1 参数初始化
实现一个神经网络前,需要先初始化模型参数。如果对每一层的权重和偏置都用0初始化,那么通过第一遍前向计算,所有隐藏层神经元的激活值都相同;在反向传播时,所有权重的更新也都相同,这样会导致隐藏层神经元没有差异性,出现对称权重现象。
导入需要的库:
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.init import constant_, normal_, uniform_
import torch
from data import make_moons
from nndl import accuracy
from Runner2_2 import RunnerV2_2
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt 这次实验又认识到一个pytorch新的模块torch.nn.init ,是 PyTorch 中一个用于初始化神经网络模型参数的模块。
总结常用的几个有:
常数初始化:将权重或偏置初始化为固定值torch.nn.init.constant_(tensor, value)
正态分布初始化:从正态分布中随机生成权重
torch.nn.init.normal_(tensor, mean, std)均匀分布初始化:从均匀分布中随机生成权重。torch.nn.init.uniform_(tensor, a, b)
零初始化:将权重或偏置初始化为零torch.nn.init.zeros_(tensor)
模型构建
将模型参数全都初始化为0
class Model_MLP_L2_V4(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model_MLP_L2_V4, self).__init__()
# 定义第一个线性层,输入特征数为 input_size,输出特征数为 hidden_size
self.fc1 = nn.Linear(input_size, hidden_size)
'''
weight为权重参数属性,bias为偏置参数属性,这里使用'torch.nn.init.constant_'进行常量初始化
'''
# 初始化第一个线性层的权重和偏置为 0
constant_(self.fc1.weight, 0.0)
constant_(self.fc1.bias, 0.0)
# 定义第二个线性层,输入特征数为 hidden_size,输出特征数为 output_size
self.fc2 = nn.Linear(hidden_size, output_size)
# 初始化第二个线性层的权重和偏置为 0
constant_(self.fc2.weight, 0.0)
constant_(self.fc2.bias, 0.0)
self.act_fn = F.sigmoid
# 前向计算
def forward(self, inputs):
z1 = self.fc1(inputs)
a1 = self.act_fn(z1)
z2 = self.fc2(a1)
a2 = self.act_fn(z2)
return a2设置打印权重变化的函数:
def print_weight(runner):
print('The weights of the Layers:')
# 通过 enumerate() 可以同时获取参数的索引 i 和参数的内容 item
for i, item in enumerate(runner.model.named_parameters()):
print(item)
print('=========================')模型训练
利用runner类训练模型:
# ================================训练模型===========================
input_size = 2
hidden_size = 5
output_size = 1
model = Model_MLP_L2_V4(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 设置损失函数
loss_fn = F.binary_cross_entropy
# 设置优化器
learning_rate = 0.2
optimizer = torch.optim.SGD(params=model.parameters(), lr=learning_rate)
# 设置评价指标
metric = accuracy
# 其他参数
epoch = 2000
saved_path = 'best_model.pdparams'
# 实例化RunnerV2_2类,并传入训练配置
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=5, log_epochs=50, save_path="best_model.pdparams",
custom_print_log=print_weight)输出结果:
The weights of the Layers:
('fc1.weight', Parameter containing:
tensor([[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]], requires_grad=True))
=========================
('fc1.bias', Parameter containing:
tensor([0., 0., 0., 0., 0.], requires_grad=True))
=========================
('fc2.weight', Parameter containing:
tensor([[0., 0., 0., 0., 0.]], requires_grad=True))
=========================
('fc2.bias', Parameter containing:
tensor([0.], requires_grad=True))
=========================
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.47500
[Train] epoch: 0/5, loss: 0.6931473016738892
The weights of the Layers:
('fc1.weight', Parameter containing:
tensor([[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]], requires_grad=True))
=========================
('fc1.bias', Parameter containing:
tensor([0., 0., 0., 0., 0.], requires_grad=True))
=========================
('fc2.weight', Parameter containing:
tensor([[0.0008, 0.0008, 0.0008, 0.0008, 0.0008]], requires_grad=True))
=========================
('fc2.bias', Parameter containing:
tensor([0.0016], requires_grad=True))
=========================
The weights of the Layers:
('fc1.weight', Parameter containing:
tensor([[ 9.3081e-06, -7.6568e-06],
[ 9.3081e-06, -7.6568e-06],
[ 9.3081e-06, -7.6568e-06],
[ 9.3081e-06, -7.6568e-06],
[ 9.3081e-06, -7.6568e-06]], requires_grad=True))
=========================
('fc1.bias', Parameter containing:
tensor([2.7084e-07, 2.7084e-07, 2.7084e-07, 2.7084e-07, 2.7084e-07],
requires_grad=True))
=========================
('fc2.weight', Parameter containing:
tensor([[0.0015, 0.0015, 0.0015, 0.0015, 0.0015]], requires_grad=True))
=========================
('fc2.bias', Parameter containing:
tensor([0.0029], requires_grad=True))
=========================
The weights of the Layers:
('fc1.weight', Parameter containing:
tensor([[ 2.6847e-05, -2.2122e-05],
[ 2.6847e-05, -2.2122e-05],
[ 2.6847e-05, -2.2122e-05],
[ 2.6847e-05, -2.2122e-05],
[ 2.6847e-05, -2.2122e-05]], requires_grad=True))
=========================
('fc1.bias', Parameter containing:
tensor([7.2455e-07, 7.2455e-07, 7.2455e-07, 7.2455e-07, 7.2455e-07],
requires_grad=True))
=========================
('fc2.weight', Parameter containing:
tensor([[0.0021, 0.0021, 0.0021, 0.0021, 0.0021]], requires_grad=True))
=========================
('fc2.bias', Parameter containing:
tensor([0.0042], requires_grad=True))
=========================
The weights of the Layers:
('fc1.weight', Parameter containing:
tensor([[ 5.1669e-05, -4.2643e-05],
[ 5.1669e-05, -4.2643e-05],
[ 5.1669e-05, -4.2643e-05],
[ 5.1669e-05, -4.2643e-05],
[ 5.1669e-05, -4.2643e-05]], requires_grad=True))
=========================
('fc1.bias', Parameter containing:
tensor([1.2953e-06, 1.2953e-06, 1.2953e-06, 1.2953e-06, 1.2953e-06],
requires_grad=True))
=========================
('fc2.weight', Parameter containing:
tensor([[0.0026, 0.0026, 0.0026, 0.0026, 0.0026]], requires_grad=True))
=========================
('fc2.bias', Parameter containing:
tensor([0.0053], requires_grad=True))
所有权重的更新都相同,即出现了对称权重现象
可视化权重变化:
# ===========可视化函数===============
def plot(runner, fig_name):
plt.figure(figsize=(10, 5))
epochs = [i for i in range(0, len(runner.train_scores))]
plt.subplot(1, 2, 1)
plt.plot(epochs, runner.train_loss, color='#e4007f', label="Train loss")
plt.plot(epochs, runner.dev_loss, color='#f19ec2', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1, 2, 2)
plt.plot(epochs, runner.train_scores, color='#e4007f', label="Train accuracy")
plt.plot(epochs, runner.dev_scores, color='#f19ec2', linestyle='--', label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
plot(runner, 'fw-acc.pdf')
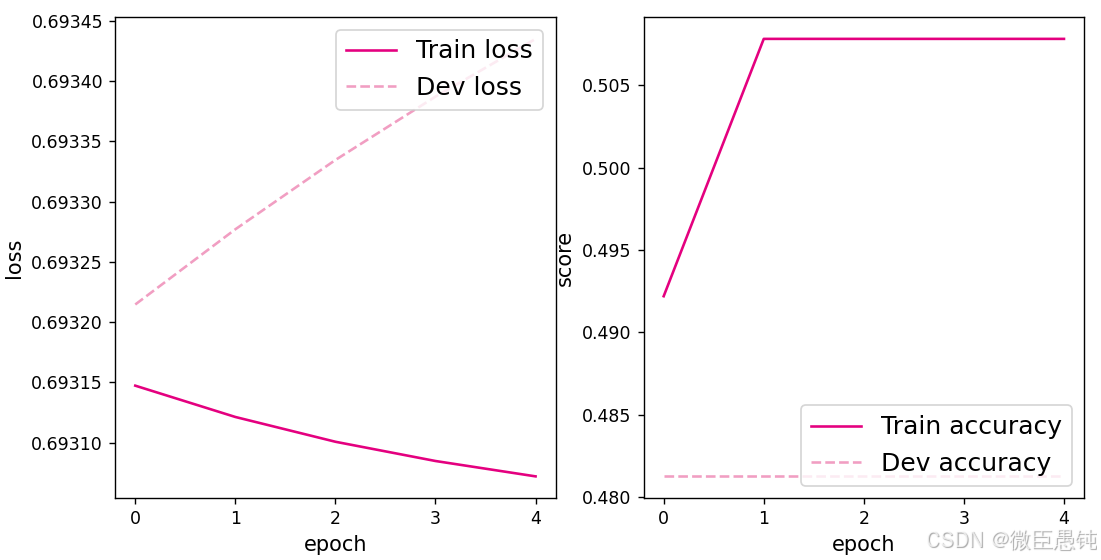
从图像可以看出,二分类score为50%左右,说明模型没有学到任何内容。训练和验证的loss几乎没有怎么下降。
优化
为了避免对称权重现象,可以使用高斯分布或均匀分布初始化神经网络的参数。
高斯分布和均匀分布采样的实现和可视化代码如下:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import torch
# 使用'torch.normal'实现高斯分布采样,其中'mean'为高斯分布的均值,'std'为高斯分布的标准差,'shape'为输出形状
gausian_weights = torch.normal(mean=0.0, std=1.0, size=[10000])
# 使用'torch.uniform'实现在[min,max)范围内的均匀分布采样,其中'shape'为输出形状
uniform_weights = torch.Tensor(10000)
uniform_weights.uniform_(-1,1)
gausian_weights=gausian_weights.numpy()
uniform_weights=uniform_weights.numpy()
print(uniform_weights)
# 绘制两种参数分布
plt.figure()
plt.subplot(1,2,1)
plt.title('Gausian Distribution')
plt.hist(gausian_weights, bins=200, density=True, color='#f19ec2')
plt.subplot(1,2,2)
plt.title('Uniform Distribution')
plt.hist(uniform_weights, bins=200, density=True, color='#e4007f')
plt.savefig('fw-gausian-uniform.pdf')
plt.show()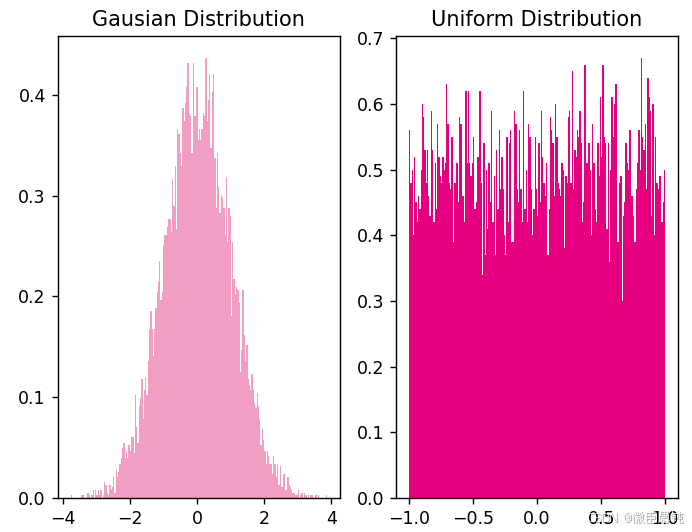
完整代码
'''
@author: lxy
@function: The Impact of Zero Weight Initialization
@date: 2024/10/31
'''
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.init import constant_, normal_, uniform_
import torch
from data import make_moons
from nndl import accuracy
from Runner2_2 import RunnerV2_2
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
class Model_MLP_L2_V4(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model_MLP_L2_V4, self).__init__()
# 定义第一个线性层,输入特征数为 input_size,输出特征数为 hidden_size
self.fc1 = nn.Linear(input_size, hidden_size)
'''
weight为权重参数属性,bias为偏置参数属性,这里使用'torch.nn.init.constant_'进行常量初始化
'''
# 初始化第一个线性层的权重和偏置为 0
constant_(self.fc1.weight, 0.0)
constant_(self.fc1.bias, 0.0)
# 定义第二个线性层,输入特征数为 hidden_size,输出特征数为 output_size
self.fc2 = nn.Linear(hidden_size, output_size)
# 初始化第二个线性层的权重和偏置为 0
constant_(self.fc2.weight, 0.0)
constant_(self.fc2.bias, 0.0)
self.act_fn = F.sigmoid
# 前向计算
def forward(self, inputs):
z1 = self.fc1(inputs)
a1 = self.act_fn(z1)
z2 = self.fc2(a1)
a2 = self.act_fn(z2)
return a2
def print_weight(runner):
print('The weights of the Layers:')
# 通过 enumerate() 可以同时获取参数的索引 i 和参数的内容 item
for i, item in enumerate(runner.model.named_parameters()):
print(item)
print('=========================')
# =============================数据集=======================
# 数据集构建
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.2)
# 划分数据集
num_train = 640 # 训练集样本数量
num_dev = 160 # 验证集样本数量
num_test = 200 # 测试集样本数量
# 根据指定数量划分数据集
X_train, y_train = X[:num_train], y[:num_train] # 训练集
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev] # 验证集
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:] # 测试集
# 调整标签的形状,将其转换为[N, 1]的格式
y_train = y_train.reshape([-1, 1])
y_dev = y_dev.reshape([-1, 1])
y_test = y_test.reshape([-1, 1])
# ================================训练模型===========================
input_size = 2
hidden_size = 5
output_size = 1
model = Model_MLP_L2_V4(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 设置损失函数
loss_fn = F.binary_cross_entropy
# 设置优化器
learning_rate = 0.2
optimizer = torch.optim.SGD(params=model.parameters(), lr=learning_rate)
# 设置评价指标
metric = accuracy
# 其他参数
epoch = 2000
saved_path = 'best_model.pdparams'
# 实例化RunnerV2_2类,并传入训练配置
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=5, log_epochs=50, save_path="best_model.pdparams",
custom_print_log=print_weight)
# ===========可视化函数===============
def plot(runner, fig_name):
plt.figure(figsize=(10, 5))
epochs = [i for i in range(0, len(runner.train_scores))]
plt.subplot(1, 2, 1)
plt.plot(epochs, runner.train_loss, color='#e4007f', label="Train loss")
plt.plot(epochs, runner.dev_loss, color='#f19ec2', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1, 2, 2)
plt.plot(epochs, runner.train_scores, color='#e4007f', label="Train accuracy")
plt.plot(epochs, runner.dev_scores, color='#f19ec2', linestyle='--', label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
plot(runner, 'fw-acc.pdf')2 梯度消失问题
由于Sigmoid型函数的饱和性,饱和区的导数更接近于0,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停衰减,甚至消失,使得整个网络很难训练,这就是所谓的梯度消失问题。减轻梯度消失问题的方法有很多种,一种简单有效的方式就是使用导数比较大的激活函数,如:ReLU。
定义一个前馈神经网络,包含4个隐藏层和1个输出层,分别使用ReLU函数和sigmod函数作为激活函数,观察梯度变化。
模型构建
class Model_MLP_L5(nn.Module):
def __init__(self, input_size, output_size, act='sigmoid', w_init=nn.init.normal_, b_init=nn.init.constant_):
super(Model_MLP_L5, self).__init__()
self.fc1 = nn.Linear(input_size, 3)
self.fc2 = nn.Linear(3, 3)
self.fc3 = nn.Linear(3, 3)
self.fc4 = nn.Linear(3, 3)
self.fc5 = nn.Linear(3, output_size)
# 定义激活函数
if act == 'sigmoid':
self.act = F.sigmoid
elif act == 'relu':
self.act = F.relu
elif act == 'lrelu':
self.act = F.leaky_relu
else:
raise ValueError("Please enter sigmoid, relu or lrelu!")
# 初始化权重和偏置
self.init_weights(w_init, b_init)
# 初始化线性层权重和偏置参数
def init_weights(self, w_init, b_init):
for m in self.children():
if isinstance(m, nn.Linear):
w_init(m.weight, mean=0.0, std=0.01) # 对权重进行初始化
b_init(m.bias, 1.0) # 对偏置进行初始化
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
outputs = self.act(outputs)
outputs = self.fc3(outputs)
outputs = self.act(outputs)
outputs = self.fc4(outputs)
outputs = self.act(outputs)
outputs = self.fc5(outputs)
outputs = F.sigmoid(outputs)
return outputs设置打印梯度的L 2范数的函数
def print_grads(runner, grad_norms):
""" 打印模型每一层的梯度并计算其L2范数。 """
print("The gradient of the Layers:")
for name, param in runner.model.named_parameters():
if param.requires_grad and param.grad is not None:
grad_norm = param.grad.data.norm(2).item() # 计算L2范数
grad_norms[name].append(grad_norm) # 记录L2范数
print(f'Layer: {name}, Gradient Norm: {grad_norm}')这里为什么要打印梯度范数?
当梯度过大时,它可能导致模型训练过程中的数值不稳定,进而影响模型的性能。
打印范数可以帮助我们了解梯度的幅度大小。范数可以衡量向量的大小,因此通过打印梯度的范数,我们可以直观地看到梯度的幅度是否过大或过小。简单说,就是范数可以反应梯度的大小,打印范数我们可以及时知道梯度的情况。
参考连接:
模型训练
分别使用sigmod函数和relu函数
# =====================使用sigmoid激活函数训练=====================
torch.manual_seed(111)
lr = 0.01
model = Model_MLP_L5(input_size=2, output_size=1, act='sigmoid')
optimizer = torch.optim.SGD(params=model.parameters(), lr=lr)
loss_fn = F.binary_cross_entropy
metric = accuracy
# 初始化L2范数记录字典
grad_norms_sigmoid = {name: [] for name, _ in model.named_parameters()}
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
print("使用sigmoid函数为激活函数时:")
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=None,
save_path="best_model.pdparams",
custom_print_log=lambda runner: print_grads(runner, grad_norms_sigmoid))
# =====================使用ReLU激活函数训练=====================
torch.manual_seed(102)
model = Model_MLP_L5(input_size=2, output_size=1, act='relu')
optimizer = torch.optim.SGD(params=model.parameters(), lr=lr)
loss_fn = F.binary_cross_entropy
# 初始化L2范数记录字典
grad_norms_relu = {name: [] for name, _ in model.named_parameters()}
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
print("使用ReLU函数为激活函数时:")
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=None,
save_path="best_model.pdparams",
custom_print_log=lambda runner: print_grads(runner, grad_norms_relu))运行结果输出:
使用sigmoid函数为激活函数时:
The gradient of the Layers:
Layer: fc1.weight, Gradient Norm: 2.4828878536498067e-11
Layer: fc1.bias, Gradient Norm: 1.8694254477757966e-11
Layer: fc2.weight, Gradient Norm: 1.2134693250231976e-08
Layer: fc2.bias, Gradient Norm: 9.58359702707412e-09
Layer: fc3.weight, Gradient Norm: 5.372268333303509e-06
Layer: fc3.bias, Gradient Norm: 4.236671884427778e-06
Layer: fc4.weight, Gradient Norm: 0.001065725926309824
Layer: fc4.bias, Gradient Norm: 0.0008412969764322042
Layer: fc5.weight, Gradient Norm: 0.27612796425819397
Layer: fc5.bias, Gradient Norm: 0.21845529973506927
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.54375
使用ReLU函数为激活函数时:
The gradient of the Layers:
Layer: fc1.weight, Gradient Norm: 1.736074395353171e-08
Layer: fc1.bias, Gradient Norm: 1.370427327174184e-08
Layer: fc2.weight, Gradient Norm: 1.4403226487047505e-06
Layer: fc2.bias, Gradient Norm: 8.300839340336097e-07
Layer: fc3.weight, Gradient Norm: 0.00011438350338721648
Layer: fc3.bias, Gradient Norm: 6.653369928244501e-05
Layer: fc4.weight, Gradient Norm: 0.009503044188022614
Layer: fc4.bias, Gradient Norm: 0.005468158517032862
Layer: fc5.weight, Gradient Norm: 0.3917791247367859
Layer: fc5.bias, Gradient Norm: 0.22893022000789642
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.54375可视化梯度范数的变化情况:
# 可视化梯度L2范数
def plot_grad_norms(grad_norms_sigmoid, grad_norms_relu):
layers = list(grad_norms_sigmoid.keys())
sigmoid_norms = [np.mean(grad_norms_sigmoid[layer]) for layer in layers]
relu_norms = [np.mean(grad_norms_relu[layer]) for layer in layers]
x = np.arange(len(layers))
plt.figure(figsize=(10, 6))
plt.plot(x, sigmoid_norms, marker='o', label='Sigmoid', color='b')
plt.plot(x, relu_norms, marker='o', label='ReLU', color='r')
plt.ylabel('Gradient L2 Norm')
plt.title('Gradient L2 Norm by different Activation Function')
plt.xticks(x, layers)
plt.legend()
# 设置 y 轴为对数坐标
plt.yscale('log')
# 设置 y 轴的范围
plt.ylim(1e-8, 1) # 设置下限为 1e-8,上限为 1
# 设置 y 轴的刻度
plt.yticks([1, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6, 1e-7, 1e-8,1e-9,1e-10,1e-11])
plt.grid()
plt.tight_layout()
plt.show()
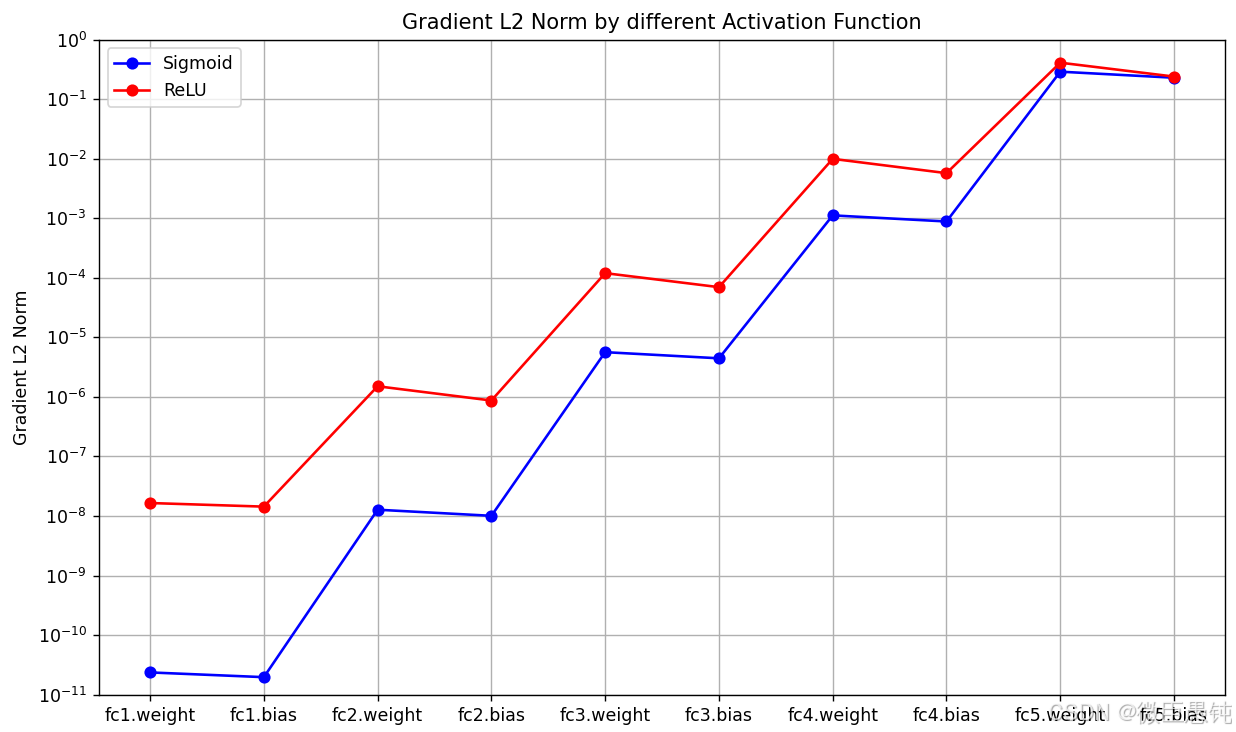
图中展示了使用不同激活函数时,网络每层梯度值的ℓ2范数情况。从结果可以看到,5层的全连接前馈神经网络使用Sigmoid型函数作为激活函数时,梯度经过每一个神经层的传递都会不断衰减,最终传递到第一个神经层时,梯度几乎完全消失。改为ReLU激活函数后,梯度消失现象得到了缓解
完整代码
'''
@author: lxy
@function: Exploration and Optimization of the Gradient Vanishing Problem
@date: 2024/10/31
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.init import constant_, normal_
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from data import make_moons
from nndl import accuracy
from Runner2_2 import RunnerV2_2
class Model_MLP_L5(nn.Module):
def __init__(self, input_size, output_size, act='sigmoid', w_init=nn.init.normal_, b_init=nn.init.constant_):
super(Model_MLP_L5, self).__init__()
self.fc1 = nn.Linear(input_size, 3)
self.fc2 = nn.Linear(3, 3)
self.fc3 = nn.Linear(3, 3)
self.fc4 = nn.Linear(3, 3)
self.fc5 = nn.Linear(3, output_size)
# 定义激活函数
if act == 'sigmoid':
self.act = F.sigmoid
elif act == 'relu':
self.act = F.relu
elif act == 'lrelu':
self.act = F.leaky_relu
else:
raise ValueError("Please enter sigmoid, relu or lrelu!")
# 初始化权重和偏置
self.init_weights(w_init, b_init)
# 初始化线性层权重和偏置参数
def init_weights(self, w_init, b_init):
for m in self.children():
if isinstance(m, nn.Linear):
w_init(m.weight, mean=0.0, std=0.01) # 对权重进行初始化
b_init(m.bias, 1.0) # 对偏置进行初始化
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
outputs = self.act(outputs)
outputs = self.fc3(outputs)
outputs = self.act(outputs)
outputs = self.fc4(outputs)
outputs = self.act(outputs)
outputs = self.fc5(outputs)
outputs = F.sigmoid(outputs)
return outputs
def print_grads(runner, grad_norms):
""" 打印模型每一层的梯度并计算其L2范数。 """
print("The gradient of the Layers:")
for name, param in runner.model.named_parameters():
if param.requires_grad and param.grad is not None:
grad_norm = param.grad.data.norm(2).item() # 计算L2范数
grad_norms[name].append(grad_norm) # 记录L2范数
print(f'Layer: {name}, Gradient Norm: {grad_norm}')
# 可视化梯度L2范数
def plot_grad_norms(grad_norms_sigmoid, grad_norms_relu):
layers = list(grad_norms_sigmoid.keys())
sigmoid_norms = [np.mean(grad_norms_sigmoid[layer]) for layer in layers]
relu_norms = [np.mean(grad_norms_relu[layer]) for layer in layers]
x = np.arange(len(layers))
plt.figure(figsize=(10, 6))
plt.plot(x, sigmoid_norms, marker='o', label='Sigmoid', color='b')
plt.plot(x, relu_norms, marker='o', label='ReLU', color='r')
plt.ylabel('Gradient L2 Norm')
plt.title('Gradient L2 Norm by different Activation Function')
plt.xticks(x, layers)
plt.legend()
# 设置 y 轴为对数坐标
plt.yscale('log')
# 设置 y 轴的范围
plt.ylim(1e-8, 1) # 设置下限为 1e-8,上限为 1
# 设置 y 轴的刻度
plt.yticks([1, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6, 1e-7, 1e-8,1e-9,1e-10,1e-11])
plt.grid()
plt.tight_layout()
plt.show()
# =============================数据集=======================
# 数据集构建
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.2)
# 划分数据集
num_train = 640 # 训练集样本数量
num_dev = 160 # 验证集样本数量
num_test = 200 # 测试集样本数量
# 根据指定数量划分数据集
X_train, y_train = X[:num_train], y[:num_train] # 训练集
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev] # 验证集
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:] # 测试集
# 调整标签的形状,将其转换为[N, 1]的格式
y_train = y_train.reshape([-1, 1])
y_dev = y_dev.reshape([-1, 1])
y_test = y_test.reshape([-1, 1])
# =====================使用sigmoid激活函数训练=====================
torch.manual_seed(111)
lr = 0.01
model = Model_MLP_L5(input_size=2, output_size=1, act='sigmoid')
optimizer = torch.optim.SGD(params=model.parameters(), lr=lr)
loss_fn = F.binary_cross_entropy
metric = accuracy
# 初始化L2范数记录字典
grad_norms_sigmoid = {name: [] for name, _ in model.named_parameters()}
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
print("使用sigmoid函数为激活函数时:")
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=None,
save_path="best_model.pdparams",
custom_print_log=lambda runner: print_grads(runner, grad_norms_sigmoid))
# =====================使用ReLU激活函数训练=====================
torch.manual_seed(102)
model = Model_MLP_L5(input_size=2, output_size=1, act='relu')
optimizer = torch.optim.SGD(params=model.parameters(), lr=lr)
loss_fn = F.binary_cross_entropy
# 初始化L2范数记录字典
grad_norms_relu = {name: [] for name, _ in model.named_parameters()}
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
print("使用ReLU函数为激活函数时:")
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=None,
save_path="best_model.pdparams",
custom_print_log=lambda runner: print_grads(runner, grad_norms_relu))
# 绘制梯度范数
plot_grad_norms(grad_norms_sigmoid, grad_norms_relu)
3 死亡Relu问题
ReLU激活函数可以一定程度上改善梯度消失问题,但是ReLU函数在某些情况下容易出现死亡 ReLU问题,使得网络难以训练。
这是由于激活前神经元通常也包含偏置项,如果偏置项是一个过小的负数当x<0时,ReLU函数的输出恒为0。在训练过程中,如果参数在一次不恰当的更新后,某个ReLU神经元在所有训练数据上都不能被激活(即输出为0),那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远都不能被激活。
模型构建
当神经层的偏置被初始化为一个相对于权重较大的负值时,可以想像,输入经过神经层的处理,最终的输出会为负值,从而导致死亡ReLU现象。这里我们初始化偏置为-8.0
class Model_MLP_L5(nn.Module):
def __init__(self, input_size, output_size, act='sigmoid', w_init=nn.init.normal_, b_init=-8.0):
super(Model_MLP_L5, self).__init__()
self.fc1 = nn.Linear(input_size, 3)
self.fc2 = nn.Linear(3, 3)
self.fc3 = nn.Linear(3, 3)
self.fc4 = nn.Linear(3, 3)
self.fc5 = nn.Linear(3, output_size)
# 定义激活函数
if act == 'sigmoid':
self.act = F.sigmoid
elif act == 'relu':
self.act = F.relu
elif act == 'lrelu':
self.act = F.leaky_relu
else:
raise ValueError("Please enter sigmoid, relu or lrelu!")
# 初始化权重和偏置
self.init_weights(w_init, b_init)
# 初始化线性层权重和偏置参数
def init_weights(self, w_init, b_init):
for m in self.children():
if isinstance(m, nn.Linear):
w_init(m.weight, mean=0.0, std=0.01) # 对权重进行初始化
constant_(m.bias, b_init)
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
outputs = self.act(outputs)
outputs = self.fc3(outputs)
outputs = self.act(outputs)
outputs = self.fc4(outputs)
outputs = self.act(outputs)
outputs = self.fc5(outputs)
outputs = F.sigmoid(outputs)
return outputs 设置打印梯度范数的函数:
def print_grads(runner, grad_norms):
""" 打印模型每一层的梯度并计算其L2范数。 """
print("The gradient of the Layers:")
for name, param in runner.model.named_parameters():
if param.requires_grad and param.grad is not None:
grad_norm = param.grad.data.norm(2).item() # 计算L2范数
grad_norms[name].append(grad_norm) # 记录L2范数
print(f'Layer: {name}, Gradient Norm: {grad_norm}')模型训练
使用relu函数-观察梯度变化
# 定义网络,并使用较大的负值来初始化偏置
model = Model_MLP_L5(input_size=2, output_size=1, act='relu')
#model = Model_MLP_L5(input_size=2, output_size=1, act='lrelu')
torch.manual_seed(111)
lr = 0.01
optimizer = torch.optim.SGD(params=model.parameters(), lr=lr)
loss_fn = F.binary_cross_entropy
metric = accuracy
# 初始化L2范数记录字典
grad_norms = {name: [] for name, _ in model.named_parameters()}
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
# 启动训练
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=0,
save_path="best_model.pdparams",
custom_print_log=lambda runner: print_grads(runner, grad_norms))运行结果:
The gradient of the Layers:
Layer: fc1.weight, Gradient Norm: 0.0
Layer: fc1.bias, Gradient Norm: 0.0
Layer: fc2.weight, Gradient Norm: 0.0
Layer: fc2.bias, Gradient Norm: 0.0
Layer: fc3.weight, Gradient Norm: 0.0
Layer: fc3.bias, Gradient Norm: 0.0
Layer: fc4.weight, Gradient Norm: 0.0
Layer: fc4.bias, Gradient Norm: 0.0
Layer: fc5.weight, Gradient Norm: 0.0
Layer: fc5.bias, Gradient Norm: 0.4887271523475647
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.50000可以看出梯度反向传播时以及变为0了 ,出现了死亡relu问题
可视化梯度变化:
# 可视化梯度L2范数
def plot_grad_norms(grad_norms):
layers = list(grad_norms.keys())
norms = [np.mean(grad_norms[layer]) for layer in layers]
x = np.arange(len(layers)) # x轴为层数
plt.figure(figsize=(10, 6))
plt.plot(x, norms, marker='o', label='ReLU', color='r')
plt.ylabel('Gradient L2 Norm')
plt.title('Gradient L2 Norm --Relu')
plt.xticks(x, layers)
plt.legend()
# 设置 y 轴为对数坐标
plt.yscale('log')
# 设置 y 轴的范围
plt.ylim(1e-8, 1) # 设置下限为 1e-8,上限为 1
# 设置 y 轴的刻度
plt.yticks([1, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6, 1e-7, 1e-8, 1e-9, 1e-12, 1e-17]
)
plt.grid()
plt.tight_layout()
plt.show()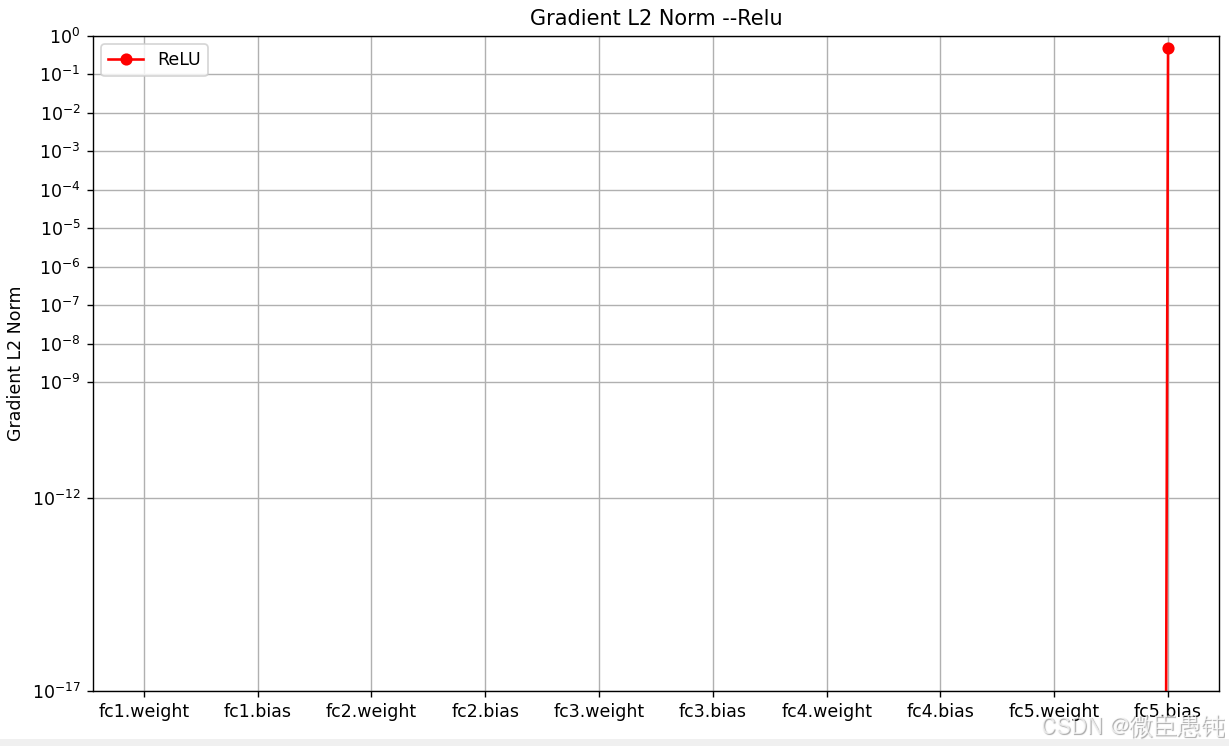
从输出结果以及可视化的图像可以发现,使用 ReLU 作为激活函数,当满足条件时,会发生死亡ReLU问题,网络训练过程中 ReLU 神经元的梯度始终为0,参数无法更新。
优化
针对死亡ReLU问题,一种简单有效的优化方式就是将激活函数更换为Leaky ReLU、ELU等ReLU 的变种。接下来,观察将激活函数更换为 Leaky ReLU时的梯度情况。
model = Model_MLP_L5(input_size=2, output_size=1, act='lrelu')The gradient of the Layers:
Layer: fc1.weight, Gradient Norm: 1.6563501643453269e-16
Layer: fc1.bias, Gradient Norm: 1.6535552203171837e-16
Layer: fc2.weight, Gradient Norm: 1.4167183051694288e-13
Layer: fc2.bias, Gradient Norm: 1.0233488318897588e-12
Layer: fc3.weight, Gradient Norm: 6.822118980842617e-10
Layer: fc3.bias, Gradient Norm: 4.9233230825507235e-09
Layer: fc4.weight, Gradient Norm: 6.337210834317375e-06
Layer: fc4.bias, Gradient Norm: 4.57389687653631e-05
Layer: fc5.weight, Gradient Norm: 0.07076060771942139
Layer: fc5.bias, Gradient Norm: 0.510601818561554
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.55625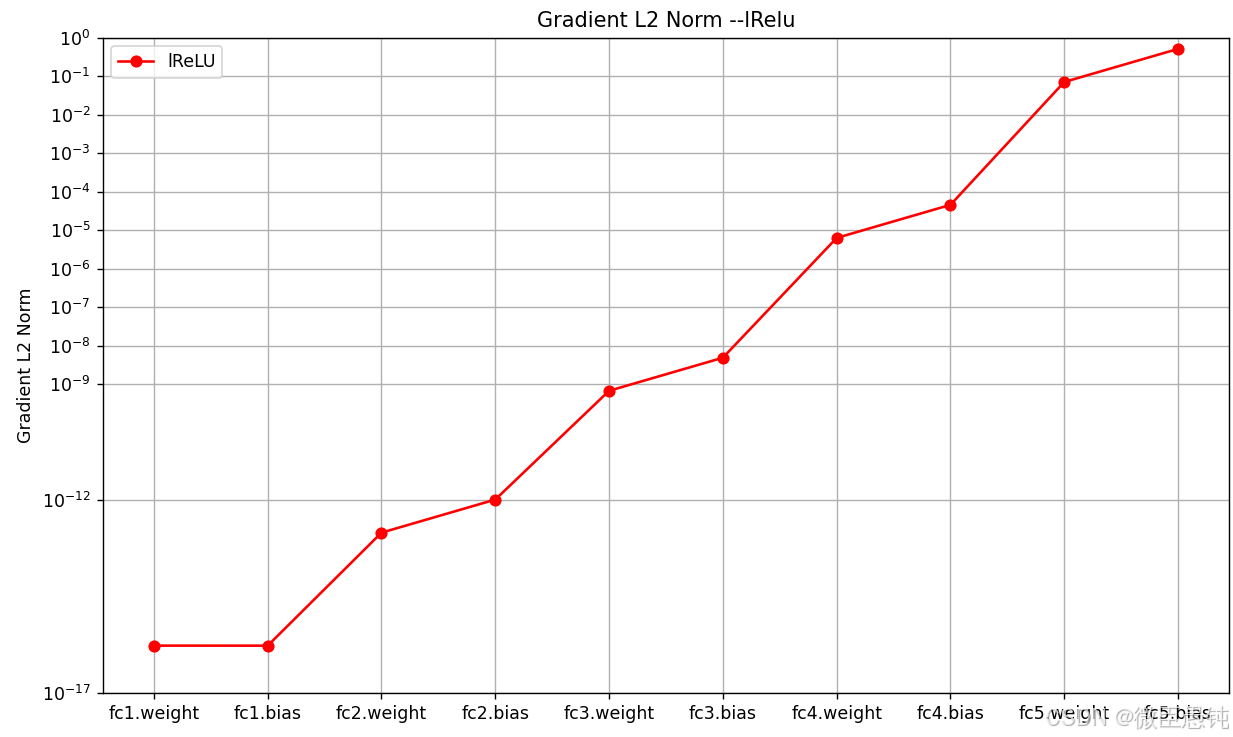
完整代码
'''
@author: lxy
@function: Exploration and Optimization of the Dead ReLU Problem
@date: 2024/10/31
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.init import constant_, normal_
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from data import make_moons
from nndl import accuracy
from Runner2_2 import RunnerV2_2
# 定义模型
class Model_MLP_L5(nn.Module):
def __init__(self, input_size, output_size, act='sigmoid', w_init=nn.init.normal_, b_init=-8.0):
super(Model_MLP_L5, self).__init__()
self.fc1 = nn.Linear(input_size, 3)
self.fc2 = nn.Linear(3, 3)
self.fc3 = nn.Linear(3, 3)
self.fc4 = nn.Linear(3, 3)
self.fc5 = nn.Linear(3, output_size)
# 定义激活函数
if act == 'sigmoid':
self.act = F.sigmoid
elif act == 'relu':
self.act = F.relu
elif act == 'lrelu':
self.act = F.leaky_relu
else:
raise ValueError("Please enter sigmoid, relu or lrelu!")
# 初始化权重和偏置
self.init_weights(w_init, b_init)
# 初始化线性层权重和偏置参数
def init_weights(self, w_init, b_init):
for m in self.children():
if isinstance(m, nn.Linear):
w_init(m.weight, mean=0.0, std=0.01) # 对权重进行初始化
constant_(m.bias, b_init)
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
outputs = self.act(outputs)
outputs = self.fc3(outputs)
outputs = self.act(outputs)
outputs = self.fc4(outputs)
outputs = self.act(outputs)
outputs = self.fc5(outputs)
outputs = F.sigmoid(outputs)
return outputs
def print_grads(runner, grad_norms):
""" 打印模型每一层的梯度并计算其L2范数。 """
print("The gradient of the Layers:")
for name, param in runner.model.named_parameters():
if param.requires_grad and param.grad is not None:
grad_norm = param.grad.data.norm(2).item() # 计算L2范数
grad_norms[name].append(grad_norm) # 记录L2范数
print(f'Layer: {name}, Gradient Norm: {grad_norm}')
# 可视化梯度L2范数
def plot_grad_norms(grad_norms):
layers = list(grad_norms.keys())
norms = [np.mean(grad_norms[layer]) for layer in layers]
x = np.arange(len(layers)) # x轴为层数
plt.figure(figsize=(10, 6))
plt.plot(x, norms, marker='o', label='ReLU', color='r')
plt.ylabel('Gradient L2 Norm')
plt.title('Gradient L2 Norm --Relu')
plt.xticks(x, layers)
plt.legend()
# 设置 y 轴为对数坐标
plt.yscale('log')
# 设置 y 轴的范围
plt.ylim(1e-8, 1) # 设置下限为 1e-8,上限为 1
# 设置 y 轴的刻度
plt.yticks([1, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6, 1e-7, 1e-8, 1e-9, 1e-12, 1e-17]
)
plt.grid()
plt.tight_layout()
plt.show()
# =============================数据集=======================
# 数据集构建
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.2)
# 划分数据集
num_train = 640 # 训练集样本数量
num_dev = 160 # 验证集样本数量
num_test = 200 # 测试集样本数量
# 根据指定数量划分数据集
X_train, y_train = X[:num_train], y[:num_train] # 训练集
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev] # 验证集
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:] # 测试集
# 调整标签的形状,将其转换为[N, 1]的格式
y_train = y_train.reshape([-1, 1])
y_dev = y_dev.reshape([-1, 1])
y_test = y_test.reshape([-1, 1])
# ===============================模型训练=================
model = Model_MLP_L5(input_size=2, output_size=1, act='relu')
#model = Model_MLP_L5(input_size=2, output_size=1, act='lrelu')
torch.manual_seed(111)
lr = 0.01
optimizer = torch.optim.SGD(params=model.parameters(), lr=lr)
loss_fn = F.binary_cross_entropy
metric = accuracy
# 初始化L2范数记录字典
grad_norms = {name: [] for name, _ in model.named_parameters()}
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
# 启动训练
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=0,
save_path="best_model.pdparams",
custom_print_log=lambda runner: print_grads(runner, grad_norms))
# 绘制梯度范数
plot_grad_norms(grad_norms)参考链接:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【实验八】前馈神经网络(4)优化问题

发表评论 取消回复