
基本信息
标题: Perceiver: General Perception with Iterative Attention
作者: Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, Joao Carreira
发表: ICML 2021
arXiv: https://arxiv.org/abs/2103.03206

摘要
生物系统通过同时处理来自视觉、听觉、触觉、本体感觉等多样化模态的高维输入来感知世界。
另一方面,深度学习中使用的感知模型是为单个模态设计的,通常依赖于特定领域的假设,例如几乎所有现有视觉模型所利用的局部网格结构。
这些先验引入了有用的归纳偏差,但也使模型局限于单个模态。
在本文中,我们介绍了Perceiver——一个基于Transformer构建的模型,它对输入之间的关系几乎没有架构假设,但也能扩展到处理数以万计的输入,就像卷积神经网络。
该模型利用非对称注意力机制,通过迭代地将输入蒸馏到一个紧凑的潜在瓶颈中,从而能够扩展以处理非常大的输入。
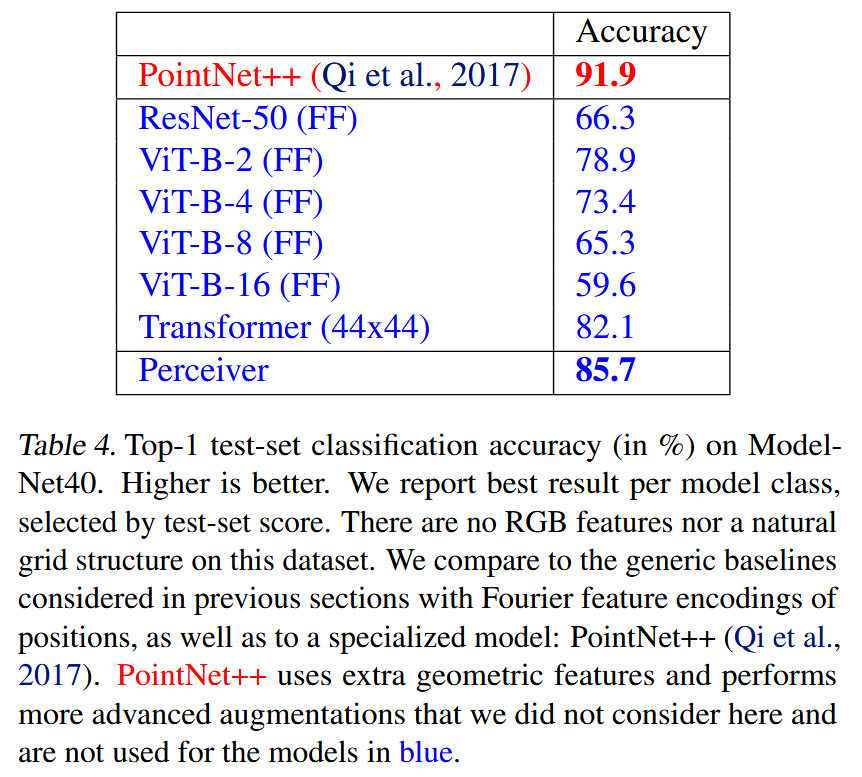
我们表明,这种架构在各种模态的分类任务上与强大、专业的模型具有竞争力或优于它们:图像、点云、音频、视频以及视频+音频。
Perceiver在ImageNet上直接关注50,000个像素,其性能与ResNet-50和ViT相当,而不使用二维卷积。
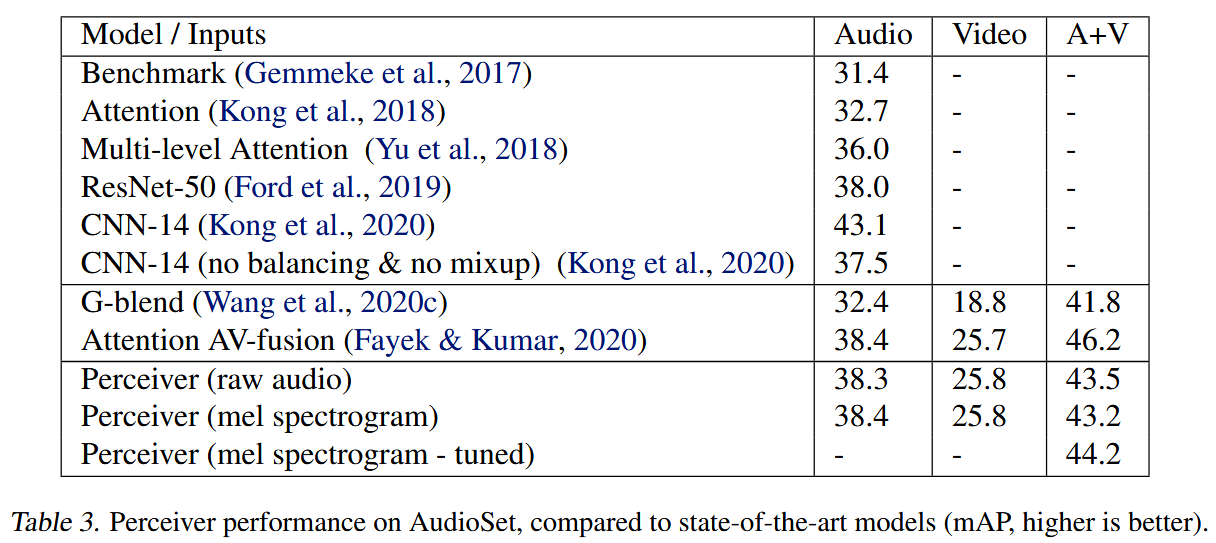
在AudioSet的所有模态中,它也具有竞争力。
模型架构
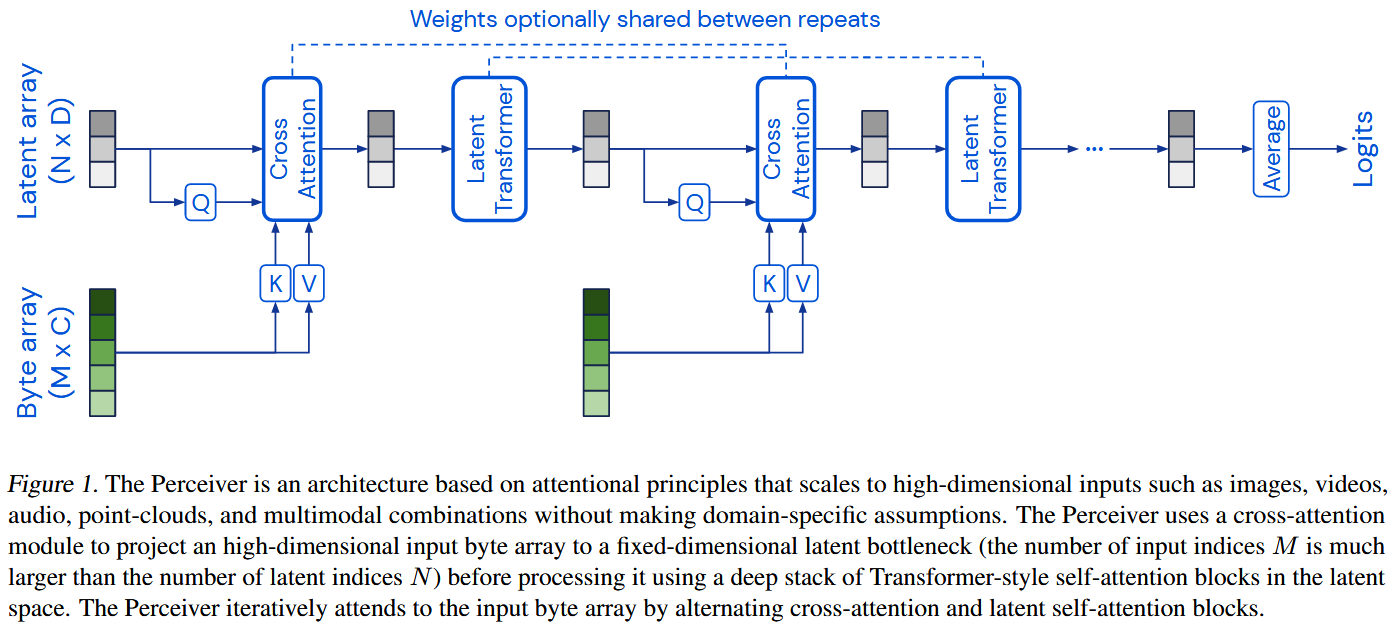
用一组可训练的Latent array来查询Byte array中的特征。
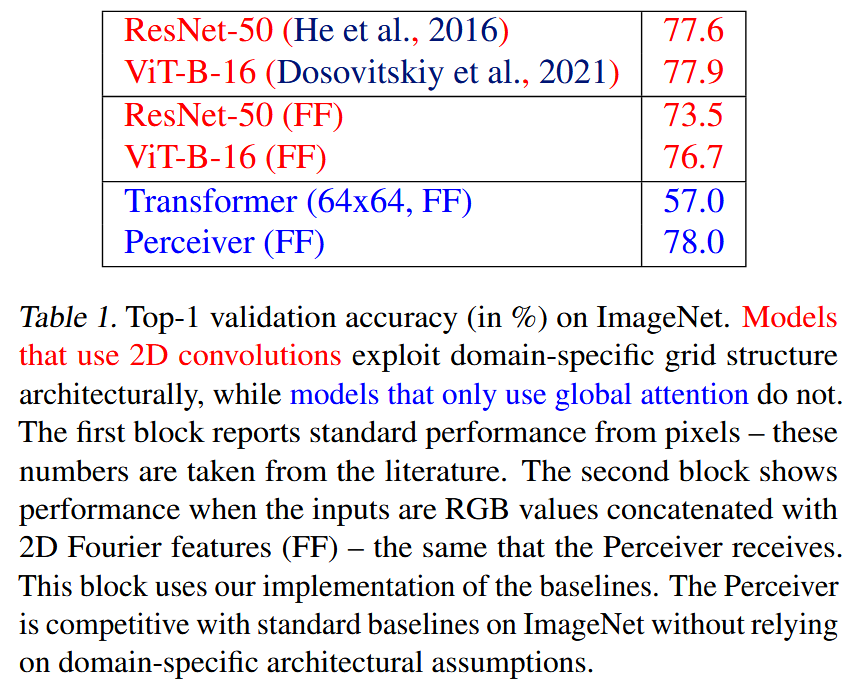
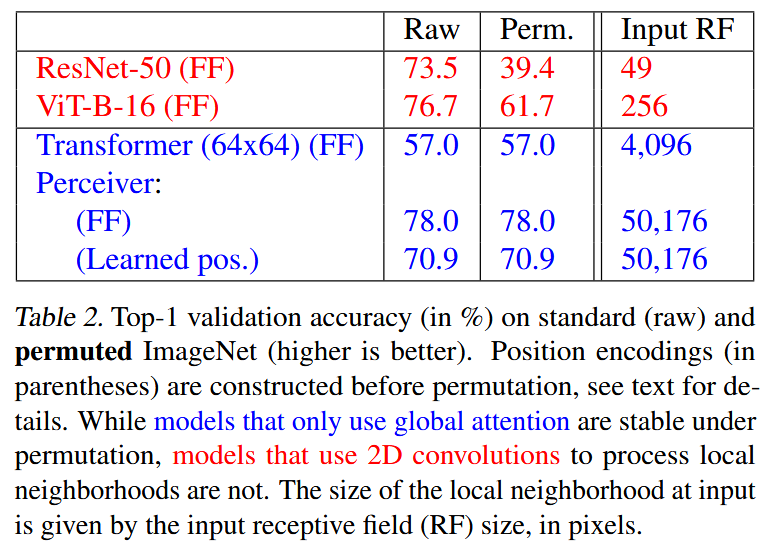
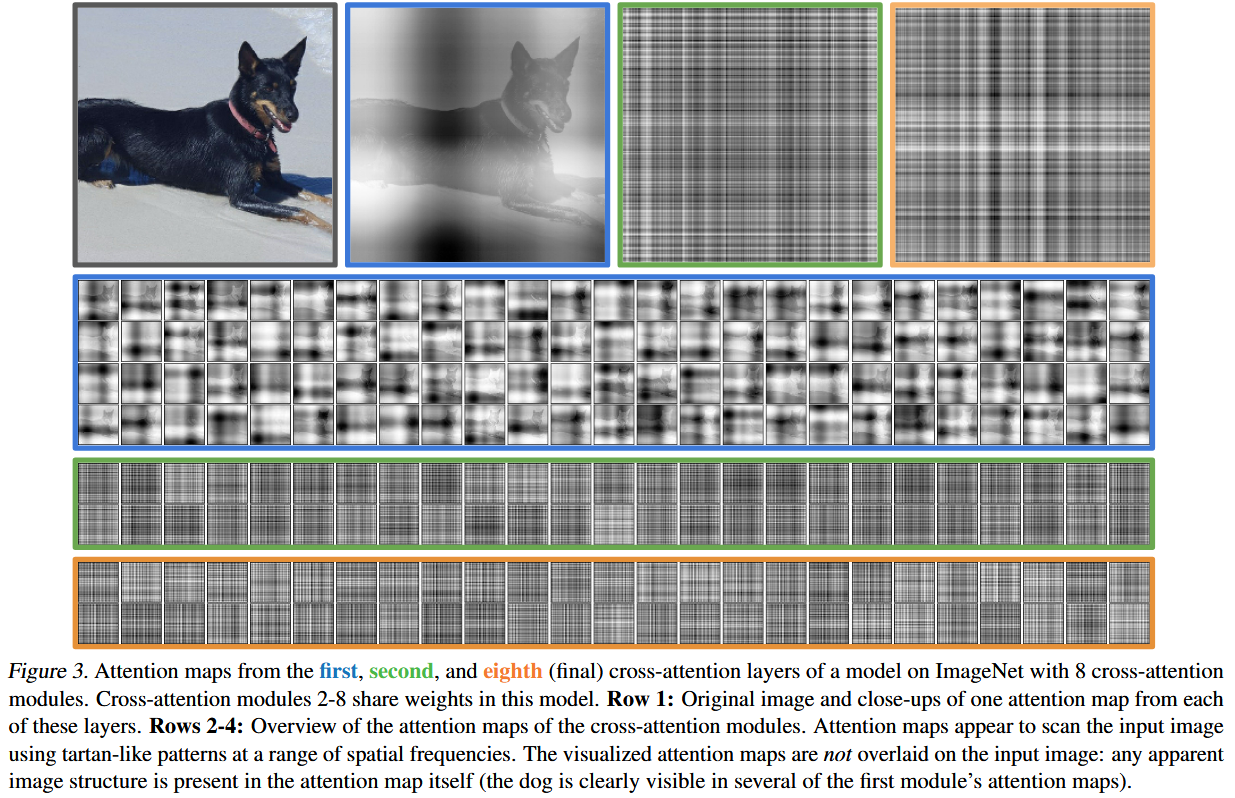
实验
总结
我们提出了Perceiver,这是一个基于Transformer的模型,可以扩展到超过十万个输入。
这为对输入假设较少且能够处理任意传感器配置的通用感知架构开辟了新的途径,同时能够实现所有层次的信息融合。
随着灵活性的提高,过拟合的风险也随之增大,我们许多设计决策都是为了减轻这一风险。
在未来工作中,我们希望在非常大规模的数据上预训练我们的图像分类模型。
我们在包含1.7百万个示例的大型AudioSet数据集上取得了强大的结果,其中Perceiver在音频、视频以及两者结合方面与最新的最先进方法竞争。
在ImageNet上,该模型的表现与ResNet-50和ViT相当。
当比较论文中考虑的所有不同模态和组合时,Perceiver在整体上表现最佳。
虽然我们减少了模型中模态特定先验知识的使用量,但我们仍然采用了模态特定的增强和位置编码。
端到端的模态无关学习仍然是一个有趣的研究方向。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【论文笔记】Perceiver: General Perception with Iterative Attention

发表评论 取消回复