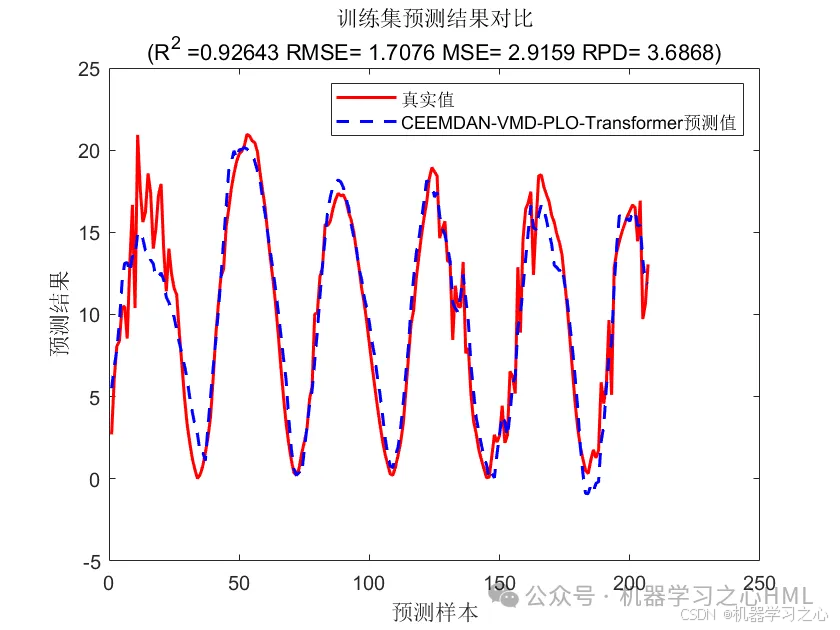
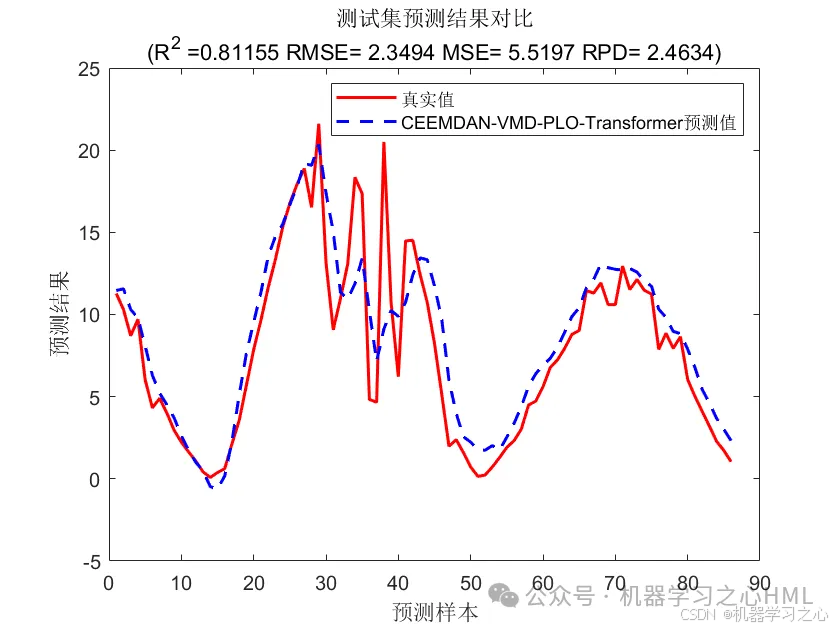
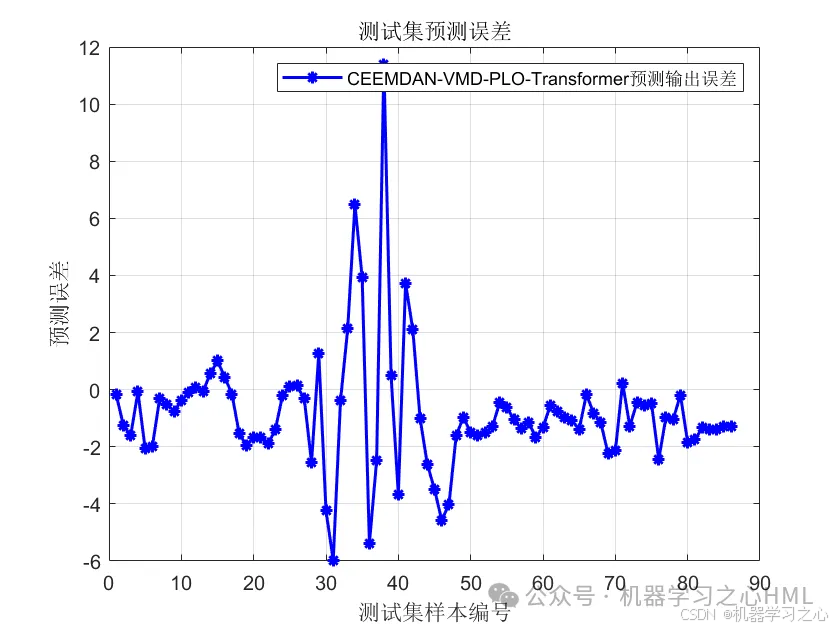
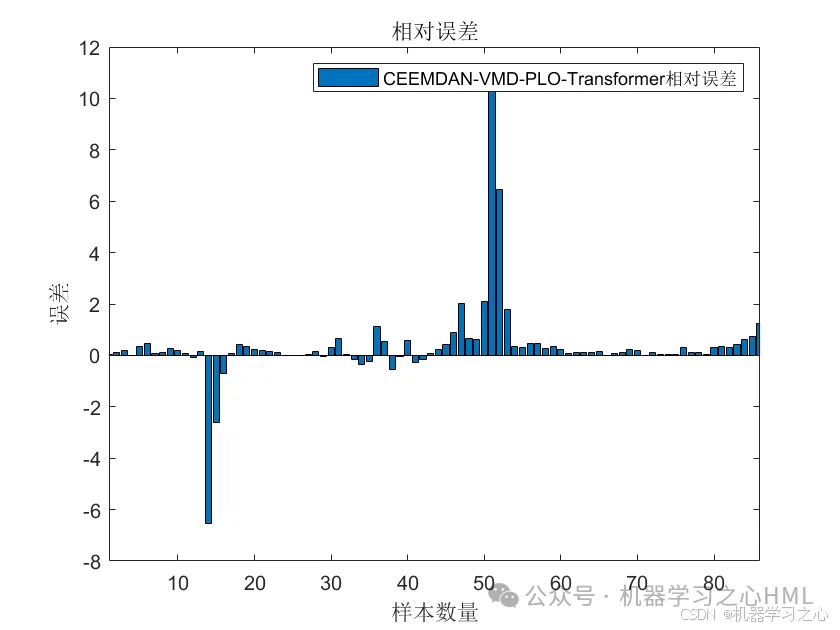
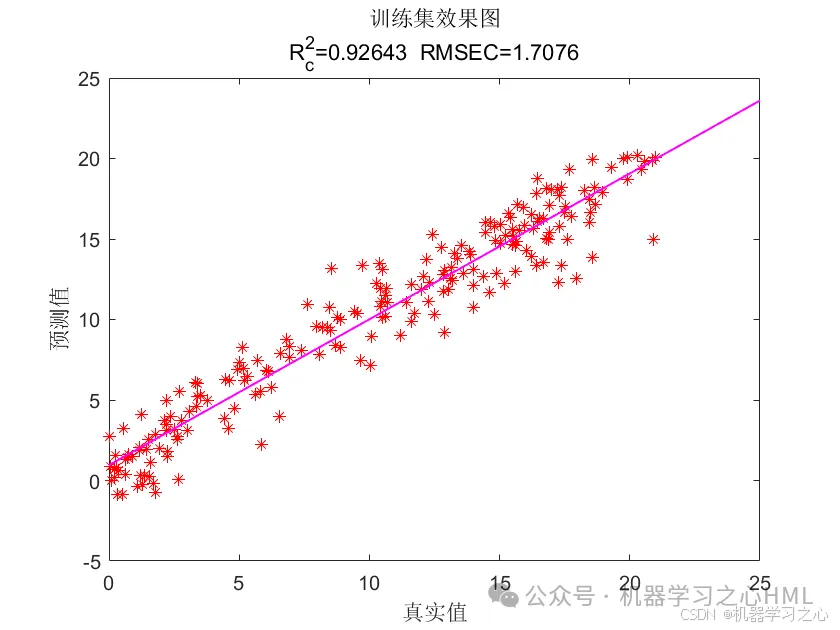
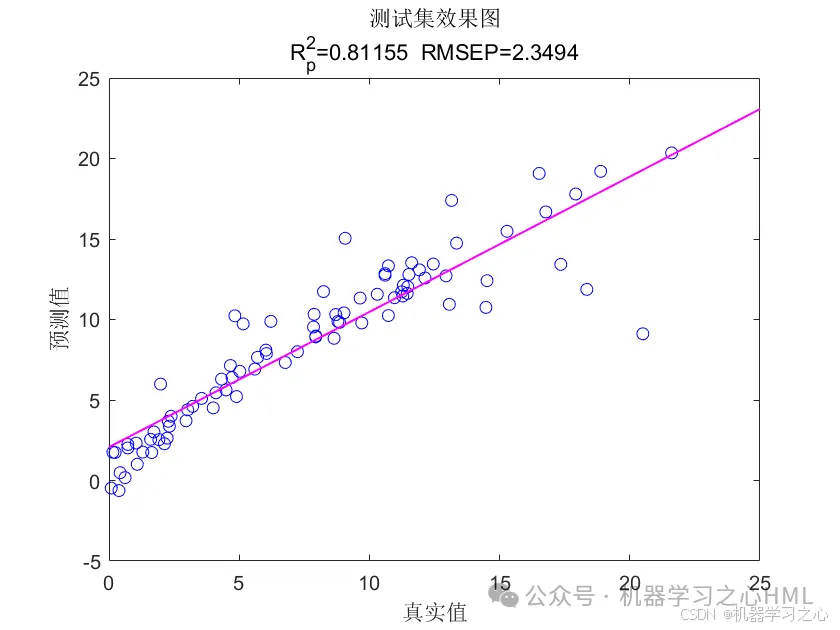
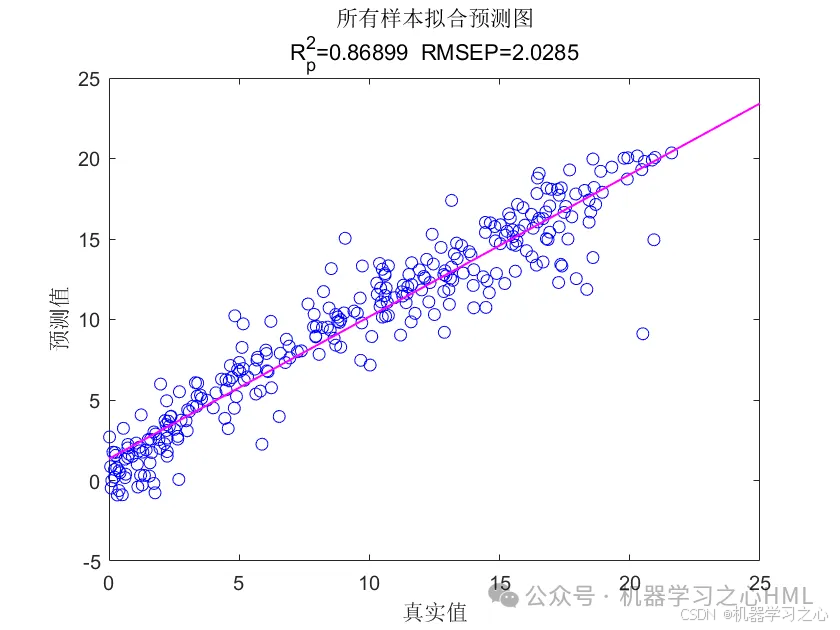
效果一览

基本介绍
1.Matlab实现CEEMDAN-Kmeans-VMD-PLO-Transformer融合K均值聚类的数据双重分解+极光优化+Transformer多元时间序列预测(完整源码和数据)
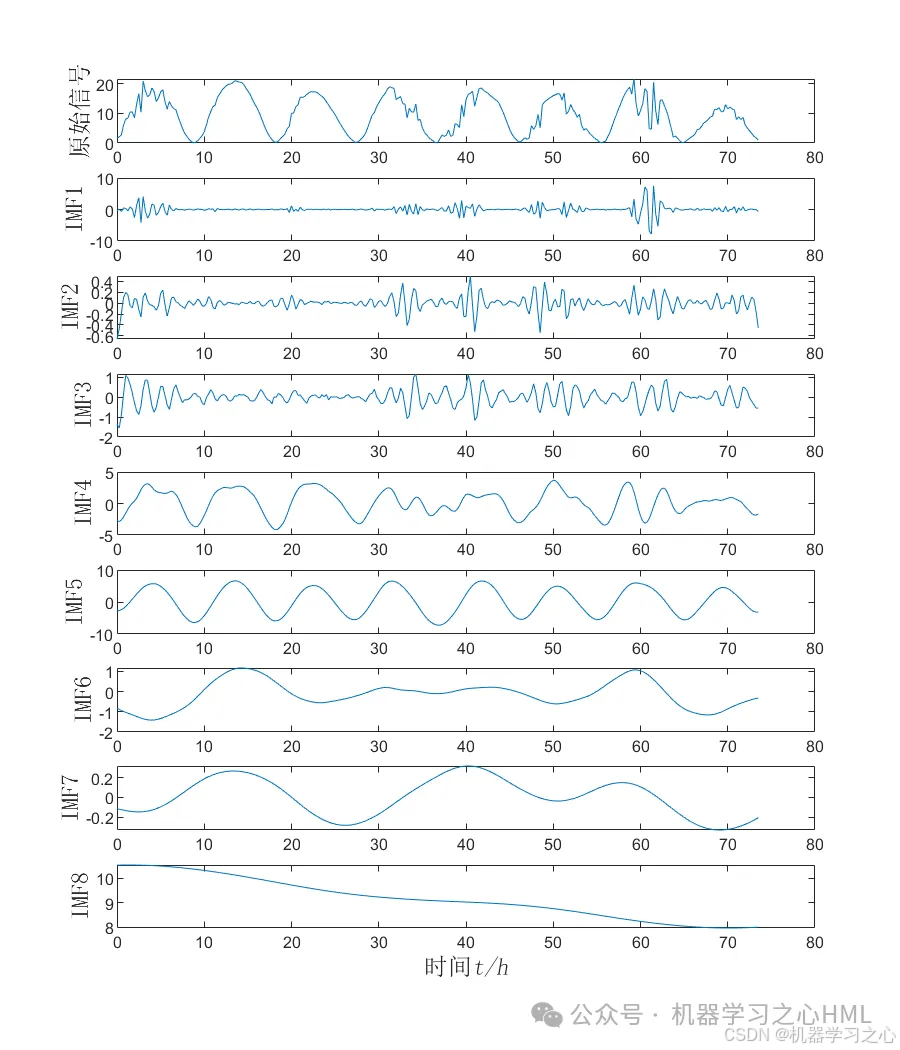
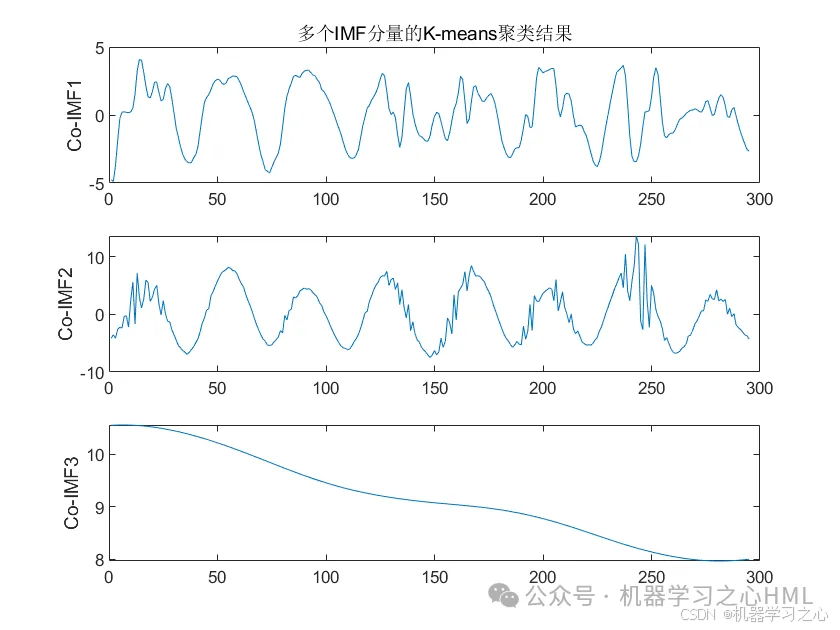
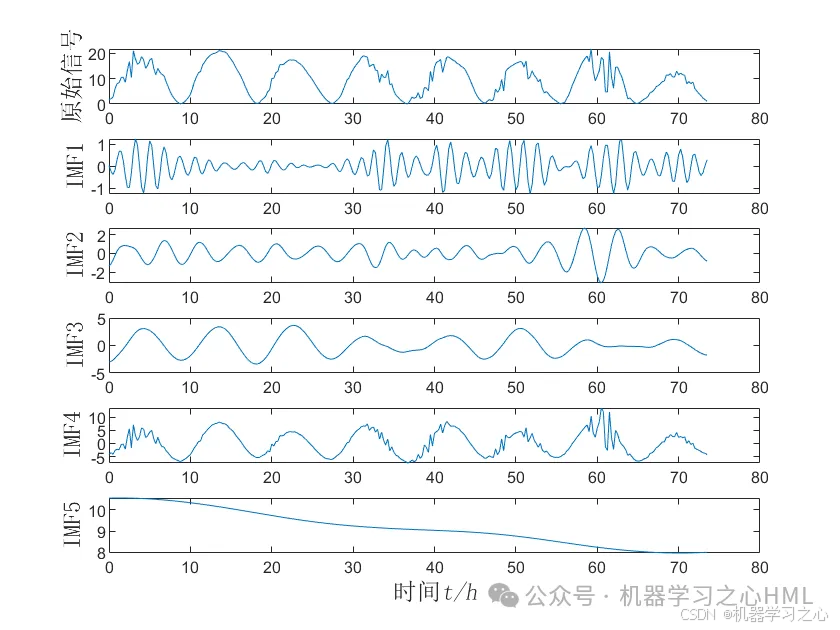
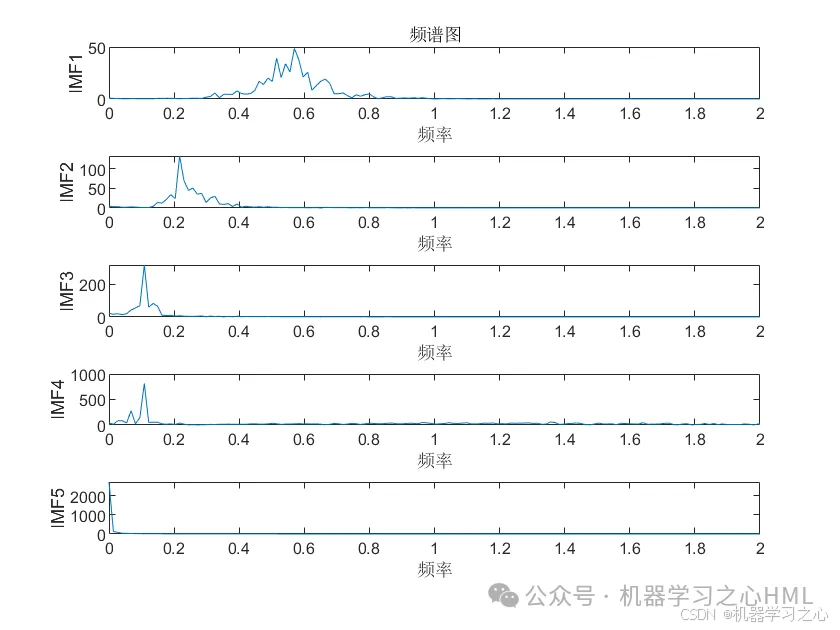
2.CEEMDAN分解,计算样本熵,根据样本熵进行kmeans聚类,调用VMD对高频分量二次分解, VMD分解的高频分量与前分量作为PLO-Transformer模型的目标输出分别预测后相加。
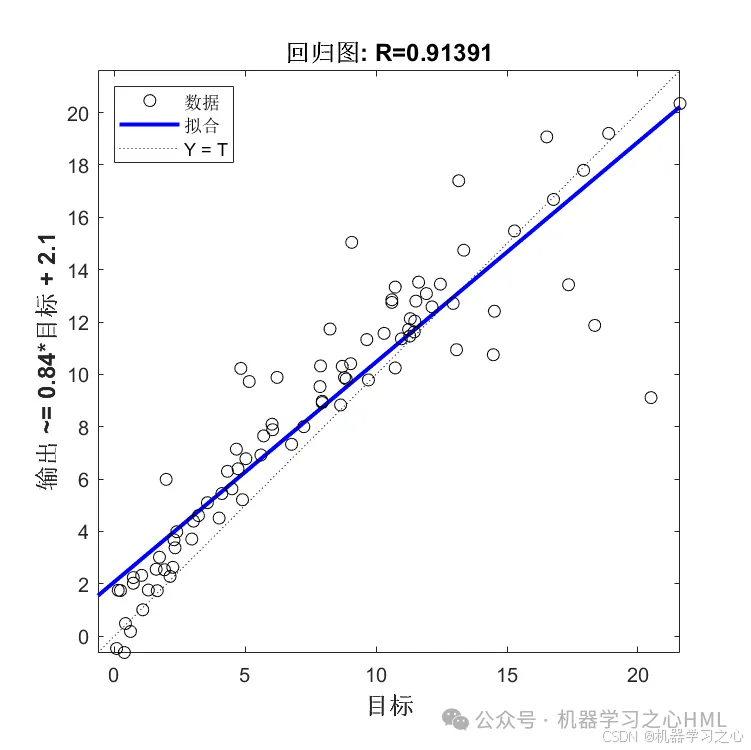
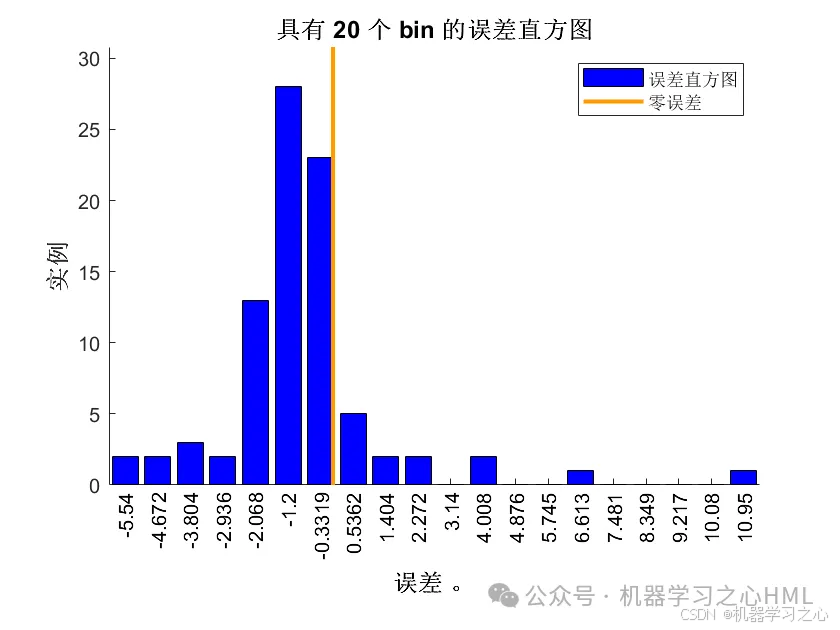
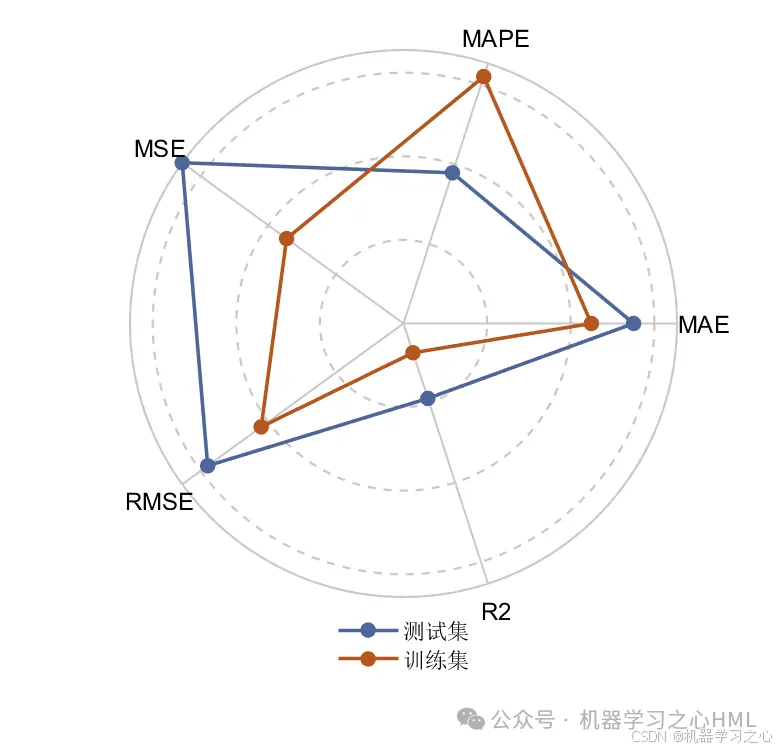
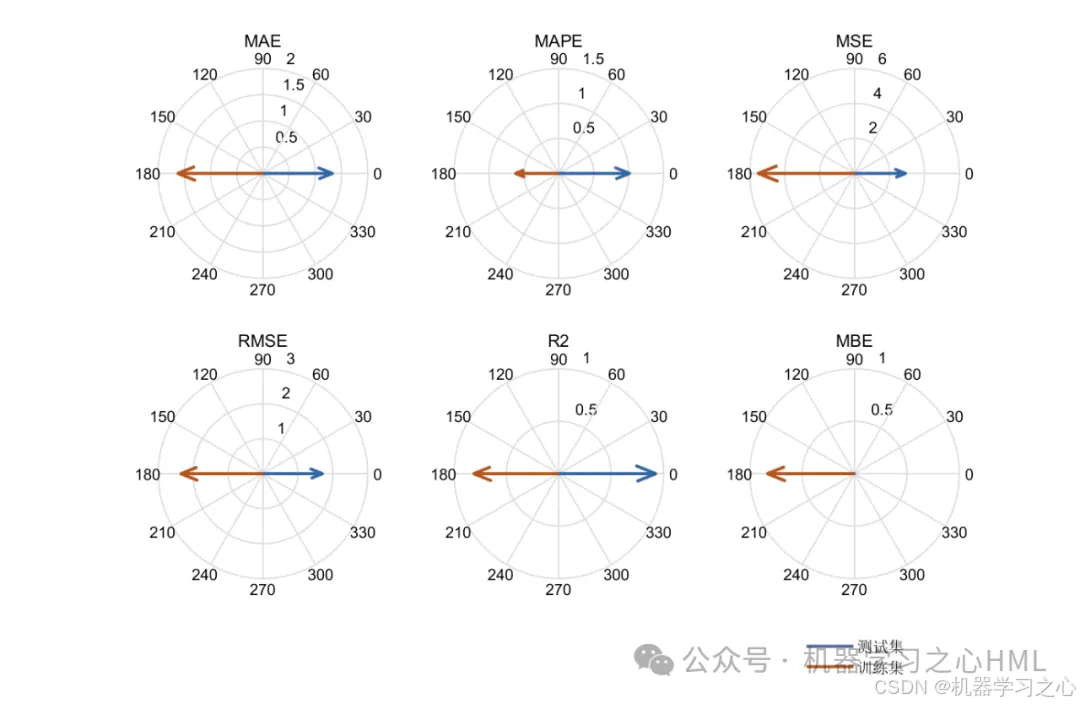
3.多变量单输出,考虑历史特征的影响!评价指标包括R2、MAE、RMSE、MAPE等。
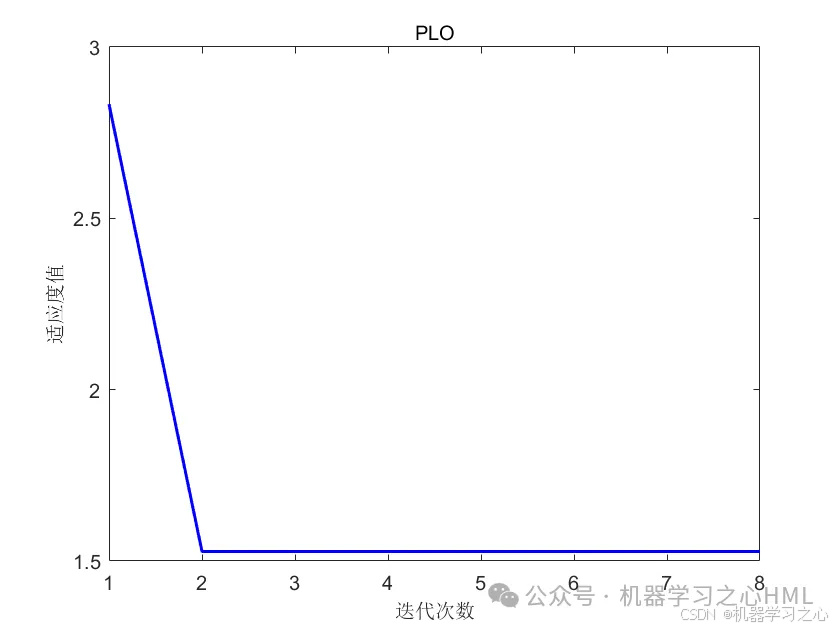
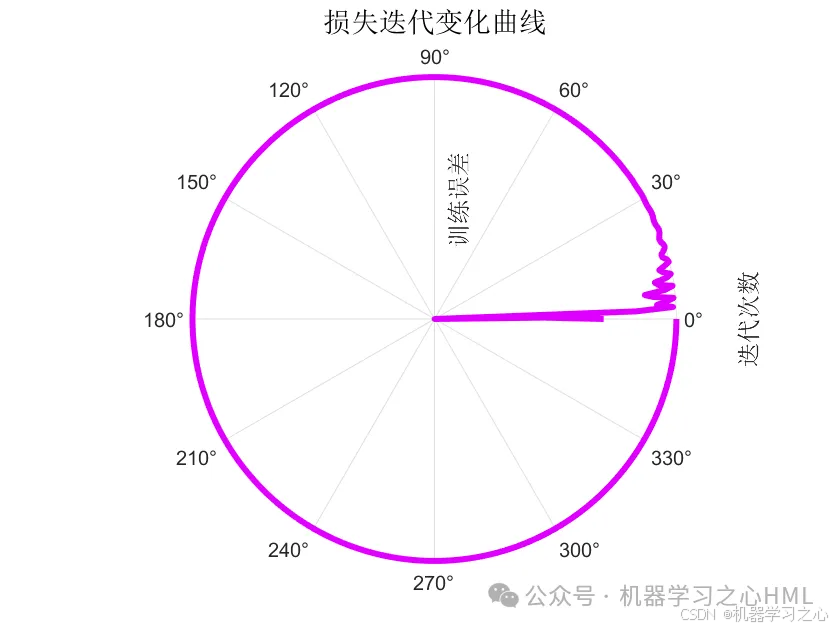
4.算法新颖。⑴ CEEMDAN模型处理高频数据,具有更高的准确率,能够跟踪数据的趋势以及变化。⑵ VMD 模型处理非线性、非平稳以及复杂的数据,表现得比EMD系列更好,因此将重构的数据通过VMD模型分解,提高了模型的准确度。(3)极光优化算法 Polar Lights Optimization (PLO)的元启发式算法,该成果于2024年8月最新发表在国际顶级JCR 1区、中科院 Top SCI期刊 Neurocomputing。PLO优化参数为自注意力机制头数、正则化系数、学习率!
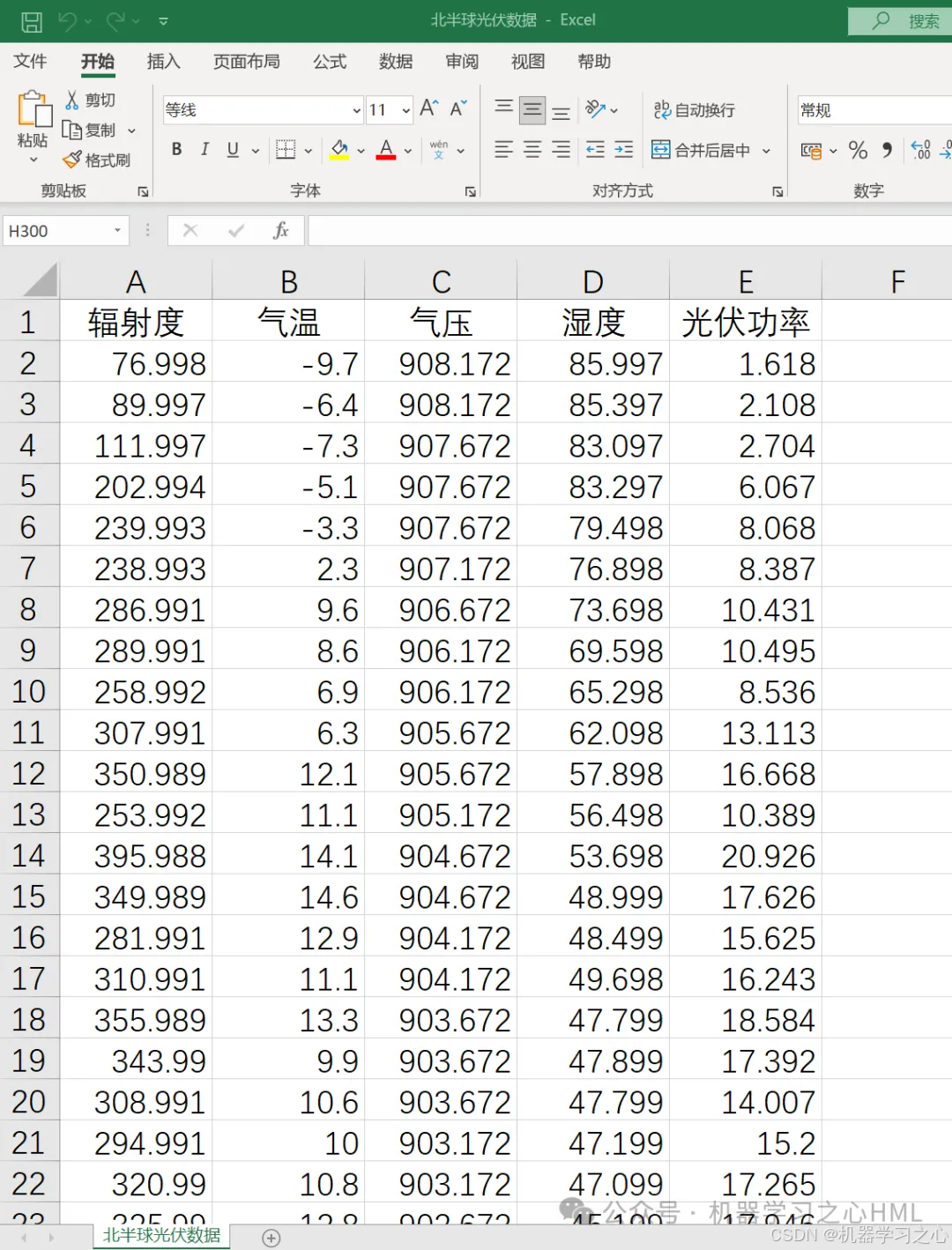
5.直接替换Excel数据即可用,数据集为excel(光伏功率数据集,输入辐射度、气温、气压、湿度,输出光伏功率),注释清晰,适合新手小白,直接运行主文件一键出图。

程序设计
- 完整程序私信博主回复Matlab实现CEEMDAN-Kmeans-VMD-PLO-Transformer多元时序预测。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
参考资料
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 双分解+一区极光优化+Transformer!CEEMDAN-Kmeans-VMD-PLO-Transformer多元时序预测

发表评论 取消回复