【大语言模型】ACL2024论文-03 MAGE: 现实环境下机器生成文本检测
目录

MAGE: 现实环境下机器生成文本检测
摘要
随着大型语言模型(LLMs)在文本生成方面的能力愈发接近人类水平,区分机器生成文本和人类撰写文本变得尤为重要。这项研究构建了一个大规模的现实测试平台,通过收集不同领域人类撰写的文本和由多种LLMs生成的深度伪造文本,探讨了深度伪造文本检测的挑战。研究发现,人类标注者在识别机器生成文本方面仅略优于随机猜测,而自动化检测方法在现实测试平台上面临挑战。此外,研究还发现,预训练语言模型(PLM)在所有测试平台上均获得了最高的性能,但在面对未见领域或新模型集生成的文本时性能下降。最后,研究通过调整决策边界显著提高了模型在现实场景下的性能,证明了深度伪造文本检测在现实世界中的可行性。
研究背景
近期,大型语言模型(LLMs)在文本生成方面取得了显著进展,使得机器生成的文本与人类撰写的文本之间的差异越来越小。这种能力缩小了人与机器在文本创作方面的差距,但也带来了诸如假新闻传播和抄袭等潜在风险。因此,检测深度伪造文本成为了一个重要的研究方向。
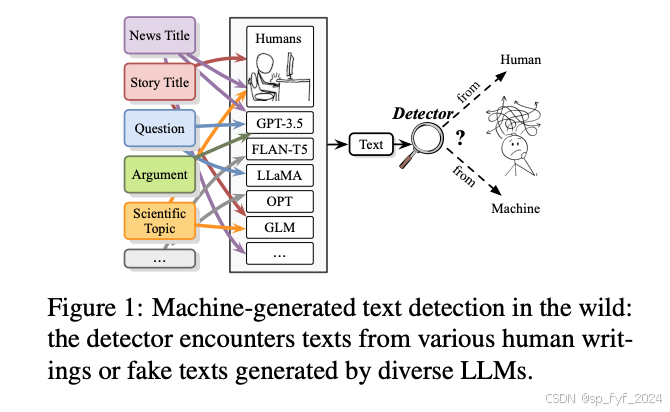
问题与挑战
在实际应用中,检测器需要面对来自不同领域或由不同LLMs生成的文本,而这些文本的来源对检测器来说是未知的。此外,检测器还需要能够识别未见领域或由新型LLMs生成的文本,这种跨领域和跨模型的检测能力对于实际应用尤为重要。
如何解决
研究者们构建了一个大规模的现实测试平台,通过收集不同领域的人类撰写文本和由多种LLMs生成的深度伪造文本,来模拟实际应用中的复杂情况。此外,研究还考虑了不同的检测方法,包括基于PLM的分类器、基于特征的分类器和零样本分类器,并在不同的测试平台上评估它们的性能。
核心创新点
- 构建了一个大规模的现实测试平台,覆盖了多种写作任务和不同来源的文本。
- 评估了多种自动化检测方法在现实测试平台上的性能,并探讨了跨领域和跨模型检测的挑战。
- 发现PLM在所有测试平台上均获得了最高的性能,尤其是在未见领域或新模型集生成的文本检测上。
- 通过调整决策边界显著提高了模型在现实场景下的性能,证明了深度伪造文本检测的可行性。
算法模型
研究中考虑了三种常用的文本分类器:
- PLM-based classifier:在数据集上微调Longformer模型,并添加分类层。
- Feature-based classifier:包括FastText和GLTR,前者使用词级二元模型作为特征,后者利用语言模型收集特征,如Top-10、Top-100和Top-1000排名的标记数量。
- Zero-shot classifier:DetectGPT,通过比较扰动文本的对数概率变化来检测文本,无需监督数据。
实验效果(包含重要数据与结论)
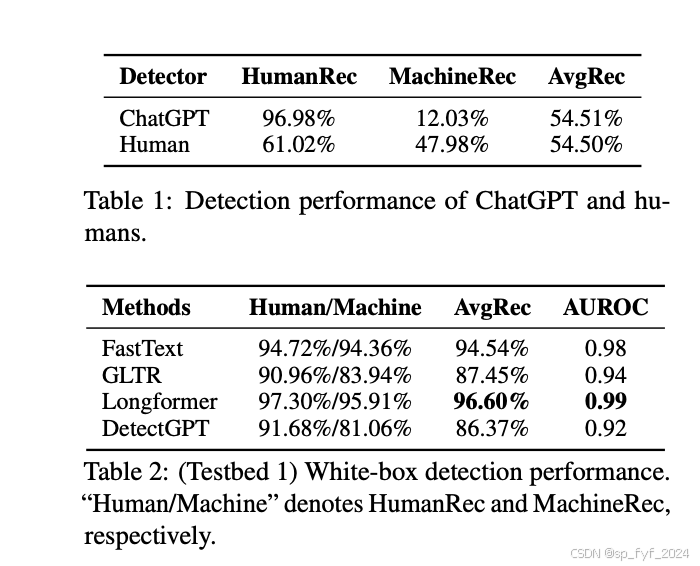
- 人类标注者:在识别机器生成文本方面仅略优于随机猜测。
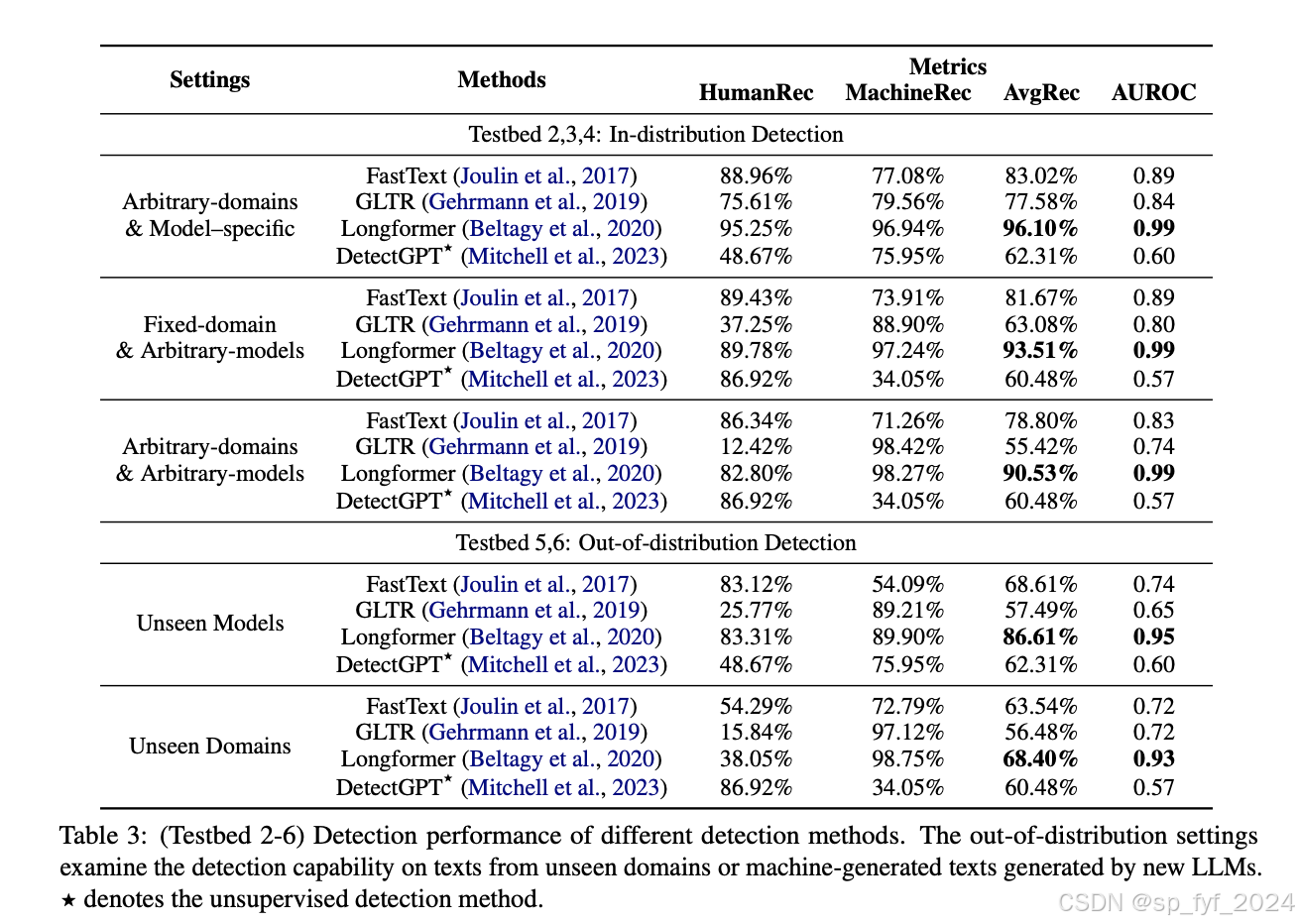
- PLM-based classifier:在所有测试平台上均获得了最高的性能,AvgRec超过90%。
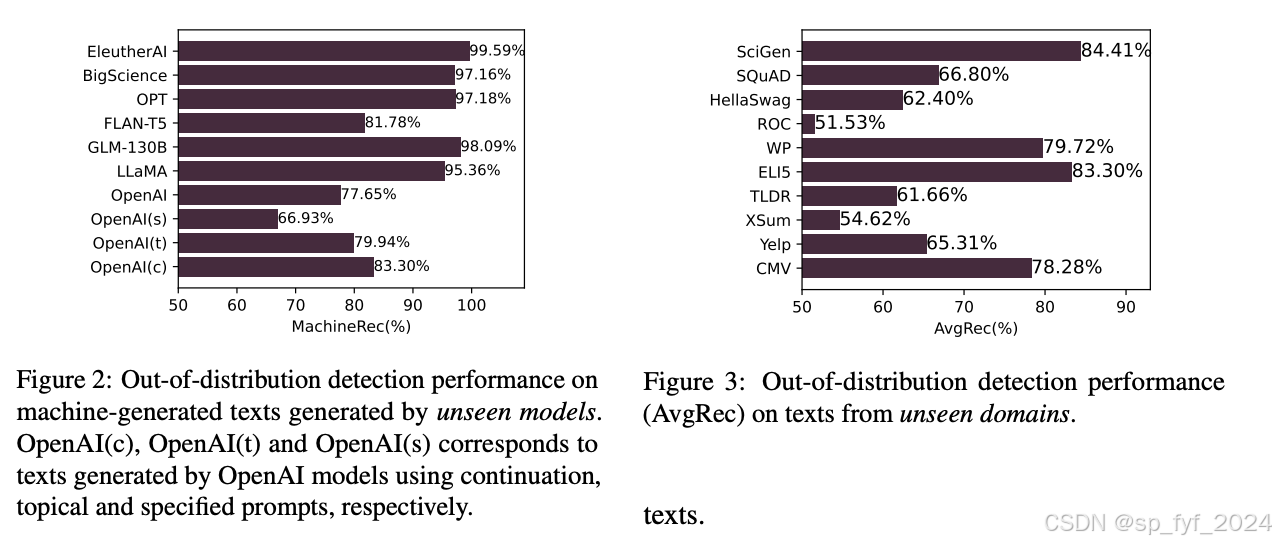
- 跨领域和跨模型检测:PLM-based detector在未见领域检测上性能下降至68.40% AvgRec。
- 决策边界调整:使用0.1%的领域内数据重新选择决策边界,将性能提高了13.38% AvgRec。
主要参考工作
研究中引用了多个相关工作,包括:
- 用于检测机器生成文本的统计边界方法。
- 基于神经网络的检测器。
- 语言模型中的水印技术,用于修改模型生成行为以便于检测。
后续优化方向
- 提高跨领域和跨模型的检测能力:研究如何提高检测器在面对未见领域或新模型集时的性能。
- 优化决策边界选择:探索更精细的方法来选择决策边界,以提高模型在现实场景下的性能。
- 探索新的检测方法:研究新的或改进的算法,以提高深度伪造文本检测的准确性和鲁棒性。
后记
如果觉得我的博客对您有用,欢迎 打赏 支持!三连击 (点赞、收藏、关注和评论) 不迷路,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【大语言模型】ACL2024论文-03 MAGE: 现实环境下机器生成文本检测

发表评论 取消回复