MapReduce框架原理
MapReduce详细工作流程1
MapReduce详细工作流程2
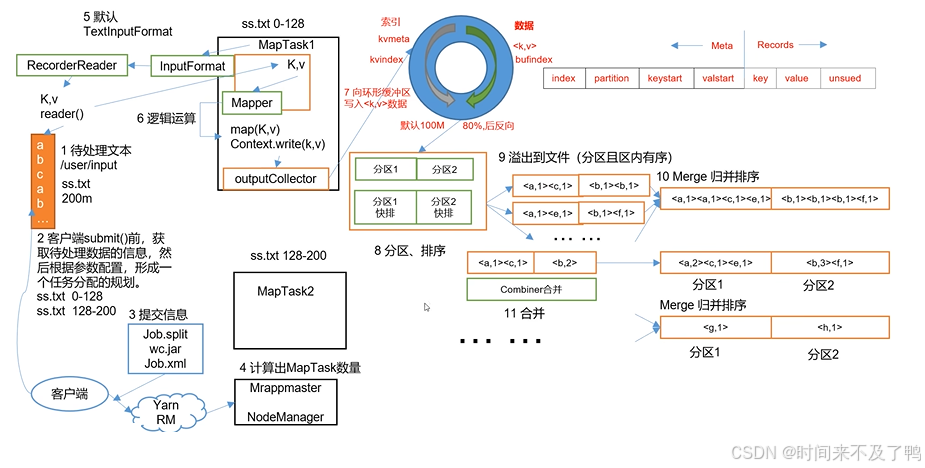
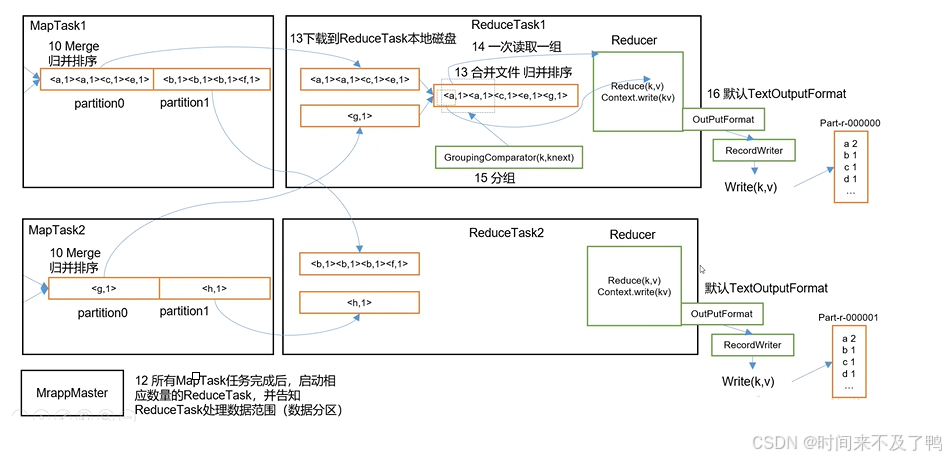
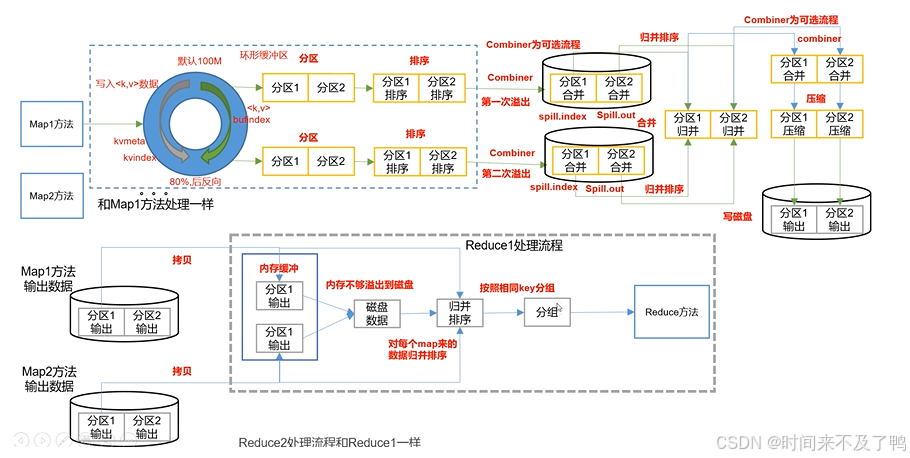
shuffle流程
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
Partition分区
默认分区是根据key的hashCode对ReduceTasks个数取模得到的,用户没法控制哪个key存储到那个分区

需要在driver上加上以下内容才行
分区注意事项
1.如果ReduceTask数量 > getPartition(自己的分区)的结果数, 会产生几个空的文件
2.1 < 如果ReduceTask数量 < getPartition(自己的分区)的结果数, 会报错
3.如果ReduceTask数量= 1, 不管几个分区文件都是1个ReduceTask
4.分区号必须从0开始逐一递增

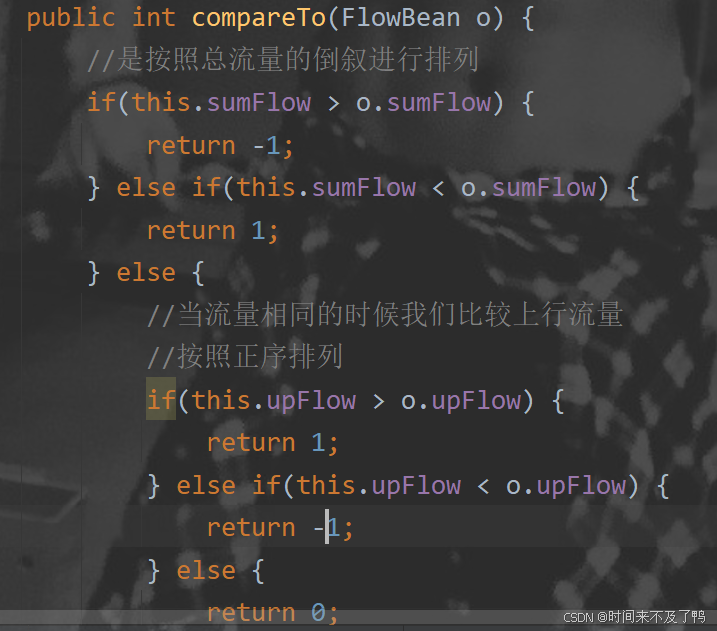
排序—倒序/二次排序/分区内排
加上compareto方法
更改代码
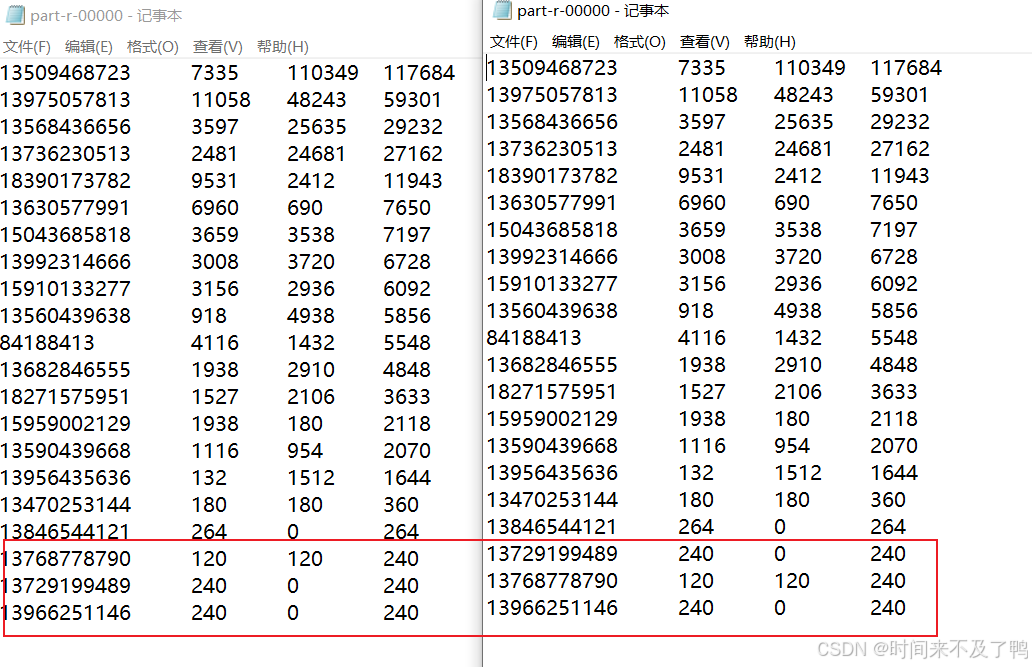
最后结果正序排列了,这称为二次排序
分区内排
在之前的基础上加上分区



本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Hadoop---MapReduce(2)

发表评论 取消回复