1. 概述
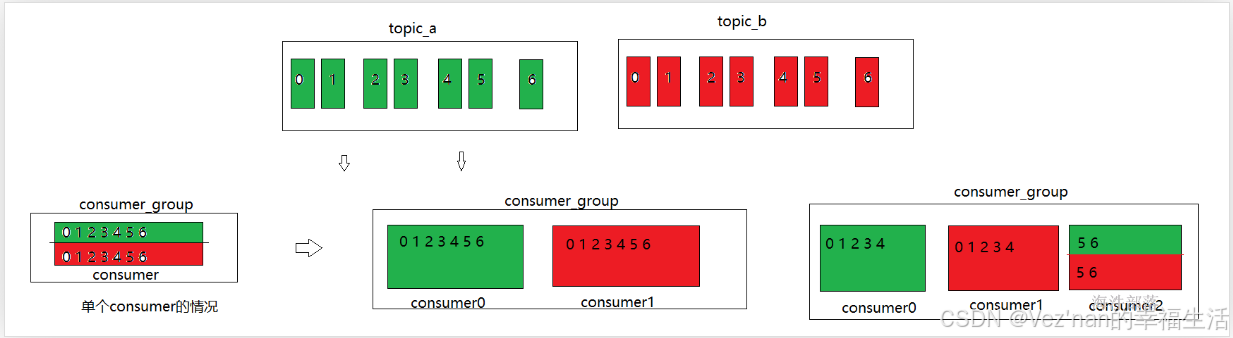
上面我们提到过,消费者有的时候会少于或者多于分区的个数,那么如果消费者少了有的消费者要消费多个分区的数据,如果消费者多了,有的消费者就可能没有分区的数据消费。
那么这个关系是如何分配的呢?
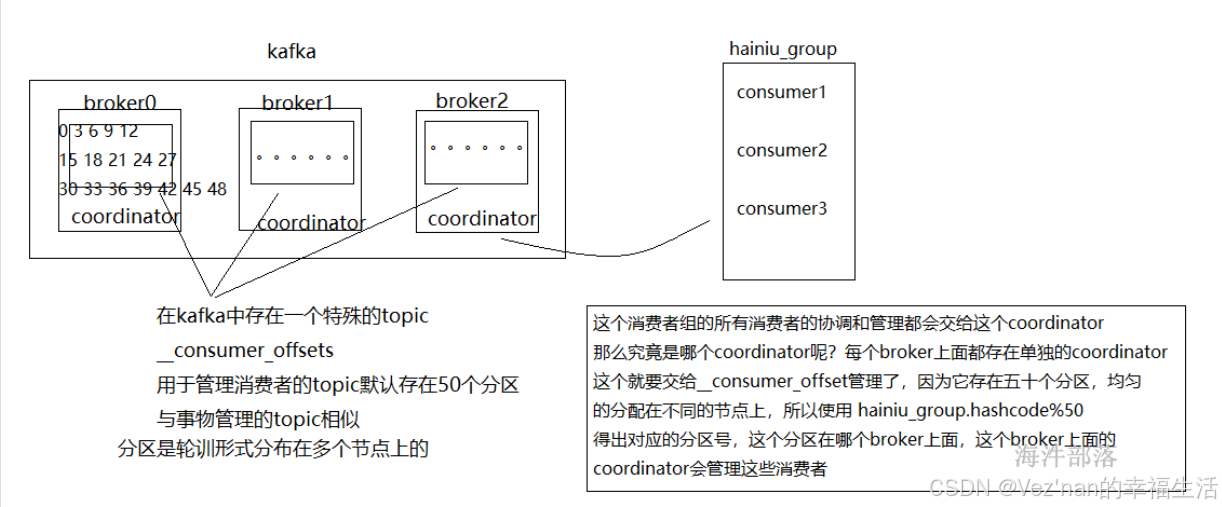
现在我们知道kafka中存在一个coordinator可以管理这么一堆消费者,它可以帮助一个组内的所有消费者进行分区的分配和对应。
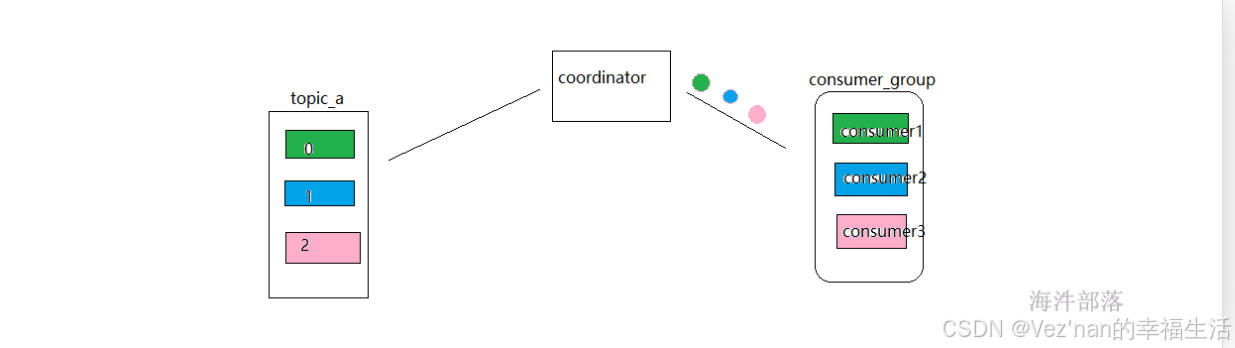
通过coordinator进行协调
这个分配规则分为以下几种。
2. range分配器
按照范围形式进行分配分区数量
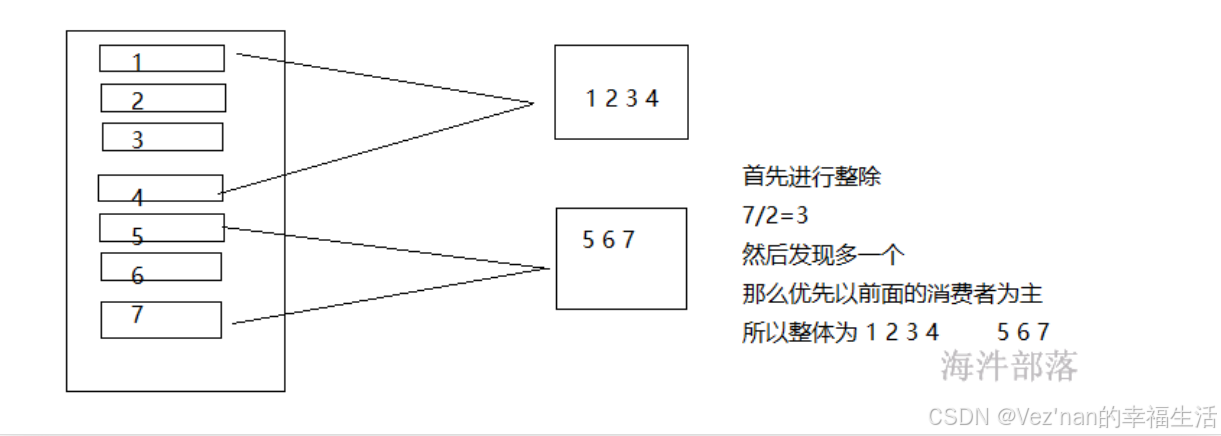
# 为了演示分区的分配效果我们创建一个topic_d,设定为7个分区
[hexuan@hadoop106 bin]$ kafka-topics.sh --bootstrap-server hadoop106:9092 --create --topic topic_f --partitions 7 --replication-factor 2
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
});然后改版订阅代码,subscribe订阅信息的时候展示出来分区的对应映射关系,这个只是一个监控的作用没有其他的代码影响,ConsumerRebalanceListener增加监视。
其中存在两个比较直观的方法
onPartitionsRevoked回收的分区。
onPartitionsAssigned分配的分区。
能够直观展示在分区分配的对应关系
其中我们需要知道两个比较重要的参数。
| 参数 | 解释 |
|---|---|
| offsets.topic.num.partitions | __consumer_offset这个topic的分区数量默认50个 |
| heartbeat.interval.ms | 消费者和协调器的心跳时间 默认3s |
| session.timeout.ms | 消费者断开的超时时间 默认45s,最小不能小于6000 |
| partition.assignment.strategy | 设定分区分配策略 |
也就是说我们想要直观查看消费者变化后的映射对应关系需要停止消费者以后45s才可以,这个在代码中我们需要人为设定小点,更加快速查看变化
代码测试原理
首先设定topic_d的分区为7个,然后启动一个组内的两个消费者,可以看到他们的分配关系在onPartitionsAssigned这个方法中打印出来,同时我们关闭一个消费者,可以看到onPartitionsRevoked可以展示回收的分区,onPartitionsAssigned以及这个方法中分配的分区
整体代码如下:
package com.hainiu.kafka.consumer;
/**
* ClassName : rangeAssigned
* Package : com.hainiu.kafka.consumer
* Description
*
* @Author HeXua
* @Create 2024/11/4 22:04
* Version 1.0
*/
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class rangeAssigned {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group2");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,RangeAssignor.class.getName());
//设定分区分配策略为range
pro.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,6000);
//设定consumer断开超时时间最小不能小于6s
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_f");
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
System.out.println("revoke-->"+partition.topic()+"-->"+partition.partition());
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
System.out.println("assign-->"+partition.topic()+"-->"+partition.partition());
}
}
});
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}我们执行两个实例,两个实例代表两个消费者位于同一个组中,那么两个消费者的分配关系按照,范围进行分割
consumer0[0,1,2,3] consumer1[4,5,6]
执行第一个实例的时候,无需回收,并且七个分区都分配给第一个消费者实例。
执行第二个消费者的时候,需要对第一个消费者实例进行回收分区:
revoke-->topic_f-->0
revoke-->topic_f-->1
revoke-->topic_f-->2
revoke-->topic_f-->3
revoke-->topic_f-->4
revoke-->topic_f-->5
revoke-->topic_f-->6
然后由于一个消费者组中有两个消费者实例,则将分区重新分配个两个消费者实例。
因为coordinator的分配规则基于eager协议,这个协议的规则就是当分配关系发生变化的时候要全部回收然后打乱重分。
consumer1分配分区情况:
assign-->topic_f-->0
assign-->topic_f-->1
assign-->topic_f-->2
assign-->topic_f-->3consumer2分配分区情况:
assign-->topic_f-->4
assign-->topic_f-->5
assign-->topic_f-->6缺点:
这个协议只是按照范围形式进行重新分配分区,会造成单个消费者的压力过大问题,多个topic就会不均匀。
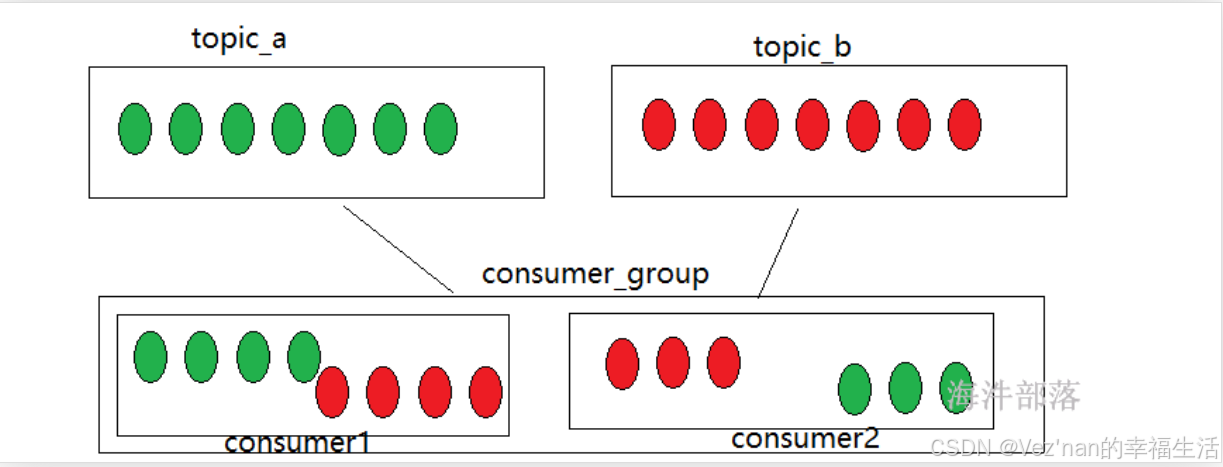
一个消费者组消费多个topic时可能会造成数据倾斜。
比如该消费者组有两个消费者:consumer1和consumer2。该消费者组消费两个topic分区:topic_1, topic_2,且假设两个topic都有7个分区,那么range分配规则可能会这么干:
consumer1分配topic_1-0,topic_1-1,topic_1-2, topic_1-3,topic_2-0,topic_2-1,topic_2-2, topic_2-3。
consumer3分配topic_1-4,topic_1-5,topic_1-6,topic_2-4,topic_2-5,topic_2-6。
consumer1要消费8个分区的数据,而consumer2要消费6个分区的数据,
当一个消费者出现消费多个topic主题的时候就可能出现这种数据倾斜的情况。
3. roundRobin轮训分配策略
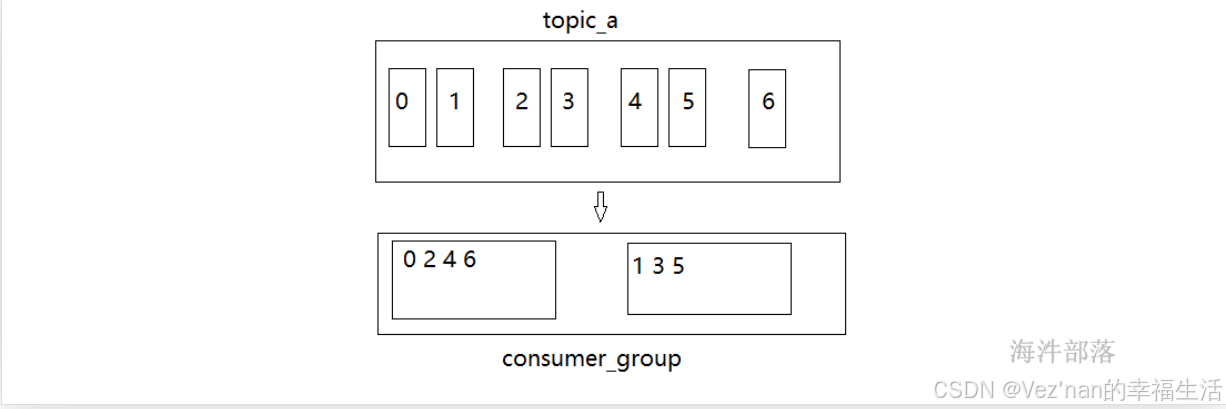
轮训形式分配分区,一个消费者一个分区
整体代码如下:
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,RoundRobinAssignor.class.getName());设定分配规则为roundRobin的
启动一个的效果:
assign-->topic_f-->0
assign-->topic_f-->1
assign-->topic_f-->2
assign-->topic_f-->3
assign-->topic_f-->4
assign-->topic_f-->5
assign-->topic_f-->6启动两个应用
第一个消费者consumer实例:
回收所有的七个分区:
revoke-->topic_f-->0
revoke-->topic_f-->1
revoke-->topic_f-->2
revoke-->topic_f-->3
revoke-->topic_f-->4
revoke-->topic_f-->5
revoke-->topic_f-->6再被分配到3个分区:
assign-->topic_f-->1
assign-->topic_f-->3
assign-->topic_f-->5第二个消费者consumer2实例:
assign-->topic_f-->0
assign-->topic_f-->2
assign-->topic_f-->4
assign-->topic_f-->6优点:
同range方式相比,在多个topic的情况下,可以保证多个consumer负载均衡
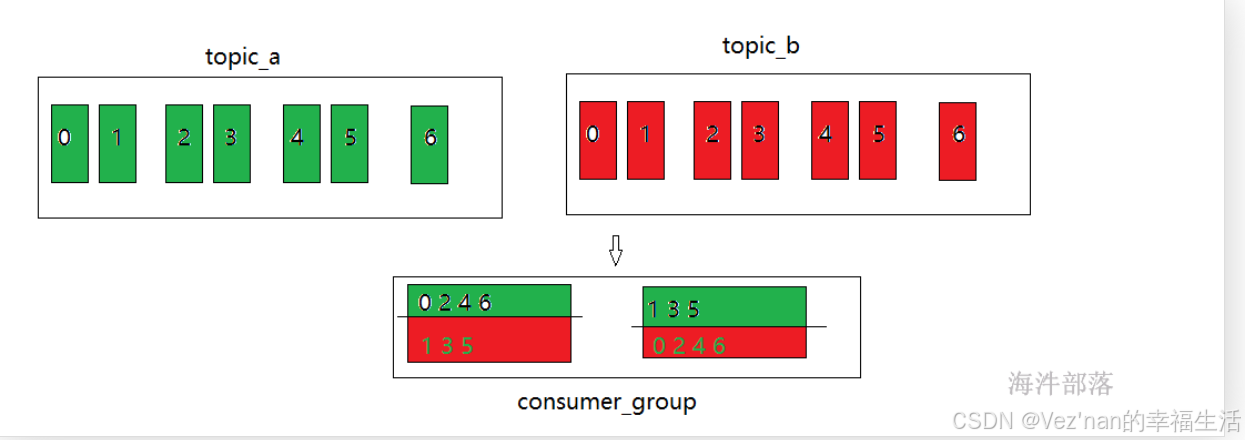
分配规则如上图,一人一个轮训形式
consumer0 [0 2 4 6 1 3 5]
consumer1 [1 3 5 0 2 4 6]
缺点
不管是range的还是roundRobin的分配方式都是全量收回打乱重新分配,这样的效率太低,所以我们使用下面的粘性分区策略。
4. sticky粘性分区
粘性分区它的重新分区原理和原来的roundRobin的分区方式差不多,但是又不相同,主要是分区逻辑一样,但是重新分配分区的时候优先保留原分区,然后重新分配其他分区,从而不需要全部打乱重分,减少重新分配分区消耗
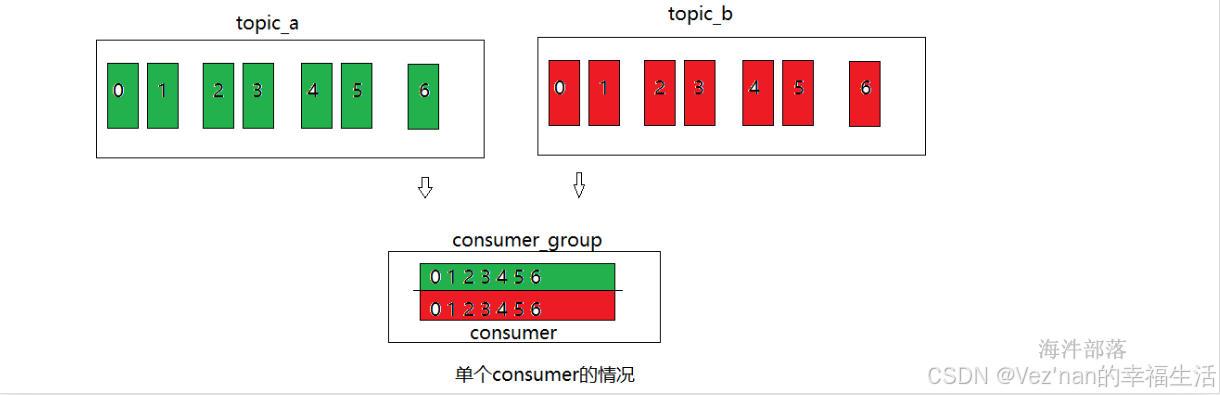
第二次启动
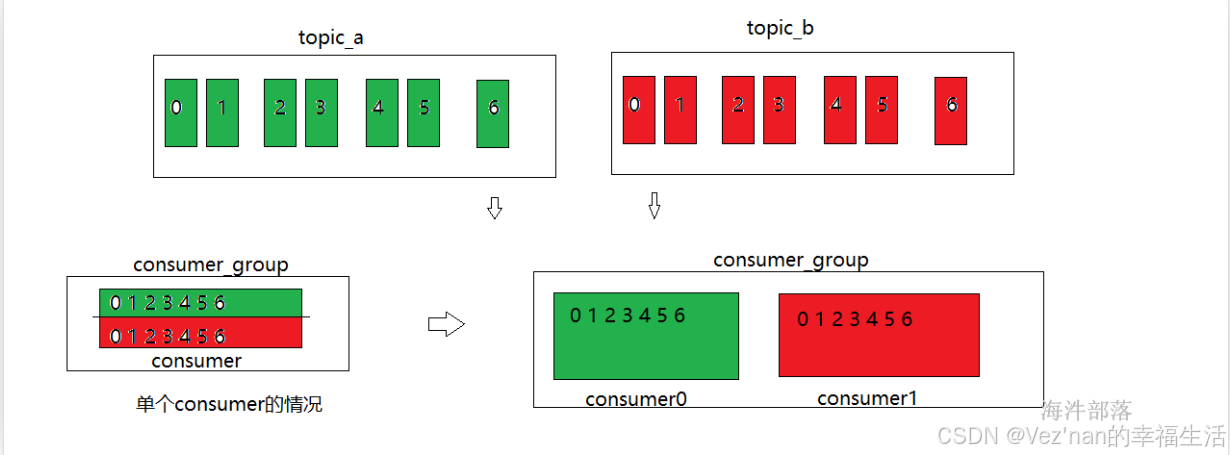
第三次
分区分配方式一样,但是如果重新分配的话会有很多原来分区的预留,重新分配新的分区
# 为了演示效果再次创建新的topic topic_g 七个分区
kafka-topics.sh --bootstrap-server hadoop106:9092 --topic topic_g --create --partitions 7 --replication-factor 2然后让复制代码,修改订阅两个topic
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,StickyAssignor.class.getName());
//修改为粘性分区
List<String> topics = Arrays.asList("topic_f","topic_g");
//订阅两个topic并且运行应用实例分别运行1 ,2 ,3 多种个数的实例
执行第一个消费者实例consumer1,无需回收,分配14个分区(topic_f和topic_g都是七个分区)
assign-->topic_f-->0
assign-->topic_f-->1
assign-->topic_f-->2
assign-->topic_f-->3
assign-->topic_f-->4
assign-->topic_f-->5
assign-->topic_f-->6
assign-->topic_g-->0
assign-->topic_g-->1
assign-->topic_g-->2
assign-->topic_g-->3
assign-->topic_g-->4
assign-->topic_g-->5
assign-->topic_g-->6执行第二个消费者实例consumer2时:
consumer1:
回收了14个分区:
revoke-->topic_f-->0
revoke-->topic_f-->1
revoke-->topic_f-->2
revoke-->topic_f-->3
revoke-->topic_f-->4
revoke-->topic_f-->5
revoke-->topic_f-->6
revoke-->topic_g-->0
revoke-->topic_g-->1
revoke-->topic_g-->2
revoke-->topic_g-->3
revoke-->topic_g-->4
revoke-->topic_g-->5
revoke-->topic_g-->6优先保留原来分区,所以分配七个分区:
assign-->topic_f-->0
assign-->topic_f-->1
assign-->topic_f-->2
assign-->topic_f-->3
assign-->topic_f-->4
assign-->topic_f-->5
assign-->topic_f-->6consumer2:
分配了七个分区;
assign-->topic_g-->0
assign-->topic_g-->1
assign-->topic_g-->2
assign-->topic_g-->3
assign-->topic_g-->4
assign-->topic_g-->5
assign-->topic_g-->6执行第三个实例consumer3:
consumer1将会回收七个分区,consumer2将会回收七个分区。
14 / 3 = 4 ----> 4 + 1 4 + 1 4
comsumer1将会被分配:[0, 1, 2, 3, 4]
consumer2将会被分配 : [0, 1, 2, 3, 4]
consumer3将会被分配:[5, 6, 5, 6]
尽量不改变原分区的规则的前提下进行分区分配。
以上三种都基于eager协议,也就是想要重新分配分区一定要将原来的所有分区回收,全部打乱重新,即使保留原来的分区规则,也需要全部都回收分区,这样效率非常低下,最后一种CooperativeSticky分区策略完全打破以上三种的分区关系。
5. CooperativeSticky分区
以粘性为主,但是不全部收回分区,只是将部分需要重新分配的分区重新调配,效率高于以上三种分区策略。
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,CooperativeStickyAssignor.class.getName());
//设定分区策略运行两个实例,查看控制台信息发现:
运行第一个消费者实例:
consumer1:
分配了14个分区:
assign-->topic_f-->0
assign-->topic_f-->1
assign-->topic_f-->2
assign-->topic_f-->3
assign-->topic_f-->4
assign-->topic_f-->5
assign-->topic_f-->6
assign-->topic_g-->0
assign-->topic_g-->1
assign-->topic_g-->2
assign-->topic_g-->3
assign-->topic_g-->4
assign-->topic_g-->5
assign-->topic_g-->6运行第二个消费者实例:
consumer1:
回收7个分区:与前三种分区规则不同,前三种是分配分区的时候将所有分区全部收回
revoke-->topic_g-->0
revoke-->topic_g-->1
revoke-->topic_g-->2
revoke-->topic_g-->3
revoke-->topic_g-->4
revoke-->topic_g-->5
revoke-->topic_g-->6详细信息:
Assigned partitions: [topic_f-0, topic_f-1, topic_f-2, topic_f-3, topic_f-4, topic_f-5, topic_f-6]
Current owned partitions: [topic_f-0, topic_f-1, topic_f-2, topic_f-3, topic_f-4, topic_f-5, topic_f-6]
Added partitions (assigned - owned): []
Revoked partitions (owned - assigned): []
consumer2:
分配七个分区:
assign-->topic_g-->0
assign-->topic_g-->1
assign-->topic_g-->2
assign-->topic_g-->3
assign-->topic_g-->4
assign-->topic_g-->5
assign-->topic_g-->6详细情况:
Assigned partitions: [topic_g-0, topic_g-1, topic_g-2, topic_g-3, topic_g-4, topic_g-5, topic_g-6]
Current owned partitions: []
Added partitions (assigned - owned): [topic_g-0, topic_g-1, topic_g-2, topic_g-3, topic_g-4, topic_g-5, topic_g-6]
Revoked partitions (owned - assigned): []整个分区分配规则和粘性分区策略一致,但是并不需要收回全部分区。
系统默认分区分配规则为:。
range+CooperativeSticky。
范围分区为主,优先粘性并且不急于eager协议。
6. 指定分区消费
在计算处理过程中,有时候我们需要指定一个消费者组消费指定的分区,计算其中的数据,这个时候以上的所有分区策略都不符合我们人为的要求,我们需要指定相应的分区进行消费。
consumer.assign();
//用指定的方式定向消费相应的分区数据整体代码如下:
package com.hainiu.kafka.consumer;
/**
* ClassName : rangeAssigned
* Package : com.hainiu.kafka.consumer
* Description
*
* @Author HeXua
* @Create 2024/11/4 22:04
* Version 1.0
*/
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class Assigned {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group2");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, CooperativeStickyAssignor.class.getName());
pro.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,6000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<TopicPartition> list = Arrays.asList(
new TopicPartition("topic_f", 0),
new TopicPartition("topic_g", 0)
);
consumer.assign(list);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}我们只消费topic_e的0号分区和topic_d的0号分区
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【大数据学习 | kafka】消费者的分区分配规则

发表评论 取消回复