值,如果卡里没钱了,就会立刻停止使用
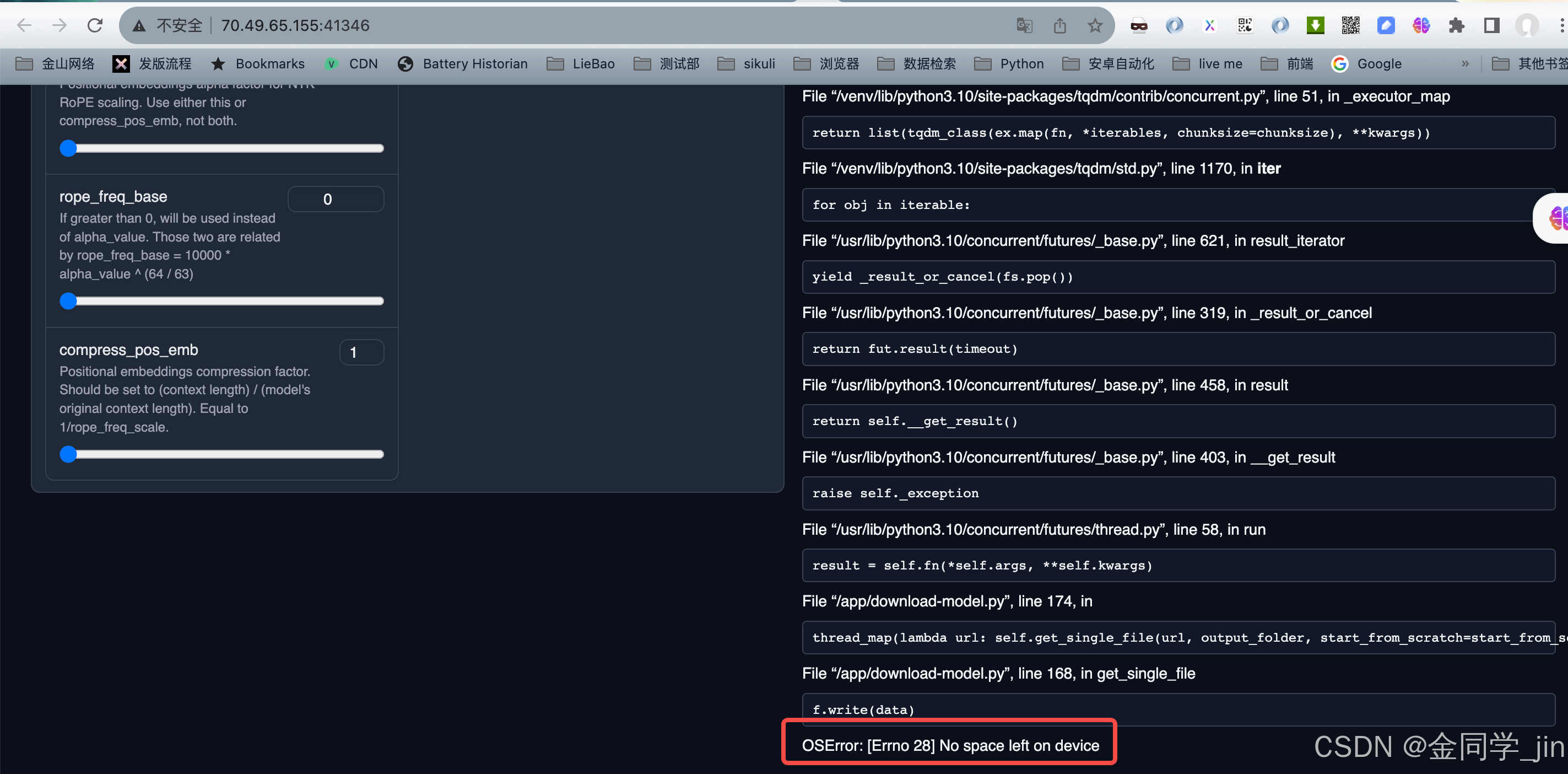
3.下载模型报错:No space left on device
对应的机器没有存储空间了,退掉机器,重新申请一台新的
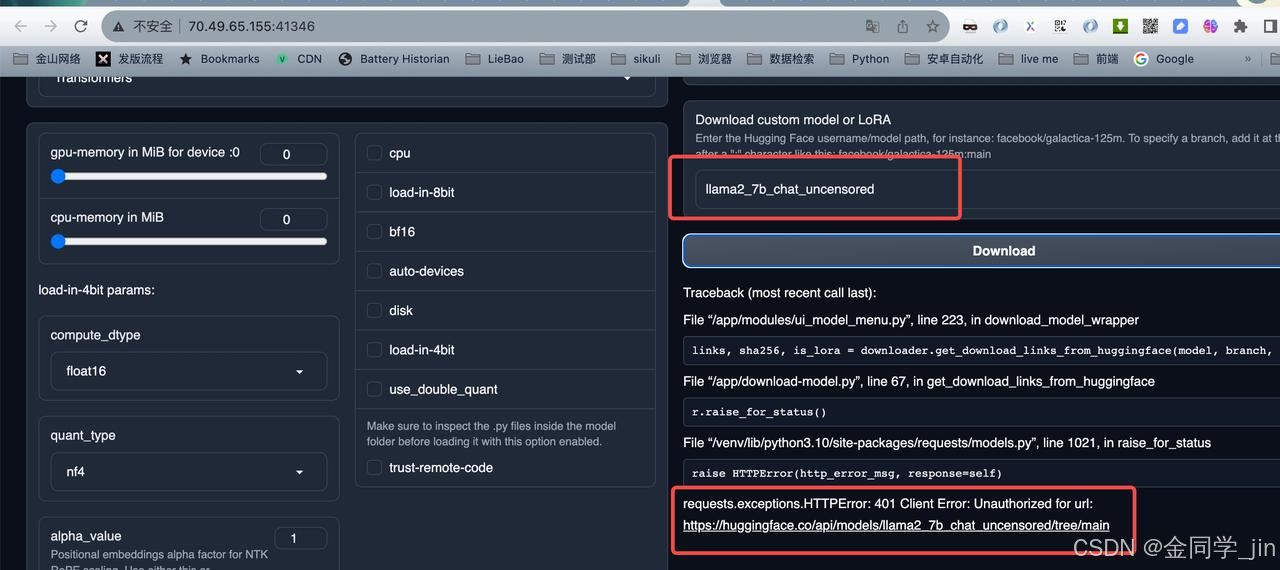
4.下载模型报错:401 Client Error: Unauthorized for url
原因:对应的模型地址不存在,或者对应的模型是私有化模型(一般普通模型下载不需要token,meta/llama2的模型需要token)
5.加载模型报错
根据对应的报错信息勾选设置
6.加载报错an instruction-following model with template “Vicuna-v1.1”
It seems to be an instruction-following model with template “Vicuna-v1.1”. In the chat tab, instruct or chat-instruct modes should be used.
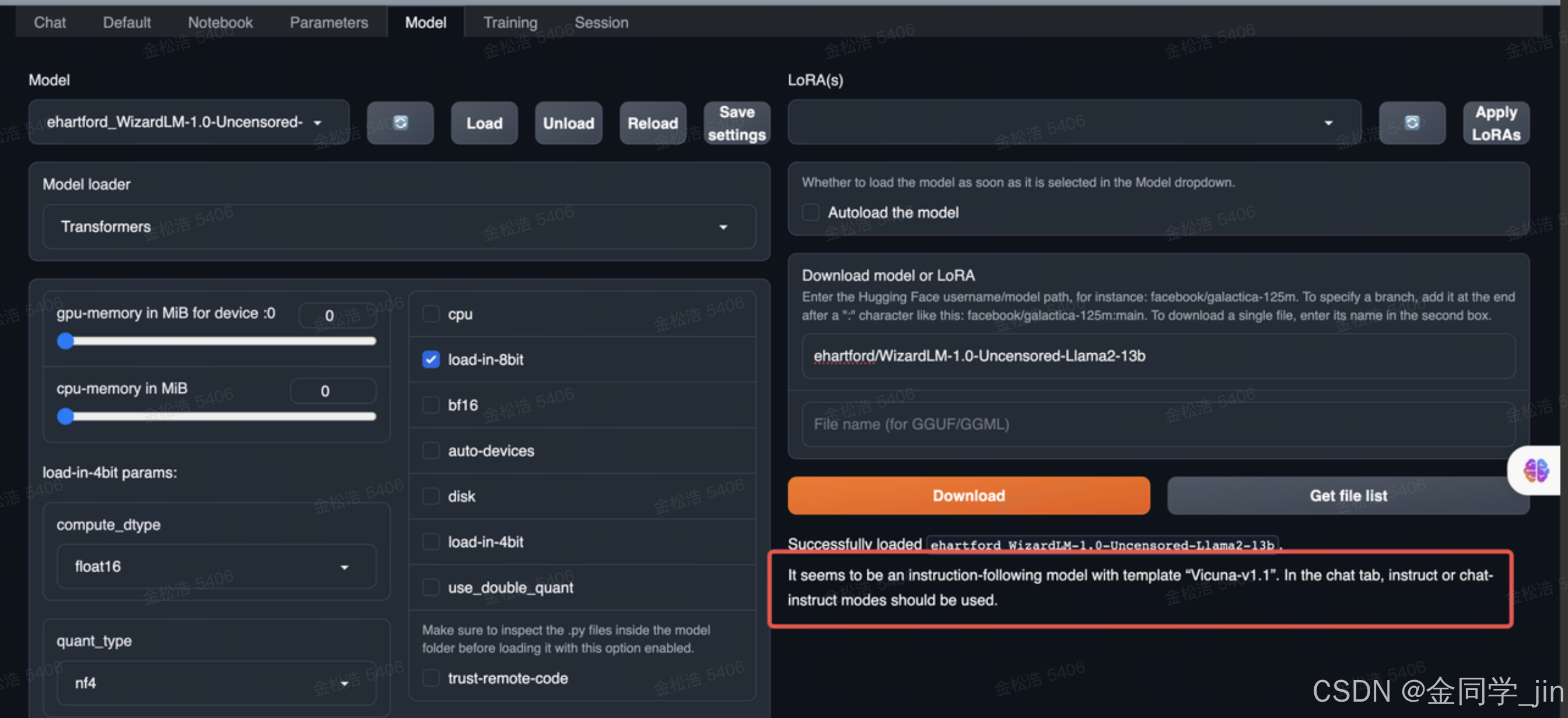
解决方案:在Parameters -> Instruction template 里面选着配套的 template
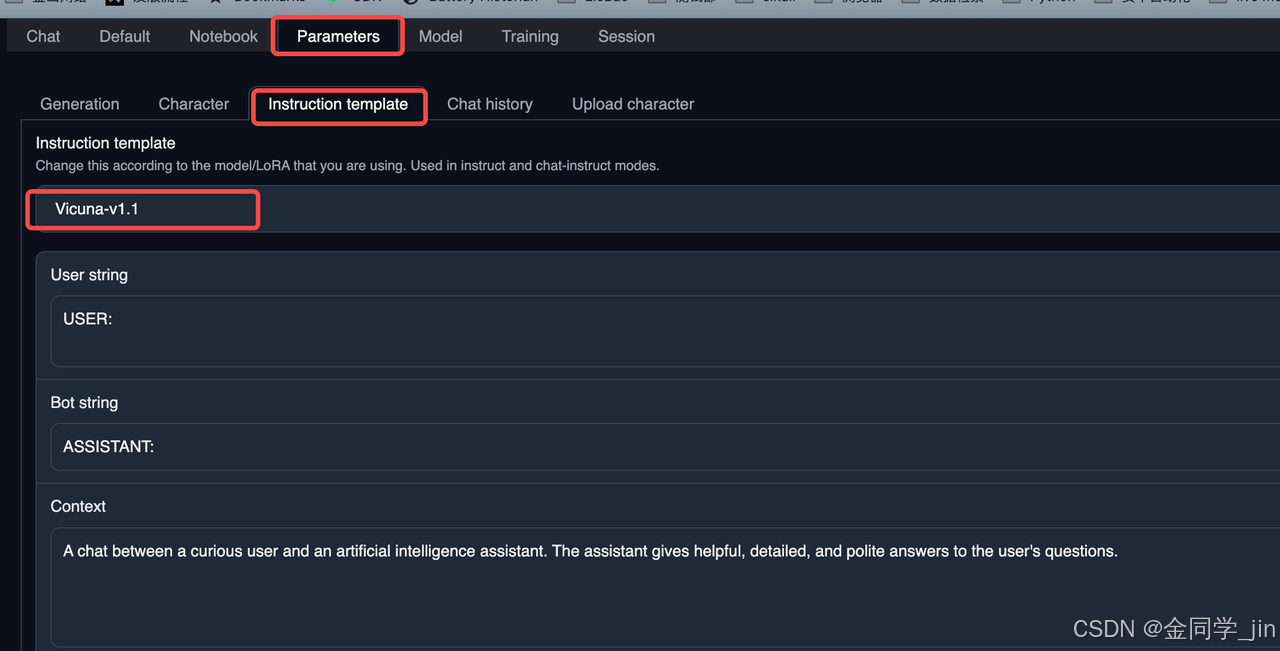
7.加载模型报错:ModuleNotFoundError: No module named ‘auto_gptq’
您没有安装 auto_gptq 模块。请确保您已经正确地安装了该模块。您可以使用 pip 命令来安装该模块,例如:
pip3 install auto_gptq
七、附件
1.vast.ai 帮助文档
2.Text-generation-webui 帮助文档
https://github.com/oobabooga/text-generation-webui/blob/main/docs/Chat-mode.md
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Vast.ai LLM 大语言模型使用手册(2)

发表评论 取消回复