Apache Hive™是一个分布式的、容错的数据仓库系统,它支持大规模的分析,并使用SQL方便地读取、写入和管理驻留在分布式存储中的pb级数据。
Apache Hive是什么
Apache Hive是一个分布式的、容错的数据仓库系统,支持大规模的分析。Hive Metastore(HMS)提供了一个元数据的中央存储库,可以很容易地对其进行分析,从而做出明智的、数据驱动的决策,因此它是许多数据湖架构的关键组件。Hive建立在Apache Hadoop之上,通过hdfs支持S3、adls、gs等存储。Hive允许用户使用SQL读取、写入和管理pb级的数据。
Hive-Server 2 (HS2)
HS2支持多客户机并发性和身份验证。它旨在为JDBC和ODBC等开放API客户机提供更好的支持。
>beeline -u "jdbc:hive2://host:10001/default"
Connected to: Apache Hive
>jdbc:hive2://host:10001/>select count(*) from test_t1;学习更多:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Overview
Hive Metastore Server (HMS)
Hive Metastore (HMS)是关系数据库中Hive表和分区的元数据中央存储库,并通过Metastore服务API为客户端(包括Hive、Impala和Spark)提供访问这些信息的服务。它已经成为数据湖的构建块,这些数据湖利用了各种开源软件,比如Apache Spark和Presto。事实上,一个完整的工具生态系统,开源的和其他的,都是围绕Hive Metastore构建的,这张图展示了其中的一些。
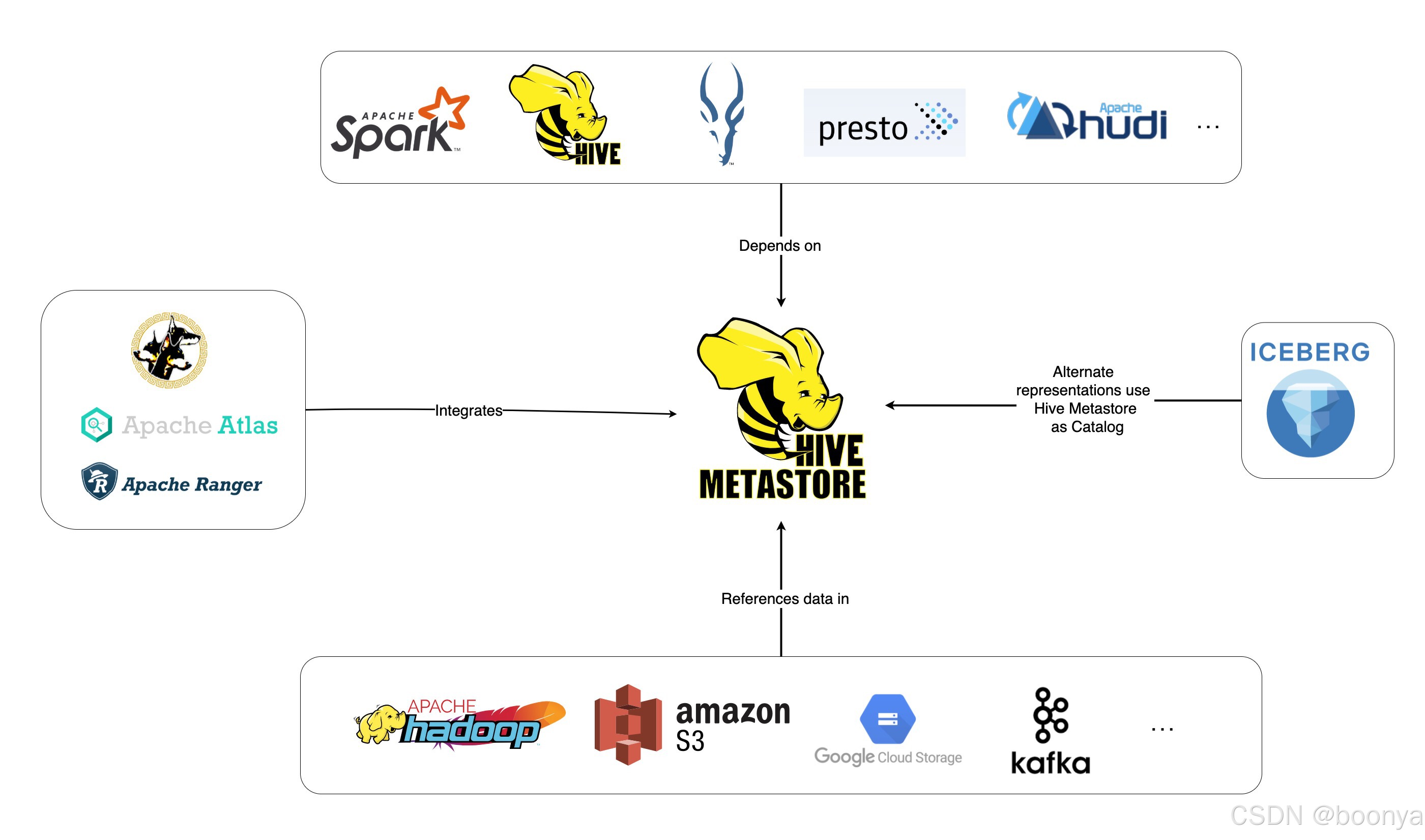
学习更多:Design - Apache Hive - Apache Software Foundation
Hive ACID
Hive为ORC表提供了完整的ACID支持,并且只支持插入所有其他格式。

了解更多:Hive Transactions - Apache Hive - Apache Software Foundation
Hive数据压缩
基于查询和基于mr的数据压缩是开箱即用的。
jdbc:hive2://> alter table test_t1 compact "MAJOR";
Done!
jdbc:hive2://> alter table test_t1 compact "MINOR";
Done!
jdbc:hive2://> show compactions;
学习更多:LanguageManual DDL - Apache Hive - Apache Software Foundation
Hive冰山
Hive通过Hive StorageHandler为Apache冰山表提供了开箱即用的支持,冰山表是一种云原生的高性能开放表格式。

安全性和可观察性
Apache Hive支持kerberos认证,并与Apache Ranger和Apache Atlas集成以提高安全性和可观察性。



Apache Atlas – Apache Atlas Hook & Bridge for Apache Hive
Hive LLAP
Apache Hive通过低延迟分析处理(LLAP)实现交互式和亚秒级SQL, LLAP在Hive 2.0中引入,通过使用持久的查询基础设施和优化的数据缓存使Hive更快
LLAP - Apache Hive - Apache Software Foundation
查询规划器和基于成本的优化器
Hive使用Apache Calcite的基于成本的查询优化器(CBO)和查询执行框架来优化sql查询。
jdbc:hive2://> explain cbo select ss.ss_net_profit, sr.sr_net_loss from store_sales ss join store_returns sr on (ss.ss_item_sk=sr.sr_item_sk) limit 5 ;+---------------------------------------------+ Explain +---------------------------------------------+ CBO PLAN: HiveSortLimit(fetch=[5]) HiveProject(ss_net_profit=[$1], sr_net_loss=[$3]) HiveJoin(condition=[=($0, $2)], joinType=[inner]) HiveProject(ss_item_sk=[$2], ss_net_profit=[$22]) HiveFilter(condition=[IS NOT NULL($2)]) HiveTableScan(table=[[tpcds_text_10, store_sales]], table:alias=[ss]) HiveProject(sr_item_sk=[$2], sr_net_loss=[$19]) HiveFilter(condition=[IS NOT NULL($2)]) HiveTableScan(table=[[tpcds_text_10, store_returns]], table:alias=[sr]) +---------------------------------------------+Hive复制
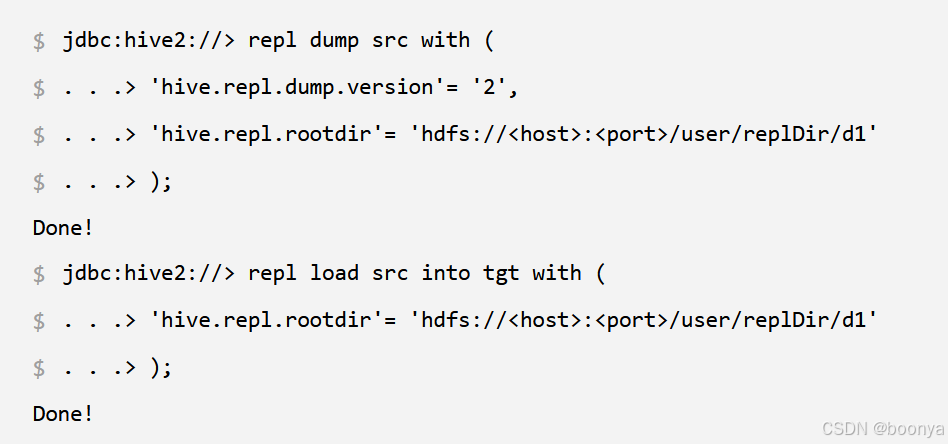
Hive支持启动复制和增量复制,用于备份和恢复。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Apache Hive分布式容错数据仓库系统

发表评论 取消回复