引言
大家好,我叫张琦,来自每日互动,担任大数据平台架构师。今天我将分享我们团队在基于Apache DolphinScheduler实现ClickHouse零压入库过程中的实践经验。

这个实践项目涉及到两个关键组件:Apache DolphinScheduler和ClickHouse,主要是我们在实际工作中遇到挑战后的解决方案。通过调研开源组件、验证官方建议和在线方法,我们最终找到了一种较为理想的实现方式,并将其落地。
分享内容概述
本次分享将主要分为以下三个部分:
- 面临的技术挑战
- 零压入库的实现方式
- 生产应用效果及思考
整个分享的内容设计较为简洁,我们会围绕实际遇到的问题和解决方案展开讨论,并分享在开源和非开源技术中的探索和应用经验。
最后,我们会讲述生产应用中的效果,以便大家能够从中获得启发,在未来的类似场景中取得更好的体验和成果。
什么是零压入库?
首先,我们先来解释一下“零压入库”的概念。可能很多人听过“零压大床房”这个词,它指的是让人感受到舒缓、无压力的睡眠体验。
而在我们的技术场景中,“零压入库” 指的是如何让 ClickHouse 在数据入库时不产生明显的系统压力,从而保证服务的稳定性和高性能。
换句话说,我们希望通过优化让 ClickHouse 在数据入库时能做到“无感知”地处理这些操作,从而保证系统性能不受影响。这就是我们称之为“零压入库”的原因。
面临的挑战
ClickHouse的优势与劣势
在实现ClickHouse的零压入库实践中,我们首先需要深入了解其优势和不足,以便于在实际应用中扬长避短。
ClickHouse的优势和不足可以从以下几方面来分析:
ClickHouse的优势
高性能的存储与查询
ClickHouse的列式存储结构让其在数据压缩和查询速度方面表现优异。支持多种数据压缩算法(如LZ4和ZSTD),用户可以根据服务器配置选择合适的压缩算法,在磁盘空间与CPU消耗之间进行平衡。在测试中,ClickHouse单机即可在毫秒级处理十亿级别的数据,社区也在不断更新,百亿级数据下性能表现出色。
灵活的SQL支持
ClickHouse兼容标准SQL,支持复杂查询,包括窗口函数、自定义函数等,适用于大规模数据分析场景。其中对于bitmap的支持,非常优秀。
此外,ClickHouse还支持多源数据联合查询,能够满足多源跨表分析的需求。
单机百亿级别性能
在64C CPU和256GB内存的配置下,ClickHouse单机可以轻松处理百亿级别的数据,实现高效查询和写入。
ClickHouse的劣势
硬件敏感性高
ClickHouse对硬件配置的要求较高,尤其对磁盘的性能非常敏感。不同于对CPU和内存的相对宽容,ClickHouse在机械硬盘和固态硬盘的使用体验上有显著差异,这也直接影响了数据的写入性能。
写入并发受限
ClickHouse的高查询性能是以牺牲写入性能为代价的,尤其在高并发写入场景中易出现瓶颈。其推荐单机QPS/TPS不超过20,最好不超过100。高并发写入会加重IO负担,直接影响查询和服务器性能。
内存消耗高
ClickHouse在写入数据和执行查询时都对内存有较大需求,尤其是在执行关联查询时,需要大量的内存空间来缓存和处理数据。对于内存配置不高的服务器,写入和查询的内存需求可能会影响其他任务的正常执行。
合并性能低
ClickHouse的数据合并性能较差,数据入库后可能需要花费数小时甚至更长时间进行文件合并。文件合并过程中会大量占用IO、CPU和内存资源,影响整体性能。
海量数据入库的挑战
在海量数据入库过程中,ClickHouse的弱点逐渐暴露,尤其是在日入库量达到TB级别、数十TB级别甚至更高的情况下。
我们遇到的主要挑战包括:
数据时效性受影响
在高并发写入的场景中,服务器的负载快速上升,写入和查询都会受到影响,导致数据时效性下降。
业务查询的影响
在数据入库期间,服务器水位高企,业务查询的性能会受到较大影响,甚至可能出现查询失败的情况。
集群资源有限
如何平衡业务查询和数据入库的资源分配是一个重要的课题,特别是当集群资源紧张时,往往难以保证两者的性能。
数据堆积和补数问题
在数据量大、数据入库性能受限的情况下,数据堆积和补数难度增加。数据堆积可能导致集群性能下降,而补数时大批量写入又容易引发性能瓶颈。
补数和依赖管理困难
在补数的过程中,批量部署和上下游依赖的处理较为复杂,入库、告警等功能目前多依赖人工维护,缺乏自动化支持。
现有调度平台的局限性
之前,我们主要采用的是Azakaban调度平台。它在早期大数据加工调度和日常数据运维中表现尚可,但在面向现代化的DataOps或Data AI场景下,表现出了一些不足。
例如,对于需要快速迭代的数据研发场景,Azakaban缺乏灵活性,且在自动化告警和维护方面较为薄弱,所以我们需重新选型一款调度产品来替代现有的技术栈。
总之,我们在ClickHouse零压入库实践中,必须解决ClickHouse的硬件敏感性、写入瓶颈和内存需求等方面的挑战,同时探索新的调度平台和方法来提升整体的运行效率。
零压入库的实现
为什么选择 DolphinScheduler
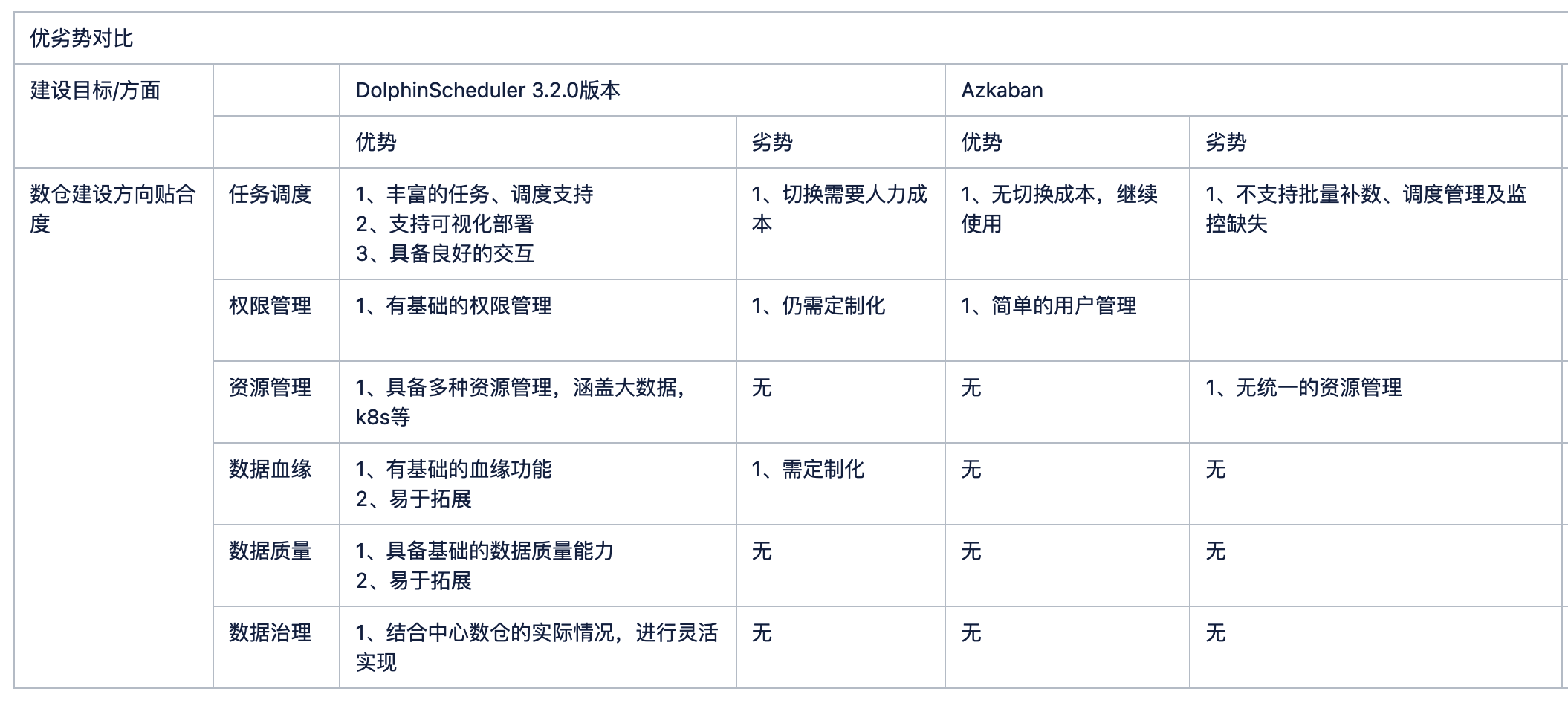
选择 DolphinScheduler 作为调度引擎的主要原因包括以下几点:
强大的调度能力
DolphinScheduler 已成为 Apache 顶级项目,具备了稳定的调度能力,支持复杂的任务流程管理,社区活跃度高,更新迅速。
这让我们能够高效实现各类复杂的数据调度需求,同时支持多种作业流程管理需求。
可视化模板作业流
DolphinScheduler 的可视化模板大大简化了任务配置流程。数据开发人员可以通过模板快速创建作业流,支持直接在可视化平台上完成配置。
这样,核心开发人员只需设计模板,其他用户即可复用,大幅减少开发和配置时间。
丰富的重跑和补数机制
在 3.2.0 及后续版本中,DolphinScheduler 支持依赖数据节点的补数机制,即当上游节点出现异常时可以一键启动依赖链路中的所有节点自动补数。
此功能配合数据血缘图使用,能有效降低数据维护难度,使数据问题排查和修复更加迅速。
多环境支持
DolphinScheduler 支持开发、测试、生产环境的无缝切换,允许用户在开发环境完成调试后将配置导入测试环境,最终同步至生产环境,极大地提升了数据上线效率。
环境配置的灵活管理,使得多环境切换在保障数据安全的同时,还能加速数据任务的上线流程。
零压入口平台架构
我们的数据零压入库平台架构分为几层:
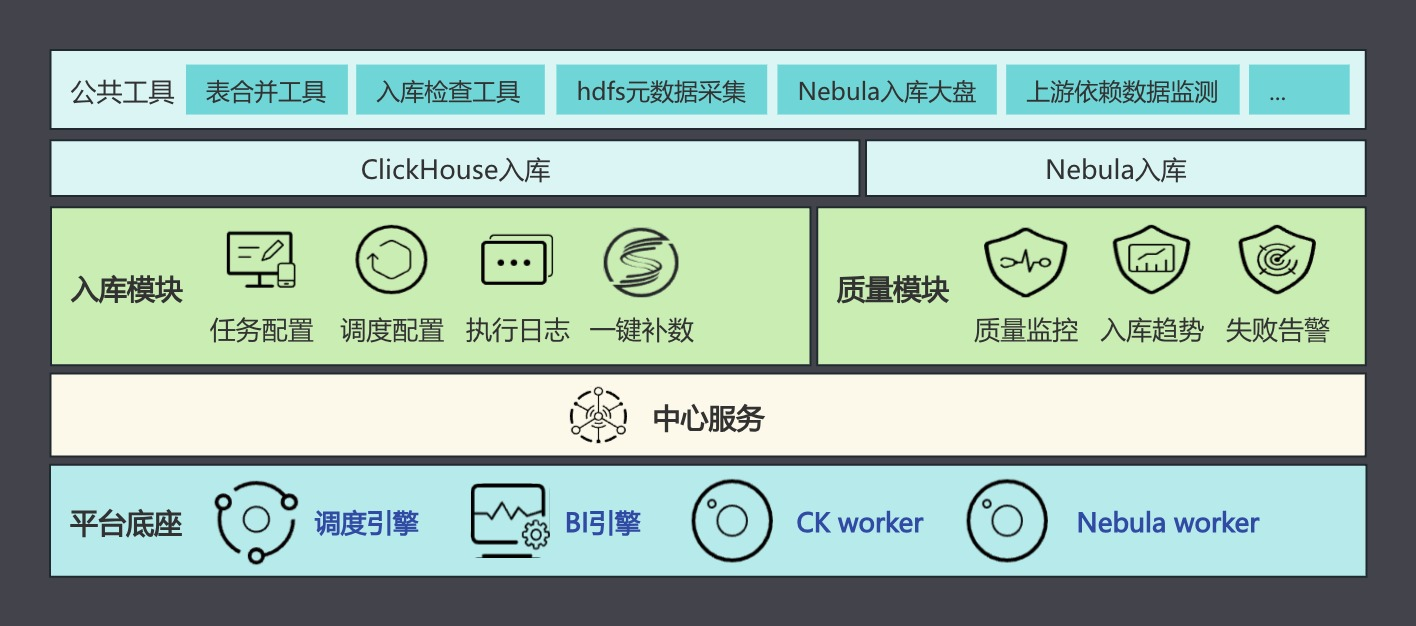
- 调度引擎与 BI 引擎:DolphinScheduler 为调度底层,引导 ClickHouse 和 Nebula 的 Worker 执行节点的操作,提供调度稳定性保障。
- 中心服务层:中心服务集成了 DolphinScheduler 的调度和数据管理功能,负责任务配置、日志管理以及一键补数等关键功能。
- 数据质量模块:基于 DolphinScheduler 的监控功能,加入数据质量模块,用于监控数据入库趋势、链路检查、大小与耗时分析等。告警模块提供多种告警方式,包括 HTTP、邮件、企业微信和钉钉等。
- 业务使用层:通过模板化开发,将 ClickHouse 和 Nebula 的入库任务标准化,提升数据处理流程的易用性。公共工具如表合并工具、入库检查工具等进一步增强平台的灵活性和实用性。
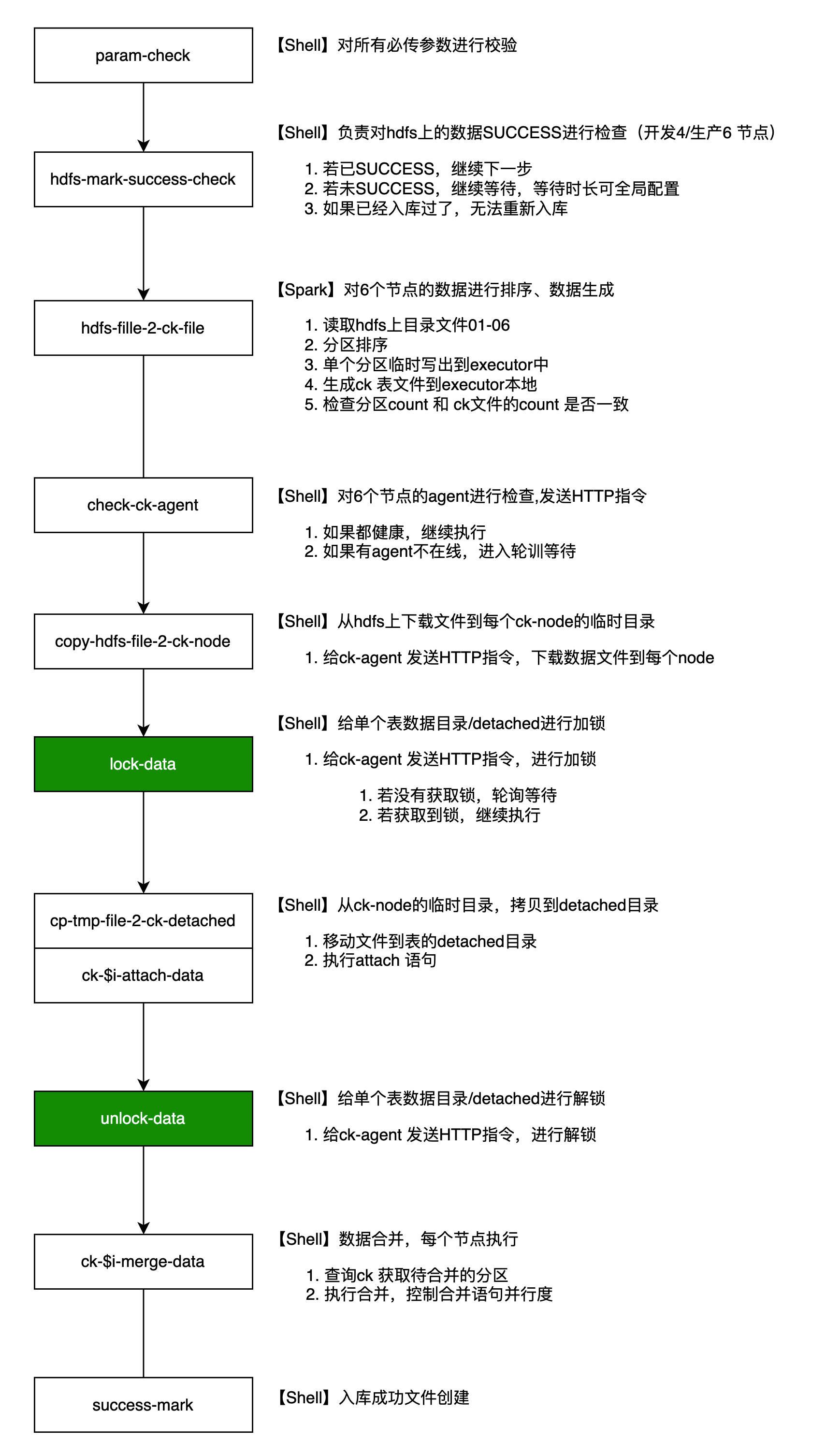
流程设计
零压入库的核心技术原则为“算力转移”,即将 ClickHouse 入库时的 CPU、内存和磁盘资源消耗尽可能转移至大数据平台 Yarn 中,从而减少对 ClickHouse 资源的占用。
流程设计如下:
技术参考: https://www.bilibili.com/read/cv16473965/ https://www.slidestalk.com/DolphinScheduler/SeaTunnelwithDolphinScheduler43829?embed https://www.slidestalk.com/SeaTunnel/23020 https://seatunnel.incubator.apache.org/zh-CN/docs/2.3.3/connector-v2/sink/ClickhouseFile https://clickhouse.com/docs/en/sql-reference/statements/attach https://juejin.cn/post/7162441097514319909 https://clickhouse.com/docs/zh/operations/utilities/clickhouse-local

核心算子的执行流程
在 Spark 中执行 ClickHouse 本地生成工具 ClickHouse Local,以预先生成符合 ClickHouse 分区要求的文件。
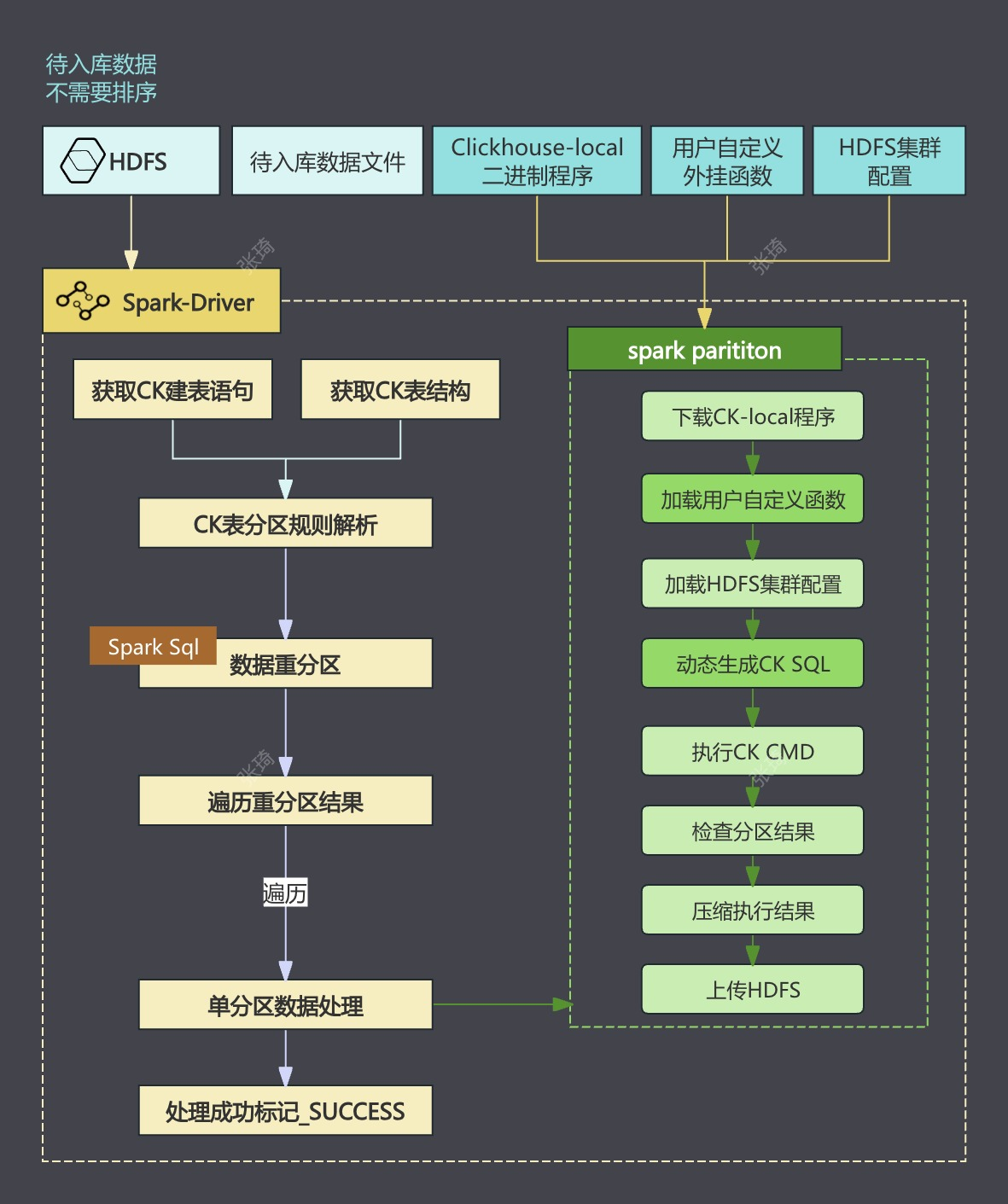
执行步骤如下:
待入库数据不需要排序
Spark在Driver中,连接ClickHouse获取到表结构,按照表分区规则进行Spark sql重分区计算
Executor中
- 下载
ClickHouse-local程序 - 读取HDFS上重分区后的数据
- 加载用户自定义函数
- 动态生成执行语句。执行命令生成表分区,包含索引、数据文件等完整的分区目录结构(基于配置化的参数,可以自行调整大小)
- 这两个参数可以调整sql语句插入ck表时,
insert ck表时, 单个最小切分分区目录大小的参数min_insert_block_size_rows=10000000,min_insert_block_size_bytes=1073741824
- 压缩分区数据,上传到HDFS
通过设计 Spark Executor 进行分区内数据处理,减少 ClickHouse 资源的消耗,并实现零压入库。与传统 Insert Into 方法相比,这种方式降低了 ClickHouse 资源的占用,同时提升了数据合并的效率。
总结来看,通过零压入库方案,我们实现了 ClickHouse 数据导入的高效、低压,并且大大减少了内存和 CPU 的消耗,确保数据入库稳定高效,极大提升了 ClickHouse 在大数据场景下的数据处理性能。
生产应用效果
在我们的生产应用中,基于海豚的技术方案取得了一些显著效果,具体包括以下几个方面:
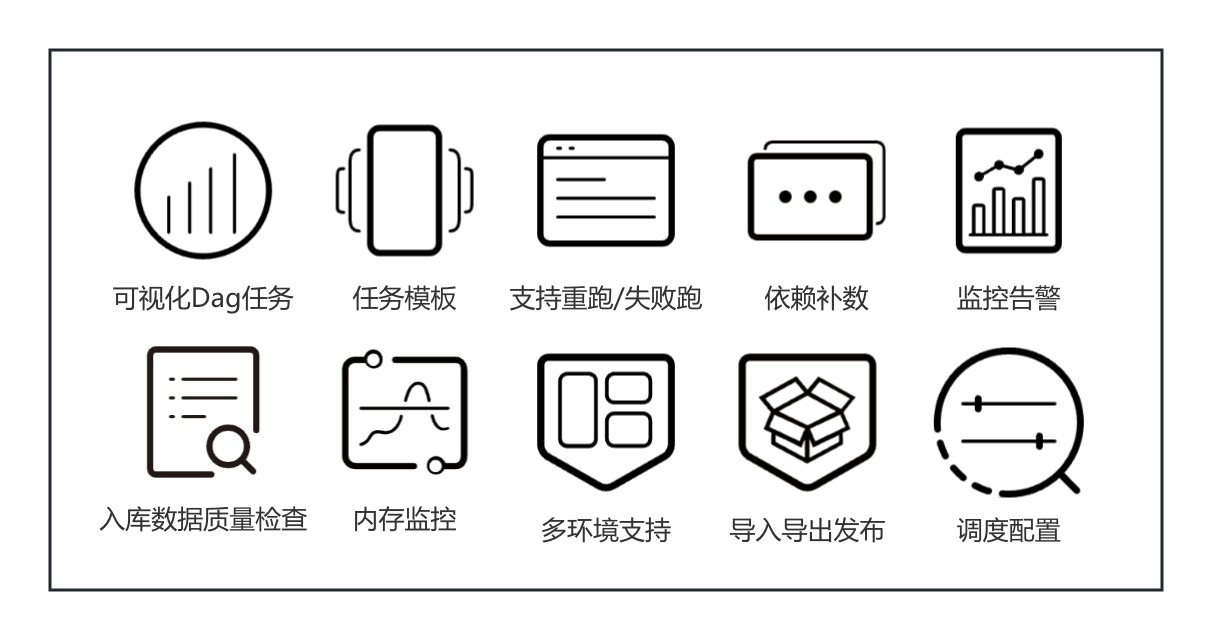
可视化任务管理
- 开发人员可以创建任务模板,并将这些模板开放给其他数据研发人员使用。
- 目前主要通过复制或点击引用的方式进行使用。
支持重跑和失败重跑
- 实现了任务的重跑和失败重跑功能,利用社区现有的功能来降低人力和成本,提高数据研发效率。
监控告警
- 完善了监控告警机制,利用组件的丰富性建立了有效的告警机制。
数据质量检查
- 入驻库的数据质量检查通过提供数据质量相关的算子,若不够用,用户仍可自定义编写Spark或SQL任务进行检查。
内存监控与管理
- Worker监控机器服务器资源,支持脚本监控整个CK服务器资源。
- 提供多环境支持及导入导出的发布功能。
方案特点

我们的方案特点是“削峰不填谷”,通过提前完成CK文件计算,仅在入库时进行短时磁盘写入,降低了CPU的负担。
我们目前验证的一些效果显示,整体提升的效果基本上都在一倍或者一倍以上。具体而言,8小时的合并时间可以缩短至4小时,4小时缩短至2小时,2小时再缩短至1小时。
这些改进还可以根据不同用户自行设定参数,系统提供了项目参数功能,可以直接引用全局参数来使用,从而减少内存占用并降低CPU使用率。
入库过程优化
在入库过程中,系统只需将数据从一个目录搬到另一个目录,就可以完成数据的入库。得益于数据分块更大,下载和解压过程的CPU占用率得以降低。

以下是优化的几个关键点:
内存清理:内存的清理效果超出了我们的预期。在完成入库时,系统会瞬时清理无效的缓存和过期的内存标记文件,整理内存,降低水位,为后续的查询提供更多的内存空间。在生产环境中,这一内存清理操作经过多次验证,对业务查询没有影响。
数据强一致性检查:在使用
INSERT INTO方式进行入库时,如果数据在Spark或Flink任务中重复,而检查机制不到位,则可能会造成数据问题。在我们的方案中,通过统计HDFS上的单个分区与生成的CK表的条数,一旦发现重复,系统会在合并时自动剔除重复数据,从而确保入库数据的准确性。数据时效提升:对入库的数据进行统计检查,发现重复数据问题,有助于及时解决业务和数据上的bug,计算、入库、合并三个阶段的耗时均有所下降,在数据入库过程中,资源使用更高效,减少了CPU和内存的占用。
我们的生产效果验证了CK表的压缩算法及分区预生成的优化策略,实现了资源的高效利用和性能的显著提升。这种方法不仅提升了入库效率,还确保了数据质量与一致性,是我们未来应用的一个重要方向。
性能对比分析
常规方式 vs CK File 方式
以下是生产上使用单节点900GB大小数据的性能对比分析:
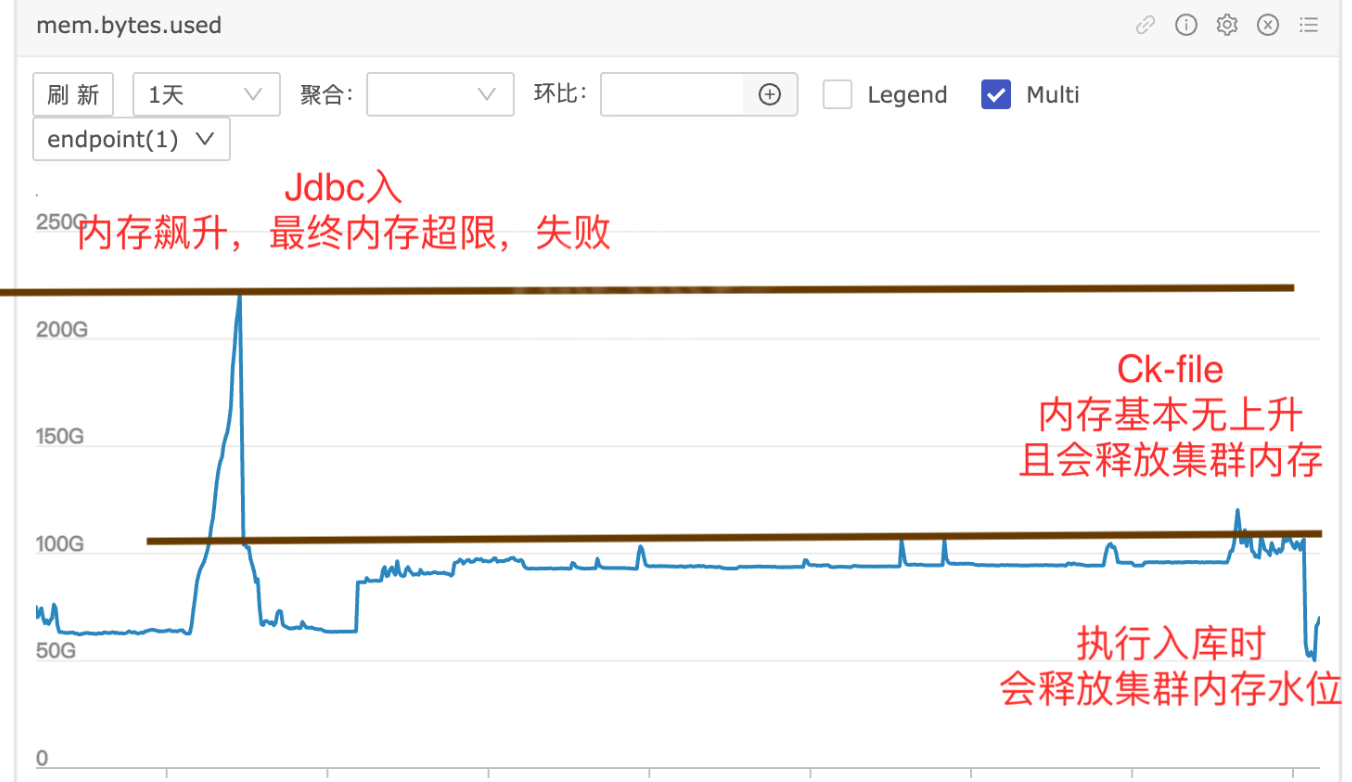
内存使用情况:使用 INSERT INTO 方式时,内存使用提升至80%(约200-220GB可用资源),但随即出现内存回落现象。而使用CK File方式时,内存基本没有上升,并且会释放部分内存,最终稳定在50GB左右。
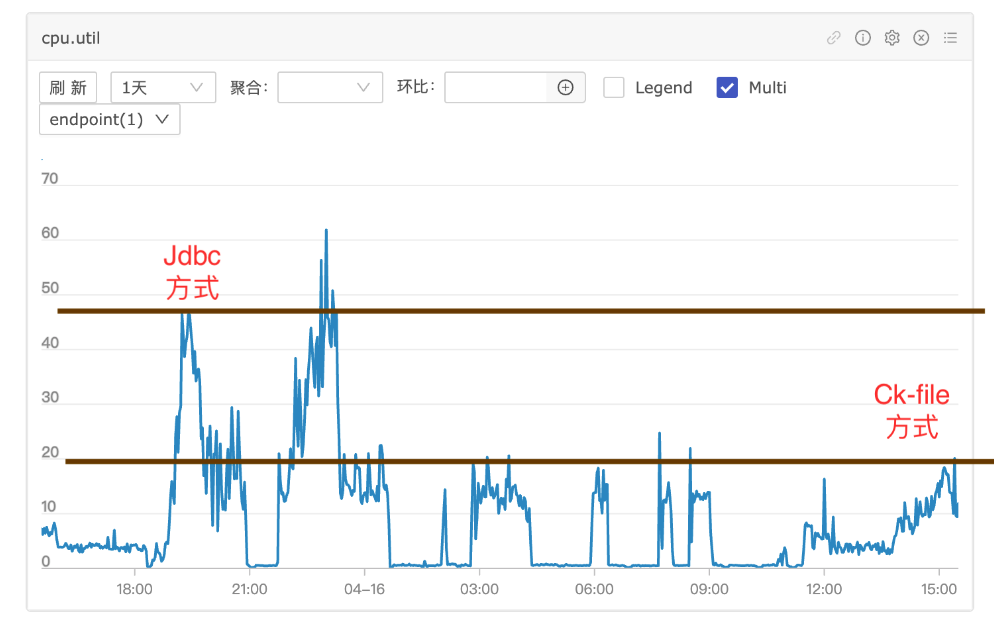
CPU占用:在使用之前的JDBC方式时,CPU使用率明显上升;而CK File方式的CPU上升幅度较小,整体减少了资源占用。
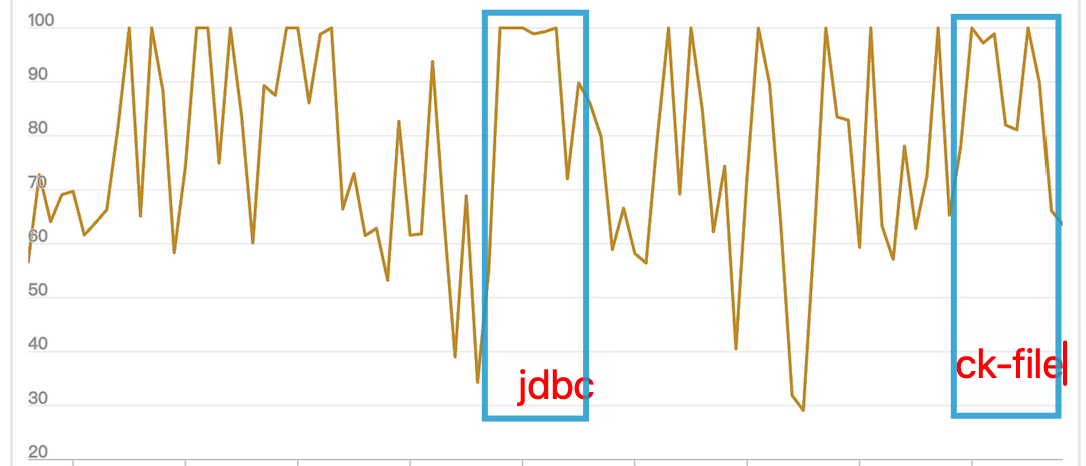
IO性能:在JDBC与CK File的对比中,尽管峰值没有太大差距(因磁盘使用率较高),但CK File的写入速度更快,显著减少了入库所需时间。
存储与压缩算法
整体性能提升还依赖于文件大小的减少,采用CK表的压缩算法(默认LZ4)。我们建议设定为ZSTD以提高压缩率,从而降低存储压力。不过,ZSTD对CPU的要求相对较高。
合并速度优化
通过控制预分区和生成的表分区块大小,目前设置为每个分区1,000万个数据,显著减少了分区块的数量,从而加快了合并速度,不消耗内存。
资源管理与扩展
在CK中,单个节点的资源是固定的(例如,64核、256GB内存)。若需扩容,只能进行横向扩展。然而,将部分机器资源转移至Yarn后,Yarn可以复用这些资源,使得CK的计算在Yarn上进行,从而有效提升计算效率。在理想情况下,可能将CK输入库的数据处理时间缩短至两个小时。
数据处理收益分析
在资源管理方面,尽管我们在计算能力上有所提升,但实际使用的资源上升时间反而减少。这是因为机器的计算能力能够更有效地均摊和利用,为其他业务线提供服务。
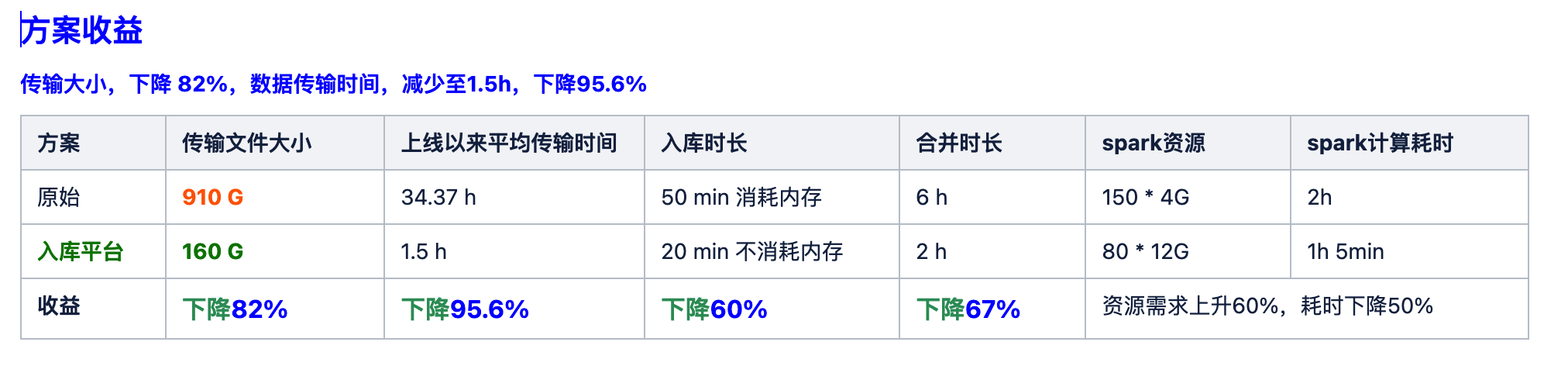
经过一段时间的验证,我们的数据处理效果显著提升,基本上都在一倍以上。
例如,原始文件大小为 910 GB 的数据处理后,仅减少至 160 GB,实现了 82% 的压缩。数据传输时间从 35 小时降至 1.5 小时,效率提升了 95%。
在入库环节,耗时从 50 分钟降至 20 分钟,并且这一过程几乎不消耗内存。合并时间更是从 6 小时缩短至 2 小时,极大地提升了数据处理的时效性。
Spark资源管理
通过优化资源配置,我们在 Spark 的资源使用上有所提升,虽然单个执行器的资源需求增大,但整体处理时长却下降了近一半。
此外,在过去的一段时间里,我们遇到了内存使用不均和入库失败的问题,但自从系统上线以来,这些问题得到了有效解决,数据处理过程也变得更加平稳。
- 资源要求:由于调大了1,000万和1GB的资源要求,单个Executor的资源需求有所上升。
- 整体时长:处理时长下降接近一半。
内存管理与性能
内存的使用情况表现为时高时低,这主要是由于每次数据入库后,系统会进行内存清理,有效降低内存水位,确保机器处于良好的状态。
这种管理策略提高了系统的容错性。在执行大型查询任务时,我们能够提前释放内存,以满足高内存需求的任务,从而为业务场景提供更多的应用可能。
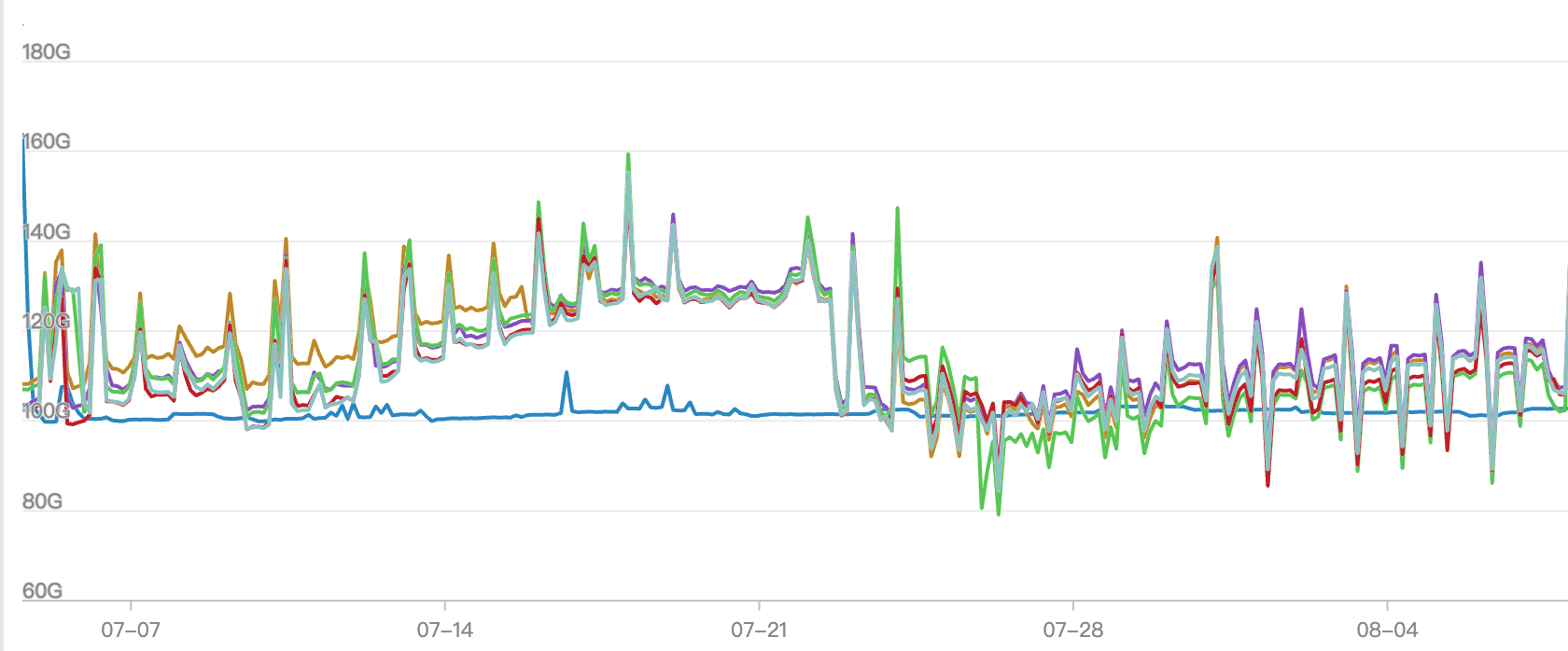
- 在上线前,内存水位和OOM产生问题较为明显,特别是在7月底的某个时间段内,常出现OOM入库失败和数据条数不一致的问题。
- 自7月24日至25号大规模投产后,数据和机器的压力显著下降,运行状态趋于平稳。
这一功能确保了后续查询能够获得更多的内存资源,进而提升了查询效率。同时,我们的内存清理策略并没有对业务查询造成影响,这一策略的成功实施为后续的业务需求提供了强有力的支持。
以上是我们在数据处理中的一些收益和经验分享,希望对你有帮助和启发,欢迎大家提出疑问或进行交流与研究。
本文由 白鲸开源科技 提供发布支持!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 每日互动基于 Apache DolphinScheduler 从容应对ClickHouse 大数据入库瓶颈

发表评论 取消回复