github地址:https://github.com/infinilabs/analysis-pinyin(各种版本,对接es版本)
拼音分词器存在的问题:
1、是直接将每个字的拼音返回和一段话的拼音首字母返回,不能很好的分词。
2、不会保留中文,转为拼音之后,没有中文存在。
自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
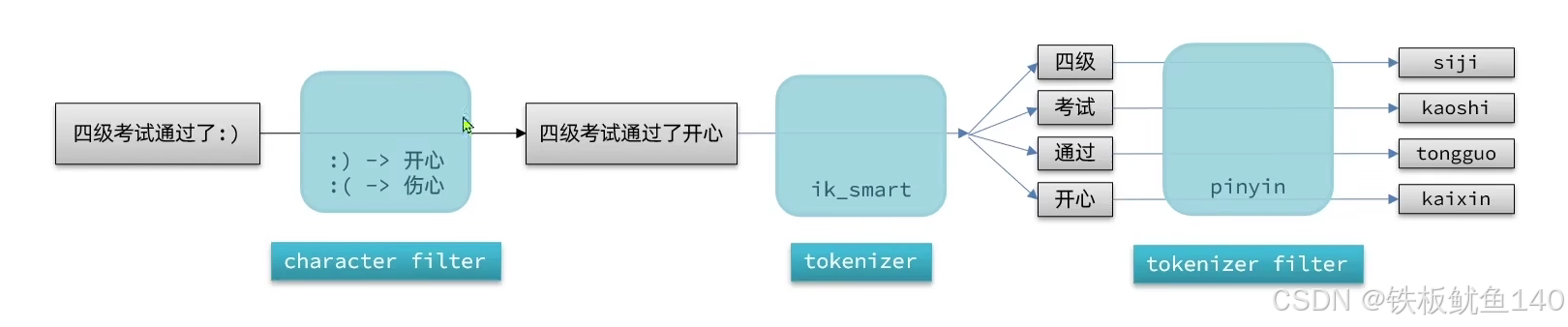
elasticsearch中分词器(analyzer)的组成包含三部分:
1、 character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
2、tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
3、tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
自定义分词器的配置:(只能是相应的索引库使用,创建了test索引库,那么自定义的只能在这个索引库中使用。不能在其他索引库中使用)
#自定义分词器,在ik和py的基础上自定义
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word", #分词用ik
"filter": "py" #配置拼音分词器
}
},
"filter": {
"py": {
"type": "pinyin", #拼音分词器
"keep_full_pinyin": false, # 关闭了单个字符的转为拼音
"keep_joined_full_pinyin": true, #开启了词语的拼音转换
"keep_original": true, #保留中文
"limit_first_letter_length": 16, #首字母的长度小于16
"remove_duplicated_term": true, #去除重复的
"none_chinese_pinyin_tokenize": false #禁止除中文以为的其他语言转为拼音
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}为了避免搜索的时候使用拼音搜到同音词,所以在搜索的时候使用ik分词器"search_analyzer": "ik_smart"
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » es拼音分词器(仅供自己参考)

发表评论 取消回复