一、U版RtDetr代码运行的流程图
首先去熟悉了整个代码的运行流程,再去看细节就更加容易理解了。
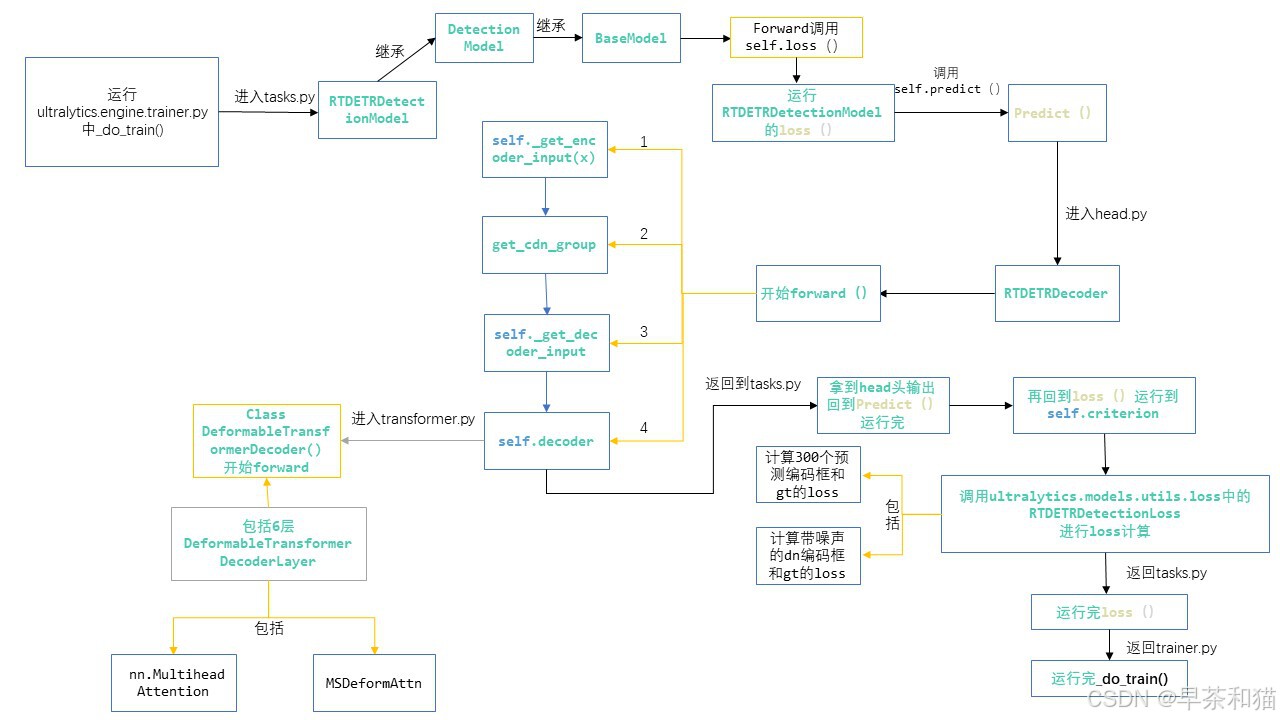
二、U版RtDetr代码细节解析
1、_do_train
搭建好模型以后开始训练。
#数据读取
batch = self.preprocess_batch(batch)
#传入训练数据到RTDETRDetectionModel中loss()中开始计算loss
self.loss, self.loss_items = self.model(batch)
2、RTDETRDetectionModel()已添加注释
这个类是负责构建RTDERT模型结构。在代码训练_do_train开始运行时
主要包括的方法:
①__init__:参数初始化
②init_criterion:初始化loss函数
③loss:训练过程中计算并返回loss
④predict:执行网络的前向传播过程并返回模型输出结果
先从loss()函数开始读起
class RTDETRDetectionModel(DetectionModel):
"""
RTDETR (Real-time DEtection and Tracking using Transformers) Detection Model class.
This class is responsible for constructing the RTDETR architecture, defining loss functions, and facilitating both
the training and inference processes. RTDETR is an object detection and tracking model that extends from the
DetectionModel base class.
Attributes:
cfg (str): The configuration file path or preset string. Default is 'rtdetr-l.yaml'.
ch (int): Number of input channels. Default is 3 (RGB).
nc (int, optional): Number of classes for object detection. Default is None.
verbose (bool): Specifies if summary statistics are shown during initialization. Default is True.
Methods:
init_criterion: Initializes the criterion used for loss calculation.
loss: Computes and returns the loss during training.
predict: Performs a forward pass through the network and returns the output.
"""
def __init__(self, cfg="rtdetr-l.yaml", ch=3, nc=None, verbose=True):
"""
Initialize the RTDETRDetectionModel.
Args:
cfg (str): Configuration file name or path.
ch (int): Number of input channels.
nc (int, optional): Number of classes. Defaults to None.
verbose (bool, optional): Print additional information during initialization. Defaults to True.
"""
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
"""Initialize the loss criterion for the RTDETRDetectionModel."""
from ultralytics.models.utils.loss import RTDETRDetectionLoss
return RTDETRDetectionLoss(nc=self.nc, use_vfl=True)
def loss(self, batch, preds=None):
"""
Compute the loss for the given batch of data.
Args:
batch (dict): Dictionary containing image and label data.
preds (torch.Tensor, optional): Precomputed model predictions. Defaults to None.
Returns:
(tuple): A tuple containing the total loss and main three losses in a tensor.
"""
# hasattr():函数用于判断对象是否包含对应的属性
if not hasattr(self, "criterion"):
#定义RTDETRDetectionloss
self.criterion = self.init_criterion()
#从batch里获取图像和gt的相关参数
img = batch["img"]
# NOTE: preprocess gt_bbox and gt_labels to list.
bs = len(img)
batch_idx = batch["batch_idx"]
gt_groups = [(batch_idx == i).sum().item() for i in range(bs)]
targets = {
"cls": batch["cls"].to(img.device, dtype=torch.long).view(-1),
"bboxes": batch["bboxes"].to(device=img.device),
"batch_idx": batch_idx.to(img.device, dtype=torch.long).view(-1),
"gt_groups": gt_groups,
}
#获得输出头的预测结果,进行后续的loss计算
preds = self.predict(img, batch=targets) if preds is None else preds
dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta = preds if self.training else preds[1]
#把decoder层的输出,生成框和带噪声的gt框分开来。
if dn_meta is None:
dn_bboxes, dn_scores = None, None
else:
dn_bboxes, dec_bboxes = torch.split(dec_bboxes, dn_meta["dn_num_split"], dim=2)
dn_scores, dec_scores = torch.split(dec_scores, dn_meta["dn_num_split"], dim=2)
#讲encoder层和decoder层输出cat到一起,6+1
dec_bboxes = torch.cat([enc_bboxes.unsqueeze(0), dec_bboxes]) # (7, bs, 300, 4)
dec_scores = torch.cat([enc_scores.unsqueeze(0), dec_scores])
#计算RTDETRDetectionloss
loss = self.criterion(
(dec_bboxes, dec_scores), targets, dn_bboxes=dn_bboxes, dn_scores=dn_scores, dn_meta=dn_meta
)
# NOTE: There are like 12 losses in RTDETR, backward with all losses but only show the main three losses.
return sum(loss.values()), torch.as_tensor(
[loss[k].detach() for k in ["loss_giou", "loss_class", "loss_bbox"]], device=img.device
)
def predict(self, x, profile=False, visualize=False, batch=None, augment=False, embed=None):
"""
Perform a forward pass through the model.
Args:
x (torch.Tensor): The input tensor.
profile (bool, optional): If True, profile the computation time for each layer. Defaults to False.
visualize (bool, optional): If True, save feature maps for visualization. Defaults to False.
batch (dict, optional): Ground truth data for evaluation. Defaults to None.
augment (bool, optional): If True, perform data augmentation during inference. Defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): Model's output tensor.
"""
y, dt, embeddings = [], [], [] # outputs
for m in self.model[:-1]: # except the head part 除了head输出头RTDETRDecoder之外的backbone和head
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run 模型开始传入图像参数
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
#head层 RTDETRDecoder
head = self.model[-1]
#head.f为三个输出层[21, 24, 27],y[j]是对应层输出的特征,然后走RTDETRDecoder的forward进行特征编码
x = head([y[j] for j in head.f], batch) # head inference
return x
3、RTDETRDecoder()已添加注释
第2点中的RTDETRDetectionModel中的predict()函数调用head.py中RTDETRDecoder()进行transformer编码预测相关操作,并返回编码特征。
forward主要流程如下图所示:
以下操作都是基于图像的batch输入为8,图像的输出尺寸为640
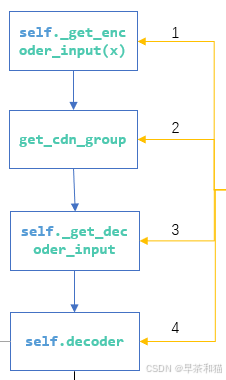
① self._get_encoder_input(x) :将三个特征层进行cat融合获得feats([8, 8400, 256]),并存储每个特征层的shape([[80, 80], [40, 40], [20, 20]])。
其中self.input_proj定义了3个卷积(因为yolo系列默认的输出层ch是3个),分别进行卷积操作提取特征,维度不变

def __init__()
# Backbone feature projection
self.input_proj = nn.ModuleList(nn.Sequential(nn.Conv2d(x, hd, 1, bias=False), nn.BatchNorm2d(hd)) for x in ch)
def forward(self, x, batch=None):
#输入的x:[8, 256, 80, 80],[8, 256, 40, 40],[8, 256, 20, 20]
# Input projection and embedding
#feats:[8, 8400, 256],shape:[[80, 80], [40, 40], [20, 20]]
feats, shapes = self._get_encoder_input(x)
def _get_encoder_input(self, x):
"""Processes and returns encoder inputs by getting projection features from input and concatenating them."""
# Get projection features
#输入前x:[8, 256, 80, 80],[8, 256, 40, 40],[8, 256, 20, 20]
x = [self.input_proj[i](feat) for i, feat in enumerate(x)]
#输出后x:[8, 256, 80, 80],[8, 256, 40, 40],[8, 256, 20, 20]
# Get encoder inputs
feats = []
shapes = []
for feat in x:
h, w = feat.shape[2:]
# [b, c, h, w] -> [b, h*w, c]
feats.append(feat.flatten(2).permute(0, 2, 1))
# [nl, 2]
shapes.append([h, w])
# [b, h*w, c]
feats = torch.cat(feats, 1)
return feats, shapes
②get_cdn_group():和DN Deformable DETR一样,动态构造了num_group个去噪组,num_group=100//max_nums(一个batch中类别数的最大值)。只是代码实现上有点不同,基本思想一致。只有训练的时候才会生成一个去噪组用于辅助训练,模型预测的时候会跳过这一步
def __Init__(
self,
nc=80,
ch=(512, 1024, 2048),
hd=256, # hidden dim
nq=300, # num queries
ndp=4, # num decoder points
nh=8, # num head
ndl=6, # num decoder layers
d_ffn=1024, # dim of feedforward
dropout=0.0,
act=nn.ReLU(),
eval_idx=-1,
# Training args
nd=100, # num denoising
label_noise_ratio=0.5,
box_noise_scale=1.0,
learnt_init_query=False,):
super().__init__()
self.nc = nc
self.num_queries = nq
# Denoising part
self.denoising_class_embed = nn.Embedding(nc, hd) #[14, 256]
self.num_denoising = nd
self.label_noise_ratio = label_noise_ratio
self.box_noise_scale = box_noise_scale
def forward(self, x, batch=None):
from ultralytics.models.utils.ops import get_cdn_group
# Prepare denoising training
# 动态构造了num_group个去噪组
dn_embed, dn_bbox, attn_mask, dn_meta = get_cdn_group(
batch,
self.nc,
self.num_queries,
self.denoising_class_embed.weight,
self.num_denoising,
self.label_noise_ratio,
self.box_noise_scale,
self.training, #训练的时候才会生成
)
输入:
batch:包括每张图里的所有检测框坐标以及对应框的类别,对应的batch索引id和每张图片里框的数量gt_groups
self.nc:检测框的类别数
self.num_queries:生成queries的数量,默认是300
self.denoising_class_embed.weight:
深度学习:pytorch nn.Embedding详解
self.num_denoising:100


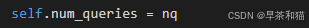
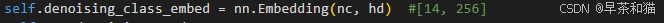
self.label_noise_ratio:0.5
self.box_noise_scale:1.0
self.training:True
输出:
dn_embed: 【8, 192, 256】 噪声类别的编码特征
dn_bbox: 【8, 192, 4】 噪声框
attn_mask:【492, 492】 gt框和噪声框的注意力mask
dn_meta:包括 ①"dn_pos_idx",②"dn_num_group"噪声组数,③"dn_num_split": [num_dn, num_queries],噪声框和预测框
def get_cdn_group(
batch, num_classes, num_queries, class_embed, num_dn=100, cls_noise_ratio=0.5, box_noise_scale=1.0, training=False
):
"""
Get contrastive denoising training group. This function creates a contrastive denoising training group with positive
and negative samples from the ground truths (gt). It applies noise to the class labels and bounding box coordinates,
and returns the modified labels, bounding boxes, attention mask and meta information.
Args:
batch (dict): A dict that includes 'gt_cls' (torch.Tensor with shape [num_gts, ]), 'gt_bboxes'
(torch.Tensor with shape [num_gts, 4]), 'gt_groups' (List(int)) which is a list of batch size length
indicating the number of gts of each image.
num_classes (int): Number of classes.
num_queries (int): Number of queries.
class_embed (torch.Tensor): Embedding weights to map class labels to embedding space.
num_dn (int, optional): Number of denoising. Defaults to 100.
cls_noise_ratio (float, optional): Noise ratio for class labels. Defaults to 0.5.
box_noise_scale (float, optional): Noise scale for bounding box coordinates. Defaults to 1.0.
training (bool, optional): If it's in training mode. Defaults to False.
Returns:
(Tuple[Optional[Tensor], Optional[Tensor], Optional[Tensor], Optional[Dict]]): The modified class embeddings,
bounding boxes, attention mask and meta information for denoising. If not in training mode or 'num_dn'
is less than or equal to 0, the function returns None for all elements in the tuple.
"""
if (not training) or num_dn <= 0:
return None, None, None, None
gt_groups = batch["gt_groups"] #[7, 5, 8, 12, 12, 12, 6, 8]
total_num = sum(gt_groups) #70
max_nums = max(gt_groups) #12
if max_nums == 0:
return None, None, None, None
num_group = num_dn // max_nums #100//12=8
num_group = 1 if num_group == 0 else num_group #8
# Pad gt to max_num of a batch
bs = len(gt_groups) #batch数
gt_cls = batch["cls"] # (bs*num, )
gt_bbox = batch["bboxes"] # bs*num, 4
b_idx = batch["batch_idx"]
# Each group has positive and negative queries.
dn_cls = gt_cls.repeat(2 * num_group) # (2*num_group*bs*num, ) 70*2*8=1120,70个类别复制16遍
dn_bbox = gt_bbox.repeat(2 * num_group, 1) # 2*num_group*bs*num, 4 [70, 4]--->[1120, 4]
dn_b_idx = b_idx.repeat(2 * num_group).view(-1) # (2*num_group*bs*num, ) [1120]
# Positive and negative mask
# (bs*num*num_group, ), the second total_num*num_group part as negative samples
#负样本索引的id,取1120的后一半,即[560,1120]
neg_idx = torch.arange(total_num * num_group, dtype=torch.long, device=gt_bbox.device) + num_group * total_num
if cls_noise_ratio > 0:
# Half of bbox prob
mask = torch.rand(dn_cls.shape) < (cls_noise_ratio * 0.5) #对1120个位置随机生成0到1的数值,如果小于cls_noise_ratio * 0.5为True,否则为Fale
idx = torch.nonzero(mask).squeeze(-1) #提取出为True的位置索引
# Randomly put a new one here 对True位置赋予随机类别
new_label = torch.randint_like(idx, 0, num_classes, dtype=dn_cls.dtype, device=dn_cls.device)
dn_cls[idx] = new_label
if box_noise_scale > 0: #将dn_bboxs转成xyxy形式存在known_bbox中,据known_bbox生成diff,按known_bbox的shape生成随机数,按给定的公式将diff与该随机数(经过一系列处理)相乘后加在known_bbox,最后将known_bbox转成cxcywh形式
known_bbox = xywh2xyxy(dn_bbox)
diff = (dn_bbox[..., 2:] * 0.5).repeat(1, 2) * box_noise_scale # 2*num_group*bs*num, 4 [1120, 4]
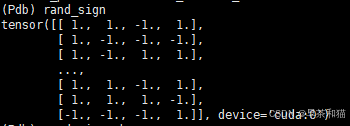
rand_sign = torch.randint_like(dn_bbox, 0, 2) * 2.0 - 1.0 #[1120, 4]
rand_part = torch.rand_like(dn_bbox)
rand_part[neg_idx] += 1.0
rand_part *= rand_sign
known_bbox += rand_part * diff
known_bbox.clip_(min=0.0, max=1.0) #框的坐标限制在0,1
dn_bbox = xyxy2xywh(known_bbox)
dn_bbox = torch.logit(dn_bbox, eps=1e-6) # inverse sigmoid
# dn_cls和dn_bbox为添加噪声之后的labels和bbox
num_dn = int(max_nums * 2 * num_group) # total denoising queries 12*2*8=192
# class_embed = torch.cat([class_embed, torch.zeros([1, class_embed.shape[-1]], device=class_embed.device)])
dn_cls_embed = class_embed[dn_cls] # bs*num * 2 * num_group, 256 class_embed:[14, 256] ,dn_cls[1120], dn_cls_embed: [1120, 256]
padding_cls = torch.zeros(bs, num_dn, dn_cls_embed.shape[-1], device=gt_cls.device) #[8, 192, 256]
padding_bbox = torch.zeros(bs, num_dn, 4, device=gt_bbox.device) # [8, 192, 4]
map_indices = torch.cat([torch.tensor(range(num), dtype=torch.long) for num in gt_groups]) # [70]
pos_idx = torch.stack([map_indices + max_nums * i for i in range(num_group)], dim=0) # [8, 70]
map_indices = torch.cat([map_indices + max_nums * i for i in range(2 * num_group)]) #1120
padding_cls[(dn_b_idx, map_indices)] = dn_cls_embed #[8, 192, 256]
padding_bbox[(dn_b_idx, map_indices)] = dn_bbox #[8, 192, 4]
tgt_size = num_dn + num_queries #192+300=492
attn_mask = torch.zeros([tgt_size, tgt_size], dtype=torch.bool) #[492,492]
# Match query cannot see the reconstruct
attn_mask[num_dn:, :num_dn] = True
# Reconstruct cannot see each other
for i in range(num_group):
if i == 0:
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), max_nums * 2 * (i + 1) : num_dn] = True
if i == num_group - 1:
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), : max_nums * i * 2] = True
else:
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), max_nums * 2 * (i + 1) : num_dn] = True
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), : max_nums * 2 * i] = True
dn_meta = {
"dn_pos_idx": [p.reshape(-1) for p in pos_idx.cpu().split(list(gt_groups), dim=1)],
"dn_num_group": num_group,
"dn_num_split": [num_dn, num_queries],
}
return (
padding_cls.to(class_embed.device),
padding_bbox.to(class_embed.device),
attn_mask.to(class_embed.device),
dn_meta,
)
论文中的图:
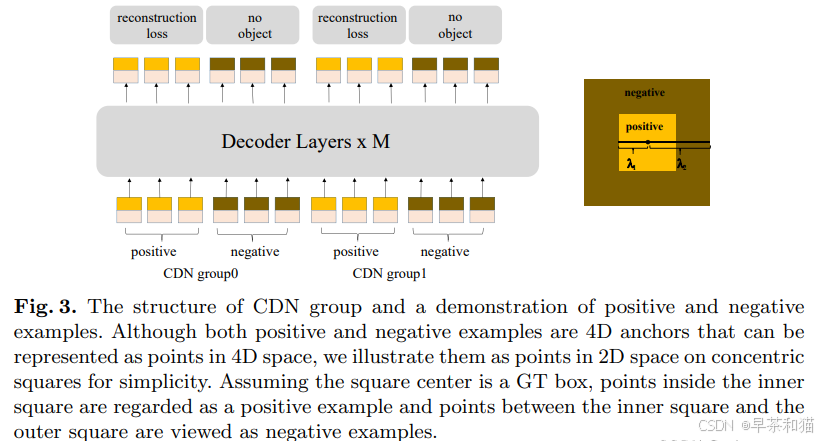
在DINO中,有两个超参数λ1和λ2,其中λ1 < λ2。如图3中的同心正方形所示,生成两种类型的CDN查询:正查询和负查询。内部正方形中的正查询的噪声尺度小于λ1,并且期望能够重构出相应的真实框。内部正方形和外部正方形之间的负查询的噪声尺度大于λ1且小于λ2。它们被期望预测为“无对象”。通常采用较小的λ2,因为靠近GT框的困难负样本对于提高性能更有帮助。如图3所示,每个CDN组都有一组正查询和负查询。如果一张图像有n个GT框,则CDN组将具有2×n个查询,每个GT框生成一个正查询和一个负查询。与DN-DETR类似,作者还使用多个CDN组来提高方法的有效性。重构损失包括边界框回归的l1损失和GIOU损失,分类则使用focal loss。将负样本分类为背景的损失也是focal loss。
加入噪声后,还需要注意的一点便是信息之间的是否可见问题,噪声 queries 是会和匈牙利匹配任务的 queries 拼接起来一起送入 transformer中的。在 transformer 中,它们会经过 attention 交互,这势必会得知一些信息,这是作弊行为,是绝对不允许的
一、首先,如上所述,匈牙利匹配任务的 queries 肯定不能看到 DN 任务的 queries。
二、其次,不同 dn group 的 queries 也不能相互看到。因为综合所有组来看,gt -> query 是 one-to-many 的,每个 gt 在
每组都会有 1 个 query 拥有自己的信息。于是,对于每个 query 来说,在其它各组中都势必存在 1 个 query 拥有自己负责预测的那个 gt 的信息。
三、接着,同一个 dn group 的 queries 是可以相互看的 。因为在每组内,gt -> query 是 one-to-one 的关系,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息。
四、最后,DN 任务的 queries 可以去看匈牙利匹配任务的 queries ,因为只有前者才拥有 gt 信息,而后者是“凭空构造”的(主要是先验,需要自己去学习)。
总的来说,attention mask 的设计归纳为:
1、匈牙利匹配任务的 queries 不能看到 DN任务的 queries;
2、DN 任务中,不同组的 queries 不能相互看到;
3、其它情况均可见
其中attn_mask:
tgt_size = num_dn + num_queries #192+300=492
attn_mask = torch.zeros([tgt_size, tgt_size], dtype=torch.bool) #[492,492]
# Match query cannot see the reconstruct
attn_mask[num_dn:, :num_dn] = True
# Reconstruct cannot see each other
for i in range(num_group):
#第一组,看不见他后面的所有目标
if i == 0:
#[0:24,24:192]
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), max_nums * 2 * (i + 1) : num_dn] = True
#最后一组,看不见他前面的所有目标
if i == num_group - 1:
#[12*2*7:12*2*8,:12*2*7]=[168:192,:168]
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), : max_nums * i * 2] = True
#中间组,看不见他前面的也看不见他后面的目标
else:
#[24:48,48:192]...
#[24:48,:24]...
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), max_nums * 2 * (i + 1) : num_dn] = True
attn_mask[max_nums * 2 * i : max_nums * 2 * (i + 1), : max_nums * 2 * i] = True
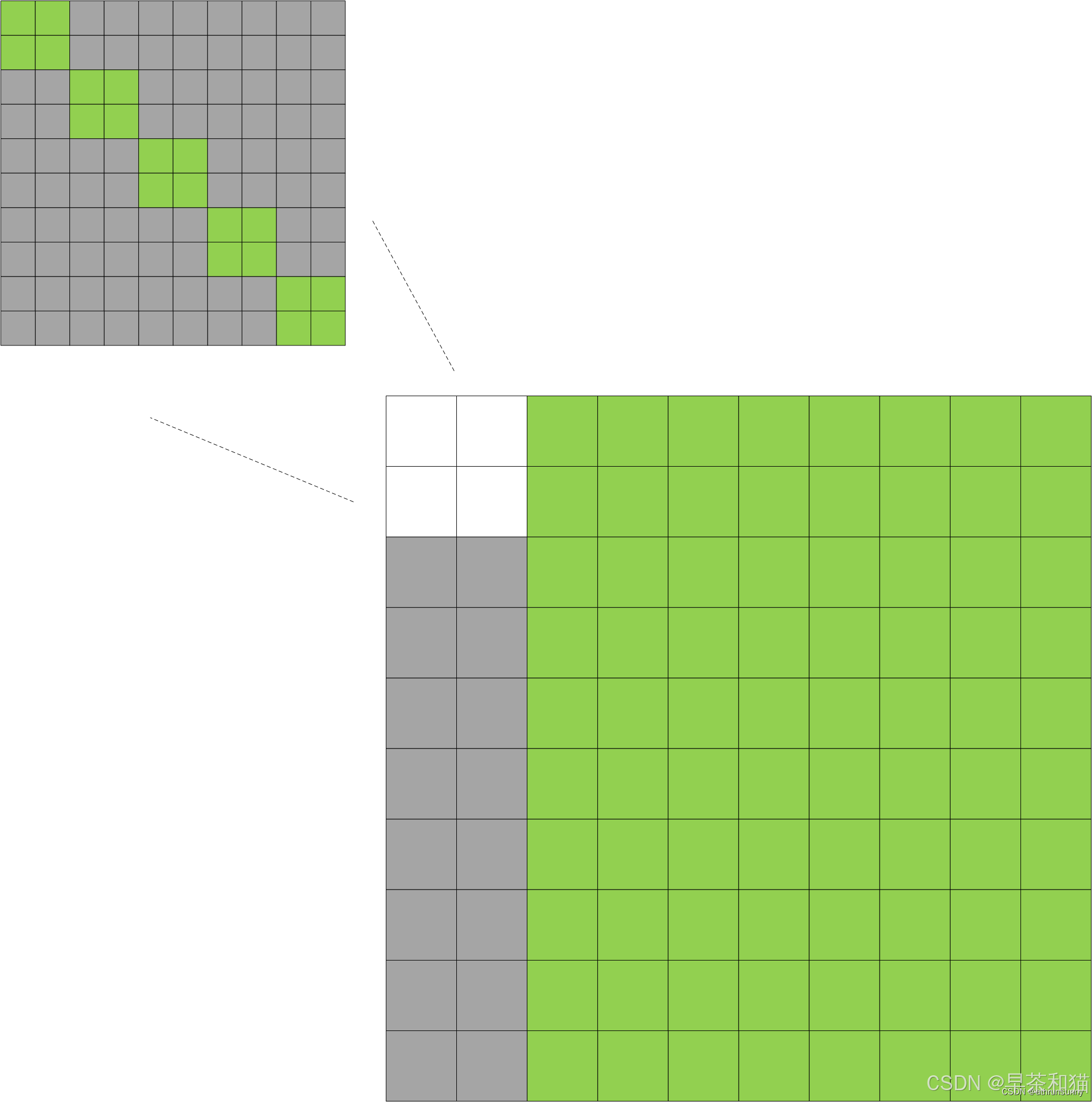
该max_nums表示在该batch中包含的最大的label个数。
其中绿色部分表示为False,灰色部分表示为True。有那么点最初的transformer的味道。上图是个示意图,右下角的大图为:
300+(num_group * 2max_nums)300+(num_group * 2max_nums),
左上的小图(num_group * 2max_nums)(num_group * 2max_nums)
这里还用到了DINO中的Mixed Query Selection策略,也就是从最后一个编码器层中选择前K个编码器特征作为先验,以增强解码器查询。
参考文献:
RT-DETR代码学习笔记(DETRs Beat YOLOs on Real-time Object Detection)
DINO代码学习笔记(一)
DINO代码学习笔记(二)
DINO代码学习笔记(三)
DINO代码学习笔记(四)
③ self._get_decoder_input()获取解码输入
训练时输出:
embed :有效区域内选出的top300的特征和去噪组的特征合并 , [batch,300+n,256]
refer_bbox:有效区域内选出的top300的特征经过Linear得到的bbox + top_k_anchors 与去噪组的bbox合并, [batch,300+n,4]
enc_bboxes:有效区域内选出的top300的特征经过Linear得到的bbox + top_k_anchors 再进行sigmoid
enc_scores:根据batch和topk的索引在enc_outputs_scores中得到enc_scores

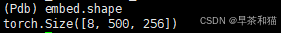
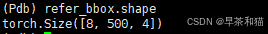
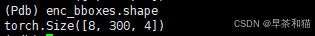

PS:预测时候只保留300个预测框,去噪组的生成框不加入
def _get_decoder_input(self, feats, shapes, dn_embed=None, dn_bbox=None):
"""Generates and prepares the input required for the decoder from the provided features and shapes."""
bs = feats.shape[0]
# Prepare input for decoder
anchors, valid_mask = self._generate_anchors(shapes, dtype=feats.dtype, device=feats.device) #[8, 8400, 4],[8, 8400, 1]
#输出一个encoder分类头:
#self.enc_output: Sequential(
# (0): Linear(in_features=256, out_features=256, bias=True)
# (1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
# )
# self.enc_score_head: Linear(in_features=256, out_features=14, bias=True)
features = self.enc_output(valid_mask * feats) # bs, h*w, 256 valid_mask * feats:([1, 8400, 1]*[8, 8400, 256]=[8, 8400, 256])
enc_outputs_scores = self.enc_score_head(features) # (bs, h*w, nc) [8, 8400, 256]->[8, 8400, 14]
# Query selection
# (bs, num_queries) 选择每个batch中得分值排名前300个框的位置索引
topk_ind = torch.topk(enc_outputs_scores.max(-1).values, self.num_queries, dim=1).indices.view(-1) #[300*8=2400]
# (bs, num_queries) 记录上述排名框对应的batch索引
batch_ind = torch.arange(end=bs, dtype=topk_ind.dtype).unsqueeze(-1).repeat(1, self.num_queries).view(-1) #[2400]
# (bs, num_queries, 256) #记录每个batch得分值前300个框在featuremap上对应点位的特征向量。
top_k_features = features[batch_ind, topk_ind].view(bs, self.num_queries, -1) #[8, 300, 256]
# (bs, num_queries, 4) #记录得分值前300的框坐标偏移
top_k_anchors = anchors[:, topk_ind].view(bs, self.num_queries, -1) #[8, 300, 4]
# Dynamic anchors + static content 输出一个encoder的box回归头(mlp)加上坐标偏移,获得encoder预测框
#self.enc_bbox_head:
#MLP((layers): ModuleList(
# (0-1): 2 x Linear(in_features=256, out_features=256, bias=True)
# (2): Linear(in_features=256, out_features=4, bias=True)
# )
# (act): ReLU(inplace=True)
# )
refer_bbox = self.enc_bbox_head(top_k_features) + top_k_anchors #[8, 300, 4]
#把预测框坐标限制在0-1之间
enc_bboxes = refer_bbox.sigmoid()
if dn_bbox is not None:
#合并encoder300个预测框和带噪声的gt编码框
refer_bbox = torch.cat([dn_bbox, refer_bbox], 1)
#挑出分类得分值前300个目标。
enc_scores = enc_outputs_scores[batch_ind, topk_ind].view(bs, self.num_queries, -1) #[8, 300, 14]
#得分前300个特征向量赋值给embeddings,默认 self.learnt_init_query为false不需要进行再学习,直接赋值。否则需要进行一次nn.Embedding(nq, hd)特征编码学习
embeddings = self.tgt_embed.weight.unsqueeze(0).repeat(bs, 1, 1) if self.learnt_init_query else top_k_features
#.detach()从当前的计算图中分离出来,返回一个新的Tensor。这个新的Tensor和原始的Tensor共享底层的存储空间,但不会参与到梯度的计算中。
if self.training:
refer_bbox = refer_bbox.detach()
if not self.learnt_init_query:
embeddings = embeddings.detach()
#encoder预测框特征向量和带噪声的gt编码框特征向量进行拼接
if dn_embed is not None:
embeddings = torch.cat([dn_embed, embeddings], 1)
#embedding:拼接了得分值前300的encoder预测框位置的特征向量和带噪声的gt编码框的特征向量,例[8,300,256]+[8,174,256]=[8,474,256]
#refer_bbox::拼接了得分值前300的encoder预测框坐标(未做sigmoid,后续进行DeformableTransformerDecoder里再做sigmoid)和带噪声的gt编码框坐标,例[8,300,4]+[8,174,4]=[8,474,4]
#enc_bboxes:得分值前300的encoder预测框坐标(做了sigmoid把框的坐标值限制在0-1之间的正值),例[8,300,4]
#enc_scores:所有batch中分类得分前300个分类输出,例[8,300,14],14是类别数,每个batch一共有300x14个得分。
return embeddings, refer_bbox, enc_bboxes, enc_scores
其中_generate_anchors根据特征图的大小,以特征图大小的网格中心生成归一化后的中心点坐标(grid_xy = (grid_xy.unsqueeze(0) + 0.5) / valid_WH),anchor的wh则根据(wh = torch.ones_like(grid_xy) * grid_size * (2.0 ** i))其中i表示层号(0-2)grid_size=0.05
def _generate_anchors(self, shapes, grid_size=0.05, dtype=torch.float32, device='cpu', eps=1e-2):
"""Generates anchor bounding boxes for given shapes with specific grid size and validates them."""
# 在给定shapes的情况下,_generate_anchors函数用于生成锚框(anchor bounding boxes)
# 并对其进行验证。其中,valid_mask是一个布尔掩码,用于标记哪些锚框是有效的
anchors = []
for i, (h, w) in enumerate(shapes):
sy = torch.arange(end=h, dtype=dtype, device=device)
sx = torch.arange(end=w, dtype=dtype, device=device)
grid_y, grid_x = torch.meshgrid(sy, sx, indexing='ij') if TORCH_1_10 else torch.meshgrid(sy, sx)
grid_xy = torch.stack([grid_x, grid_y], -1) # (h, w, 2)
valid_WH = torch.tensor([h, w], dtype=dtype, device=device)
grid_xy = (grid_xy.unsqueeze(0) + 0.5) / valid_WH # (1, h, w, 2)
wh = torch.ones_like(grid_xy, dtype=dtype, device=device) * grid_size * (2.0 ** i)
anchors.append(torch.cat([grid_xy, wh], -1).view(-1, h * w, 4)) # (1, h*w, 4)
anchors = torch.cat(anchors, 1) # (1, h*w*nl, 4)
# 限制每个anchor内的值都在[0.01-0.99]之间,在这个区间之外的值设为无效,后面通过masked_fill设为'inf'
valid_mask = ((anchors > eps) * (anchors < 1 - eps)).all(-1, keepdim=True) # 1, h*w*nl, 1
# 这里,将锚框的坐标值进行对数变换,并使用masked_fill函数将无效的锚框的值设置为正无穷(float('inf'))。
# 这样做是为了在后续处理中过滤掉无效的锚框。
anchors = torch.log(anchors / (1 - anchors))
anchors = anchors.masked_fill(~valid_mask, float('inf'))
return anchors, valid_mask
④进行tansformer,decoder
def __init__():
# Transformer module
decoder_layer = DeformableTransformerDecoderLayer(hd, nh, d_ffn, dropout, act, self.nl, ndp)
self.decoder = DeformableTransformerDecoder(hd, decoder_layer, ndl, eval_idx)
self.query_pos_head = MLP(4, 2 * hd, hd, num_layers=2)
# Decoder head
self.dec_score_head = nn.ModuleList([nn.Linear(hd, nc) for _ in range(ndl)])
self.dec_bbox_head = nn.ModuleList([MLP(hd, hd, 4, num_layers=3) for _ in range(ndl)])
def forward(self, x, batch=None):
# 6层Decoder输出 [6, 8, 474, 4],[6, 8, 474, 14]
dec_bboxes, dec_scores = self.decoder(
embed,
refer_bbox,
feats,
shapes,
self.dec_bbox_head,
self.dec_score_head,
self.query_pos_head,
attn_mask=attn_mask,
)
self.dec_bbox_head:
self.dec_score_head:
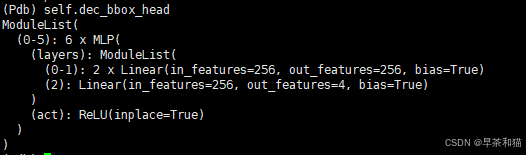
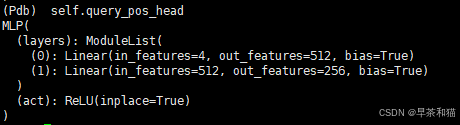
self.query_pos_head:

输入参数后进入DeformableTransformerDecoder:
训练的时候保存6个transformer层的输出,辅助loss计算,并且训练时候除了300个生成预测框还有额外的噪声框,非训练的时候只保留300个预测框。
预测和评估的时候只保留最后一层的输出结果作为最终输出,只保留300个预测框。
class DeformableTransformerDecoder(nn.Module):
"""
Implementation of Deformable Transformer Decoder based on PaddleDetection.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
"""
def __init__(self, hidden_dim, decoder_layer, num_layers, eval_idx=-1):
"""Initialize the DeformableTransformerDecoder with the given parameters."""
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers) #对DeformableTransformerDecoderLayer复制6层并串联
self.num_layers = num_layers #6层
self.hidden_dim = hidden_dim #256
self.eval_idx = eval_idx if eval_idx >= 0 else num_layers + eval_idx #6+(-1)=5
def forward(
self,
embed, # decoder embeddings
refer_bbox, # anchor
feats, # image features
shapes, # feature shapes
bbox_head,
score_head,
pos_mlp,
attn_mask=None,
padding_mask=None,
):
"""Perform the forward pass through the entire decoder."""
output = embed
dec_bboxes = [] #存放每层DeformableTransformerDecoderLayer输出结果框
dec_cls = [] #存放每层DeformableTransformerDecoderLayer输出类别得分
last_refined_bbox = None
refer_bbox = refer_bbox.sigmoid() #对得分值前300的encoder预测框坐标和带噪声的gt编码框坐标做sigmoid,把框的坐标值限制在0-1之间的正值, 例[8, 474, 4]
for i, layer in enumerate(self.layers):
#output:拼接了得分值前300的encoder预测框位置的特征向量和带噪声的gt编码框的特征向量,例[8,300,256]+[8,174,256]=[8,474,256]
#refer_bbox:[8, 474, 4]
#feats:3个feature_map的特征[8, 8400, 256]
#shapes:3个feature_map的尺寸,[[80, 80], [40, 40], [20, 20]],此处是以输入图像尺寸为640x640得到的结果
#padding_mask:无需做padding
#pos_mlp(refer_bbox):提取得分值前300的encoder预测框位置和带噪声的gt编码框的特征,[8, 474, 4]--->[8, 474, 256]
#attn_mask:[474,474]
output = layer(output, refer_bbox, feats, shapes, padding_mask, attn_mask, pos_mlp(refer_bbox))
bbox = bbox_head[i](output)
refined_bbox = torch.sigmoid(bbox + inverse_sigmoid(refer_bbox))
#训练的时候保存6个transformer层的输出,辅助loss计算,并且训练时候除了300个生成预测框还有额外的噪声框,非训练的时候只保留300个预测框
if self.training:
dec_cls.append(score_head[i](output))
if i == 0:
dec_bboxes.append(refined_bbox)
else:
dec_bboxes.append(torch.sigmoid(bbox + inverse_sigmoid(last_refined_bbox)))
#预测和评估的时候只保留最后一层的输出结果作为最终输出,只保留300个预测框
elif i == self.eval_idx:
dec_cls.append(score_head[i](output))
dec_bboxes.append(refined_bbox)
break
last_refined_bbox = refined_bbox
refer_bbox = refined_bbox.detach() if self.training else refined_bbox
return torch.stack(dec_bboxes), torch.stack(dec_cls)
其中
def _get_clones(module, n):
"""Create a list of cloned modules from the given module."""
return nn.ModuleList([copy.deepcopy(module) for _ in range(n)])
对于对单层layer就是一层DeformableTransformerDecoderLayer()
output = layer(output, refer_bbox, feats, shapes, padding_mask,attn_mask, pos_mlp(refer_bbox))
class DeformableTransformerDecoderLayer(nn.Module):
"""
Deformable Transformer Decoder Layer inspired by PaddleDetection and Deformable-DETR implementations.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/deformable_transformer.py
"""
def __init__(self, d_model=256, n_heads=8, d_ffn=1024, dropout=0.0, act=nn.ReLU(), n_levels=4, n_points=4):
"""Initialize the DeformableTransformerDecoderLayer with the given parameters."""
super().__init__()
# Self attention
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
self.dropout1 = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
# Cross attention
self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
self.dropout2 = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
# FFN
self.linear1 = nn.Linear(d_model, d_ffn)
self.act = act
self.dropout3 = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
self.dropout4 = nn.Dropout(dropout)
self.norm3 = nn.LayerNorm(d_model)
@staticmethod
def with_pos_embed(tensor, pos):
"""Add positional embeddings to the input tensor, if provided."""
return tensor if pos is None else tensor + pos
def forward_ffn(self, tgt):
"""Perform forward pass through the Feed-Forward Network part of the layer."""
tgt2 = self.linear2(self.dropout3(self.act(self.linear1(tgt))))
tgt = tgt + self.dropout4(tgt2)
return self.norm3(tgt)
def forward(self, embed, refer_bbox, feats, shapes, padding_mask=None, attn_mask=None, query_pos=None):
"""Perform the forward pass through the entire decoder layer."""
# Self attention
#query_pos为refer_bbox经过mlp提取到升维后的特征。pos_mlp(refer_bbox)
#q=k=embed+query_pos, 因为维度相同此处是参数相加,而非cat拼接操作。[8, 474, 256]+[8, 474, 256]=[8, 474, 256]
q = k = self.with_pos_embed(embed, query_pos)
#进行多头注意力机制操作,tgt:[8, 474, 256]
tgt = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), embed.transpose(0, 1), attn_mask=attn_mask)[0].transpose(0, 1)
#embed:[8, 474, 256]
embed = embed + self.dropout1(tgt)
#embed:[8, 474, 256]
embed = self.norm1(embed)
# Cross attention
# MSDeformAttn模块
tgt = self.cross_attn(
self.with_pos_embed(embed, query_pos), refer_bbox.unsqueeze(2), feats, shapes, padding_mask
)
embed = embed + self.dropout2(tgt)
embed = self.norm2(embed)
# FFN
return self.forward_ffn(embed)
对着下面图解一行一行看代码很容易理解
【Pytorch】一文向您详细介绍 nn.MultiheadAttention() 的作用和用法
MultiHeadAttention实现详解
MultiHead-Attention和Masked-Attention的机制和原理
单层decoder的图解
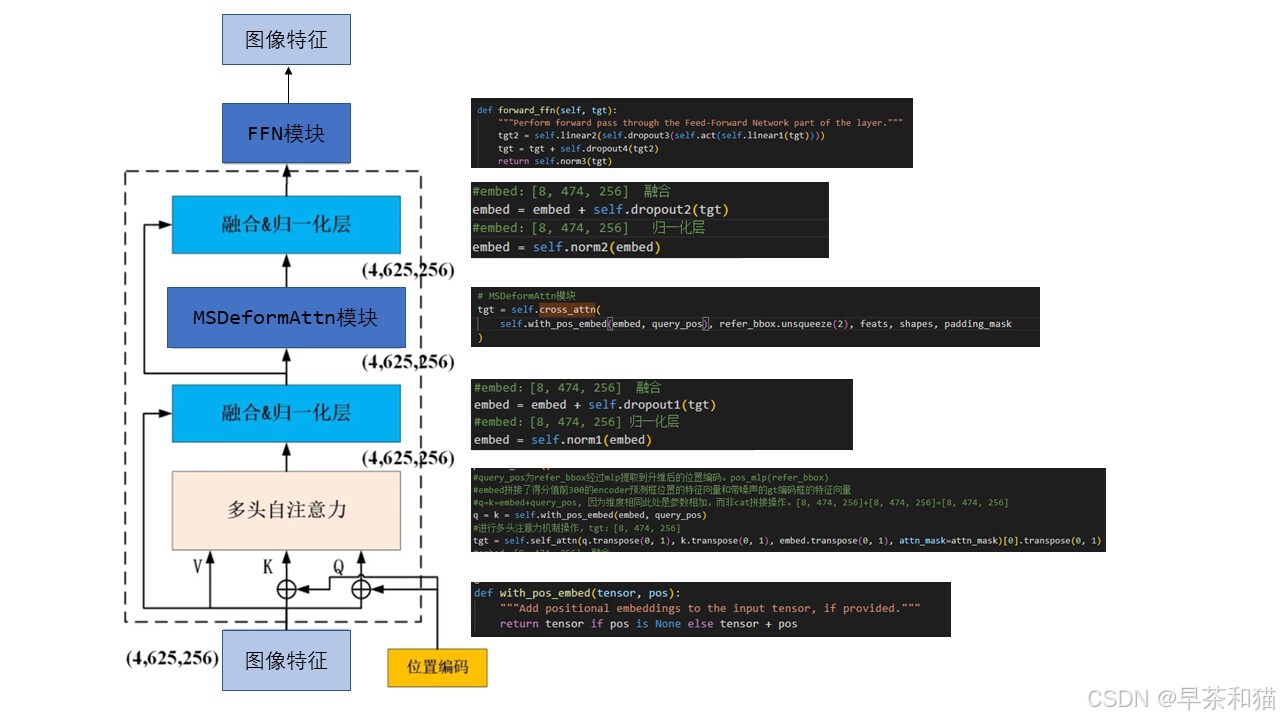
RT-DETR 详解之 Efficient Hybrid Encoder
DEFORMABLE DETR论文地址:https://arxiv.org/pdf/2010.04159
Deformable-DETR代码学习笔记
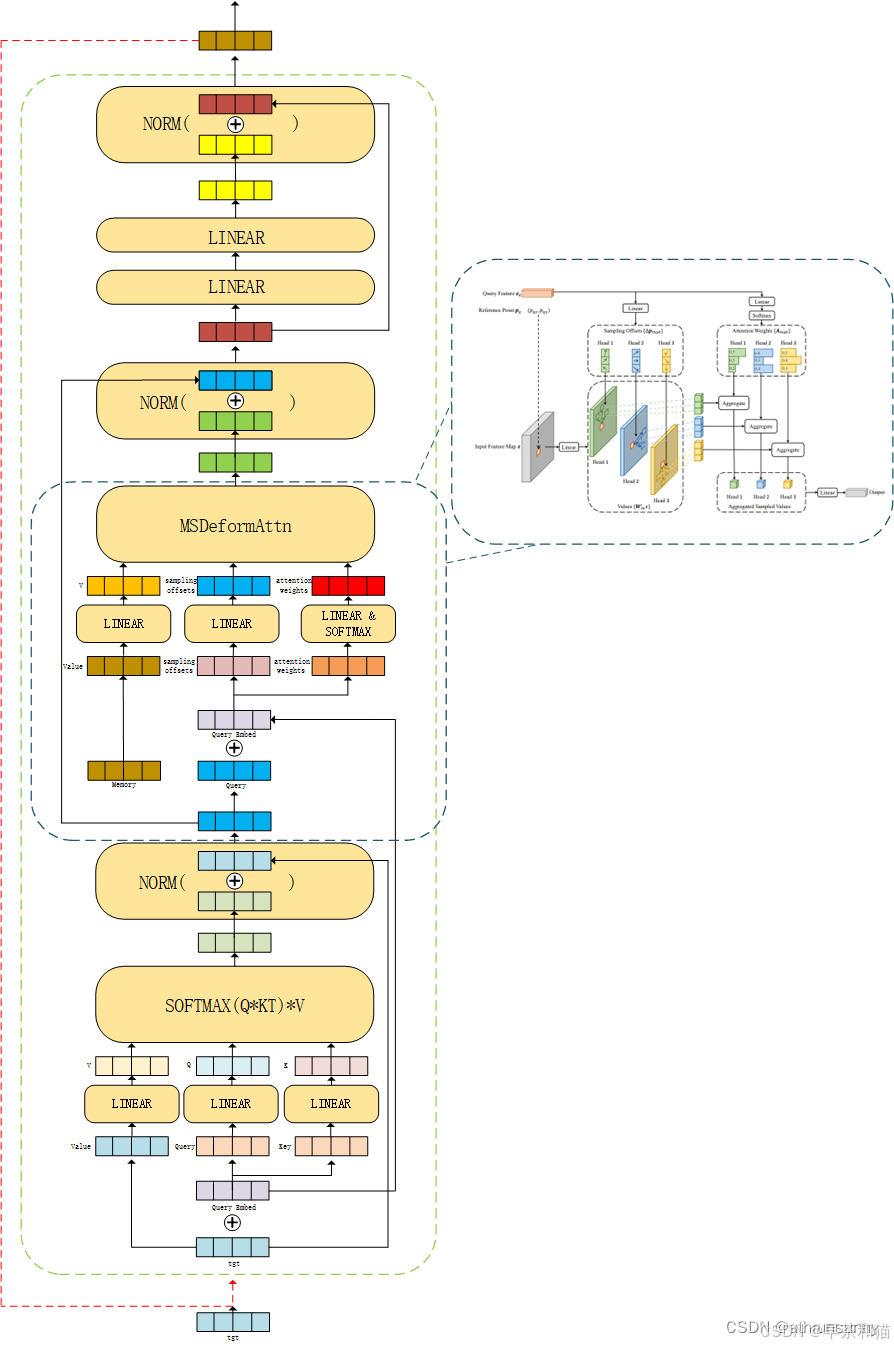
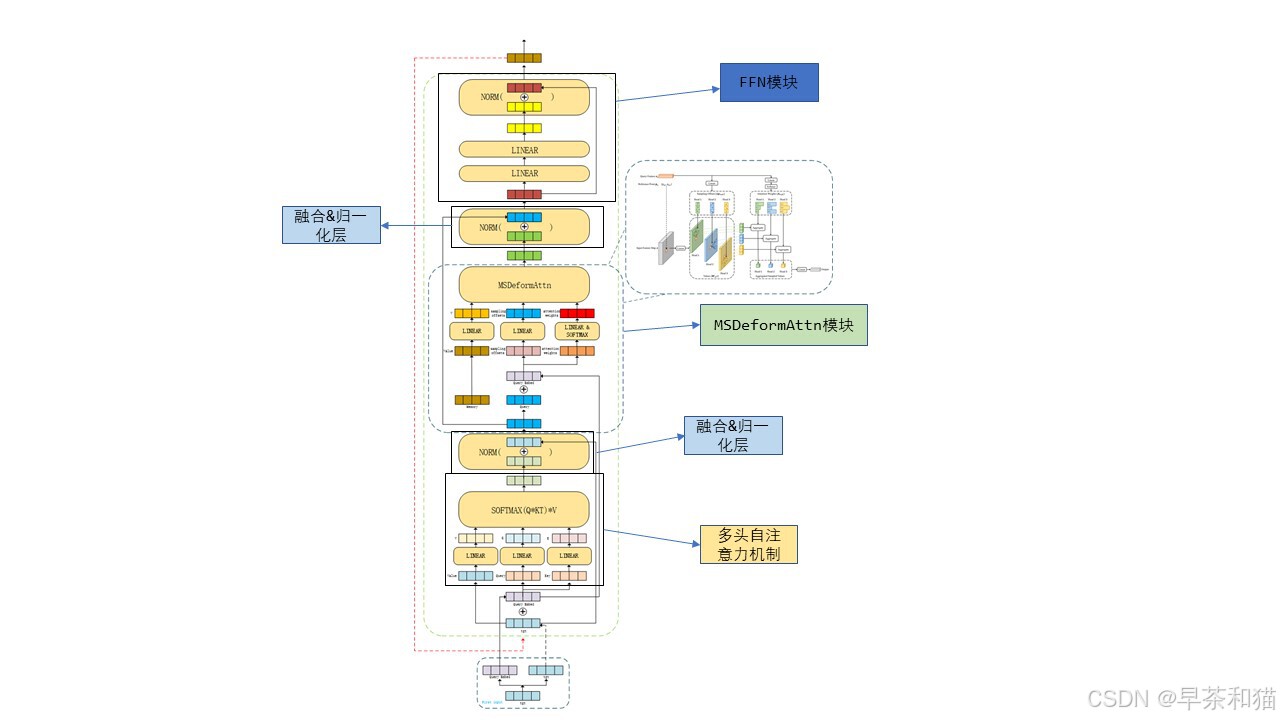
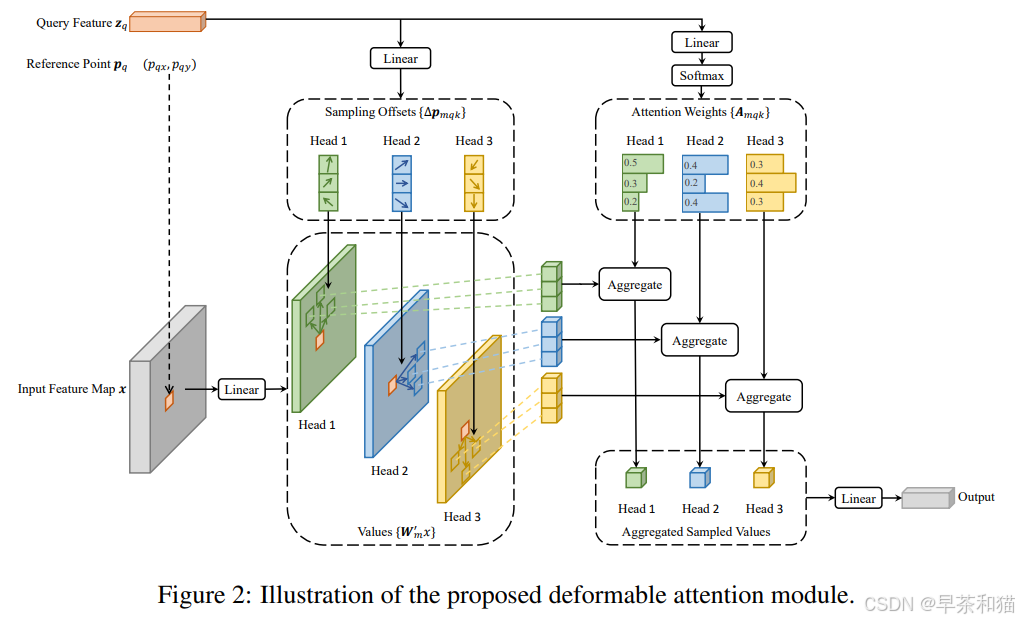
其中MSDeformAttn模块: value即是输入的图像特征[8, 8400, 256]。
计算公式:
代码实现:
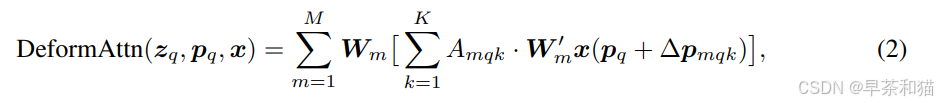
class MSDeformAttn(nn.Module):
"""
Multiscale Deformable Attention Module based on Deformable-DETR and PaddleDetection implementations.
https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/ops/modules/ms_deform_attn.py
"""
def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4):
"""Initialize MSDeformAttn with the given parameters."""
super().__init__()
if d_model % n_heads != 0:
raise ValueError(f"d_model must be divisible by n_heads, but got {d_model} and {n_heads}")
_d_per_head = d_model // n_heads
# Better to set _d_per_head to a power of 2 which is more efficient in a CUDA implementation
assert _d_per_head * n_heads == d_model, "`d_model` must be divisible by `n_heads`"
self.im2col_step = 64
self.d_model = d_model
self.n_levels = n_levels
self.n_heads = n_heads
self.n_points = n_points
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
self.value_proj = nn.Linear(d_model, d_model)
self.output_proj = nn.Linear(d_model, d_model)
self._reset_parameters()
def _reset_parameters(self):
"""Reset module parameters."""
constant_(self.sampling_offsets.weight.data, 0.0)
thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads)
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (
(grid_init / grid_init.abs().max(-1, keepdim=True)[0])
.view(self.n_heads, 1, 1, 2)
.repeat(1, self.n_levels, self.n_points, 1)
)
for i in range(self.n_points):
grid_init[:, :, i, :] *= i + 1
with torch.no_grad():
self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
constant_(self.attention_weights.weight.data, 0.0)
constant_(self.attention_weights.bias.data, 0.0)
xavier_uniform_(self.value_proj.weight.data)
constant_(self.value_proj.bias.data, 0.0)
xavier_uniform_(self.output_proj.weight.data)
constant_(self.output_proj.bias.data, 0.0)
def forward(self, query, refer_bbox, value, value_shapes, value_mask=None):
"""
Perform forward pass for multiscale deformable attention.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
Args:
query (torch.Tensor): [bs, query_length, C]
refer_bbox (torch.Tensor): [bs, query_length, n_levels, 2], range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area
value (torch.Tensor): [bs, value_length, C]
value_shapes (List): [n_levels, 2], [(H_0, W_0), (H_1, W_1), ..., (H_{L-1}, W_{L-1})]
value_mask (Tensor): [bs, value_length], True for non-padding elements, False for padding elements
Returns:
output (Tensor): [bs, Length_{query}, C]
"""
#query:embed+query_pos=[8, 474, 256]
#refer_bbox:[8, 474, 1, 4]
#value:就是feats,[8, 8400, 256]
#value_shapes:[[80, 80], [40, 40], [20, 20]]
#value_mask:None
bs, len_q = query.shape[:2] # bs:8,len_q:474
len_v = value.shape[1] #8400
assert sum(s[0] * s[1] for s in value_shapes) == len_v
#value:[8, 8400, 256]->[8, 8400, 256],走一个线性层之后的feature特征
value = self.value_proj(value)
if value_mask is not None:
value = value.masked_fill(value_mask[..., None], float(0))
#value:[8, 8400, 256]->[8, 8400, 8,32]
value = value.view(bs, len_v, self.n_heads, self.d_model // self.n_heads)
#sampling_offsets:[8, 474, 256]->[8, 474, 192]->[8, 474, 8, 3, 4, 2]
sampling_offsets = self.sampling_offsets(query).view(bs, len_q, self.n_heads, self.n_levels, self.n_points, 2)
#attention_weights:[8, 474, 256]->[8, 474, 96]->[8, 474, 8, 12]
attention_weights = self.attention_weights(query).view(bs, len_q, self.n_heads, self.n_levels * self.n_points)
#attention_weights:[8, 474, 8, 12]->[8, 474, 8, 3,4]
attention_weights = F.softmax(attention_weights, -1).view(bs, len_q, self.n_heads, self.n_levels, self.n_points)
# N, Len_q, n_heads, n_levels, n_points, 2
num_points = refer_bbox.shape[-1] #4
if num_points == 2:
offset_normalizer = torch.as_tensor(value_shapes, dtype=query.dtype, device=query.device).flip(-1)
add = sampling_offsets / offset_normalizer[None, None, None, :, None, :]
sampling_locations = refer_bbox[:, :, None, :, None, :] + add
elif num_points == 4:
#add:[8, 474, 8, 3, 4, 2]/4*[8, 474, 1, 1, 1, 2]*0.5=[8, 474, 8, 3, 4, 2]
add = sampling_offsets / self.n_points * refer_bbox[:, :, None, :, None, 2:] * 0.5
#sampling_locations:[8, 474, 8, 3, 4, 2]
sampling_locations = refer_bbox[:, :, None, :, None, :2] + add
else:
raise ValueError(f"Last dim of reference_points must be 2 or 4, but got {num_points}.")
#走一个多尺度变形注意力机制
output = multi_scale_deformable_attn_pytorch(value, value_shapes, sampling_locations, attention_weights)
return self.output_proj(output)
def multi_scale_deformable_attn_pytorch(
value: torch.Tensor,
value_spatial_shapes: torch.Tensor,
sampling_locations: torch.Tensor,
attention_weights: torch.Tensor,
) -> torch.Tensor:
"""
Multiscale deformable attention.
https://github.com/IDEA-Research/detrex/blob/main/detrex/layers/multi_scale_deform_attn.py
"""
bs, _, num_heads, embed_dims = value.shape #8,8400,8,32
_, num_queries, num_heads, num_levels, num_points, _ = sampling_locations.shape #8, 474, 8, 3, 4, 2
#value_spatial_shapes:[[80, 80], [40, 40], [20, 20]]
#value_list:把合并的3个特征图再切开,(8,8400,8,32)-> [[8, 6400, 8, 32],[8, 1600, 8, 32],[8, 400, 8, 32]]
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
#sampling_grids:[8, 474, 8, 3, 4, 2]->[8, 474, 8, 3, 4, 2]
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
#对应的特征层和对应尺寸宽高
for level, (H_, W_) in enumerate(value_spatial_shapes):
# bs, H_*W_, num_heads, embed_dims ->
# bs, H_*W_, num_heads*embed_dims ->
# bs, num_heads*embed_dims, H_*W_ ->
# bs*num_heads, embed_dims, H_, W_
#value_l_:resahep[8, 6400, 8, 32]->[64, 32, 80, 80]
value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape(bs * num_heads, embed_dims, H_, W_)
# bs, num_queries, num_heads, num_points, 2 ->
# bs, num_heads, num_queries, num_points, 2 ->
# bs*num_heads, num_queries, num_points, 2
#sampling_grid_l_:对当前特征层的grids进行操作,[8, 474, 8, 4, 2]->[8, 8, 474, 4, 2]->[64, 474, 4, 2]
sampling_grid_l_ = sampling_grids[:, :, :, level].transpose(1, 2).flatten(0, 1)
# bs*num_heads, embed_dims, num_queries, num_points
#sampling_value_l_:[64, 32, 474, 2]
sampling_value_l_ = F.grid_sample(
value_l_, sampling_grid_l_, mode="bilinear", padding_mode="zeros", align_corners=False
)
sampling_value_list.append(sampling_value_l_)
#sampling_value_list:[[64, 32, 474, 4],[64, 32, 474, 4],[64, 32, 474, 4]]
# (bs, num_queries, num_heads, num_levels, num_points) ->
# (bs, num_heads, num_queries, num_levels, num_points) ->
# (bs, num_heads, 1, num_queries, num_levels*num_points)
#attention_weights:[8, 474, 8, 3, 4]->[64, 1, 474, 12]
attention_weights = attention_weights.transpose(1, 2).reshape(
bs * num_heads, 1, num_queries, num_levels * num_points
)
#output:[64, 32, 474, 3, 4]->[64, 32, 474, 12]*[64, 1, 474, 12]=[64, 32, 474, 12]->[64, 32, 474]->[8, 256, 474]
output = (
(torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights)
.sum(-1)
.view(bs, num_heads * embed_dims, num_queries)
)
return output.transpose(1, 2).contiguous() #[8,474, 256]
经过一层DeformableTransformerDecoderLayer()之后拿到output的输出,再回到DeformableTransformerDecoder()的循环中,把6个DeformableTransformerDecoderLayer预测的边框和分类结果进行存储并返回,进行后续的loss计算。
(PS:这里的inverse_sigmoid操作我还不是特别理解,先做个记录)
output = layer(output, refer_bbox, feats, shapes, padding_mask, attn_mask, pos_mlp(refer_bbox))
#[8, 474, 256]->[8, 474, 4]
bbox = bbox_head[i](output)
refined_bbox = torch.sigmoid(bbox + inverse_sigmoid(refer_bbox))
if self.training:
dec_cls.append(score_head[i](output))
if i == 0:
dec_bboxes.append(refined_bbox)
else:
dec_bboxes.append(torch.sigmoid(bbox + inverse_sigmoid(last_refined_bbox)))
elif i == self.eval_idx:
dec_cls.append(score_head[i](output))
dec_bboxes.append(refined_bbox)
break
last_refined_bbox = refined_bbox
refer_bbox = refined_bbox.detach() if self.training else refined_bbox
return torch.stack(dec_bboxes), torch.stack(dec_cls)
计算完DeformableTransformerDecoderLayer(),再返回到head层存储self._get_decoder_input()和self.decoder()7个层的bbox和cls的预测输出。
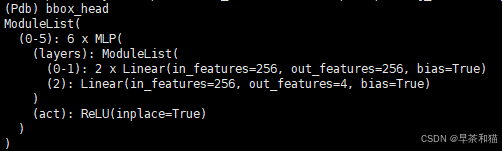

#存出6层decoder输出,和encoder最后一层的输出
x = dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta
if self.training:
return x
得到返回的预测输出后,回到task.py/RTDETRDetectionModel(DetectionModel)中的loss()函数
#获得输出头的预测结果,进行后续的loss计算
preds = self.predict(img, batch=targets) if preds is None else preds
dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta = preds if self.training else preds[1]
#把decoder层的输出,生成框和带噪声的gt框分开来。
if dn_meta is None:
dn_bboxes, dn_scores = None, None
else:
dn_bboxes, dec_bboxes = torch.split(dec_bboxes, dn_meta["dn_num_split"], dim=2)
dn_scores, dec_scores = torch.split(dec_scores, dn_meta["dn_num_split"], dim=2)
#讲encoder层和decoder层输出cat到一起,6+1
dec_bboxes = torch.cat([enc_bboxes.unsqueeze(0), dec_bboxes]) # (7, bs, 300, 4)
dec_scores = torch.cat([enc_scores.unsqueeze(0), dec_scores])
loss = self.criterion(
(dec_bboxes, dec_scores), targets, dn_bboxes=dn_bboxes, dn_scores=dn_scores, dn_meta=dn_meta
)
进行loss计算
3 loss计算
class RTDETRDetectionLoss(DETRLoss):
"""
Real-Time DeepTracker (RT-DETR) Detection Loss class that extends the DETRLoss.
This class computes the detection loss for the RT-DETR model, which includes the standard detection loss as well as
an additional denoising training loss when provided with denoising metadata.
"""
def forward(self, preds, batch, dn_bboxes=None, dn_scores=None, dn_meta=None):
"""
Forward pass to compute the detection loss.
Args:
preds (tuple): Predicted bounding boxes and scores.
batch (dict): Batch data containing ground truth information.
dn_bboxes (torch.Tensor, optional): Denoising bounding boxes. Default is None.
dn_scores (torch.Tensor, optional): Denoising scores. Default is None.
dn_meta (dict, optional): Metadata for denoising. Default is None.
Returns:
(dict): Dictionary containing the total loss and, if applicable, the denoising loss.
"""
pred_bboxes, pred_scores = preds #获取经过transformer编码后的预测的边框box和分类scores[7, 8, 300, 4],[7, 8, 300, 14]
total_loss = super().forward(pred_bboxes, pred_scores, batch) #计算300个无gt信息编码的预测框和gt的loss,走DETRLoss的forward
# Check for denoising metadata to compute denoising training loss
if dn_meta is not None:
dn_pos_idx, dn_num_group = dn_meta["dn_pos_idx"], dn_meta["dn_num_group"] #获取带噪声的正样本索引和group数量
assert len(batch["gt_groups"]) == len(dn_pos_idx)
# Get the match indices for denoising
# 获取带噪声的正样本和gt匹配上的索引对,用来计算loss,由于带噪声的正样本本来就是在gt基础上生成的所以并不需要进行匈牙利匹配,直接进行索引匹配就行了
match_indices = self.get_dn_match_indices(dn_pos_idx, dn_num_group, batch["gt_groups"])
# Compute the denoising training loss
dn_loss = super().forward(dn_bboxes, dn_scores, batch, postfix="_dn", match_indices=match_indices) #计算噪声正样本和gt的loss
total_loss.update(dn_loss) #更新噪声样本的loss
else:
# If no denoising metadata is provided, set denoising loss to zero
total_loss.update({f"{k}_dn": torch.tensor(0.0, device=self.device) for k in total_loss.keys()})
return total_loss
@staticmethod
def get_dn_match_indices(dn_pos_idx, dn_num_group, gt_groups):
"""
Get the match indices for denoising.
Args:
dn_pos_idx (List[torch.Tensor]): List of tensors containing positive indices for denoising.
dn_num_group (int): Number of denoising groups.
gt_groups (List[int]): List of integers representing the number of ground truths for each image.
Returns:
(List[tuple]): List of tuples containing matched indices for denoising.
"""
dn_match_indices = [] #创建存储索引对的列表
#idx_grouops的第n项值是对gt_groups的前n-1项进行累加。
#例如gt_groups:[7, 5, 8, 12, 12, 12, 6, 8],idx_groups:[ 0, 7, 12, 20, 32, 44, 56, 62]
idx_groups = torch.as_tensor([0, *gt_groups[:-1]]).cumsum_(0)
for i, num_gt in enumerate(gt_groups):
if num_gt > 0: #图像里得有目标框
gt_idx = torch.arange(end=num_gt, dtype=torch.long) + idx_groups[i]
gt_idx = gt_idx.repeat(dn_num_group)
assert len(dn_pos_idx[i]) == len(gt_idx), "Expected the same length, "
f"but got {len(dn_pos_idx[i])} and {len(gt_idx)} respectively."
dn_match_indices.append((dn_pos_idx[i], gt_idx))
else:
dn_match_indices.append((torch.zeros([0], dtype=torch.long), torch.zeros([0], dtype=torch.long)))
return dn_match_indices
super().forward()计算detr loss
class DETRLoss(nn.Module):
"""
DETR (DEtection TRansformer) Loss class. This class calculates and returns the different loss components for the
DETR object detection model. It computes classification loss, bounding box loss, GIoU loss, and optionally auxiliary
losses.
Attributes:
nc (int): The number of classes.
loss_gain (dict): Coefficients for different loss components.
aux_loss (bool): Whether to compute auxiliary losses.
use_fl (bool): Use FocalLoss or not.
use_vfl (bool): Use VarifocalLoss or not.
use_uni_match (bool): Whether to use a fixed layer to assign labels for the auxiliary branch.
uni_match_ind (int): The fixed indices of a layer to use if `use_uni_match` is True.
matcher (HungarianMatcher): Object to compute matching cost and indices.
fl (FocalLoss or None): Focal Loss object if `use_fl` is True, otherwise None.
vfl (VarifocalLoss or None): Varifocal Loss object if `use_vfl` is True, otherwise None.
device (torch.device): Device on which tensors are stored.
"""
def __init__(
self, nc=80, loss_gain=None, aux_loss=True, use_fl=True, use_vfl=False, use_uni_match=False, uni_match_ind=0
):
"""
Initialize DETR loss function with customizable components and gains.
Uses default loss_gain if not provided. Initializes HungarianMatcher with
preset cost gains. Supports auxiliary losses and various loss types.
Args:
nc (int): Number of classes.
loss_gain (dict): Coefficients for different loss components.
aux_loss (bool): Use auxiliary losses from each decoder layer.
use_fl (bool): Use FocalLoss.
use_vfl (bool): Use VarifocalLoss.
use_uni_match (bool): Use fixed layer for auxiliary branch label assignment.
uni_match_ind (int): Index of fixed layer for uni_match.
"""
super().__init__()
if loss_gain is None:
loss_gain = {"class": 1, "bbox": 5, "giou": 2, "no_object": 0.1, "mask": 1, "dice": 1}
self.nc = nc
self.matcher = HungarianMatcher(cost_gain={"class": 2, "bbox": 5, "giou": 2})
self.loss_gain = loss_gain
self.aux_loss = aux_loss
self.fl = FocalLoss() if use_fl else None
self.vfl = VarifocalLoss() if use_vfl else None
self.use_uni_match = use_uni_match
self.uni_match_ind = uni_match_ind
self.device = None
def _get_loss_class(self, pred_scores, targets, gt_scores, num_gts, postfix=""):
"""Computes the classification loss based on predictions, target values, and ground truth scores."""
# Logits: [b, query, num_classes], gt_class: list[[n, 1]]
name_class = f"loss_class{postfix}"
bs, nq = pred_scores.shape[:2]
# one_hot = F.one_hot(targets, self.nc + 1)[..., :-1] # (bs, num_queries, num_classes)
one_hot = torch.zeros((bs, nq, self.nc + 1), dtype=torch.int64, device=targets.device)
one_hot.scatter_(2, targets.unsqueeze(-1), 1)
one_hot = one_hot[..., :-1]
gt_scores = gt_scores.view(bs, nq, 1) * one_hot
if self.fl:
if num_gts and self.vfl:
loss_cls = self.vfl(pred_scores, gt_scores, one_hot)
else:
loss_cls = self.fl(pred_scores, one_hot.float())
loss_cls /= max(num_gts, 1) / nq
else:
loss_cls = nn.BCEWithLogitsLoss(reduction="none")(pred_scores, gt_scores).mean(1).sum() # YOLO CLS loss
return {name_class: loss_cls.squeeze() * self.loss_gain["class"]}
def _get_loss_bbox(self, pred_bboxes, gt_bboxes, postfix=""):
"""Computes bounding box and GIoU losses for predicted and ground truth bounding boxes."""
# Boxes: [b, query, 4], gt_bbox: list[[n, 4]]
name_bbox = f"loss_bbox{postfix}"
name_giou = f"loss_giou{postfix}"
loss = {}
if len(gt_bboxes) == 0:
loss[name_bbox] = torch.tensor(0.0, device=self.device)
loss[name_giou] = torch.tensor(0.0, device=self.device)
return loss
loss[name_bbox] = self.loss_gain["bbox"] * F.l1_loss(pred_bboxes, gt_bboxes, reduction="sum") / len(gt_bboxes)
loss[name_giou] = 1.0 - bbox_iou(pred_bboxes, gt_bboxes, xywh=True, GIoU=True)
loss[name_giou] = loss[name_giou].sum() / len(gt_bboxes)
loss[name_giou] = self.loss_gain["giou"] * loss[name_giou]
return {k: v.squeeze() for k, v in loss.items()}
# This function is for future RT-DETR Segment models
# def _get_loss_mask(self, masks, gt_mask, match_indices, postfix=''):
# # masks: [b, query, h, w], gt_mask: list[[n, H, W]]
# name_mask = f'loss_mask{postfix}'
# name_dice = f'loss_dice{postfix}'
#
# loss = {}
# if sum(len(a) for a in gt_mask) == 0:
# loss[name_mask] = torch.tensor(0., device=self.device)
# loss[name_dice] = torch.tensor(0., device=self.device)
# return loss
#
# num_gts = len(gt_mask)
# src_masks, target_masks = self._get_assigned_bboxes(masks, gt_mask, match_indices)
# src_masks = F.interpolate(src_masks.unsqueeze(0), size=target_masks.shape[-2:], mode='bilinear')[0]
# # TODO: torch does not have `sigmoid_focal_loss`, but it's not urgent since we don't use mask branch for now.
# loss[name_mask] = self.loss_gain['mask'] * F.sigmoid_focal_loss(src_masks, target_masks,
# torch.tensor([num_gts], dtype=torch.float32))
# loss[name_dice] = self.loss_gain['dice'] * self._dice_loss(src_masks, target_masks, num_gts)
# return loss
# This function is for future RT-DETR Segment models
# @staticmethod
# def _dice_loss(inputs, targets, num_gts):
# inputs = F.sigmoid(inputs).flatten(1)
# targets = targets.flatten(1)
# numerator = 2 * (inputs * targets).sum(1)
# denominator = inputs.sum(-1) + targets.sum(-1)
# loss = 1 - (numerator + 1) / (denominator + 1)
# return loss.sum() / num_gts
def _get_loss_aux(
self,
pred_bboxes,
pred_scores,
gt_bboxes,
gt_cls,
gt_groups,
match_indices=None,
postfix="",
masks=None,
gt_mask=None,
):
"""Get auxiliary losses."""
# NOTE: loss class, bbox, giou, mask, dice
loss = torch.zeros(5 if masks is not None else 3, device=pred_bboxes.device)
if match_indices is None and self.use_uni_match:
match_indices = self.matcher(
pred_bboxes[self.uni_match_ind],
pred_scores[self.uni_match_ind],
gt_bboxes,
gt_cls,
gt_groups,
masks=masks[self.uni_match_ind] if masks is not None else None,
gt_mask=gt_mask,
)
#分别计算每一辅助层的loss
for i, (aux_bboxes, aux_scores) in enumerate(zip(pred_bboxes, pred_scores)):
aux_masks = masks[i] if masks is not None else None
loss_ = self._get_loss(
aux_bboxes,
aux_scores,
gt_bboxes,
gt_cls,
gt_groups,
masks=aux_masks,
gt_mask=gt_mask,
postfix=postfix,
match_indices=match_indices,
)
loss[0] += loss_[f"loss_class{postfix}"]
loss[1] += loss_[f"loss_bbox{postfix}"]
loss[2] += loss_[f"loss_giou{postfix}"]
# if masks is not None and gt_mask is not None:
# loss_ = self._get_loss_mask(aux_masks, gt_mask, match_indices, postfix)
# loss[3] += loss_[f'loss_mask{postfix}']
# loss[4] += loss_[f'loss_dice{postfix}']
loss = {
f"loss_class_aux{postfix}": loss[0],
f"loss_bbox_aux{postfix}": loss[1],
f"loss_giou_aux{postfix}": loss[2],
}
# if masks is not None and gt_mask is not None:
# loss[f'loss_mask_aux{postfix}'] = loss[3]
# loss[f'loss_dice_aux{postfix}'] = loss[4]
return loss
@staticmethod
def _get_index(match_indices):
"""Returns batch indices, source indices, and destination indices from provided match indices."""
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(match_indices)])
src_idx = torch.cat([src for (src, _) in match_indices])
dst_idx = torch.cat([dst for (_, dst) in match_indices])
return (batch_idx, src_idx), dst_idx
def _get_assigned_bboxes(self, pred_bboxes, gt_bboxes, match_indices):
"""Assigns predicted bounding boxes to ground truth bounding boxes based on the match indices."""
pred_assigned = torch.cat(
[
t[i] if len(i) > 0 else torch.zeros(0, t.shape[-1], device=self.device)
for t, (i, _) in zip(pred_bboxes, match_indices)
]
)
gt_assigned = torch.cat(
[
t[j] if len(j) > 0 else torch.zeros(0, t.shape[-1], device=self.device)
for t, (_, j) in zip(gt_bboxes, match_indices)
]
)
return pred_assigned, gt_assigned
def _get_loss(
self,
pred_bboxes,
pred_scores,
gt_bboxes,
gt_cls,
gt_groups,
masks=None,
gt_mask=None,
postfix="",
match_indices=None,
):
"""Get losses."""
#预测框和gt进行匈牙利匹配
if match_indices is None:
match_indices = self.matcher(
pred_bboxes, pred_scores, gt_bboxes, gt_cls, gt_groups, masks=masks, gt_mask=gt_mask
)
idx, gt_idx = self._get_index(match_indices)
pred_bboxes, gt_bboxes = pred_bboxes[idx], gt_bboxes[gt_idx]
bs, nq = pred_scores.shape[:2]
targets = torch.full((bs, nq), self.nc, device=pred_scores.device, dtype=gt_cls.dtype)
targets[idx] = gt_cls[gt_idx]
gt_scores = torch.zeros([bs, nq], device=pred_scores.device)
if len(gt_bboxes):
gt_scores[idx] = bbox_iou(pred_bboxes.detach(), gt_bboxes, xywh=True).squeeze(-1)
#loss是个字典模式,通过updata将不同的loss更新到另一个字典中。如果键在两个字典都存在,则会用新字典中的值覆盖旧字典中的值。
loss = {}
loss.update(self._get_loss_class(pred_scores, targets, gt_scores, len(gt_bboxes), postfix))
loss.update(self._get_loss_bbox(pred_bboxes, gt_bboxes, postfix))
# if masks is not None and gt_mask is not None:
# loss.update(self._get_loss_mask(masks, gt_mask, match_indices, postfix))
return loss
def forward(self, pred_bboxes, pred_scores, batch, postfix="", **kwargs):
"""
Calculate loss for predicted bounding boxes and scores.
Args:
pred_bboxes (torch.Tensor): Predicted bounding boxes, shape [l, b, query, 4].
pred_scores (torch.Tensor): Predicted class scores, shape [l, b, query, num_classes].
batch (dict): Batch information containing:
cls (torch.Tensor): Ground truth classes, shape [num_gts].
bboxes (torch.Tensor): Ground truth bounding boxes, shape [num_gts, 4].
gt_groups (List[int]): Number of ground truths for each image in the batch.
postfix (str): Postfix for loss names.
**kwargs (Any): Additional arguments, may include 'match_indices'.
Returns:
(dict): Computed losses, including main and auxiliary (if enabled).
Note:
Uses last elements of pred_bboxes and pred_scores for main loss, and the rest for auxiliary losses if
self.aux_loss is True.
"""
self.device = pred_bboxes.device
match_indices = kwargs.get("match_indices", None)
#获取gt
gt_cls, gt_bboxes, gt_groups = batch["cls"], batch["bboxes"], batch["gt_groups"]
#total_loss包括loss_class,loss_bbox,loss_giou.
#pred_bboxes:[7, 8, 300, 4],pred_scores:[7, 8, 300, 14],7是包括1个encoder和6个decoder中间层输出
total_loss = self._get_loss(
pred_bboxes[-1], pred_scores[-1], gt_bboxes, gt_cls, gt_groups, postfix=postfix, match_indices=match_indices
)
#除去decoder最后一层的输出,其余中间层的输出计算辅助loss,pred_bboxes[:-1]:[6, 8, 300, 4],pred_scores[:-1]:[6, 8, 300, 14]
#更新后的total_loss包括loss_class,loss_bbox,loss_giou,loss_class_aux,loss_bbox_aux,loss_giou_aux
if self.aux_loss:
total_loss.update(
self._get_loss_aux(
pred_bboxes[:-1], pred_scores[:-1], gt_bboxes, gt_cls, gt_groups, match_indices, postfix
)
)
return total_loss
4、训练完之后的模型预测
如果不是训练,head则是做以下输出
def forward(self, x, batch=None):
"""Runs the forward pass of the module, returning bounding box and classification scores for the input."""
from ultralytics.models.utils.ops import get_cdn_group
feats, shapes = self._get_encoder_input(x)
# 预测时候跳过这一步
dn_embed, dn_bbox, attn_mask, dn_meta = get_cdn_group(
batch,
self.nc,
self.num_queries,
self.denoising_class_embed.weight,
self.num_denoising,
self.label_noise_ratio,
self.box_noise_scale,
self.training,#只有训练时才进行
)
#embed:【1,300,256】
#refer_bbox:【1,300,4】
embed, refer_bbox, enc_bboxes, enc_scores = self._get_decoder_input(feats, shapes, dn_embed, dn_bbox)
# 6层Decoder输出 [1, 1, 300, 4],[1, 1, 300, 14],此时self.decoder只保留最后一层的输出结果
dec_bboxes, dec_scores = self.decoder(
embed,
refer_bbox,
feats,
shapes,
self.dec_bbox_head,
self.dec_score_head,
self.query_pos_head,
attn_mask=attn_mask,
)
# (bs, 300, 4+nc)
y = torch.cat((dec_bboxes.squeeze(0), dec_scores.squeeze(0).sigmoid()), -1)
return y if self.export else (y, x)
对head输出结果300个框根据得分值进行过滤
class RTDETRPredictor(BasePredictor):
"""
RT-DETR (Real-Time Detection Transformer) Predictor extending the BasePredictor class for making predictions using
Baidu's RT-DETR model.
This class leverages the power of Vision Transformers to provide real-time object detection while maintaining
high accuracy. It supports key features like efficient hybrid encoding and IoU-aware query selection.
Example:
```python
from ultralytics.utils import ASSETS
from ultralytics.models.rtdetr import RTDETRPredictor
args = dict(model="rtdetr-l.pt", source=ASSETS)
predictor = RTDETRPredictor(overrides=args)
predictor.predict_cli()
```
Attributes:
imgsz (int): Image size for inference (must be square and scale-filled).
args (dict): Argument overrides for the predictor.
"""
def postprocess(self, preds, img, orig_imgs):
"""
Postprocess the raw predictions from the model to generate bounding boxes and confidence scores.
The method filters detections based on confidence and class if specified in `self.args`.
Args:
preds (list): List of [predictions, extra] from the model.
img (torch.Tensor): Processed input images.
orig_imgs (list or torch.Tensor): Original, unprocessed images.
Returns:
(list[Results]): A list of Results objects containing the post-processed bounding boxes, confidence scores,
and class labels.
"""
if not isinstance(preds, (list, tuple)): # list for PyTorch inference but list[0] Tensor for export inference
preds = [preds, None]
nd = preds[0].shape[-1]
bboxes, scores = preds[0].split((4, nd - 4), dim=-1)
if not isinstance(orig_imgs, list): # input images are a torch.Tensor, not a list
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = []
for bbox, score, orig_img, img_path in zip(bboxes, scores, orig_imgs, self.batch[0]): # (300, 4)
bbox = ops.xywh2xyxy(bbox)
max_score, cls = score.max(-1, keepdim=True) # (300, 1)
idx = max_score.squeeze(-1) > self.args.conf # (300, ) #获取得分值大于阈值的目标索引
if self.args.classes is not None:
idx = (cls == torch.tensor(self.args.classes, device=cls.device)).any(1) & idx
pred = torch.cat([bbox, max_score, cls], dim=-1)[idx] # filter 过滤
oh, ow = orig_img.shape[:2]
pred[..., [0, 2]] *= ow
pred[..., [1, 3]] *= oh
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 一文带你搞定Ultralytics(yolov11版本)中的RTDETR训练以及预测的代码解析和流程分析

发表评论 取消回复