目录
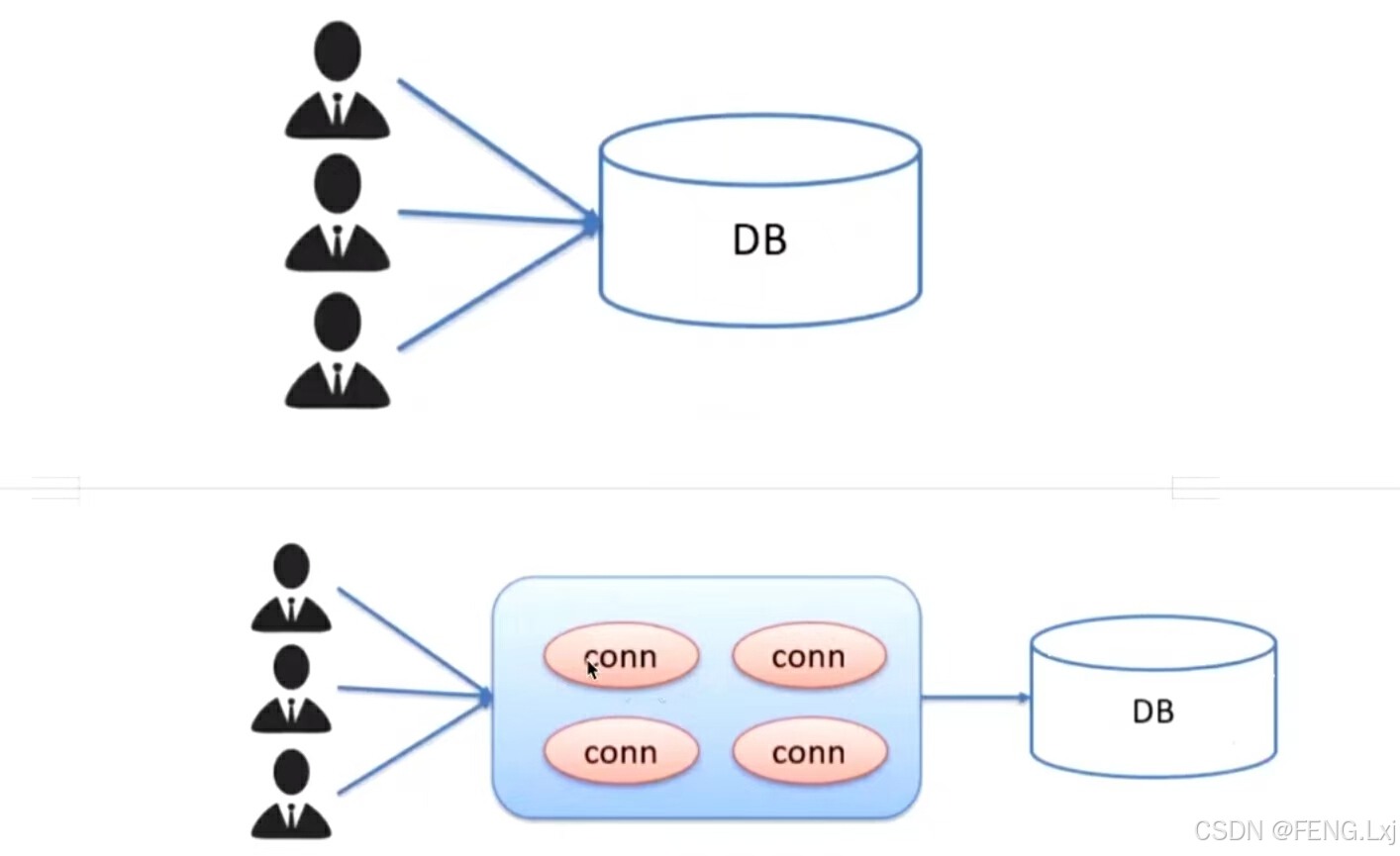
前提:如果我要操作多个表,那么就会产生冗余的JDBC步骤,另一个弊端就是每次都需要数据库连接对象(Connection),获取效率低下,每次使用时都需要先进行连接
前提:如果我要操作多个表,那么就会产生冗余的JDBC步骤,另一个弊端就是每次都需要数据库连接对象(Connection),获取效率低下,每次使用时都需要先进行连接
因此我们可以自己来实现一个数据库连接池,避免每次都需要来写Connection
数据库连接池的特点:
1.数据库连接池是一个容器,负责分配,管理数据库连接
2.它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
3.释放空闲时间超过最大空闲时间的数据库来避免因为没有释放数据库连接而引起的数据库连接泄露
数据库连接池的好处:
1.资源重用
2.提升系统响应速度
3.避免数据库连接遗漏:当其余使用者需要连接而没有链接时,连接池会去判断其余未归还连接的线程池在干什么,如果发现使用者使用完链接后一直不归还,连接池会强制断开连接,此时等待的使用者就可以使用了
对比图:
自己实现连接池过程:
创建一个连接池类:
利用单列模式,确保其他测试类只能获取连接池Pool,而不能new 创建新的连接池
package JDBC.d1102.连接池;
import java.sql.Connection;
import java.util.ArrayList;
import java.util.List;
public class Pools {
private Pools() {
}
private static Pools pools = new Pools();
List<MyConnection> list = new ArrayList<>();
{
for (int i = 0; i < 5; i++) {
MyConnection myConnection = new MyConnection();
// Connection connection = myConnection.getConnection();
list.add(myConnection);
}
}
public static Pools getInstance() {
return pools;
}
public static void main(String[] args) {
Pools instance = Pools.getInstance();
System.out.println(instance.list.size());
}
}
因为Connection 为接口,所以不能new,Connection也不是函数式接口,所以也不能利用匿名内部类来实现,
所以我们来自己写一个连接类:
package JDBC.d1102.连接池;
import java.sql.Connection;
import java.sql.DriverManager;
public class MyConnection extends Connect {
String url = "jdbc:mysql:///study?useSSL=false";
String userName = "root";
String password = "root";
Connection connection = null;
private boolean isUse = false;
private void createConnection() {
try {
Class.forName("com.mysql.jdbc.Driver");
connection = DriverManager.getConnection(url, userName, password);
} catch (Exception e) {
e.printStackTrace();
}
}
public Connection getConnection() {
createConnection();
return connection;
}
public boolean isUsed() {
if (!isUse) {
isUse = true;
return false;
}else{
return isUse;
}
}
public boolean free() {
isUse = false;
return true;
}
}
创建一个 Connect 类来实现Connection连接类,使MyConnection 继承Connect,间接的实现实现Connection连接类,这样Connection类就可以调用MyConnection 中写的方法,用于判断,是否使用同一个连接,(用还是没用,还还是没还)
package JDBC.d1102.连接池;
import java.sql.*;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executor;
public class Connect implements Connection {
@Override
public Statement createStatement() throws SQLException {
return null;
}
@Override
public PreparedStatement prepareStatement(String sql) throws SQLException {
return null;
}
@Override
public CallableStatement prepareCall(String sql) throws SQLException {
return null;
}
@Override
public String nativeSQL(String sql) throws SQLException {
return null;
}
@Override
public void setAutoCommit(boolean autoCommit) throws SQLException {
}
@Override
public boolean getAutoCommit() throws SQLException {
return false;
}
@Override
public void commit() throws SQLException {
}
@Override
public void rollback() throws SQLException {
}
@Override
public void close() throws SQLException {
}
@Override
public boolean isClosed() throws SQLException {
return false;
}
@Override
public DatabaseMetaData getMetaData() throws SQLException {
return null;
}
@Override
public void setReadOnly(boolean readOnly) throws SQLException {
}
@Override
public boolean isReadOnly() throws SQLException {
return false;
}
@Override
public void setCatalog(String catalog) throws SQLException {
}
@Override
public String getCatalog() throws SQLException {
return null;
}
@Override
public void setTransactionIsolation(int level) throws SQLException {
}
@Override
public int getTransactionIsolation() throws SQLException {
return 0;
}
@Override
public SQLWarning getWarnings() throws SQLException {
return null;
}
@Override
public void clearWarnings() throws SQLException {
}
@Override
public Statement createStatement(int resultSetType, int resultSetConcurrency) throws SQLException {
return null;
}
@Override
public PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency) throws SQLException {
return null;
}
@Override
public CallableStatement prepareCall(String sql, int resultSetType, int resultSetConcurrency) throws SQLException {
return null;
}
@Override
public Map<String, Class<?>> getTypeMap() throws SQLException {
return null;
}
@Override
public void setTypeMap(Map<String, Class<?>> map) throws SQLException {
}
@Override
public void setHoldability(int holdability) throws SQLException {
}
@Override
public int getHoldability() throws SQLException {
return 0;
}
@Override
public Savepoint setSavepoint() throws SQLException {
return null;
}
@Override
public Savepoint setSavepoint(String name) throws SQLException {
return null;
}
@Override
public void rollback(Savepoint savepoint) throws SQLException {
}
@Override
public void releaseSavepoint(Savepoint savepoint) throws SQLException {
}
@Override
public Statement createStatement(int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException {
return null;
}
@Override
public PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException {
return null;
}
@Override
public CallableStatement prepareCall(String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException {
return null;
}
@Override
public PreparedStatement prepareStatement(String sql, int autoGeneratedKeys) throws SQLException {
return null;
}
@Override
public PreparedStatement prepareStatement(String sql, int[] columnIndexes) throws SQLException {
return null;
}
@Override
public PreparedStatement prepareStatement(String sql, String[] columnNames) throws SQLException {
return null;
}
@Override
public Clob createClob() throws SQLException {
return null;
}
@Override
public Blob createBlob() throws SQLException {
return null;
}
@Override
public NClob createNClob() throws SQLException {
return null;
}
@Override
public SQLXML createSQLXML() throws SQLException {
return null;
}
@Override
public boolean isValid(int timeout) throws SQLException {
return false;
}
@Override
public void setClientInfo(String name, String value) throws SQLClientInfoException {
}
@Override
public void setClientInfo(Properties properties) throws SQLClientInfoException {
}
@Override
public String getClientInfo(String name) throws SQLException {
return null;
}
@Override
public Properties getClientInfo() throws SQLException {
return null;
}
@Override
public Array createArrayOf(String typeName, Object[] elements) throws SQLException {
return null;
}
@Override
public Struct createStruct(String typeName, Object[] attributes) throws SQLException {
return null;
}
@Override
public void setSchema(String schema) throws SQLException {
}
@Override
public String getSchema() throws SQLException {
return null;
}
@Override
public void abort(Executor executor) throws SQLException {
}
@Override
public void setNetworkTimeout(Executor executor, int milliseconds) throws SQLException {
}
@Override
public int getNetworkTimeout() throws SQLException {
return 0;
}
@Override
public <T> T unwrap(Class<T> iface) throws SQLException {
return null;
}
@Override
public boolean isWrapperFor(Class<?> iface) throws SQLException {
return false;
}
}
实现前面逻辑,我们就可以创建一个连接池测试类:
如果一开始没有获取到连接,可以利用重试机制来再次获取,直到能够获取到连接或者重试获取不到连接池为止
package JDBC.d1102.连接池;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.List;
public class ConnectionPoolTest {
//
public static void main(String[] args) {
// 向t1表中插入一条数据
Pools pools = Pools.getInstance();// 单例模式
List<MyConnection> list = pools.list;
Connection connection = null;
MyConnection myConnection = null;
int i = 1;
while (i <= 10) {
for (MyConnection conn : list) {
// 此种情况代表我获取到了之前没有线程使用的链接,那么我可以用
if (!conn.isUsed()) {
connection = conn.getConnection();
myConnection =conn;
}
}
if (connection == null) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
i++;
}
Statement statement = null;
try {
if (connection == null) {
System.out.println("太忙了,没有空闲的链接");
} else {
statement = connection.createStatement();
String sql = "insert into t1 values(4,4,20)";
int effectRows = statement.executeUpdate(sql);
if (effectRows > 0) {
System.out.println("插入成功");
} else {
System.out.println("插入失败");
}
myConnection.free();
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
利用druid德鲁伊连接池来实现连接池
首先导入德鲁伊jar包
创建一个druid.properties配置类
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///study?useSSL=false&useServerPrepStmts=true
username=root
password=root
# 初始化链接数量
initialSize=5
# 最大链接数量
maxActive=10
#最大等待时间ms
maxWait=3000创建测试类:
package JDBC.d1102.text;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class druidText {
public static void main(String[] args) {
Statement statement = null;
Connection connection = null;
ResultSet resultSet = null;
try {
FileInputStream fileInputStream = new FileInputStream("src/JDBC/d1102/text/druid.properties");
Properties properties = new Properties();
properties.load(fileInputStream);
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
connection= dataSource.getConnection();
statement = connection.createStatement();
String sql = "select * from student";
resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
int s_id = resultSet.getInt("s_id");
String name = resultSet.getString("s_name");
String s_brith = resultSet.getString("s_brith");
String s_sex = resultSet.getString("s_sex");
System.out.println(s_id + " " + name + " " + s_brith + " " + s_sex);
}
}catch (Exception e){
e.printStackTrace();
}finally {
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 数据库连接池实现

发表评论 取消回复