
- 论文地址Mini-InternVL: A Flexible-Transfer Pocket Multimodal Model with 5% Parameters and 90% Performance
- GitHub仓库地址
- 模型使用教程和权重下载地址
该论文发表于2024年10月份,截止2024年11月,引用数<10
文章目录
论文摘要
论文描述了一项关于多模态大语言模型(Multimodal Large Language Models, MLLMs)的研究成果。
-
背景介绍:
- 多模态大语言模型(MLLMs)在视觉-语言任务中表现出色,并且在多个领域都有广泛的应用。
- 这些模型的规模庞大,伴随而来的是高计算成本,这使得它们难以在消费级GPU或边缘设备上进行训练和部署,从而限制了其广泛应用。
-
研究贡献:
- 提出了Mini-InternVL系列模型,这些模型的参数量从10亿到40亿不等。
- 这些模型能够达到原有大型模型90%的性能水平,但是参数量只有原来的5%。
-
模型优势:
- 大幅提升效率和效果,使得这些模型更容易获取并在各种实际场景中应用。
-
进一步推广措施:
- 开发了一个统一的适应框架用于Mini-InternVL,使模型能够在下游任务(如自动驾驶、医学影像分析以及遥感等)中转移学习并超越专门设计的模型。
-
研究意义:
- 认为这项研究可以提供有价值的见解和资源,以促进高效有效的多模态大语言模型的发展。
总结而言,论文是关于一种名为Mini-InternVL的新模型系列的介绍,该模型旨在解决传统多模态大语言模型在实际应用中的计算成本问题,同时保持高性能, 并通过一个适应性框架来增强模型的迁移学习能力。
1. 引用介绍
近年来,多模态大语言模型(MLLMs)取得了显著的进展,这些模型利用预训练大语言模型(LLMs)的强大能力,并与视觉基础模型(VFMs)相结合。这些模型在广泛的图像-文本数据上经过多阶段训练,有效地将VFMs的视觉表示与LLMs的潜在空间对齐, 从而在通用视觉-语言理解和推理以及交互任务中展现出良好的性能。
然而,这些模型在大规模计算负担和长尾领域特定任务上的性能较差,限制了它们在实际场景中的广泛应用。轻量级MLLMs为参数大小和性能之间提供了良好的平衡,缓解了对昂贵计算设备的依赖,并促进了各种下游应用的发展。但是,仍然存在两个挑战:
- 现有的大部分MLLMs使用像CLIP这样的视觉编码器,这些编码器在互联网域的图像-文本数据上进行训练,并与BERT对齐。因此,这些视觉编码器无法覆盖广泛的视觉领域,并与LLMs的表示不匹配。
- 将MLLMs适应于专用领域,现有方法主要集中在修改模型架构,收集大量的相关训练数据,或针对目标域定制训练过程。 目前还没有关于LLMs下游适应的共识框架。不同的领域有不同的模型设计,数据格式和训练时间表。
为了解决这些问题,需要一个具有全面视觉知识的强大视觉编码器以及一个允许在各个领域下游任务中高效应用的一般迁移学习范式,同时保持低成本的边际效益。
在本研究中,作者提出了Mini-InternVL,这是一系列易于转移到各种专业领域的便携式强大MLLMs。
首先,作者首先增强了轻量级视觉编码器的表示能力。作者使用CLIP的权重初始化了一个300M的视觉编码器,并使用InternViT-6B作为教师模型进行知识蒸馏。
随后,作者开发了Mini-InternVL系列,包括10亿、20亿和40亿参数,通过将视觉编码器与预训练的LLMs(如Qwen2-0.5B,InternLM2-1.8B,和Phi-3-mini)集成。
得益于强大的视觉编码器,Mini-InternVL在通用多模态基准测试(如MMBench,ChartQA和MathVista)上表现出色。值得注意的是,与InternVL2-76B相比,所提出的Mini-InternVL-4B在参数更少(减少到5%)的同时,实现了更大同类模型==90%==的性能。这显著降低了计算开销。
为了使Mini-InternVL更好地适应特定领域的下游任务,作者引入了一种简单而有效的迁移学习范式。在这个范式中,作者开发了一种适用于各种下游任务的统一迁移方法,包括自动驾驶、医学影像和遥感。这种方法规范了模型架构、数据格式和训练计划。结果表明,这种方法在特定领域场景中增强了模型的视觉理解和推理能力,使其能够在目标领域达到专有商业模型的性能水平。
总之,作者的贡献有三方面:
- 提出了Mini-InternVL,一种强大的便携式多模态模型,它不仅实现了少于40亿参数的健壮多模态性能,而且可以以较低的边际成本轻松转移到各种领域的下游任务。
- 为Mini-InternVL开发了几个设计特性,包括一个轻量级的视觉编码器–InternViT-300M,该编码器对各种视觉域具有鲁棒性。此外,作者引入了一个简单但有效的方法,该方法标准化了模型架构、数据格式和训练时间表,以实现有效的下游任务迁移。
- 通过在通用和特定领域的基准测试上进行广泛实验,全面评估了Mini-InternVL。实验结果表明,作者的多模态模型在通用多模态基准测试上,使用显著较少的参数就能实现90%的性能。对于特定领域任务,在微调计算成本极低的情况下,它们可以与封闭源商业模型相竞争。作者进行了一系列的消融研究,以探索数据样本大小对域适应的影响,希望为在专业领域应用MLLMs提供一些洞察。
2. 本文方法
在本节中,将介绍Mini-internVL,一系列轻量级多模态大型语言模型(MLLMs)。先提供了Mini-InternVL的全面概述。然后,详细介绍了InterViT-300M,这是一个通过知识蒸馏开发的轻量级视觉模型,它继承了一个强大的视觉编码器的优势。最后,描述了一个迁移学习框架,旨在增强模型对下游任务的适应能力。
2.1. 全面概述
如图1所示,Mini-InternVL主要由三个主要组件组成:InternViT、MLP Projector和LLMs。
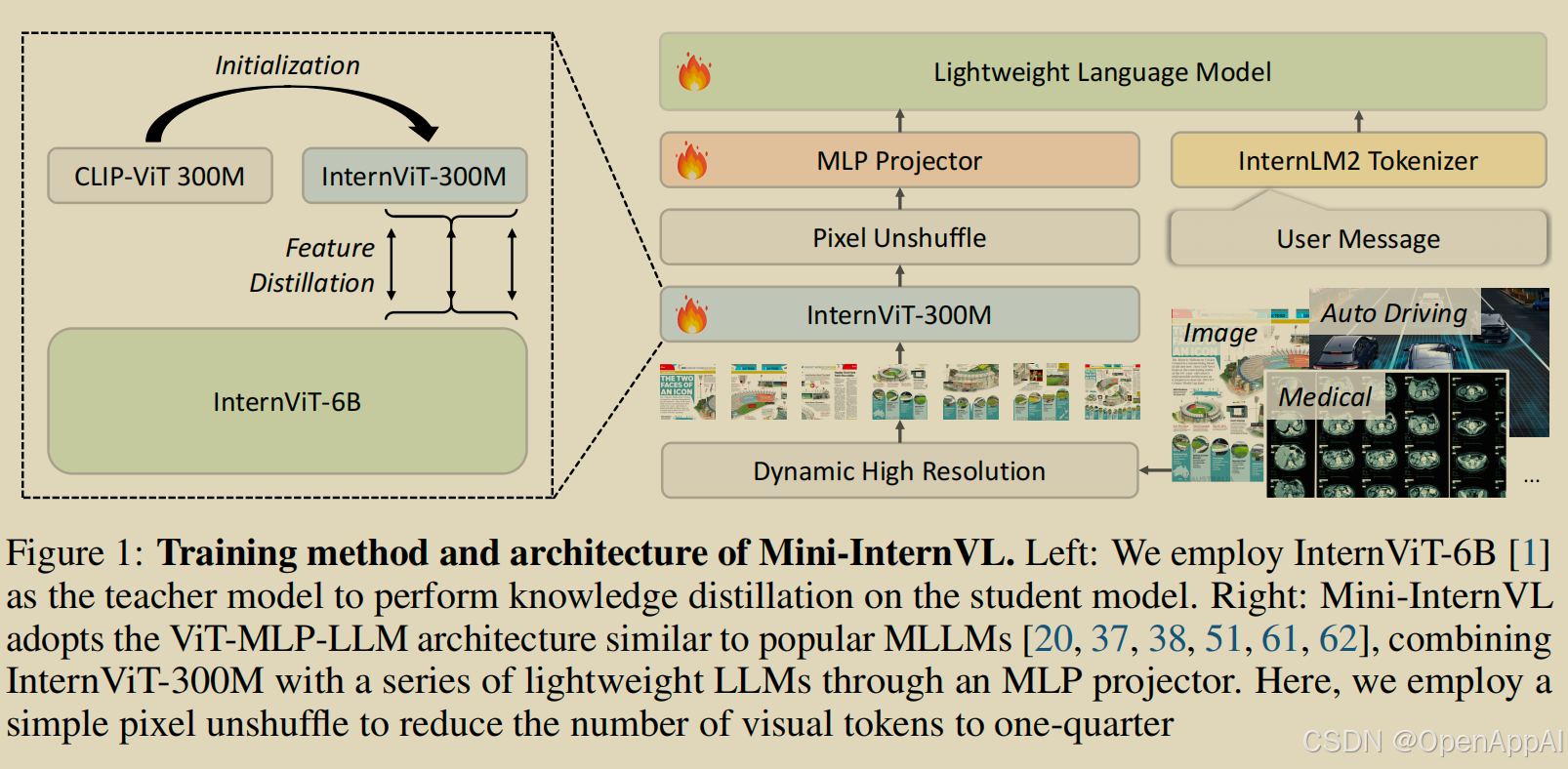
作者使用InternViT-300M作为视觉编码器,这是一个轻量级的视觉模型,继承了强大视觉编码器的功能。基于InternViT-300M,作者开发了三种版本的Mini-InternVL:Mini-InternVL-1B、Mini-InternVL-2B和Mini-InternVL-4B。每个版本分别连接到预训练的Qwen2-0.5B,InternLM2-1.8B和Phi-3-mini。
类似于其他开源的MLLMs,Mini-InternVL使用MLP项目器MLP Projector将视觉编码器和LLMs连接起来。
作者采用了类似于InternVL 1.5的动态分辨率输入策略,以提高模型捕捉细粒度细节的能力。
作者还应用了一个像素混合操作,将视觉 Token 的数量减少到原始的1/4。因此,在Mini-InternVL中,一个448x448图像被表示为256个视觉 Token ,使其能够处理多达40个图像裁剪(即,4K分辨率)。
Mini-InternVL 的训练分为两个阶段:
- 语言-图像对齐:在这个阶段,作者只解冻 MLP 组件。遵循 InternVL-1.5 [2] 的做法,作者使用一个涵盖各种任务的训练数据集,包括描述、检测、定位和 OCR。这些数据集的多样性确保了 Mini-InternVL 的强大预训练,使模型能够处理不同任务中的各种语言和视觉元素。
- 视觉指令调优:作者精心选择数据集,以增强模型在广义多模态任务上的性能,类似于 InternVL-1.5。这些任务包括图像描述、图表解释、OCR 和跨学科推理。作者使用这些数据集进行全参数微调,进一步向模型注入世界知识,使其能够遵循用户指令。
2.2. InternViT-300M
大多数现有的MLLMs采用在图像文本对齐数据上进行训练的视觉编码器,如CLIP,以获得其表示。这些编码器缺乏对视觉世界的全面知识,需要通过与LLM结合的迭代生成预训练来获取。与其他方法相比,Mini-InternVL通过使用辅助路径增强视觉基础模型的视觉基础模型,直接利用经过在多种数据集上进行生成训练的强大视觉模型,将知识转移到轻量级视觉模型。
具体而言,作者使用InternViT-6B作为教师模型,并使用CLIP-ViT-L-336px初始化学生模型的af权重。作者通过计算最后K个transformer层隐藏状态之间的负余弦相似性损失,将学生模型的表示与教师模型对齐。所得到的模型名为InternViT-300M。
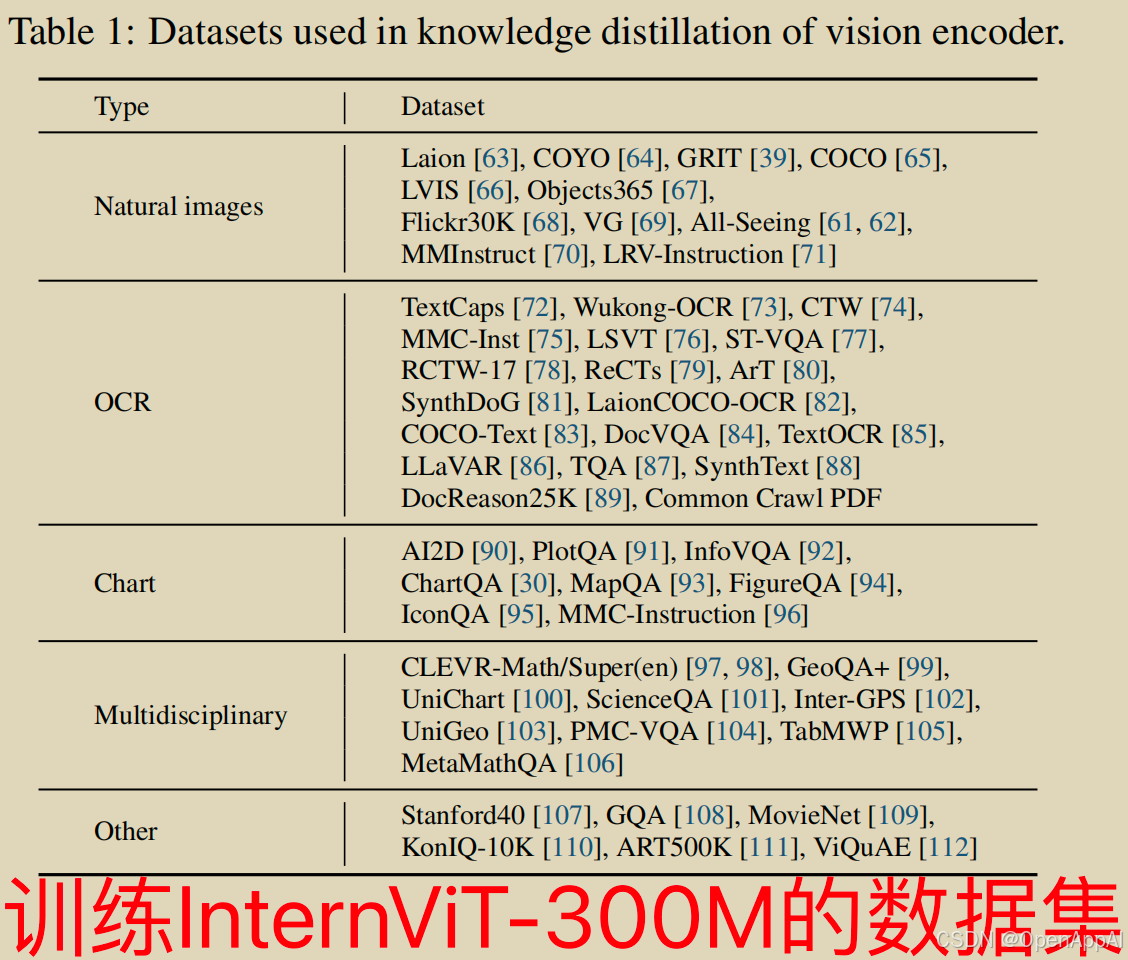
本文的主要目标是继承InternViT-6B中预训练的知识。 为了实现这一目标,作者整理了一个来源于各种公开可获取资源的Dataset,具体内容请见表1。该数据集包含四类主要数据:自然图像、OCR图像、图表和多学科图像。所有图像均被重新缩放到448x448的分辨率,并在训练过程中禁用了动态分辨率,以提高训练效率。最终,作者开发了一个名为InternViT-300M的视觉编码器,该编码器融合了多种知识,并适用于各种语言模型。
2.3. 领域适配-迁移学习框架
尽管许多研究已经成功地将MLLMs应用于下游任务,但尚未建立一个被广泛接受的框架,用于将这些模型适应于这些应用。不同领域的模型设计、数据格式和训练策略的差异导致了MLLMs之间的显著异质性,这使得标准化变得困难。为了解决这个问题,作者提出了一种简单而有效的迁移学习框架。
训练策略 在领域自适应阶段,作者对Mini-InternVL进行全参数微调。对于特定的领域应用场景,作者将相应的数据转换为所需的格式并将其纳入作者的训练数据集。在领域自适应阶段,添加一定比例的一般多模态数据不会影响特定领域的性能,同时保留模型的通用多模态能力。在实验中,作者发现添加一般数据可以提高模型在其他任务上的泛化能力。因此,在进行领域自适应时,作者可以根据计算开销和性能平衡选择适当的一般数据比例。
数据格式 指令调优是教模型遵循用户指令的重要训练阶段,其训练数据采用视觉问答(VQA)和对话格式。下游任务的VQA数据集(如RSVQA和PMC-VQA)可以直接作为指令遵循数据使用。

对于其他传统任务,如上图2所示,作者根据以下方法分别将其转化为VQA格式:
(1) 图像分类任务
在许多专业领域的传统分类任务中,涉及大量技术术语。在大多数情况下,作者可以轻松地将分类任务格式化为多项选择题。给定一张图像,候选标签集O,以及真实标签G∈O,该模板可以表示为:
【用户】: [图像][ Prompt 前缀][候选标签][ Prompt 后缀]
【助手】: [真实答案]
在远程感测图像分类中,作者利用 Prompt 如“在给出的一个类别中,将图像分类:密集居住区,…,学校。用一个词或短语回答。”,如上图2所示,这种方法将图像分类任务转化为多选题。
在自主驾驶数据中的自行车行为预测中,作者从DriveLM中获得灵感,采用模板如“预测自行车的行为。请从以下选项中选择正确答案:A. 自行车一直向前。自行车不移动。B…”。
(2) 视觉定位任务
Mini-InternVL中支持视觉定位任务,可以使用特殊 Token来包含要检测的物体的名称。使用这个 Token ,模型可以被指示在格式内提供物体的位置,坐标范围从0到1000。这种方法使作者能够将目标定位和指代表达式检测转换为对话格式。
作者在远程感测指令数据中广泛应用这种格式。例如,对于指代表达式“1座桥梁在中心附近的一些树木”,作者将其作为指令使用“检测1座桥梁在中心附近的一些树木”,作为响应使用“1座桥梁在中心附近的一些树木[[x1, y1, x2, y2]]”。
(3) 区域感知任务
在专业领域中,区域 Level 的对话任务很常见。这些任务需要向模型提供空间位置信息,除了问题输入之外。模型需要专注于指定注意力区域内的物体来生成响应。具体而言,有两种实现方法。第一种方法是通过边界框、 Mask 或轮廓直接标注图像上的位置,如图2中的Region Perception2所示。

第二种方法通过[[x1,y1,x2,y2]]来表示问题中的物体,其中坐标值在0和1000之间归一化。这种表示方法指导模型关注图像中的特定区域,使其能够执行区域级描述和区域特定VQA等任务。在遥感领域,目标是使模型能够识别位于坐标[x1, y1, x2, y2]内的物体。
为了实现这一目标,作者使用如下 Prompt 作为输入指令:“What object is in this location[[x1, y1, x2, y2]]”,其中"物体名称[[x1, y1, x2, y2]]"作为标签。
在自动驾驶中,图像从六个不同的视角捕获。如图3所示,作者有效地利用动态分辨率来适应这种数据。具体来说,InternVL支持根据其长宽比将图像分割成448×448大小的块。

(4)多视角图像
因此,作者将每个图像调整为896×448像素,然后,如上图3所示,以固定顺序将这些图像组合在一起,得到最终分辨率为2688×896。这意味着图像被自动处理为12个块,并为模型提供全局上下文,同时添加了一个缩略图。此外,作者将每个视角图像的文本标签与其相机位置相关,例如“CAM_FRON”。
2.4. 视频帧
InternVL 支持以交错图像格式表示的视频帧。作者使用模板表示帧序列,如 “Frame1: <IMG_CONTEXT> Frame2: <IMG_CONTEXT>。” 其中 <IMG_CONTEXT> 表示图像 Token 。对于分辨率为 448 448 的图像,模型可以容纳最多 40 帧的序列。
3. 实验
3.1 通用多模态基准测试结果
在本节中,作者全面评估了模型在多种基准测试上的多模态理解和推理能力。作者研究中使用的基准测试分为四种不同的类型:
- OCR相关任务,包括DocVQA、OCRBench和InfographicVQA;
- 图表和图解理解,包括AI2D和ChartQA;通用多模态任务,如MMBench;
- 多模态推理,包括MMMU和MathVista。此外,作者还报告了模型在OpenCompass上的平均得分。
结果显示,Mini-InternVL 在大多数基准测试中表现出强大的性能。最小模型只有10亿个参数,但其性能与具有20亿参数的模型(如DeepSeek-VL-1.3B和MiniCPM-V 2.0)相当。与其他轻量级模型相比,Mini-InternVL-4B 在大多数基准测试中表现出色,尤其是在MMbench、ChartQA、DocVQA和MathVista等指标上,其性能与商业模型(如Gemini-Pro-1.5)相当。
值得注意的是,与InternVL2-Llama3-76B相比,后者使用了更大的InternViT-6B,但Mini-InternVL仅使用了5%的参数,实现了约90%的性能提升。这突显了作者的知识蒸馏策略的有效性。
3.2 转移到各种专业领域
3.2.1 基于多视图图像的自动驾驶
作者选择DriveLM-nuScenes-V1.1作为作者的训练数据集,该数据集包含317k训练样本,涵盖了驾驶过程的各个方面。该数据集包括感知、预测和规划方面的数据,提供了对自动驾驶场景的全面理解。
在DriveLM-nuScenes中,作者从六个不同的视角捕捉图像。作者有效地利用了动态分辨率特性来适应这种数据。具体来说,Mini-InternVL根据其长宽比将图像分割为448×448大小的块。如图3所示,作者将每个视图的图像重新缩放到896×448像素,然后以固定顺序将这些图像组合在一起,得到最终分辨率为2688×896。这意味着图像被自动处理为12个块,并为模型提供全局上下文,添加了一个缩略图。
此外,作者为每个视图的图像 Token 了表示其摄像机位置的文本,例如“CAM_FRON”。
如图3所示,DriveLM-nuScenes包含带有坐标的问答对,因此作者需要将它们归一化到0到1000的范围内,以便与Mini-InternVL的输出对齐。在数据集中,物体用c标签表示。作者使用定制的 Prompt :“物体使用<c, CAM, [cx,cy]>编码,其中c是标识符,CAM表示物体中心点所在的光学相机,x,y分别表示2D边界框中心点的水平坐标和垂直坐标。”来指导模型组成c标签。实际响应通常包括需要所有物体列表的问题的边界框标注。

总结
论文介绍了Mini-InternVL,它是一系列轻量级的开源多模态大语言模型(MLLMs),旨在应对在资源受限环境中部署多模态大语言模型的挑战。
-
研究目标:
我们介绍了一组名为Mini-InternVL的轻量级、开源的多模态大语言模型,这些模型是为了克服在计算资源有限的环境中部署大型多模态模型的问题而设计的。 -
模型特点:
Mini-InternVL使用InternViT-300M作为紧凑的视觉编码器,通过从更强大的教师模型中进行知识蒸馏,整合了跨多个领域的世界知识。这样做的目的是解决像CLIP-ViT这样的编码器的局限性。 -
性能与参数对比:
尽管Mini-InternVL使用的参数显著少于大型模型,但它能够达到大约90%的性能表现,特别是在光学字符识别(OCR)和特定领域的图像理解等任务上表现出色。 -
应用与适应性:
为了便于小规模多模态模型在专业领域的应用,我们采用了一种统一的迁移格式,使得我们的模型能够有效地适应多个特定领域,在这些领域中它们的表现可与其它专门的方法相媲美。 -
研究的意义:
我们希望这项工作能为多模态大语言模型的应用提供有价值的见解。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 《Mini-internVL》论文阅读:OpenGVLab+清华/南大等开源Mini-InternVL | 1~4B参数,仅用5%参数实现90%性能

发表评论 取消回复