部署组件
● spark-historyserver
● spark-client
配置文件
kind: ConfigMap
apiVersion: v1
metadata:
name: spark
data:
spark-defaults.conf: |-
spark.eventLog.enabled true
spark.eventLog.dir hdfs://192.168.199.56:8020/eventLogs
spark.eventLog.compress true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.master yarn
spark.driver.cores 1
spark.driver.memory 2g
spark.executor.cores 1
spark.executor.memory 2g
spark.executor.instances 1
spark.sql.warehouse.dir hdfs://192.168.199.56:8020/user/hive/warehouse
spark.yarn.historyServer.address 192.168.199.58:18080
spark.history.ui.port 18080
spark.history.fs.logDirectory hdfs://192.168.199.56:8020/eventLogs
spark-historyserver部署文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: spark-historyserver
labels:
app: spark-historyserver
spec:
selector:
matchLabels:
app: spark-historyserver
replicas: 1
template:
metadata:
labels:
app: spark-historyserver
spec:
initContainers:
- name: init-sparklogs
image: spark:3.0.2
imagePullPolicy: IfNotPresent
command:
- "sh"
- "-c"
- "hadoop fs -ls /sparklogs;if [ $? -ne 0 ];then hadoop fs -mkdir /sparklogs && echo 'Create /sparklogs';fi"
volumeMounts:
- name: localtime
mountPath: /etc/localtime
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/core-site.xml
subPath: core-site.xml
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/hdfs-site.xml
subPath: hdfs-site.xml
containers:
- name: spark-historyserver
image: spark:3.0.2
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
memory: 2Gi
command:
- "sh"
- "-c"
- "$SPARK_HOME/sbin/start-history-server.sh && tail -f $SPARK_HOME/logs/*"
volumeMounts:
- name: localtime
mountPath: /etc/localtime
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/core-site.xml
subPath: core-site.xml
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/hdfs-site.xml
subPath: hdfs-site.xml
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/yarn-site.xml
subPath: yarn-site.xml
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/mapred-site.xml
subPath: mapred-site.xml
- name: hive-config
mountPath: /opt/spark/conf/hive-site.xml
subPath: hive-site.xml
- name: spark-config
mountPath: /opt/spark/conf/spark-defaults.conf
subPath: spark-defaults.conf
lifecycle:
preStop:
exec:
command:
- "sh"
- "-c"
- "$SPARK_HOME/sbin/stop-history-server.sh"
volumes:
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: hadoop-config
configMap:
name: hadoop
- name: hive-config
configMap:
name: hive
- name: spark-config
configMap:
name: spark
restartPolicy: Always
hostNetwork: true
hostAliases:
- ip: "192.168.199.56"
hostnames:
- "bigdata199056"
- ip: "192.168.199.57"
hostnames:
- "bigdata199057"
- ip: "192.168.199.58"
hostnames:
- "bigdata199058"
nodeSelector:
spark-historyserver: "true"
tolerations:
- key: "bigdata"
value: "true"
operator: "Equal"
effect: "NoSchedule"
spark-client部署文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: spark-client
labels:
app: spark-client
spec:
selector:
matchLabels:
app: spark-client
replicas: 1
template:
metadata:
labels:
app: spark-client
spec:
containers:
- name: spark-client
image: spark:3.0.2
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
memory: 2Gi
volumeMounts:
- name: localtime
mountPath: /etc/localtime
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/core-site.xml
subPath: core-site.xml
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/hdfs-site.xml
subPath: hdfs-site.xml
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/yarn-site.xml
subPath: yarn-site.xml
- name: hadoop-config
mountPath: /opt/hadoop/etc/hadoop/mapred-site.xml
subPath: mapred-site.xml
- name: hive-config
mountPath: /opt/spark/conf/hive-site.xml
subPath: hive-site.xml
- name: spark-config
mountPath: /opt/spark/conf/spark-defaults.conf
subPath: spark-defaults.conf
volumes:
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: hadoop-config
configMap:
name: hadoop
- name: hive-config
configMap:
name: hive
- name: spark-config
configMap:
name: spark
restartPolicy: Always
hostNetwork: true
hostAliases:
- ip: "192.168.199.56"
hostnames:
- "bigdata199056"
- ip: "192.168.199.57"
hostnames:
- "bigdata199057"
- ip: "192.168.199.58"
hostnames:
- "bigdata199058"
nodeSelector:
spark: "true"
tolerations:
- key: "bigdata"
value: "true"
operator: "Equal"
effect: "NoSchedule"
注意:spark-client一般是集成到应用服务中使用。
部署historyserver和client
> kubectl.exe apply -f .\spark\
deployment.apps/spark-client created
configmap/spark created
deployment.apps/spark-historyserver created
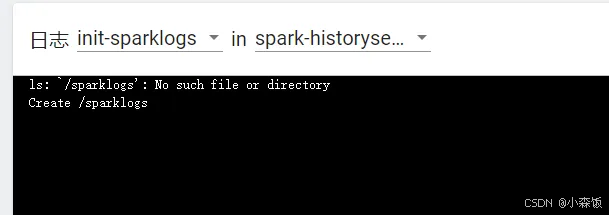
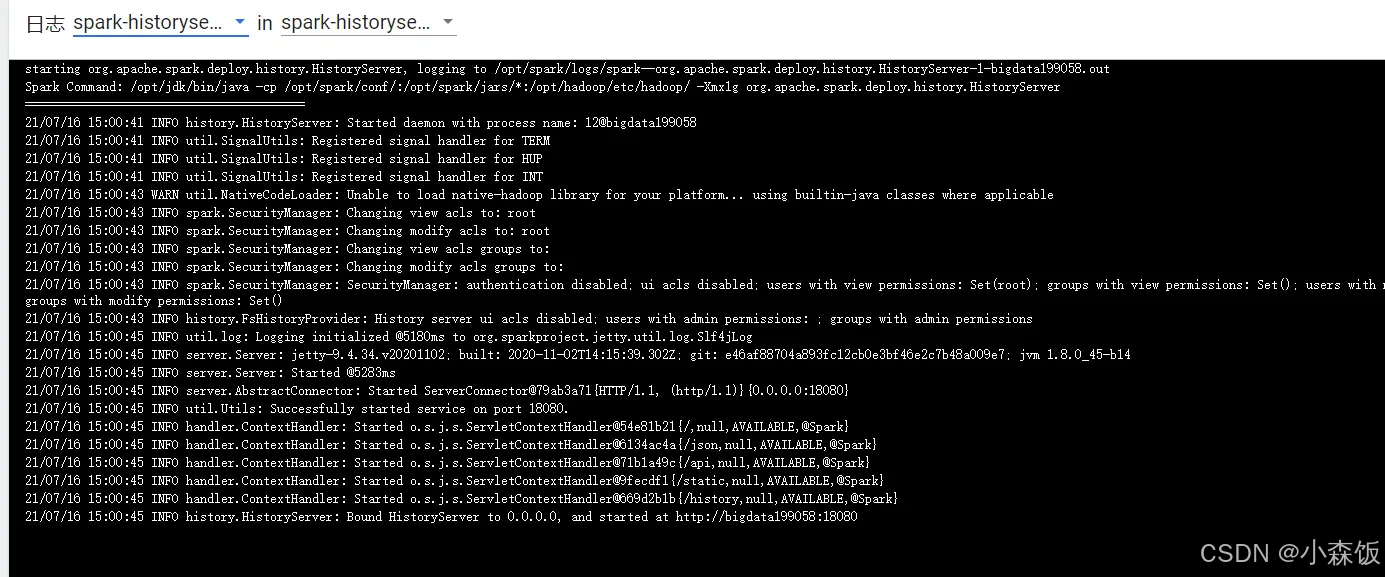
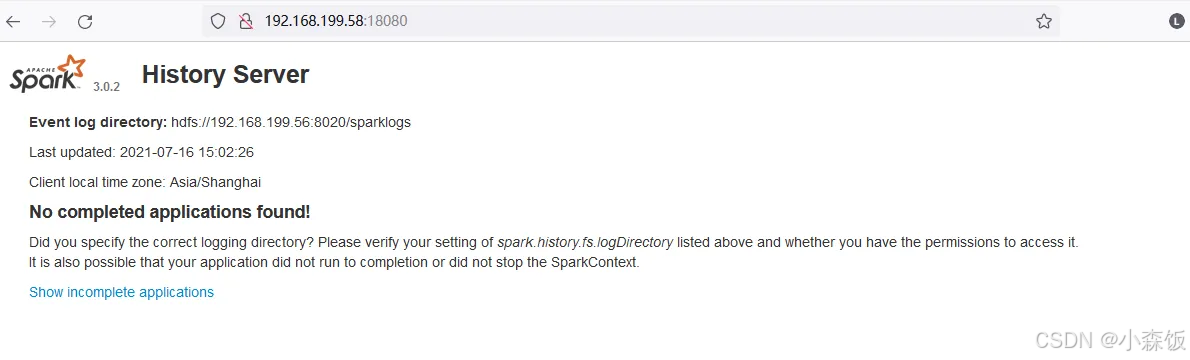
spark-historyserver日志和web服务
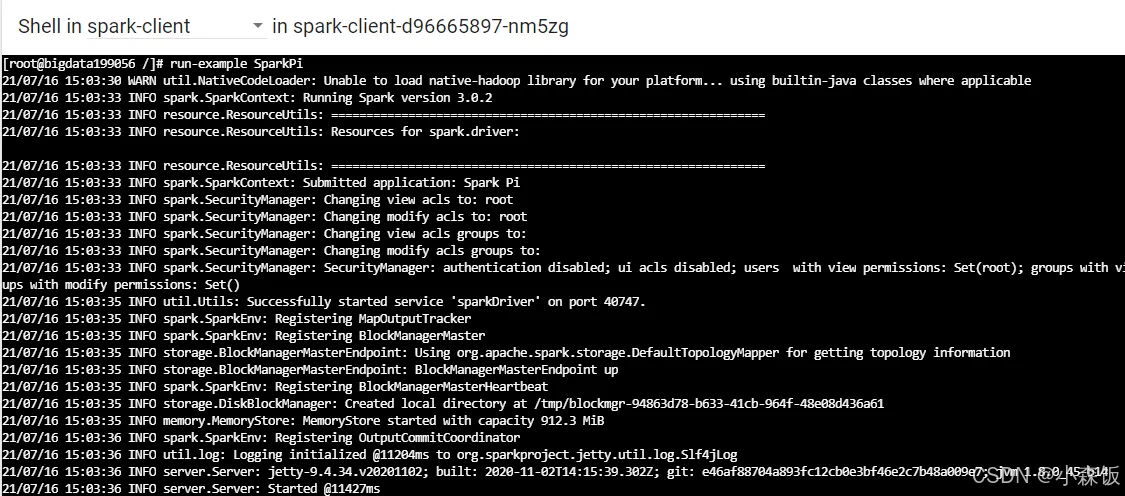
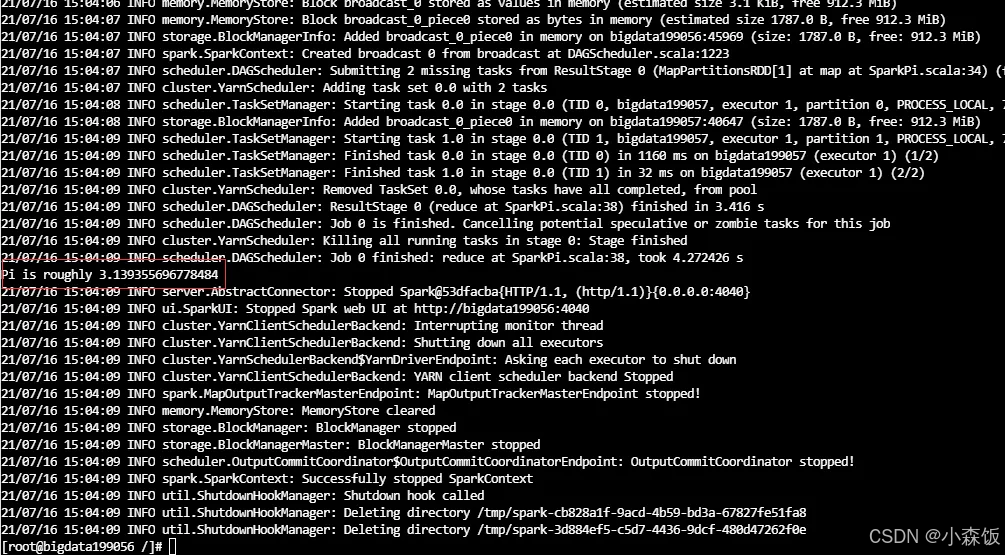
通过spark-client提交测试任务
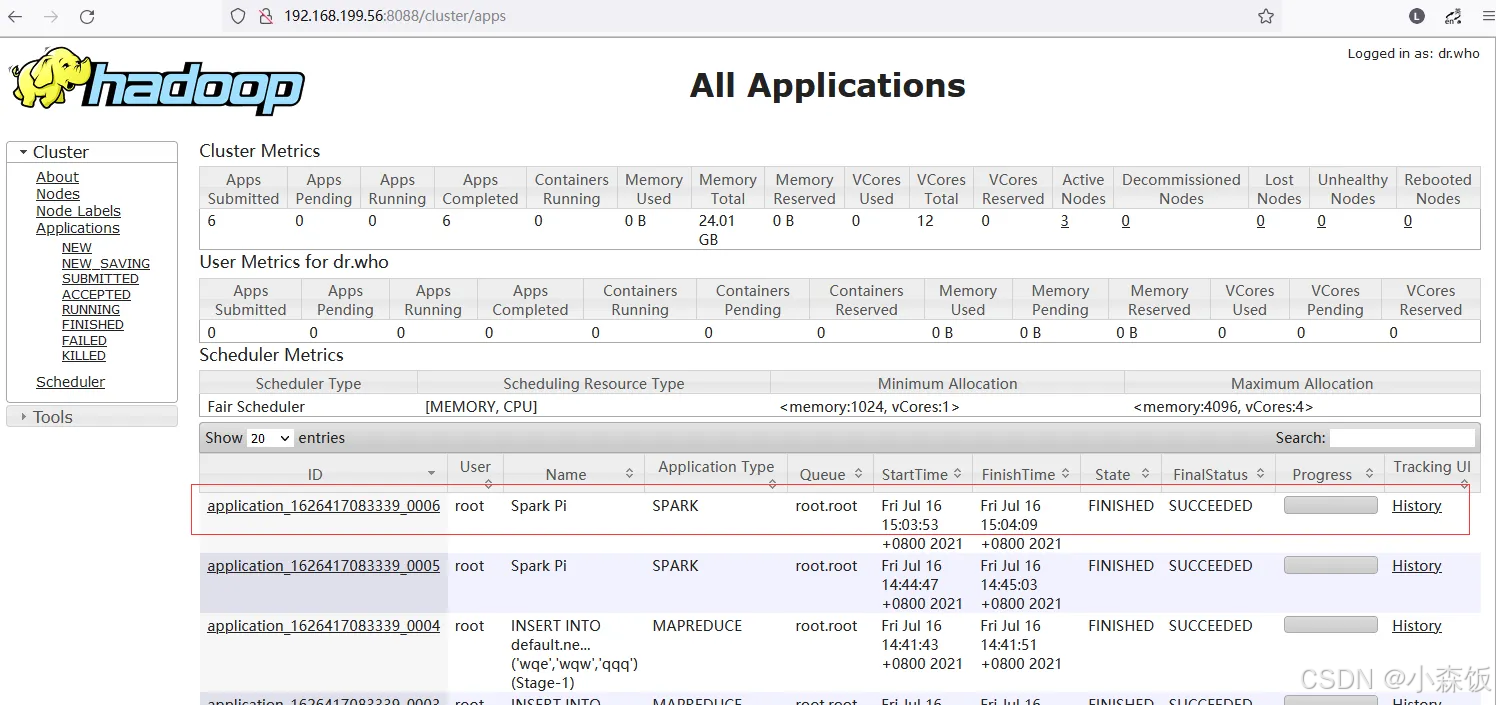
yarn中查看spark任务
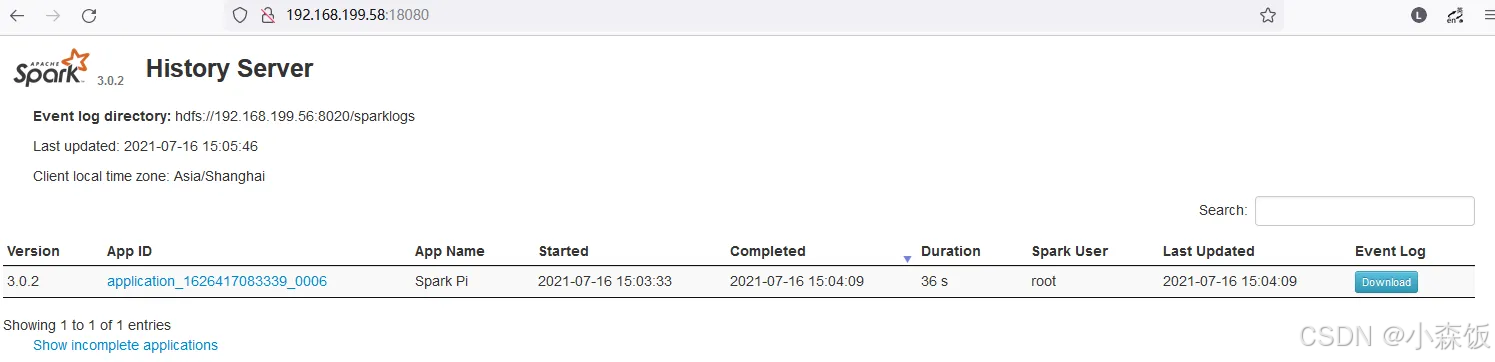
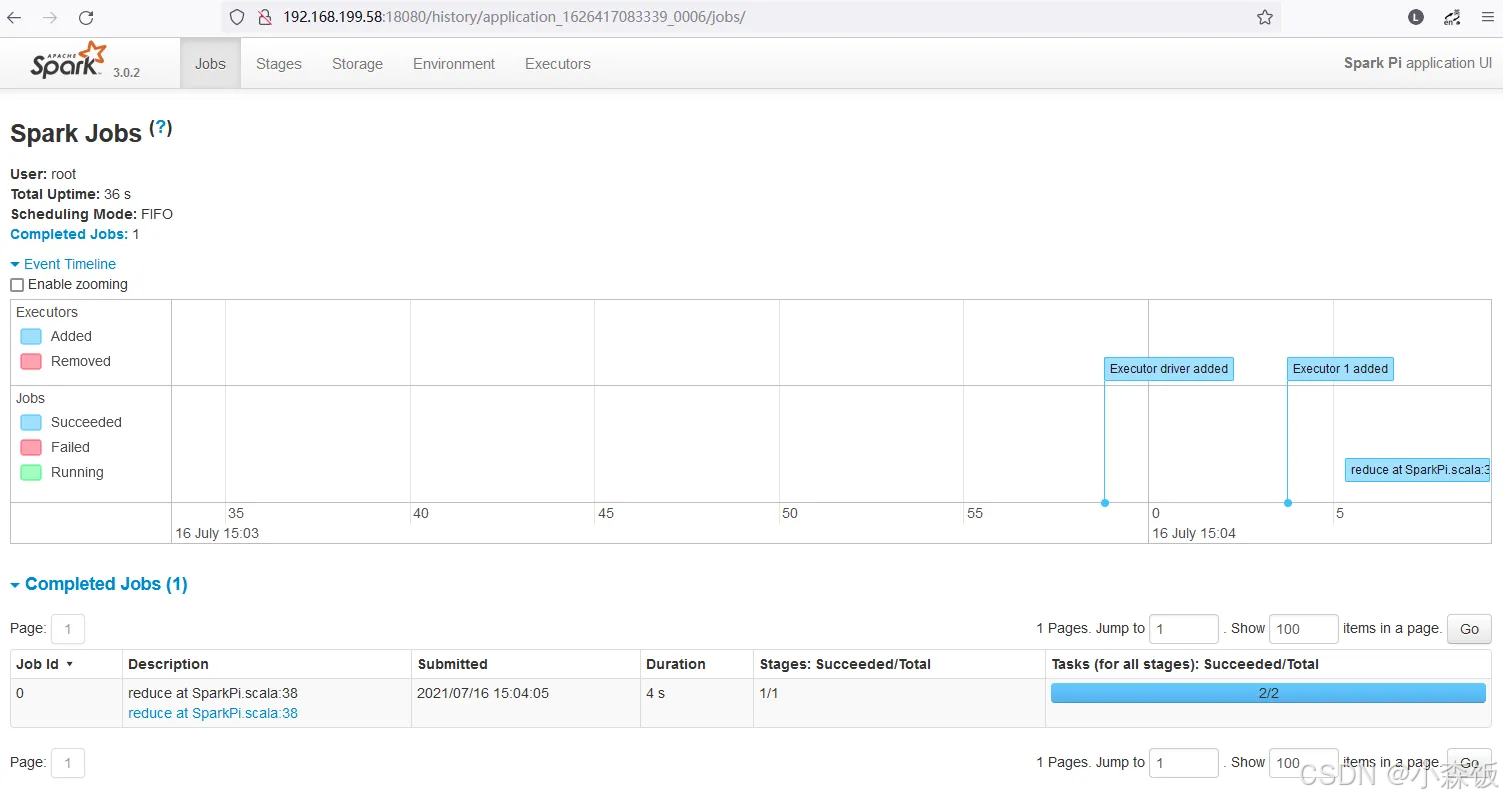
spark-historyserver中查看任务
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Kubernetes运行大数据组件-运行spark

发表评论 取消回复