快来参与讨论,点赞、收藏⭐、分享,共创活力社区。

目录
3.2当arr[right] == arr[keyi]时,要不要交换?
前言
在排序算法的领域中,快速排序是一种被广泛应用且高效的算法。它有多种实现方式,其中 Hoare 版本、挖坑法和前后指针版本是比较常见且具有代表性的。这些方法在实现思路和细节上各有特点,深入理解它们对于掌握快速排序算法至关重要。
快速排序基础概念
快速排序是一种基于分治策略的排序算法。它的基本思想是选择一个基准元素(pivot),将数组分为两部分,使得左边部分的元素都小于等于基准元素,右边部分的元素都大于等于基准元素。然后对左右两部分分别递归地进行排序,直到整个数组有序。
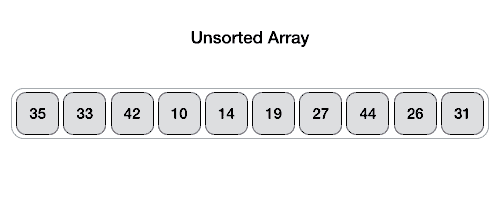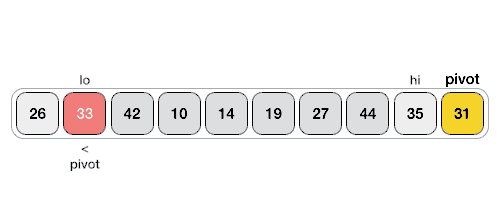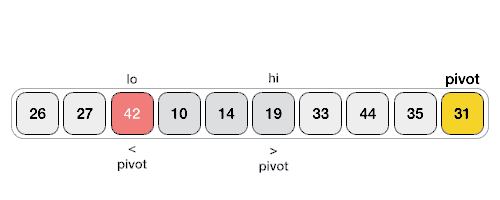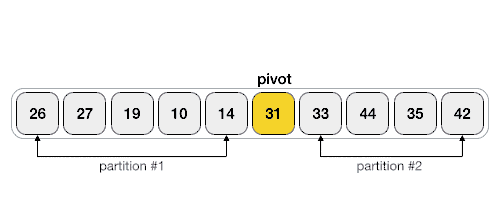
- 以下动画表示解释了如何在数组中找到基准元素(pivot):
Hoare 版本
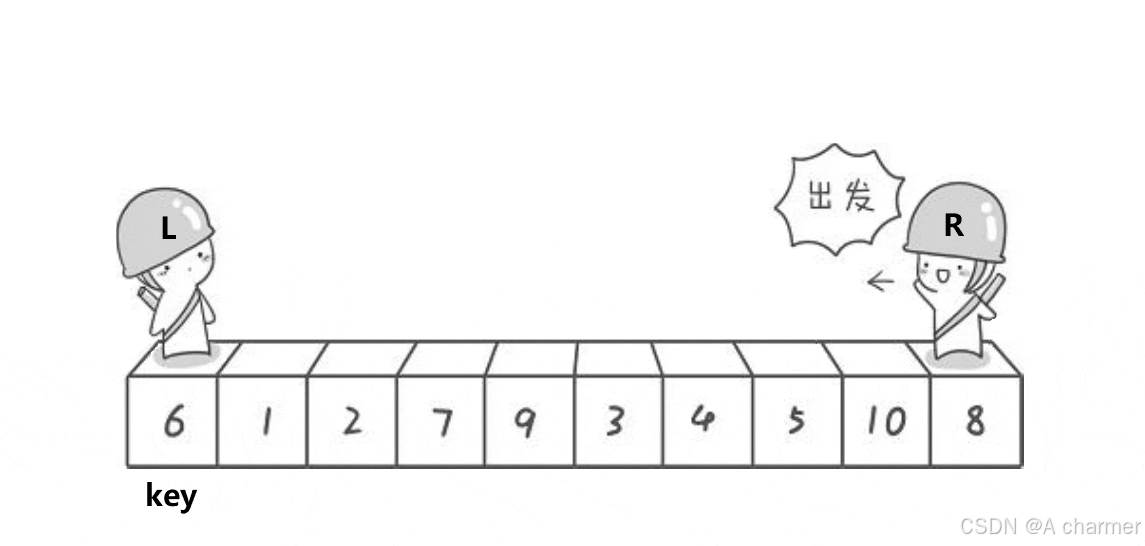
1.算法思路
- Hoare 版本的快速排序首先选择一个基准元素,通常是数组的第一个元素。然后设置两个指针,一个指针
left从数组的左端开始向右移动,另一个指针right从数组的右端开始向左移动。- 当
left指向的元素小于基准元素时,left指针继续向右移动。当right指向的元素大于基准元素时,right指针继续向左移动。- 当
left指向的元素大于等于基准元素且right指向的元素小于等于基准元素时,交换这两个元素。- 重复上述移动指针和交换元素的操作,直到
left和right指针相遇。最后将基准元素与left(或right)指针指向的元素交换,此时基准元素就处于它在排序后的正确位置。
2.代码示例
int _QuickSort(int* arr, int left, int right)
{
int keyi = left;
++left;
while (left <= right)
{
//right:从右往左找比基准值要小的数据
while (left <= right && arr[right] > arr[keyi])//要不要让arr[right] == arr[keyi],要不要交换?
{
right--;
}
//left:从左往右找比基准值要大的数据
while (left <= right && arr[left] < arr[keyi])
{
left++;
}
//left和right交换
if (left <= right)
{
Swap(&arr[left++], &arr[right--]);
}
}
//keyi 和 right交换
Swap(&arr[keyi], &arr[right]);
return right;
}
//快速排序
void QuickSort(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
//找基准值
int keyi = _QuickSort(arr, left, right);
//二分
// [left,keyi-1 ] keyi [keyi+1,right]
//[0,2][4,5]
QuickSort(arr, left, keyi - 1);
QuickSort(arr, keyi + 1, right);
}3.有关该代码的问题
3.1为什么right一定是比keyi值小?
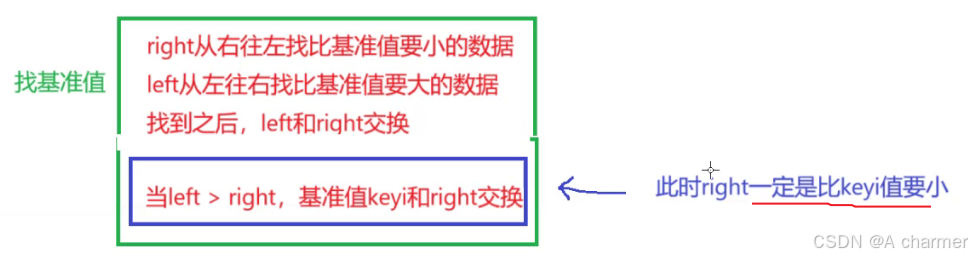
- 相遇点比基准值大时
- 相遇点比基准值小时

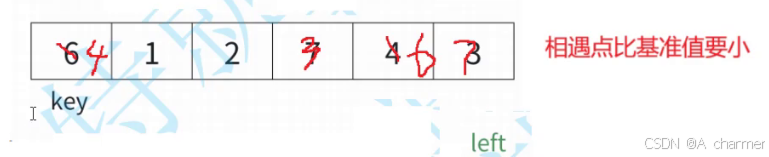
3.2当arr[right] == arr[keyi]时,要不要交换?
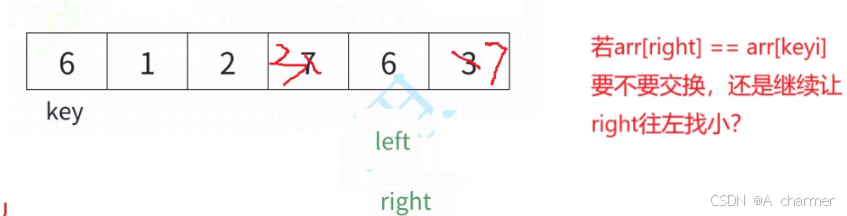
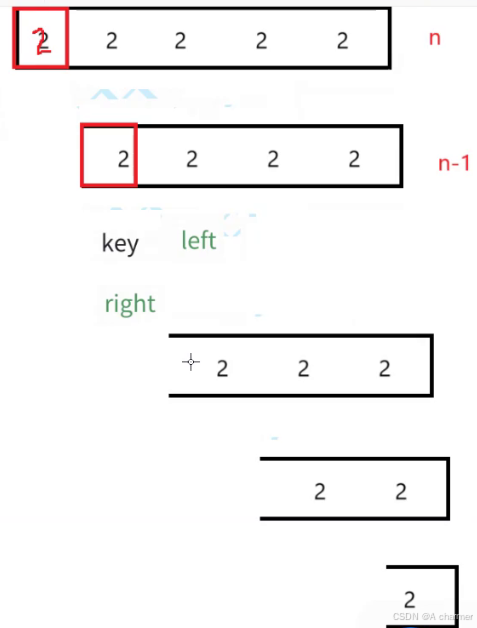
当数组的元素全是一个数字时:
一、不进行交换
如果不进行交换,即当arr[right] == arr[keyi]时不满足循环条件,跳出内层循环继续寻找其他满足条件的位置。
- 优点:在一些情况下可以减少不必要的交换操作,尤其是当数组中存在大量重复元素时,可能会减少一些无意义的移动,提高算法的效率。
- 缺点:可能会导致分区不够均衡,特别是当重复元素较多且集中在一侧时,可能会使快速排序退化为接近的时间复杂度
。例如,如果所有元素都与基准值相等,那么每次分区只会减少一个元素,递归深度将接近数组的长度,效率大大降低。
二、进行交换
如果进行交换,即当arr[right] == arr[keyi]时也被视为满足条件,可以进行交换操作。
- 优点:可以使分区更加均衡,避免出现极端情况。对于包含大量重复元素的数组,也能更好地进行分区,减少最坏情况的发生概率,保证快速排序的平均性能。
- 缺点:可能会增加一些不必要的交换操作,当重复元素较多时,可能会进行一些多余的交换,略微降低算法的效率。
挖坑法
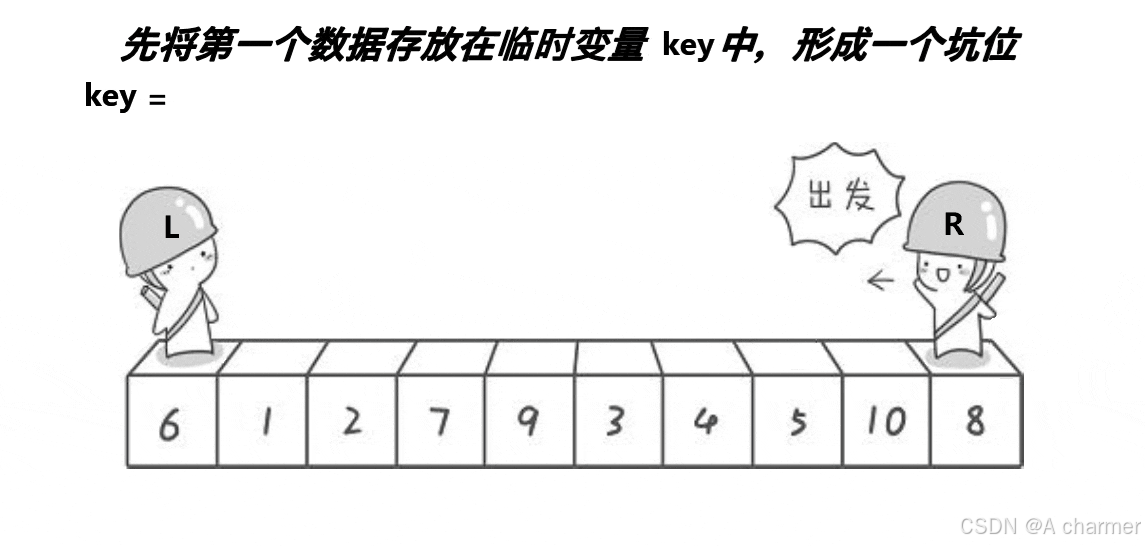
1.算法思路
- 挖坑法首先选择一个基准元素,通常也是数组的第一个元素,并将其保存起来,这个位置就形成了一个 “坑”。
- 同样设置两个指针
left从左端开始向右移动,right从右端开始向左移动。- 当
left指向的元素小于基准元素时,left指针继续向右移动。当right指向的元素大于基准元素时,right指针继续向左移动。- 当
left指向的元素大于等于基准元素且right指向的元素小于等于基准元素时,将right指向的元素放入 “坑” 中,并将right所在的位置标记为新的 “坑”。这一步是为了将小于基准的元素通过填充 “坑” 的方式放在左边,大于基准的元素放在右边。- 重复上述操作,直到
left和right指针相遇。最后将保存的基准元素放入 “坑” 中,此时基准元素就处于它在排序后的正确位置。
2.代码示例
// 挖坑法
int PartSort2(int* a, int left, int right)
{
// 选取最左边的元素作为基准值
int key = a[left];
// 将最左边的位置标记为“坑”
int hole = left;
while (left < right)
{
// 右边找小
while (left < right && a[right] >= key)
--right;
// 将找到的比基准值小的元素填入“坑”中
a[hole] = a[right];
// 更新“坑”的位置为该元素原来的位置
hole = right;
// 左边找大
while (left < right && a[left] <= key)
++left;
// 将找到的比基准值大的元素填入“坑”中
a[hole] = a[left];
// 更新“坑”的位置为该元素原来的位置
hole = left;
}
// 将基准值填入最终的“坑”中
a[hole] = key;
// 返回基准值的最终位置
return hole;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
// 调用分区函数找到基准值的索引
int keyi = PartSort2(a, left, right);
// 对基准值左边的子数组进行递归排序
QuickSort(a, left, keyi - 1);
// 对基准值右边的子数组进行递归排序
QuickSort(a, keyi + 1, right);
}前后指针版本
1.算法思路
- 前后指针版本首先选择一个基准元素,通常是数组的第一个元素。然后设置一个前指针
prev从数组的第二个元素开始,一个后指针end从数组的最后一个元素开始。- 前指针
prev不断向右移动,直到找到一个大于等于基准元素的元素。后指针end不断向左移动,直到找到一个小于等于基准元素的元素。- 如果前指针
prev小于后指针end,则交换这两个指针指向的元素。这一步是为了将小于基准的元素放在左边,大于基准的元素放在右边。- 重复上述操作,直到前指针
prev和后指针end相遇。最后将基准元素与后指针end指向的元素交换,此时基准元素就处于它在排序后的正确位置。
2.代码示例
#include <iostream>
#include <algorithm>
using namespace std;
// 分区函数,实现前后指针版本的划分
int partitionTwoPointers(int arr[], int low, int high) {
int pivot = arr[low];
int prev = low + 1;
int end = high;
while (prev <= end) {
// 从前向后找大于等于基准的元素
while (prev <= end && arr[prev] <= pivot) prev++;
// 从后向前找小于等于基准的元素
while (prev <= end && arr[end] >= pivot) end--;
if (prev < end) swap(arr[prev], arr[end]);
}
swap(arr[low], arr[end]);
return end;
}
// 快速排序函数,使用前后指针版本的分区
void quickSortTwoPointers(int arr[], int low, int high) {
if (low < high) {
int pivotIndex = partitionTwoPointers(arr, low, high);
// 对基准元素左边的子数组进行排序
quickSortTwoPointers(arr, low, pivotIndex - 1);
// 对基准元素右边的子数组进行排序
quickSortTwoPointers(arr, pivotIndex + 1, high);
}
}时间复杂度分析
- 最坏情况:当每次划分选取的基准元素都是当前子序列中的最大或最小元素时,划分得到的两个子序列一个为空,另一个子序列的长度为
。此时,快速排序退化为冒泡排序,时间复杂度为
- 最好情况:每次划分都能将序列均匀地分成两个子序列,此时时间复杂度为
。
- 平均情况:快速排序的平均时间复杂度为
总结
快速排序的 Hoare 版本、挖坑法和前后指针版本都是基于分治思想的高效排序算法实现方式。它们在平均情况下时间复杂度都为

以后我将深入研究继承、多态、模板等特性,并将默认成员函数与这些特性结合,以解决更复杂编程问题!欢迎关注我【A Charmer】

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 手撕快排的三种方法:让面试官对你刮目相看

发表评论 取消回复