自然语言处理(Natural Language Processing,NLP)是指让计算机接受用户自然语言形式的输入,并在内部通过人类所定义的算法进行加工、计算等系列操作,以模拟人类对自然语言的理解,并返回用户所期望的结果。自然语言处理的目的在于用计算机代替人工来处理大规模的自然语言信息。在很大程度上与计算语言学(Computational Linguistics,CL)重合,是计算机科学与语言学的交叉学科,也是人工智能的重要方向。自然语言处理的研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。让计算机能够确切理解人类的语言,并自然地与人进行交互是NLP的最终目标。自然语言处理的挑战通常涉及语音识别、自然语言理解和自然语言生成。
一般的业务架构
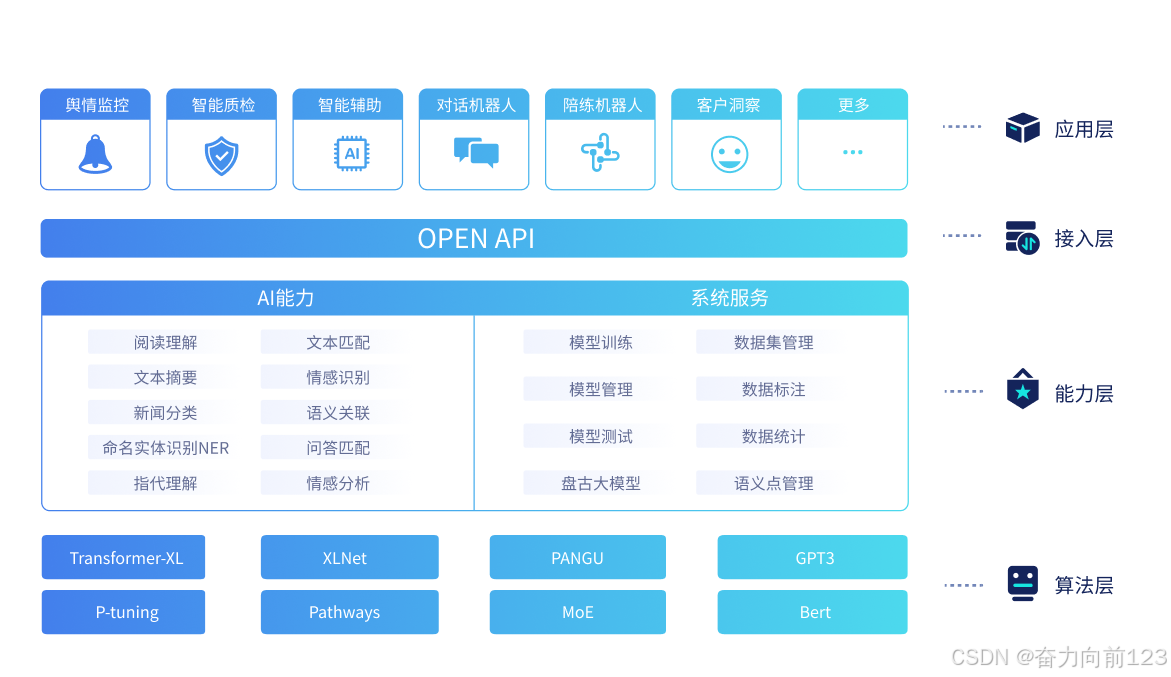
NLP模型生产过程

运用到的基础技术和算法
- 分词:基本算是所有NLP任务中最底层的技术。不论解决什么问题,分词永远是第一步。
- 词性标注:判断文本中的词的词性(名词、动词、形容词等等),一般作为额外特征使用。
- 句法分析:分为句法结构分析和依存句法分析两种。
- 词干提取:从单词各种前缀后缀变化、时态变化等变化中还原词干,常见于英文文本处理。
- 命名实体识别:识别并抽取文本中的实体,一般采用BIO形式。
- 指代消歧:文本中的代词,如“他”“这个”等,还原成其所指实体。
- 关键词抽取:提取文本中的关键词,用以表征文本或下游应用。
- 词向量与词嵌入:把单词映射到低维空间中,并保持单词间相互关系不变。是NLP深度学习技术的基础。
- 文本生成:给定特定的文本输入,生成所需要的文本,主要应用于文本摘要、对话系统、机器翻译、问答系统等领域。
算法:
fidf、BM25、TextRank、HMM、CRF、LSI、主题模型、word2vec、GloVe、LSTM/GRU、CNN、seq2seq、Attention
| 机器翻译 | 机器翻译是利用计算机将一种自然语言(源语言)自动转换为另一种自然语言(目标语言)的过程。 |
| 命名实体识别(NER) | 命名实体识别是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具。在给定一个文本流的情况下,确定文本中的哪些项目映射到适当的名称。比如从一句话中识别出人名、地名,从电商的搜索中识别出产品的名字,识别药物名称等等。 |
| 自然语言生成 | 从计算机知识库或逻辑形式的机器表述系统去生成自然语言,文本到文本生成(text-to-text generation)和数据到文本生成(data-to-text generation)都是自然语言生成的实例 |
| 自然语言理解 | 自然语言理解是将文本块转换成更正式的表示形式,研究如何让电脑读懂人类语言的一门技术。自然语言理解涉及到从多种可能的语义中识别预期的语义,例如封闭世界假定 (CWA)对开放世界假设,或者主观正/误、真/假的判断,并可从自然语言表达式中导出。自然语言表达式通常采用自然语言概念的有组织的符号的形式。语言元模型和本体的引入和创建被认为是有效的。[13] |
| 光学字符识别 | 对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程 |
| 问答 | 给定一个人类语言的问题,确定它的答案。典型的问题有特定的正确答案(比如“加拿大的首都是哪里?”),但有时也会考虑开放式问题(例如“生命的意义是什么?”)。[14] |
| 认识文字蕴涵 | 在自然语言处理是一个文字片段之间的定向关系。拥有一个文字片段的含意时,可以从另一个文字如下关系。TE的框架中,将会导致必须需要的文本被称为文本(T)和假设(H)作为分别。文字蕴涵是不一样的纯逻辑蕴涵,它有一个更宽松的定义:"T推导到H"(T⇒H),通常情况下,如果一个人阅读T将推断为H是最有可能的正确的关系。文字蕴含关系是有方向性的,如正向的"T推导到H"或反向的"H推导到T" |
| 关系提取 | 给定一段文本,确定命名实体之间的关系(例如谁与谁结婚) |
| 情感分析 | 通常从一组文档中提取主观信息,使用在线评论来确定特定对象的“极性”。它特别有助于识别社交媒体中的舆论趋势,以达到营销的目的。 |
| 话题分割和识别 | 给定一段文本,将其分成几段,每段都有一个主题,并确定该段的主题。 |
| 词义消歧 | 许多词汇有不止一个含义;我们必须联系上下文理解意义。对于这个问题,我们通常会需要一个相关词义列表,例如从字典或在线资源中获取。 |
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【升华】自然语言处理架构

发表评论 取消回复