英伟达的 GPU 架构演进之路充满了创新与突破。
©作者|Zane
来源|神州问学
一、 英伟达GPU的架构演进之路
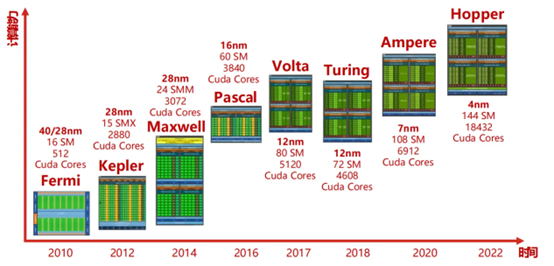
1999 年,英伟达发布 Geforce256 图形处理芯片,首次提出 GPU 概念。早期的架构如 G80 或 GeForce 8800 GTX,包含 8 个 TPC,每一个 TPC 中有两个 SM,一共有 16 个 SM。随着技术的发展,GT200 或 GeForceGTX 280 增加了 TPC 中的 SM 数量。2012 年,Kepler 架构推出,从这一架构开始,NVIDIA 以往坚持的 Core:Shader = 1:2 的分频模式消失,SM 单元中的 CUDA 核心数大幅提升,如每组 SM 单元的 CUDA 核心数从 GF100 时代的 32 个提升到了 Kepler 时代的 192 个。同时,纹理单元、前端渲染单元等也相应增加,而且核心频率达到 1GHz 以上,不再需要 Shader 异步,降低了显卡功耗。2017 年,Volta 架构引入了 Tensor Core,专门用于执行张量计算,支持并行执行 FP32 与 INT32 运算,为人工智能和机器学习工作带来了巨大的性能提升。2018 年,Turing 架构引入 RT Core,负责处理光线追踪加速。2020 年,Ampere 架构进一步提高了 FP32 着色器操作数量、RT Cores 的光线 / 三角形相交测试吞吐量,并加速稀疏神经网络处理速度。例如在完整 GA102 核心中,总共有 92 个 SM,每个 SM 包含 128 个 CUDA 核心、4 个 Tensor 核心和 1 个 RT 核心。今年,英伟达又公布了新一代 AI 芯片架构 Blackwell,集成 2080 亿颗晶体管,采用定制台积电 4NP 工艺,采用统一内存架构 + 双芯配置,共有 192GB HBM3e 内存、8TB/s 显存带宽,单卡 AI 训练算力可达 20PFLOPS,其性能堪称强大。
二、 架构演进对模型推理速度的影响

(一)计算核心的变化
首选我们需要先对GPU和CPU有一个直观的认识,如以下2张图片:
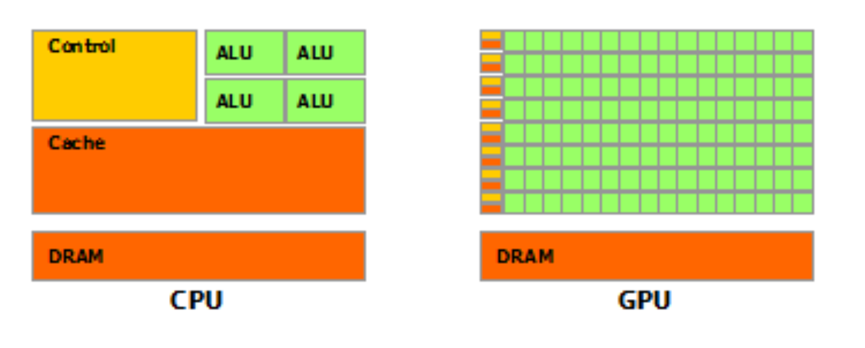
可以看到在GPU中由于存储器的发展慢与处理器,所以在CPU上发展出了多级缓存的接口,而在GPU中也存在类似的缓存接口。只是GPU中将更多的晶体管用于数值计算而不是缓存和流控制,在上边的图中可以看到GPU的Core数量要远远多于CPU,但是Cache和Control则少于CPU,这就使得GPU的单Core的自由度要远远小于CPU会收到诸多的限制,比如在一行中有多个Core却只有1个Control和1个Cache,这就代表多个Core在同一时间只能执行同样的指令这种模型被称为SIMT (Single Instruction Multiple Threads),所以从这个架构出发我们就会发现Cache和Control的缺失,只有计算密集型和数据并行的程序适合GPU。
所以在一个的英伟达GPU中资源主要分为SM大核,全局显存,全局缓存和CPU接口,而其中SM大核的设计也是从英伟达在2010年推出的Fermi架构后才出现。而对于当下的大模型来说我们在看一个显卡的性能时更多关注的指标可以分为:计算能力通常以TFLOPS(每秒万亿次浮点运算)衡量、显存容量、显存带宽、核心数量、内存类型和速度、并行处理能力、功耗、散热性能、IO性能等多个方面。
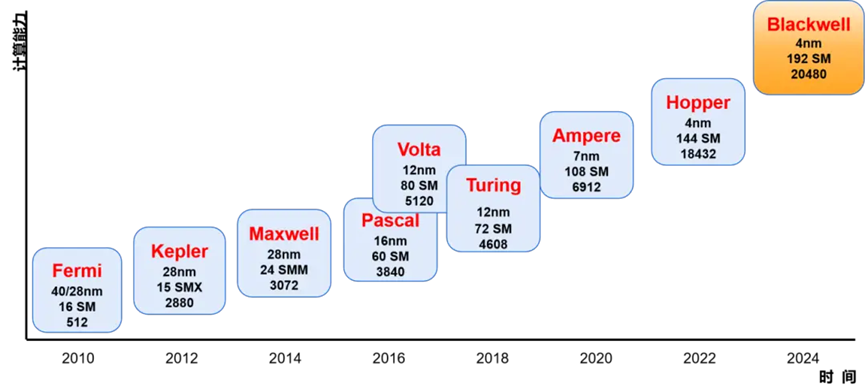
英伟达不同架构下的 GPU,其性能变化对模型推理速度有着显著的具体影响。在计算能力方面,从早期架构到如今的先进架构,CUDA 核心数量不断增加,如从 Kepler 架构开始,SM 单元中的 CUDA 核心数大幅提升,这使得通用计算能力得到极大增强。对于模型推理来说,更多的 CUDA 核心意味着可以同时处理更多的计算任务,从而加快推理速度。以深度学习中的矩阵乘法和卷积运算为例,大量的 CUDA 核心能够快速完成这些计算密集型任务,提高模型的推理效率。
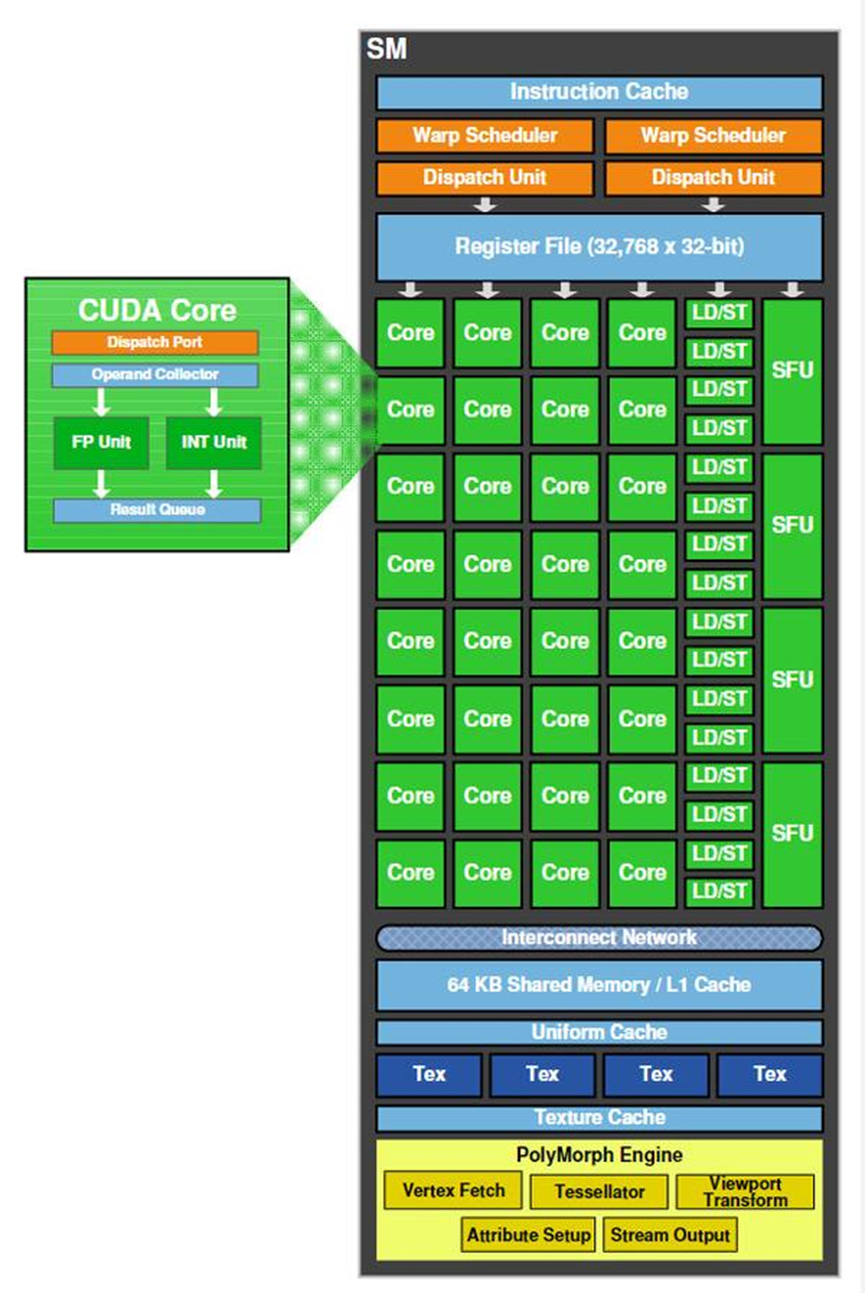
在早期的Fermi架构中存在16个SMs,而每个SM则带32个CUDA Cores,则整张卡上有512个CUDA Core,当然这个数量并不是固定的还和具体的型号有关系。
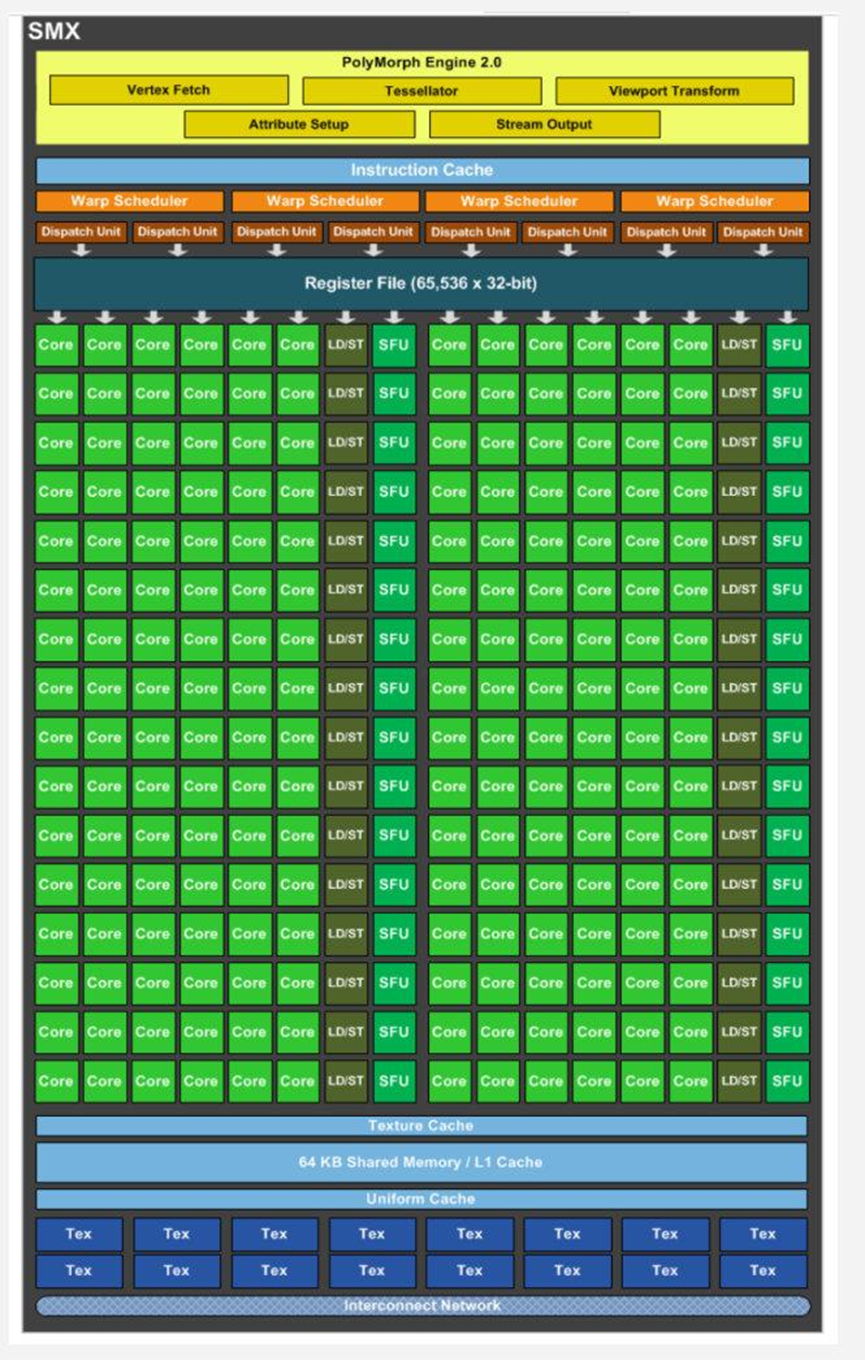
而在2012年发布的Kepler架构中则将SM改改为了SMX,同时在改架构中则加入了GPUDirect技术,该技术可以绕过CPU和System Mermory完成与本机的其他GPU或者其他机器GPU直接数据交换。
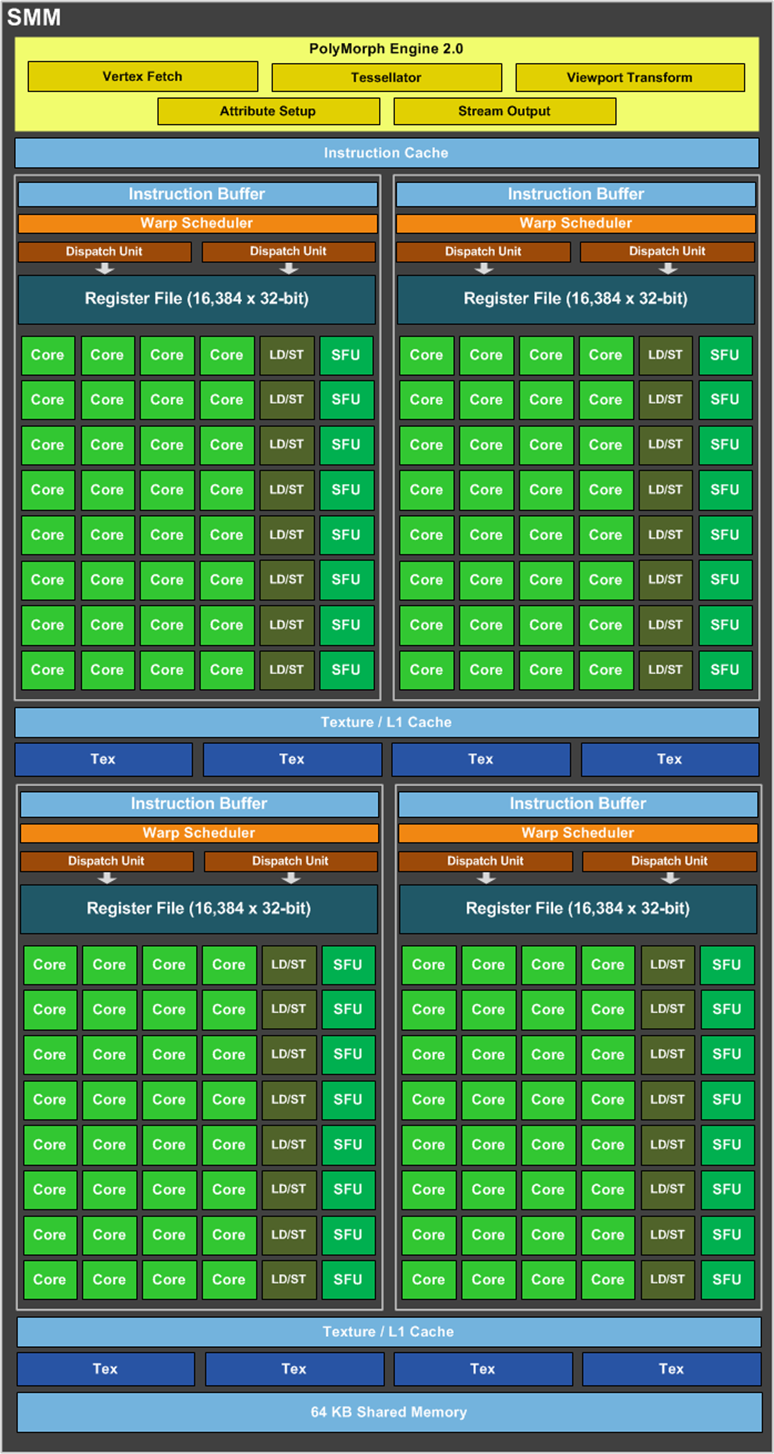
而在2014年的Maxwell架构中,则将SM改为了SMM,Core核心也变的更多了。

而在2016年的Pascal架构则是第一个考虑DeepLearning的架构,在这个架构中相较于的Maxwell和Kepler中减少了FP32的CUDA Core数量,只有64个,但是却增加了32个FP64的CUDA Core并且FP32的CUDA Core具备了FP16的处理能力,且吞吐量是FP32的两倍。同时这个版本引入了NVLink,而NVLink的引入则解决了PCIe的带宽瓶颈问题,NVLink直接在单机内进行GPU点到点通信带宽达到了160GB/s,大约是PCIe3x16的5倍。
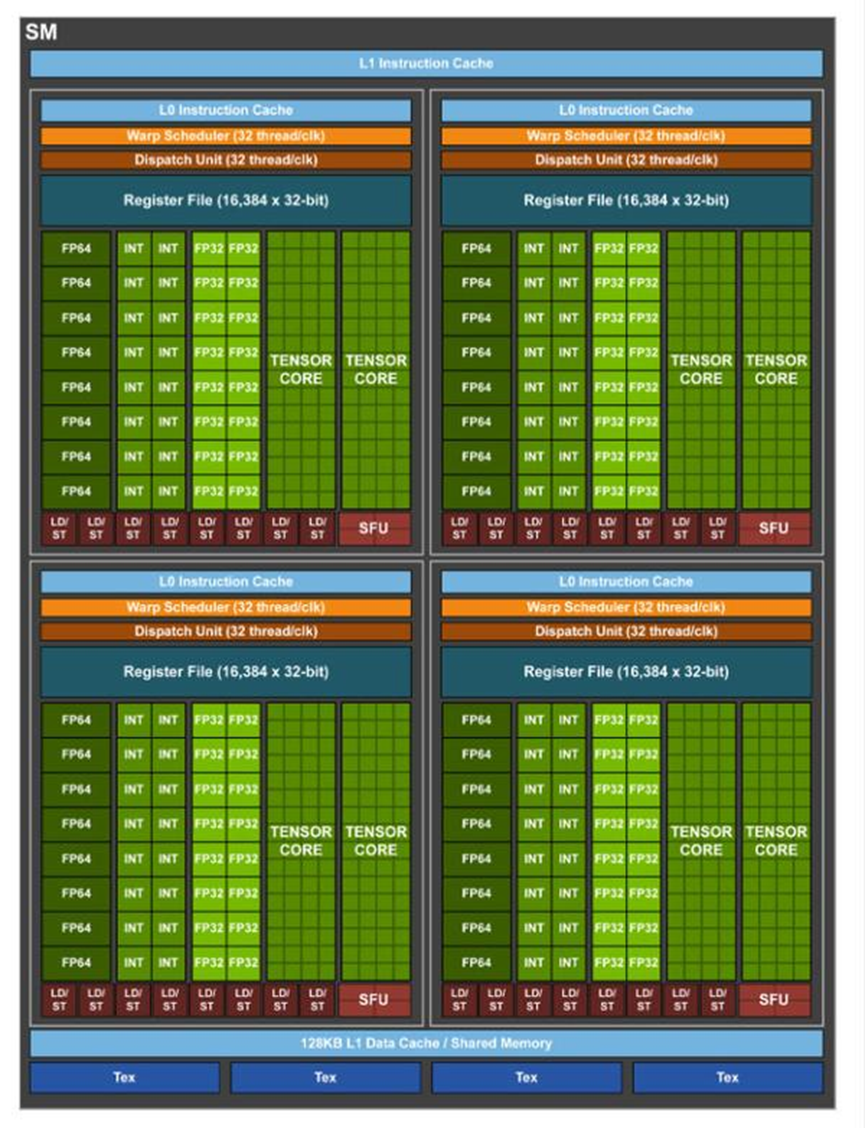
而在2017年的Volta架构中,则以DeepLearning为核心,一如既往的增加了单个SM的核心数,将原本的CUDA Core拆分为了FP32 CUDA Core和INT32 CUDA Core,这意味着可以同时执行FP32和INT32的操作。
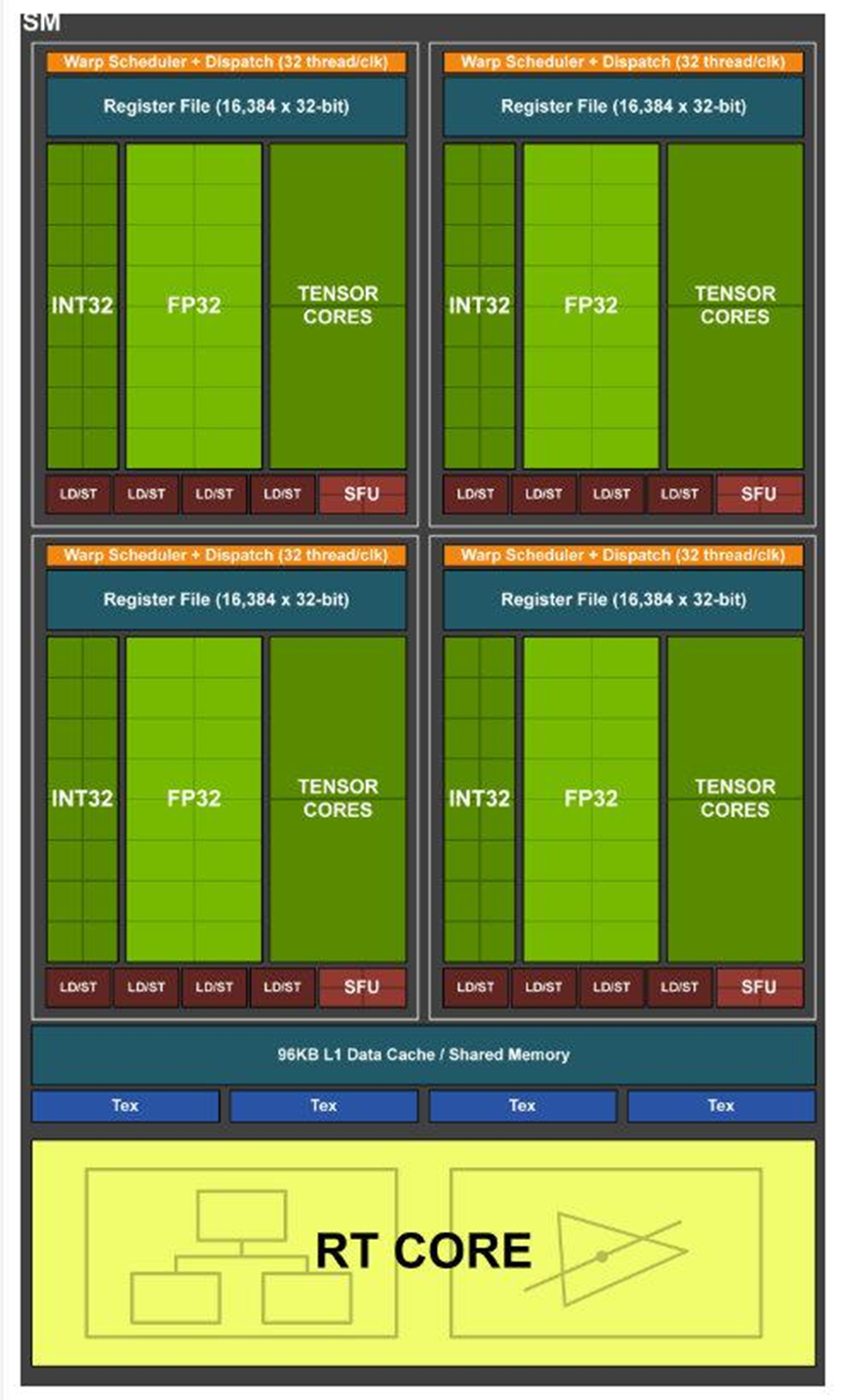
在2108年的Turing架构中依然是增加了各个参数,更加重要的是增加了RT Core全名Ray Tracing Core光线追踪模拟器,将试试管线追踪运算提升到了上一代的25倍,但是去除了对FP64的计算支持,但是增加了对INT8/INT4/Binary的支持。而也是在这个版本深度学习模型的量化部署也渐渐成熟。
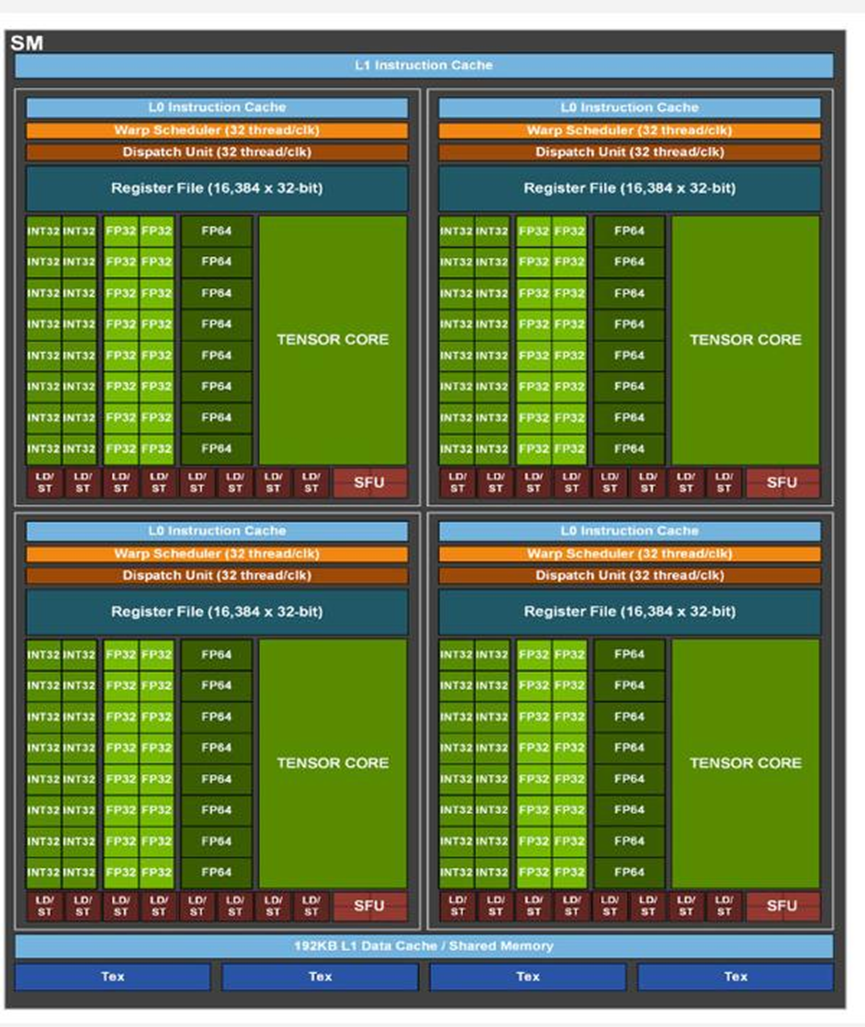
在2020年推出的Ampere架构中最核心的是升级了Tensor Core,除了在Volta的FP16以及在Turing中的INT8/INT4/Binary这个版本还新加入了TF32,BF16,并重新支持了FP64。

而在2024年的3月份英伟达推出的Blackwell架构中更是引入了FP4和FP6的精度,新的精度计算的引入则将进一步减少模型的计算和存储。而新的精度FP4和FP6精度计算的加入则将会更加助力大参数模型的量化部署深入。
(二)显存架构的变化
内存带宽也是影响模型推理速度的重要因素。随着架构的演进,内存带宽不断提高。例如,H200 芯片支持高达 48GB 的 GDDR6X 内存,其内存带宽可达 936GB/s,借助 HBM3e 技术,NVIDIA H200 每秒可以提供 4.8TB 的内存容量和 141GB 的内存带宽。对比 H100 的 SXM 版本,显存从 80GB 提升 76%,带宽从每秒 3.35TB 提升了 43%。内存带宽的增加意味着数据传输速度更快,在模型推理过程中,能够更迅速地将数据从内存传输到计算单元,减少数据等待时间,从而提高推理速度。对于大规模的模型,如具有 700 亿参数的 Llama 2 大模型,更高的内存带宽可以确保高效地访问和操作数据,使得 H200 的推理速度比 H100 快一倍,并且推理能耗降低了一半。
(三)数据交换架构的变化
在早期的NVIDIA架构中,则是使用PCIe总线标准,而随着时代的发展PCIe协议也是渐渐的推出了更多的版本,而到目前为止PCIe则是已经推出到了6.0的标准。
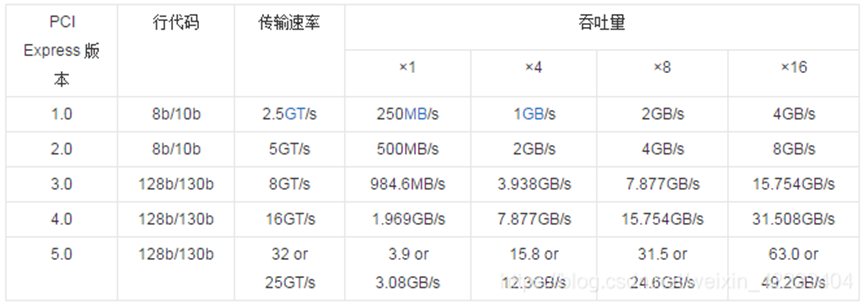
而目前大部分已经实装的硬件目前只支持到了PCIe 5.0版本,PCIe 6则仅仅是推出了规范,目前还没有具体落地的硬件,而在PCIe 6.0的规范中带宽则相较于5.0相当于翻倍提升,在x16下带宽可以达到128GB。而目前的NVIDIA推出的PCIe版本的显卡则最高支持PCIe5.0版本例如H100,而H100在PCIe5.0的下的数据传输速度达到了128GB/s, 所以在面对大数据量的并行计算时PCIe则可能成为瓶颈。
而为了解决PCIe协议数据传输速度慢的限制,NVIDIA则在2016年的Pascal架构中引入了NVLink,NVIDIA提供的NVLink用以单机内多GPU内的点到点的通信,带宽达到了160GB/s,大约5倍于PCIe3.0 x16。
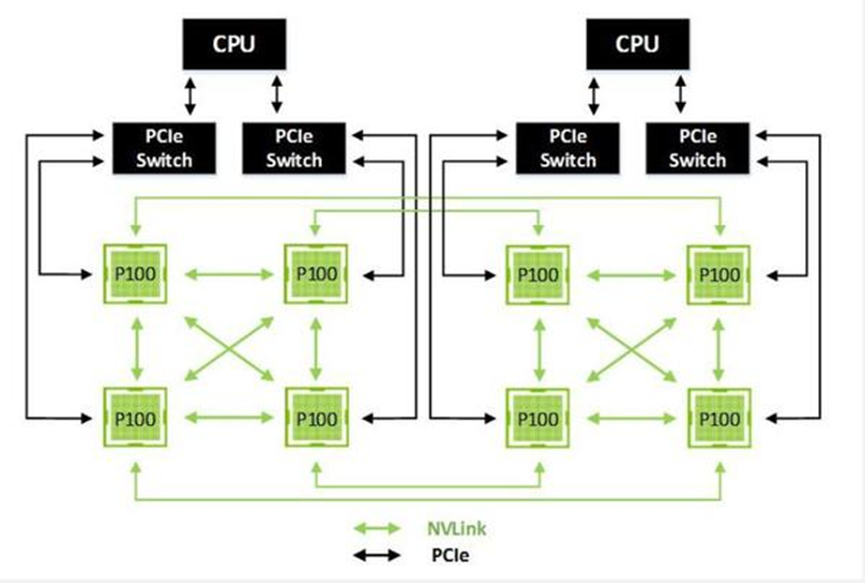
而在2017年的Volta架构中NVLink则变得更快,每个链接提供双向格子25GB/s的带宽,并且一个GPU可以链接6个NVLink,而Pascal则只能链接4个。
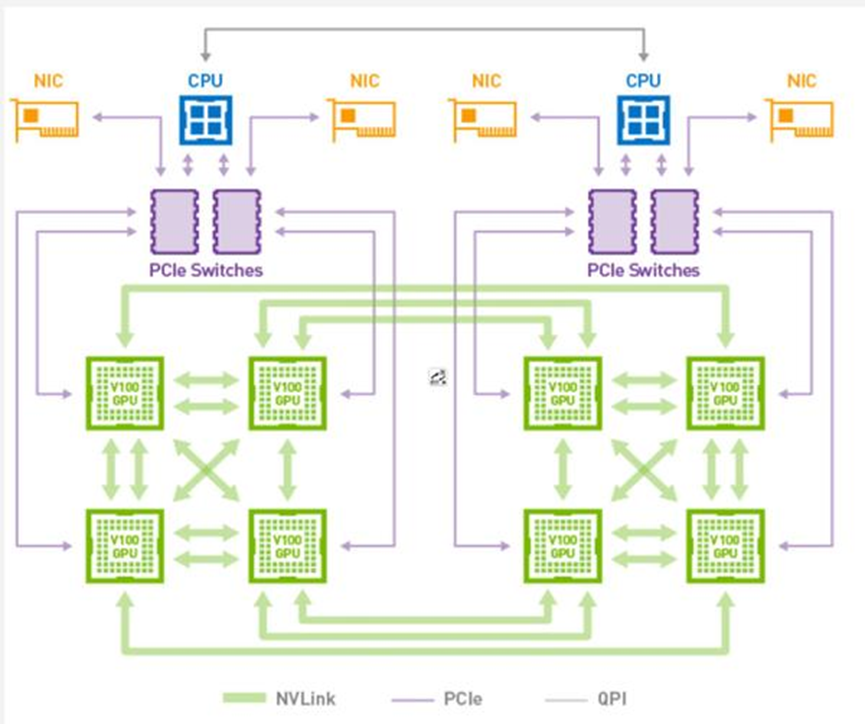
当然也并不是所有的场景都适合NVLink的,PCIe的GPU的优势主要体现在其出色的灵活性和实用性,对于工作负载小、追求GPU数量平活配置的场景,PCIe版的GPU无疑是个更好的选择,而对于GPU间互联带宽有着极高需求的大规模AI模型的训练任务,SXM版的GPU凭借其无可匹敌的NVLink宽带和极致的性能则成为首要选择。
(四)新技术的推动
CuLitho 等新技术为芯片设计制造带来了重大变革,进而对模型推理速度产生积极影响。CuLitho 在 GPU 上运行,其性能比目前的光刻技术提高了 40 倍,可以加速目前每年消耗数百亿个 CPU 小时的大规模计算工作负载。在芯片制造过程中,计算光刻模拟了光通过原件与光刻胶相互作用时的行为,这是芯片设计制造领域中需要算力最多的任务。英伟达通过新的算法,允许越来越复杂的计算光刻工作流程在 GPU 上并行执行,将制造 H100 需要的 89 块掩膜版的计算时间从在 CPU 上运算的两周减少到八小时。这意味着芯片的生产效率大大提高,能够更快地推出性能更强大的 GPU 产品。
对于模型推理来说,更高效的芯片制造技术可以带来更高的芯片性能和稳定性。例如,H100 和 H200 等芯片在设计和制造过程中可以更好地优化计算单元和内存架构,提高计算能力和内存带宽,从而直接提升模型推理速度。同时,新技术的应用也有助于降低芯片的功耗,提高能源效率,使得在相同的能源消耗下可以进行更多的计算任务,进一步加快模型推理速度。
(五)不同架构产品对比
以 H100 和 H200 为例,这两款芯片都是英伟达在不同 GPU 架构下的代表产品,它们在模型推理速度上存在明显差异。H200 在多个方面进行了升级,相较于 H100,H200 具备超过 460 万亿次的浮点运算能力,可支持大规模的 AI 模型训练和复杂计算任务。在内存方面,H200 是首款提供 HBM3e 的 GPU,HBM3e 是更快、更大的内存,可加速生成式 AI 和大型语言模型。借助 HBM3e 技术的支持,H200 能够显著提升性能。在处理 Llama-70B 推理性能时,H200 比 H100 提升近两倍;对于具有 700 亿参数的 Llama 2 大模型,H200 的推理速度比 H100 快一倍,并且推理能耗降低了一半。此外,H200 在 Llama 2 和 GPT-3.5 大模型上的输出速度分别是 H100 的 1.9 倍和 1.6 倍。
造成这种差异的原因主要有以下几点:首先,H200 的内存带宽更大。H200 的内存带宽从 H100 的每秒 3.35TB 提升到了 4.8TB,更高的内存带宽可以确保在模型推理过程中数据能够更快速地传输,减少数据等待时间,提高推理效率。其次,H200 的显存容量更大。H200 的显存从 H100 的 80GB 提升到了 141GB,更大的显存容量可以容纳更大规模的模型和数据,减少数据在内存和硬盘之间的交换次数,从而提高推理速度。最后,H200 采用了更先进的架构和技术,如 HBM3e 内存技术和更强大的 AI 加速器,这些技术的应用使得 H200 在模型推理方面具有更出色的性能表现。
三、 未来展望

(一)技术发展趋势
随着人工智能和机器学习的不断发展,英伟达 GPU 架构在模型推理速度方面将继续保持快速的发展态势。一方面,芯片制造工艺将不断进步,如台积电等代工厂将持续推出更先进的制程技术,为英伟达 GPU 提供更高的集成度和更低的功耗。这将使得英伟达能够在相同尺寸的芯片上集成更多的晶体管和计算单元,进一步提高 GPU 的性能和推理速度。
另一方面,软件优化也将成为提升模型推理速度的重要手段。英伟达将不断改进其 CUDA 平台和深度学习框架,如 TensorRT 和 PyTorch,以更好地利用 GPU 的硬件特性,提高模型的推理效率。例如,通过优化算法和数据结构,减少内存访问延迟和计算开销,从而加速模型的推理过程。
此外,英伟达还将继续投入研发新的技术和架构,如量子计算和神经形态计算。虽然这些技术目前还处于早期阶段,但它们具有巨大的潜力,可以为未来的模型推理速度带来革命性的提升。
(二)市场需求驱动
随着生成式 AI、多模态人工智能和视频处理等领域的快速发展,对模型推理速度的需求将不断增加。英伟达 GPU 架构将在这些领域发挥重要作用,为用户提供更快速、更高效的计算解决方案。
例如,在生成式 AI 领域,需要快速处理大量的文本、图像和音频数据,以生成高质量的内容。英伟达 GPU 的强大计算能力和高效的模型推理速度将使得生成式 AI 应用能够更快地响应用户需求,提高用户体验。
在多模态人工智能领域,需要同时处理多种类型的数据,如文本、图像、音频和视频。英伟达 GPU 的并行计算能力和高速的内存带宽将使得多模态人工智能应用能够更快速地融合不同类型的数据,提高模型的准确性和推理速度。
在视频处理领域,需要实时处理高分辨率的视频流,以实现视频分析、目标检测和跟踪等任务。英伟达 GPU 的高性能计算能力和低延迟的推理速度将使得视频处理应用能够更快速地处理视频数据,提高视频处理的效率和质量。
(三)竞争与合作
在未来,英伟达将面临来自其他芯片厂商和技术的竞争。例如,国产 ASIC 芯片架构在推理速度和功耗控制方面具有显著优势,可能会对英伟达 GPU 架构构成挑战。此外,像 Cerebras 这样的创业公司也在推出创新的 AI 推理芯片,挑战英伟达在 AI 芯片市场的地位。
然而,竞争也将促进合作。英伟达可以与其他芯片厂商、软件开发商和云服务提供商合作,共同推动人工智能和机器学习的发展。例如,英伟达可以与国产芯片厂商合作,共同开发适用于中国市场的 AI 芯片和解决方案,实现优势互补,共同开拓市场。
同时,英伟达还可以与学术界和研究机构合作,共同开展前沿技术的研究和开发。通过合作,英伟达可以获取更多的创新思路和技术资源,为其 GPU 架构的未来发展提供支持。
总之,英伟达 GPU 架构在模型推理速度方面具有巨大的发展潜力。未来,英伟达将继续投入研发,不断推出更先进的技术和产品,满足市场对模型推理速度的不断增长的需求。同时,英伟达也将面临来自其他芯片厂商和技术的竞争,需要通过不断创新和合作,保持其在人工智能和机器学习领域的领先地位。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 英伟达 GPU 架构:演进与模型推理速度的深度关联

发表评论 取消回复