我今天看到B站一个up主很好的资料【云计算科普研究所的个人空间-云计算科普研究所个人主页-哔哩哔哩视频】,结合我这周的积累整理了这份我觉得相比之前逻辑更加完善的笔记。
先是GPU到GPGPU 到CUDA之间进化关系部分,然后CUDA之外的友商竞品部分,到Tensor Core以及bf16、tf32进一步发展部分。
GPU如何工作的
GPU最初是用于图像渲染的,工作流程称为渲染管线。最典型的应用3D场景数据转化为2D场景数据。
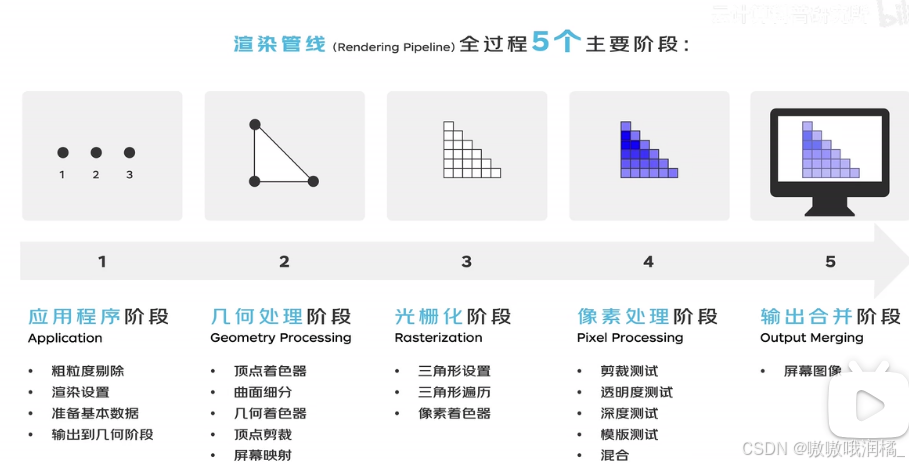
应用程序阶段:
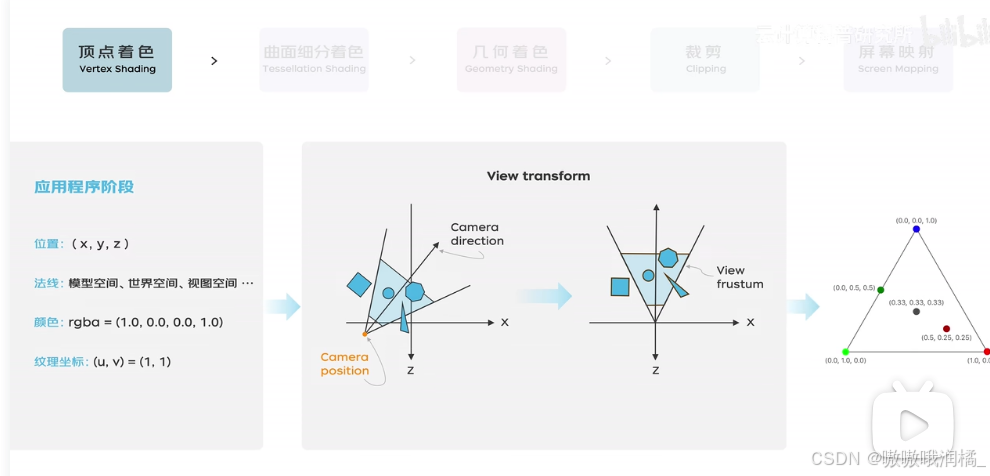
主要发生在CPU中,CPU准备后续渲染所需的数据,将数据,包括3D模型的顶点、纹理、光照、摄像机参数等,发送给GPU。
几何处理阶段: 后续都在GPU。
顶点着色。接手CPU传来的顶点数据,包括顶点的位置、法线、颜色、纹理坐标等,对其进行转换、光照处理以及坐标空间变换,计算得到每个顶点的最终属性。
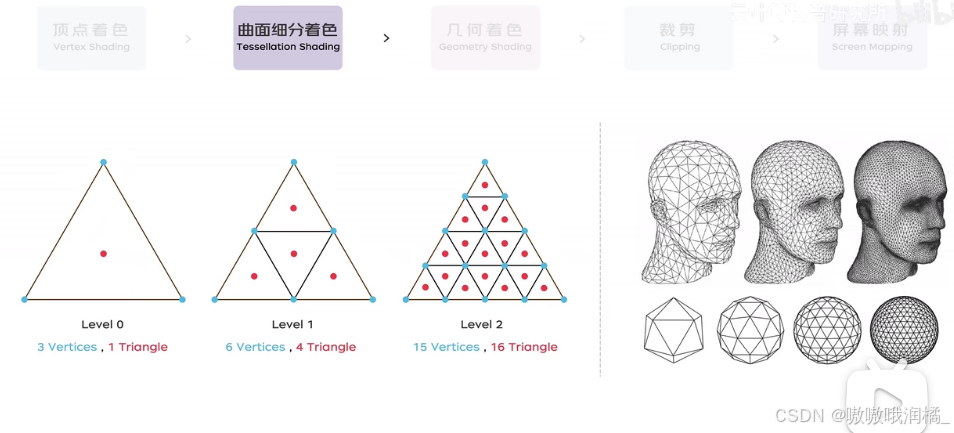
曲面细分着色。
在顶点之间插入新的顶点,生成更密集的网络结构。提高3D模型的细节,
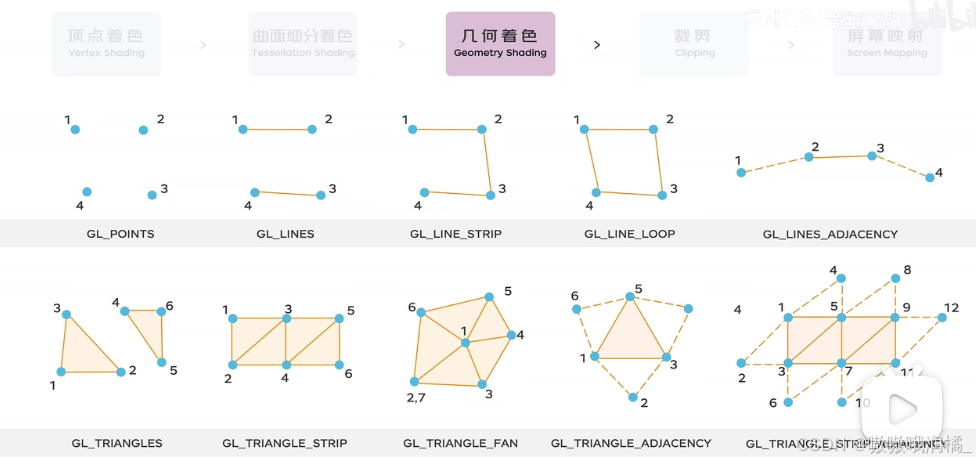
几何着色。
生成新的图元或改变现有图元的形状。即基于三角形、线段和点构建更复杂的几何图形。
裁剪。
将坐标系转换为裁剪空间。裁剪忽略那些位于视锥体外的图元,减少渲染引擎的处理负担,提高渲染效率和性能。
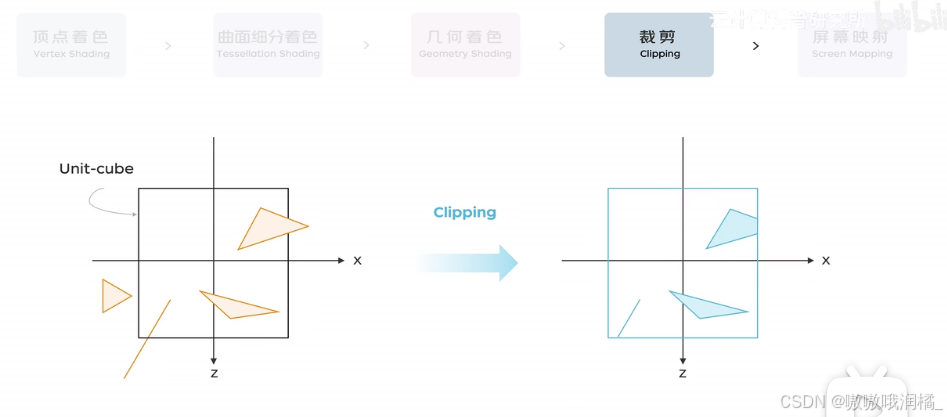
屏幕映射。
将图元从3D空间(裁剪空间)映射到2D屏幕空间上,为光栅化做准备。
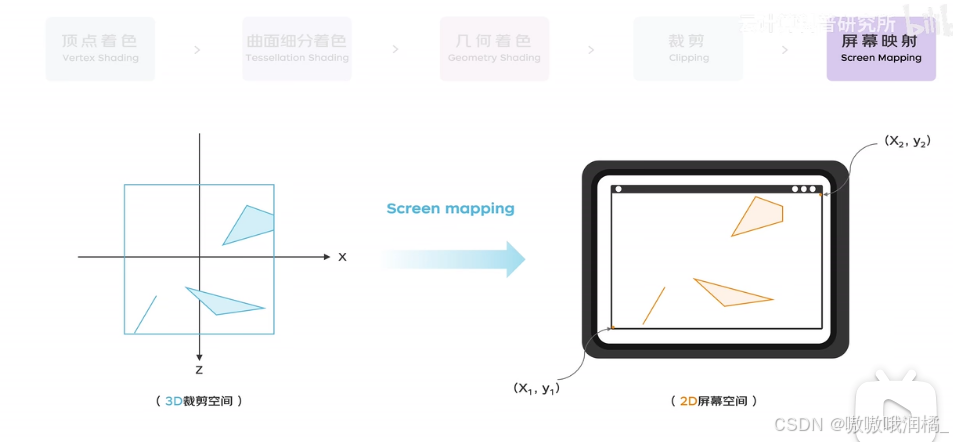
光栅化阶段
将前一阶段得到的点、线、三角形转变为屏幕上的像素或片元

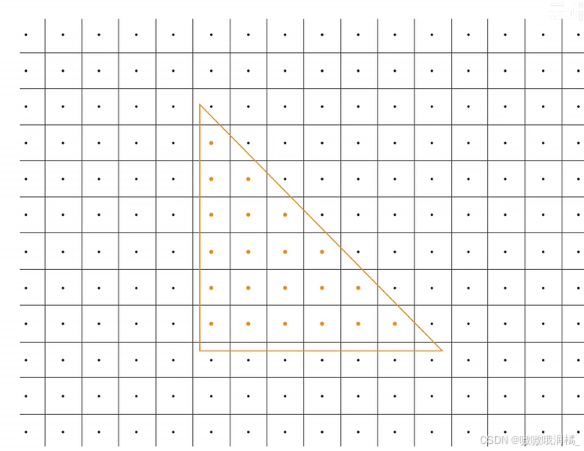
如图,若像素在图元中,那么该像素就属于这个图元,并且记录坐标、颜色、深度等,生成片元。
像素处理
光栅化阶段生成的每个片元进行颜色、纹理和光照计算,确定最终的属性值。
输出合并
对以上得到的片元进行裁剪测试、透明度测试、深度测试、模板测试和混合等操作,然后写入到帧缓冲区,最终显示在计算机屏幕上。
GPGPU
早期阶段,GPU的渲染管线被称为固定功能管线,此时渲染管线各阶段的处理单元是固定的,开发人员不可以改动,不能直接控制GPU内部的计算过程。
图形复杂度增加、半导体技术进步以及DirectX、OpenGL等图像接口API演进,可编程管线出现,把顶点着色、几何着色和像素着色迁移到可编程处理器上。
此时的GPU因为同时需要完成通用计算任务和图形处理任务,渲染管线的流水线特征,本质上成为一个可同时处理多个计算任务的加速器。被成为GPGPU 通用GPU。可高效执行非图形相关的计算任务。
CUDA
基于GPGPU的可编程管线的研发要求比普通CPU计算高,内容包含并行算法、GPU硬件和图像API接口,因此CUDA出世 Compute Unified Device Architecture 计算统一设备架构。
CUDA不仅是全新的硬件架构,还是一套全新的软件架构。推翻传统图形接口,CUDA的GPU编程语言基于标准的C语言,研发人员很容易开发CUDA应用程序使用GPU来加速计算。
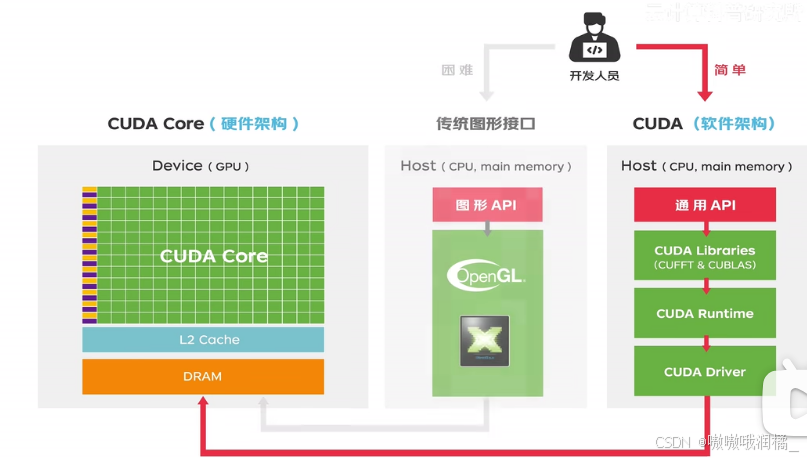
CUDA之外的GPU平台
作用: GPU与软件栈或API结合在一起,与硬件协同工作,为软件与GPU硬件交互提供了一种标准方式。它们被软件开发人员用来编写可以利用GPU并行处理能力的代码,并为软件与GPU硬件交互提供了一种标准方式。
- 通常,它们提供对低级功能的访问,例如内存管理、CPU和GPU之间的数据传输,以及GPU上并行处理任务的调度和执行。
- 它们还可以提供针对特定HPC工作负载优化的高级函数和库,如线性代数或快速傅里叶变换。
- 最后,为了方便开发人员优化和编写正确的代码,还包括调试和分析工具。
NVIDIA、AMD和Intel是为HPC设计和生产GPU的主要公司,它们各自提供CUDA、ROCm和oneAPI套件。通过这种方式,他们可以提供优化、差异化(提供针对其设备量身定制的独特功能)、供应商锁定、许可和特许权使用费,从而提高性能、盈利能力和客户忠诚度。还有跨平台API,如DirectCompute(仅适用于Windows操作系统)、OpenCL和SYCL。
| CUDA:NVIDIA的并行计算平台 | ROCm:AMD加速器的开放软件平台 | Intel oneAPI:用于跨各种体系结构优化和部署应用程序的统一软件工具包 | |
| intro | 支持C、C++和Fortran语言 | 为跨多个供应商和架构的开放可移植性而构建 为AMD GPU提供库、编译器和开发工具 支持C、C++和Fortran语言 支持GPU和多核CPU编程 | 支持CPU、GPU和FPGA 实现代码可重用性和性能可移植性 支持多种编程模型和语言: OpenMP, Classic Fortran, C++, SYCL 除非使用自定义的英特尔库,否则代码可以移植到其他OpenMP和SYCL框架 |
| Toolkits&API Libraries | 组件:CUDA工具包和CUDA驱动程序 cuBLAS(用于线性代数运算,如密集矩阵乘法)、cuFFT(用于执行快速傅里叶变换)、cuRAND(用于生成伪随机数)、cuSPARSE(用于稀疏矩阵运算) 加速GPU上的复杂计算 | 库:AMD平台前缀为roc 可以直接从HIP调用 hip-prefixed wrappers 确保了便携性,而没有性能成本 | Intel oneAPI Base Toolkit:用于高性能、以数据为中心的应用程序的核心工具和库集; 包含支持SYCL的C++编译器; 功能集合通信库、数据分析库、深度神经网络库等 additional toolkits: Intel oneAPI HPC Toolkit 包含编译器、调试工具、MPI库和性能分析工具 |
| Compilers | nvcc, nvc, nvc++, nvfortran 支持GPU和多核CPU编程 与OpenACC和OpenMP兼容 | 支持各种异构编程模型,如HIP、OpenMP和OpenCL | DPC++编译器:支持英特尔、英伟达和AMD ; 使用oneAPI Level Zero接口瞄准英特尔; 添加了对配备CUDA的NVIDIA GPU和配备ROCm的AMD GPU的支持 |
| Debugging tools | cuda-gdb, compute-sanitizer 同时调试GPU和CPU代码 识别内存访问问题 | roc-gdb命令行工具 便于GPU程序的调试 | Intel Adviser, Intel Vtune Profiler, Cluster Checker, Inspector, Intel Trace Analyzer and Collector, Intel Distribution for GDB |
| Performance analysis tools | NVIDIA Nsight Systems, NVIDIA Nsight Compute 分析系统范围和内核级别的性能 优化CPU和GPU使用率、内存带宽、指令吞吐量 | rocprof和roctracer工具 分析和优化程序性能 | |
| 全面的CUDA生态系统,具有广泛的工具和功能 | Heterogeneous-Computing Interface for Portability (HIP)异构计算接口可移植性(HIP) 支持NVIDIA和AMD平台的源代码可移植性,英特尔正在计划中 提供hipcc编译器驱动程序和运行时库 | 异构计算的综合统一方法: 抽象复杂性并提供一致的编程接口; 促进代码可重用性、生产力和性能可移植性 | |
从CUDA Core到 AI计算专用的Tensor Core以及BF16、TF32的出现
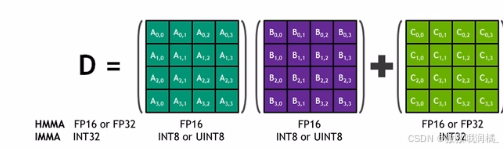
AI深度学习大爆,矩阵计算加速需求疯涨,因此NV推出Tensor Core,专门用于执行神经网络训练和推理。
- 矩阵乘法累加操作,MMA: Matrix Multiply-Accumulate。
- 融合乘积累加,FMA: Fused Multiply-Add。
- F16+FP32混合精度计算
FP32 : 1个符号位、8个指数位、23个尾数位。数值范围:~1.18e-38 ....~ 3.40e38(精度:6-9位有效数字)。支持FP32单精度的CUDA Core最多,因为范围和精度平衡。
而在AI深度学习初期训练中,FP16半精度计算精度足够而且计算快。
Tensor Core使用混合精度FMA浮点计算:乘法用FP16加快速度,累加用FP32保重精度。
Tensor Core在相同的硬件资源可以更快处理大数据集和计算更大的神经网络模型。
FP16 数值范围 ~5.96e-8(6.10e-5) ...65504【精度4位有效十进制小数】
那么如何平衡FP32的精度和FP16和运算速度?
Google AI的Google Brain提出BF16。brain floating Point Format 16。指数变为8,精度数位位7。
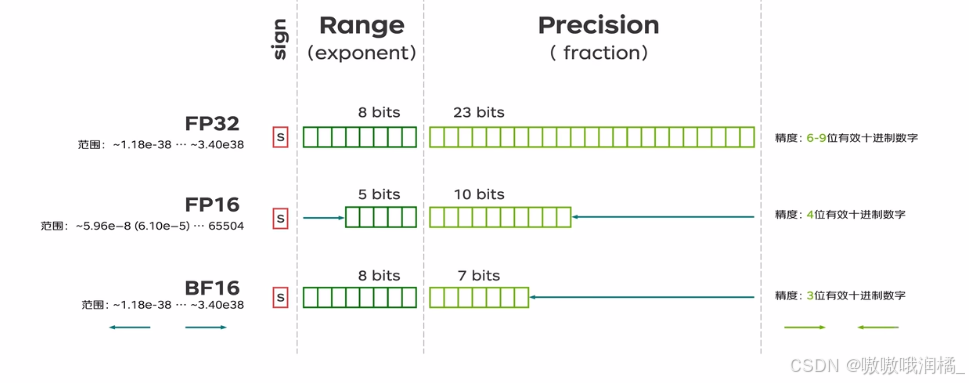
但是BF16精度有损失,于是TF32出现。
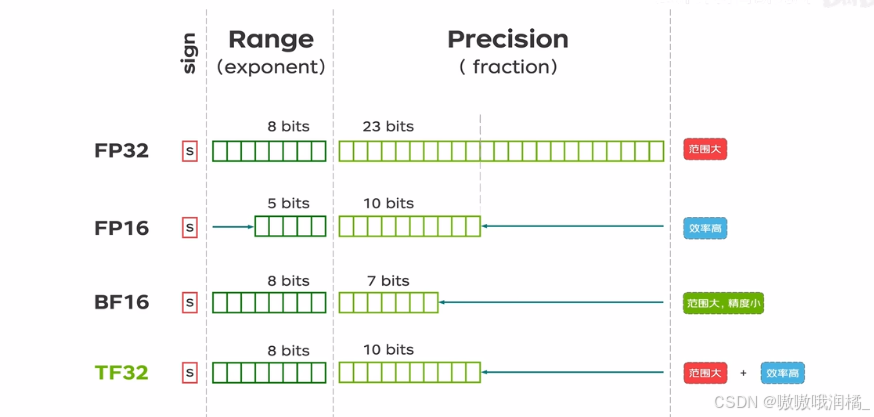
实际运行时,把FP32浮点数的尾数截断变成TF32,TF32补尾数变为FP32。AI程序代码零更改就能获得巨大性能提升。TF32成为Tensorflow和Pytorch默认浮点数类型。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 菜叶子芯酸笔记3:GPU、GPGPU、CUDA之间的关系;CUDA之外;Tensor Core

发表评论 取消回复