1、准备数据集并查看数据集长度
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练集的长度为:{}".format(train_data_size))
print("测试集的长度为:{}".format(test_data_size))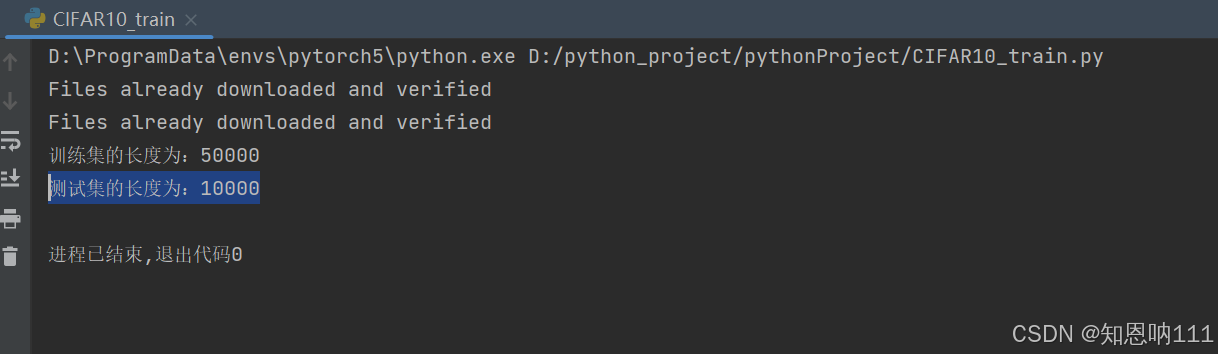
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)batch_size=64:一次读取64张图片
3、搭建神经网络
卷积是提取特征:通过卷积核提取特征(卷积核的个数=out_chennl数;j卷积核的大小随机设置)
池化是压缩特征:降低特征的数据量/剔除冗余,取池化核对应格子中最明显的一个格子(比如通过池化可以将4k画质变为720P画质)
最大池化不改变chennl数,卷积会改变chennl数
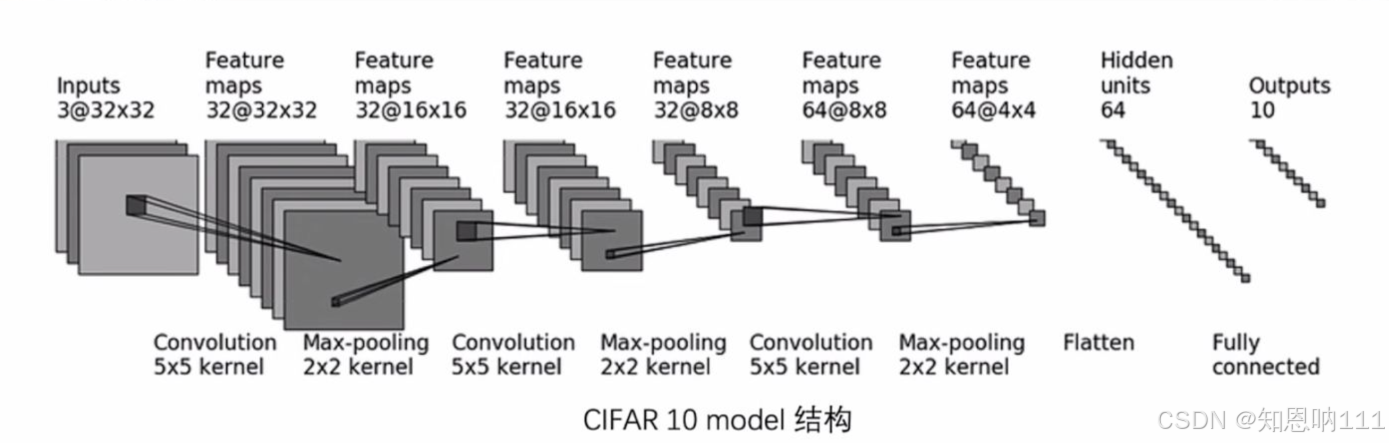
输入层的图片:3通道,像素个数/大小:32*32
- 进行第一次卷积(卷积核为5):输入通道为3,输出通道为32,像素个数/大小:32*32
- 进行最大池化(池化核为2):通道不变:32,像素个数/大小:16*16
- 进行第二次卷积(卷积核为5):输入通道为32,输出通道为32,像素个数/大小:16*16
- 进行最大池化(池化核为2):通道不变:32,像素个数/大小:8*8
- 进行第三次卷积(卷积核为5):输入通道为32,输出通道为64,像素个数/大小:8*8
- 进行最大池化(池化核为2):通道不变:64,像素个数/大小:4*4
- 进行展平(通俗理解就是将矩阵形式的像素点变为向量形式的像素点)
一共有64*4*4个像素点
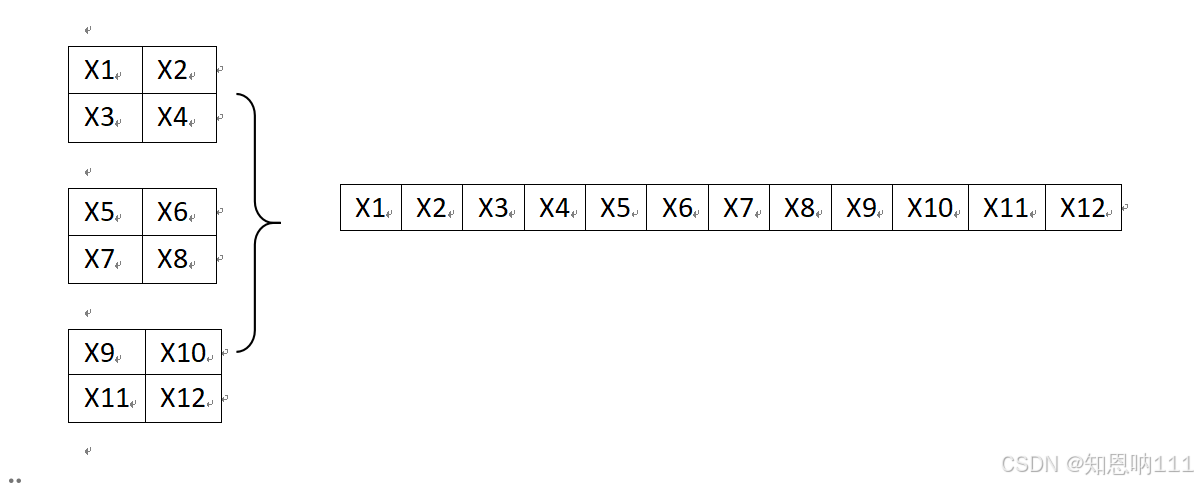
8.进行一次全连接:输入为1024压缩为64
9.进行第二次全连接:输入为64压缩为10
复杂版

简化版
利用了Sequential让模型更简化了
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential( ###
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x将该模型单独放到一个py文件中
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential( ###
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
if __name__ == '__main__':
tudui = Tudui()
## 验证网络的正确性
input = torch.ones([64,3,32,32])
output = tudui(input)
## 看输出的尺寸是不是自己想要的
print(output.shape)
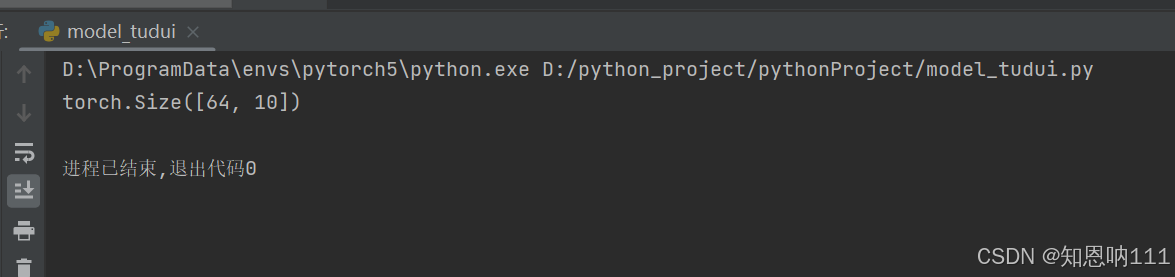
torch.ones是什意思?可查看下面的文章
from model_tudui import *:指调用自己创建的model_tudui.py文件中的模型
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from model_tudui import *
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
## 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
## 数据集长度:训练集的长度为:50000;测试集的长度为:10000
## 字符串格式化“XXX{}”.format(变量)
print("训练集的长度为:{}".format(train_data_size))
print("测试集的长度为:{}".format(test_data_size))
##利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
## 搭建神经网络
tudiu = Tudui()
# 损失函数:用的交叉熵
loss_fn = nn.CrossEntropyLoss()
# 优化器
# optimizer = torch.optim.SGD(tudiu.parameters(), lr=0.01)
##或者下面
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudiu.parameters(), learning_rate)
## 设置训练模型的一些参数
#记录训练的次数
total_train_step = 0
## 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
for i in range(epoch):
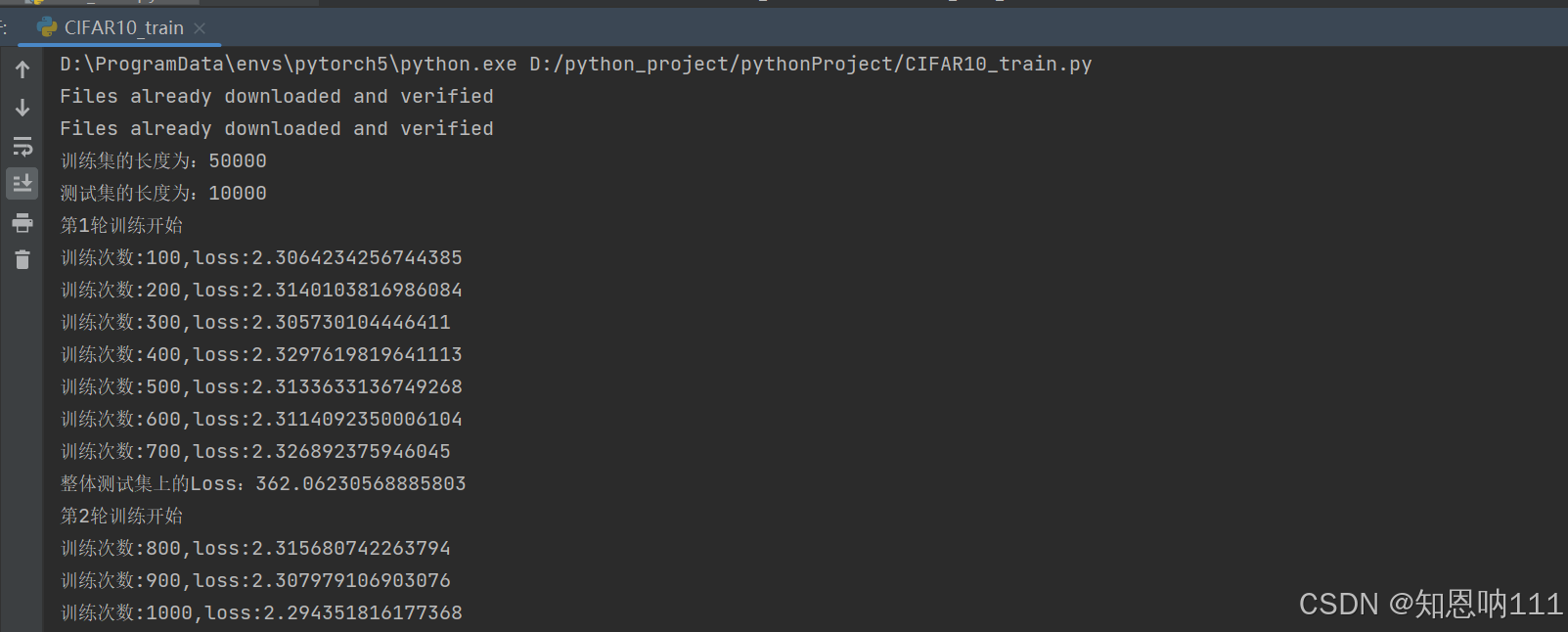
print("第{}轮训练开始".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudiu(imgs)
loss = loss_fn(outputs, targets)###output是什么
##优化器调优
optimizer.zero_grad()## 将模型参数的梯度归零
loss.backward() ##反向传播,计算当前梯度
optimizer.step()##更新参数值
total_train_step = total_train_step +1
if total_train_step % 100 ==0:
print("训练次数:{},loss:{}".format(total_train_step, loss))## loss可以写为loss.item()##item会把tensor数据值转化为真实数据
###怎么知道模型是不是训练好了,要求测试集的准确率,并对模型进行调优
## 测试开始
total_test_loss = 0
with torch.no_grad():###是一个用于禁用梯度的上下文管理器:不会拿测试集调整模型
for data in test_dataloader:
imgs, targets = data
outputs = tudiu(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
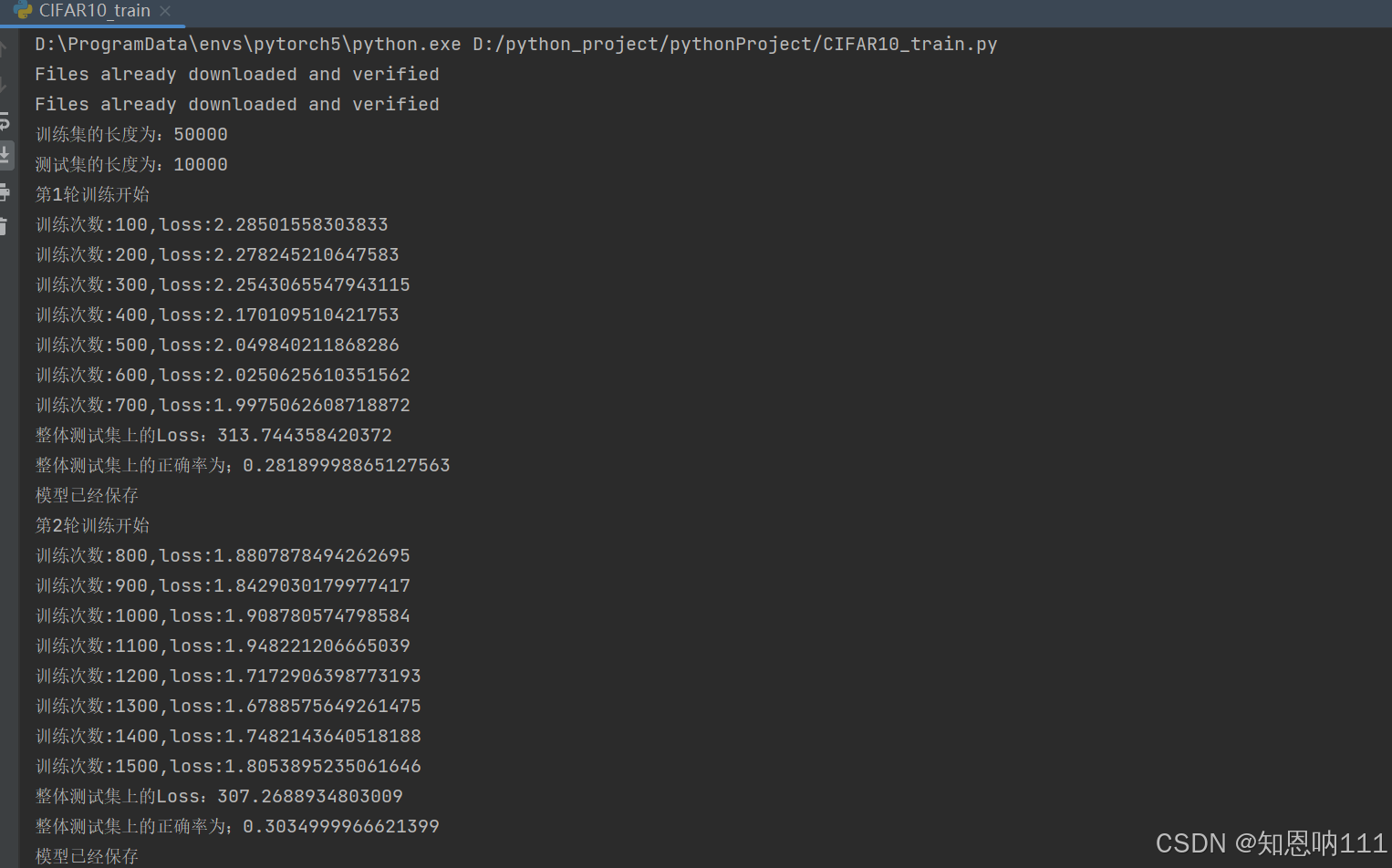
print("整体测试集上的Loss:{}".format(total_test_loss))
输出为:
改进代码将上面的结果在tensorBoder中展示出来:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model_tudui import *
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
## 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
## 数据集长度:训练集的长度为:50000;测试集的长度为:10000
## 字符串格式化“XXX{}”.format(变量)
print("训练集的长度为:{}".format(train_data_size))
print("测试集的长度为:{}".format(test_data_size))
##利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
## 搭建神经网络
tudiu = Tudui()
# 损失函数:用的交叉熵
loss_fn = nn.CrossEntropyLoss()
# 优化器
# optimizer = torch.optim.SGD(tudiu.parameters(), lr=0.01)
##或者下面
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudiu.parameters(), learning_rate)
## 设置训练模型的一些参数
#记录训练的次数
total_train_step = 0
## 记录测试的次数
total_test_step = 0
# 训练的轮数
writer = SummaryWriter("logs_train")
epoch = 10
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudiu(imgs)
loss = loss_fn(outputs, targets)###output是什么
##优化器调优
optimizer.zero_grad()## 将模型参数的梯度归零
loss.backward() ##反向传播,计算当前梯度
optimizer.step()##更新参数值
total_train_step = total_train_step +1
if total_train_step % 100 ==0:
print("训练次数:{},loss:{}".format(total_train_step, loss))## loss可以写为loss.item()##item会把tensor数据值转化为真实数据
writer.add_scalar("train_loss", loss.item(), total_train_step)
###怎么知道模型是不是训练好了,要求测试集的准确率,并对模型进行调优
## 测试开始
total_test_loss = 0
with torch.no_grad():###是一个用于禁用梯度的上下文管理器:不会拿测试集调整模型
for data in test_dataloader:
imgs, targets = data
outputs = tudiu(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss", loss.item(), total_test_step)
total_test_step = total_test_step + 1
writer.close()
在终端输入:
conda activate pytorch5
tensorboard --logdir="D:\python_project\pythonProject\logs_train" --port=6008
在浏览器打开网址:
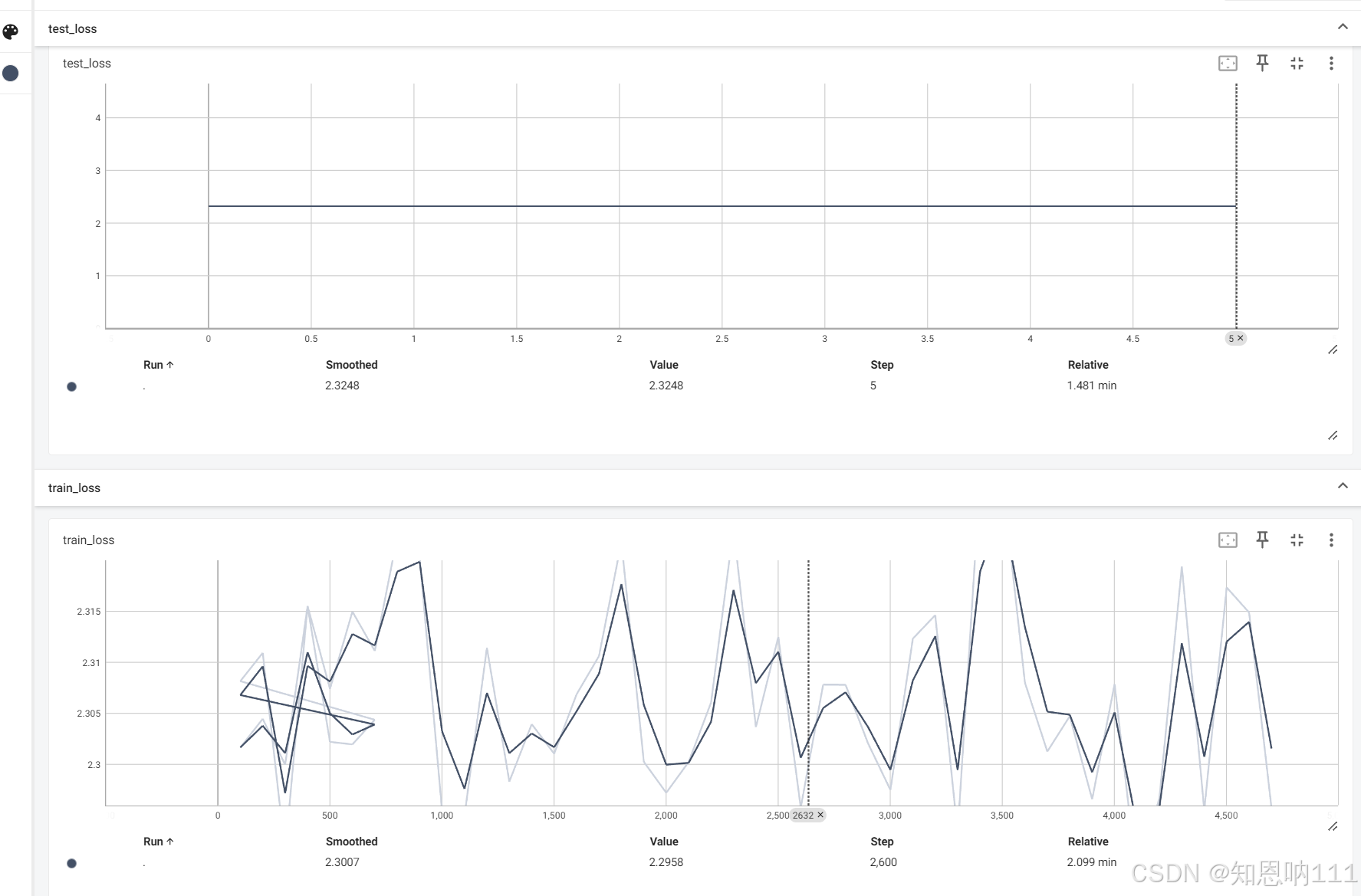
进一步优化:可以让模型 保存,并且显示测试集的正确率
###保存每一轮训练结果
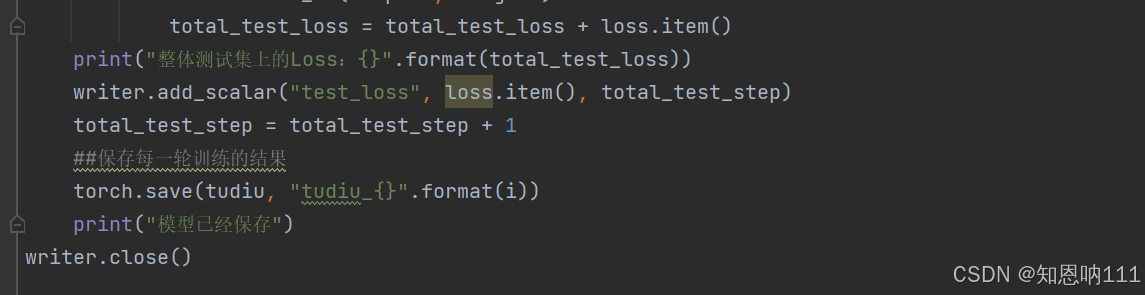
torch.save(tudiu, "tudiu_{}".format(i))
print("模型已经保存")import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model_tudui import *
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
## 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="./data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
## 数据集长度:训练集的长度为:50000;测试集的长度为:10000
## 字符串格式化“XXX{}”.format(变量)
print("训练集的长度为:{}".format(train_data_size))
print("测试集的长度为:{}".format(test_data_size))
##利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
## 搭建神经网络
tudiu = Tudui()
# 损失函数:用的交叉熵
loss_fn = nn.CrossEntropyLoss()
# 优化器
# optimizer = torch.optim.SGD(tudiu.parameters(), lr=0.01)
##或者下面
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudiu.parameters(), learning_rate)
## 设置训练模型的一些参数
#记录训练的次数
total_train_step = 0
## 记录测试的次数
total_test_step = 0
# 训练的轮数
writer = SummaryWriter("logs_train")
epoch = 10
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudiu(imgs)
loss = loss_fn(outputs, targets)###output是什么
##优化器调优
optimizer.zero_grad()## 将模型参数的梯度归零
loss.backward() ##反向传播,计算当前梯度
optimizer.step()##更新参数值
total_train_step = total_train_step +1
if total_train_step % 100 ==0:
print("训练次数:{},loss:{}".format(total_train_step, loss))## loss可以写为loss.item()##item会把tensor数据值转化为真实数据
writer.add_scalar("train_loss", loss.item(), total_train_step)
###怎么知道模型是不是训练好了,要求测试集的准确率,并对模型进行调优
## 测试开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():###是一个用于禁用梯度的上下文管理器:不会拿测试集调整模型
for data in test_dataloader:
imgs, targets = data
outputs = tudiu(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率为;{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", loss.item(), total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size,total_test_step )
total_test_step = total_test_step + 1
##保存每一轮训练的结果
torch.save(tudiu, "tudiu_{}".format(i))
print("模型已经保存")
writer.close()
####随便找一张图来尝试
测试代码:
import torchvision
from PIL import Image
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
image_path = "imgs/dog.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
###由于改图片的大小为size=1120x856;通道为mode=RGBA(png格式为4个通道) ;而建立的tudiu模型要求输入的图片大小为32*32,且通道转化为三通道
## Resize:输入什么数据类型就输出什么数据类型
##torchvision.transforms.Resize((32, 32))->获得了一个PIL的images
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)###图片变成了想要的
### 导入网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential( ###
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
model = torch.load("tudiu_9")
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():##简化操作,不需要再训练模型只需要测试模型
output = model(image)
print(output)
output1 = output.argmax(1)
print(output1)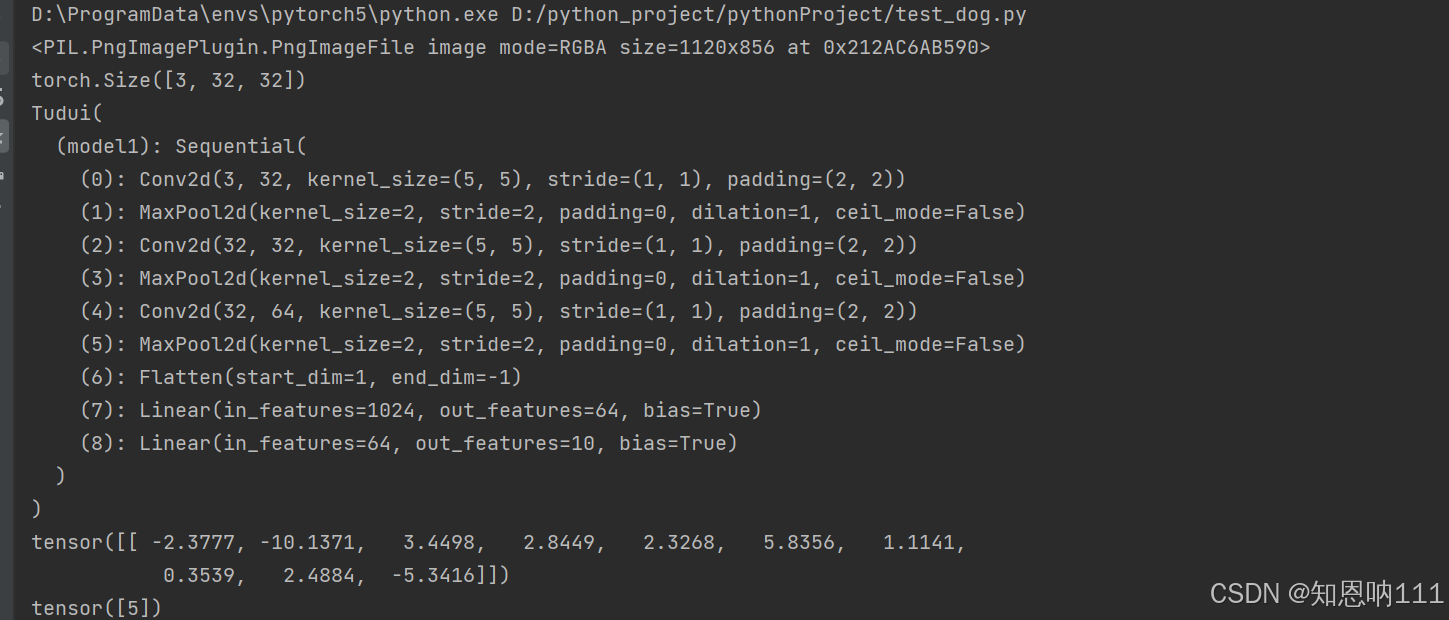
注明:该模型相对简单没有用到非线性变化
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » b站小土堆PyTorch视频学习笔记(CIFAR10数据集分类实例)

发表评论 取消回复