目录

1.创建线程的五种写法
1.1 继承Thread类
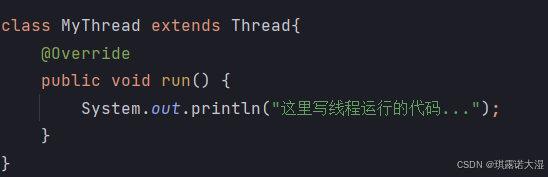
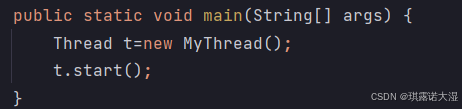
详细见上篇文章
1.2 实现Runnable接口
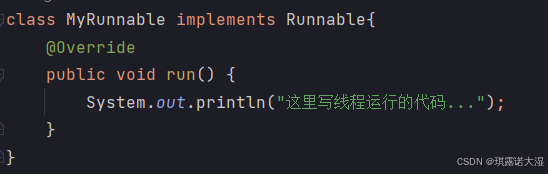
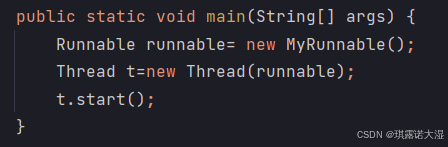
详细见上篇文章
1.3 使用匿名内部类
创建Thread内部类,并在Thread内部类里面重写run方法:
public static void main(String[] args) {
Thread t=new Thread(){
@Override
public void run() {
System.out.println("Hello Thread");
}
};
t.start();
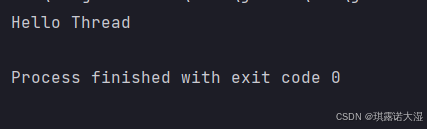
}
【注意】
使用匿名内部类可以少定义一些类(比如上面代码就省去了MyThread类)。
一般如果某个代码是“一次性的”,就可以使用匿名内部类。
1.4 使用Runnable,匿名内部类
创建Runnable内部类,并在其内部重写run方法,最后作为构造方法的参数传入Thread类:
public static void main(String[] args) {
Thread t=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello Thread");
}
});
t.start();
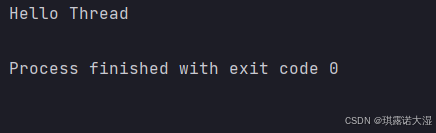
}
1.5 引入lambda表达式
针对写法三和写法四进一步改进,引入lambda表达式。
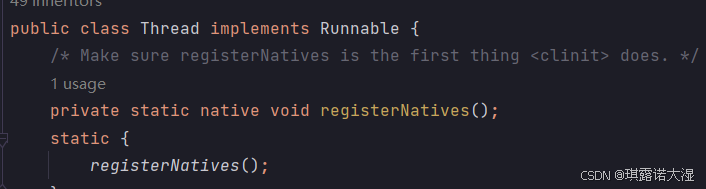
进入Thread类的定义文件可以发现Thread类是实现了Runnable接口的:
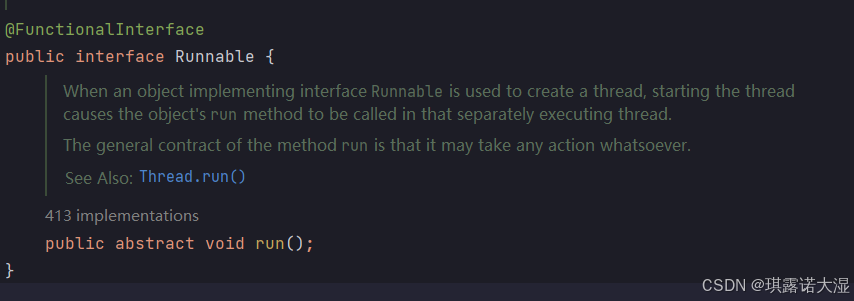
再接着进入Runnable接口,会发现Runnable其实是一个函数式接口:
对于函数式接口,可以使用lambda表达式来重写run方法:
public static void main(String[] args) {
Thread t=new Thread(()->System.out.println("Hello Thread"));
t.start();
}一般推荐使用lambda表达式的写法。
2.Thread类及常见方法
2.1 认识Thread
Thread 类是 JVM ⽤来管理线程的⼀个类,换句话说,每个线程都有⼀个唯⼀的 Thread 对象与之关联。⽤我们上⾯的例⼦来看,每个执⾏流,也需要有⼀个对象来描述,⽽ Thread 类的对象就是⽤来描述⼀个线程执⾏流的,JVM 会将这些 Thread 对象组织起来,⽤于线程调度,线程管理。
2.2 Thread的常见构造方法

对上述五个构造方法的解释:
1.创建线程对象
2.使用Runnable对象创建线程对象
3.创建线程对象,并命名
4.使用Runnbale对象创建线程对象,并命名
5.线程可以用来分组管理,分好的组即为线程组
对三个线程分别命名为t1,t2,t3:
public static void main(String[] args) {
Thread t1=new Thread(()->{
while (true){
System.out.println("Hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
},"t1");
Thread t2=new Thread(()->{
while (true){
System.out.println("Hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
},"t2");
Thread t3=new Thread(()->{
while (true){
System.out.println("Hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
},"t3");
t1.start();
t2.start();
t3.start();
}运行代码,并在jconsole中观察线程,会发现t1,t2,t3线程,这三个线程就是上面代码创建出来并重命名的线程:
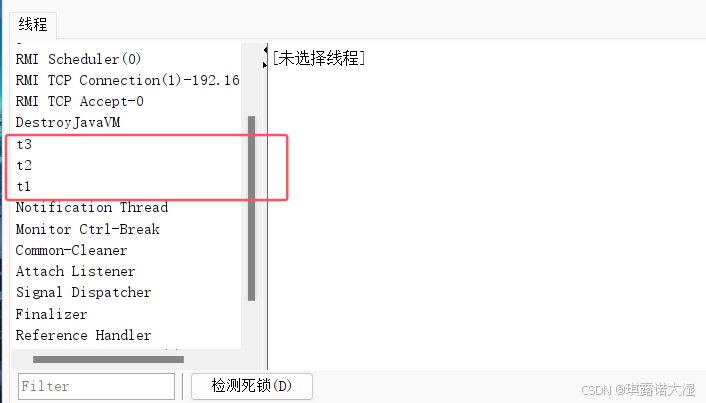
2.3 Thread的几个常见属性
| 属性 | 获取方法 |
| ID | getId() |
| 名称 | getName() |
| 状态 | getState() |
| 优先级 | getPriority() |
| 是否为后台线程 | isDaemon() |
| 是否存活 | isAlive() |
| 是否被中断 | isInterrupted() |
• ID 是线程的唯⼀标识,不同线程不会重复• 名称是各种调试⼯具⽤到的• 状态表示线程当前所处的⼀个情况,后面我们会进⼀步说明• 优先级高的线程理论上来说更容易被调度到• 关于后台线程,需要记住⼀点:JVM会在⼀个进程的所有非后台线程结束后,才会结束运⾏。• 是否存活,即简单的理解,为 run ⽅法是否运⾏结束了• 线程的中断问题,下⾯我们进⼀步说明
关于后台线程
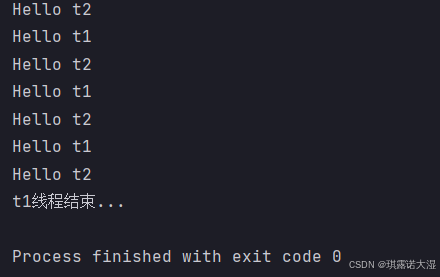
现有两个线程,将t2线程设置为后台线程(也叫守护线程),t1线程运行五秒,t2线程死循环,当t1线程结束时,不论t2(后台线程)有没有结束,整个进程都会结束:
public static void main(String[] args) {
Thread t1=new Thread(()->{
for (int i = 0; i < 5; i++) {
System.out.println("Hello t1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("t1线程结束...");
},"t1");
Thread t2=new Thread(()->{
while (true){
System.out.println("Hello t2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
},"t2");
t2.setDaemon(true);
t1.start();
t2.start();
}
像t1这种能影响到进程继续存在的线程就被成为前台线程。
一般自己创建的线程(包括main主线程)默认都是前台线程,可以通过setDaemon方法来修改。
使用jconsole观察线程,会发现除了我们自己创建的线程以外,JVM还自带了很多线程:
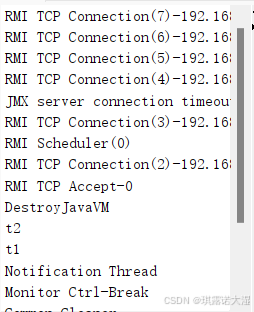
这些线程都是后台线程,当进程结束了,这些线程也就随之结束了。
JVM提供的这些线程都是属于有特殊功能的线程,会跟随整个进程持续执行的。
比如:垃圾回收线程
关于是否存活isAlive()
JAVA代码中创建的Thread对象,和系统中的线程是一 一对应的关系
但是,Thread对象的生命周期和系统中线程的生命周期是不同的。
(可能存在,Thread对象还存活,但是系统中的线程已经销毁的情况)案例如下:
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for (int i = 0; i < 3; i++) {
try {
System.out.println("Hello Thread");
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
while(true){
System.out.println(t1.isAlive());
Thread.sleep(1000);
}
}
线程组ThreadGroup
Thread(ThreadGroup group, String name)
线程组(不做详细介绍)
就是把多个线程放在一个组里
统一针对这个线程组里的所有线程进行一些属性设置
(比如:统一设置成后台线程)
2.4 启动一个线程 -start()
Java标准库/JVM提供的方法
本质上是调用操作系统的API
每个Thread对象,都是只能start一次的
每次想创建一个新的线程,都得创建一个新的Thread对象(不能重复利用)
如果一个对象多次创建线程(start):
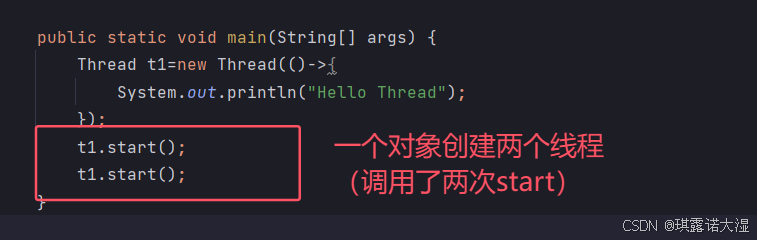
结果是报错:

Java中期望,Thread对象和操作系统中的线程是一一对应的
2.5 中断一个线程
中断一个线程,其实就是终止一个线程(该线程以后不会再恢复了)
在操作系统中,“中断”一次还有别的含义,不要混淆
使用自定义变量
先看一个案例:
在类里面定义一个成员变量isInterrupted,在main方法里通过改变isInterrupted的值来控制t1线程的终止:
public class Demo3 {
public static boolean isInterrupted=false;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
while(!isInterrupted){
System.out.println("Hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("线程结束...");
});
t1.start();
for (int i = 0; i < 3; i++) {
Thread.sleep(1000);
}
isInterrupted=true;
}
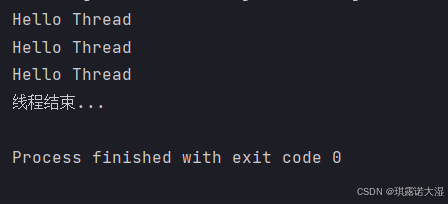
}
如果不用成员变量,而是把isInterrupted定义在main里面(作为局部变量),再执行代码就会报错:
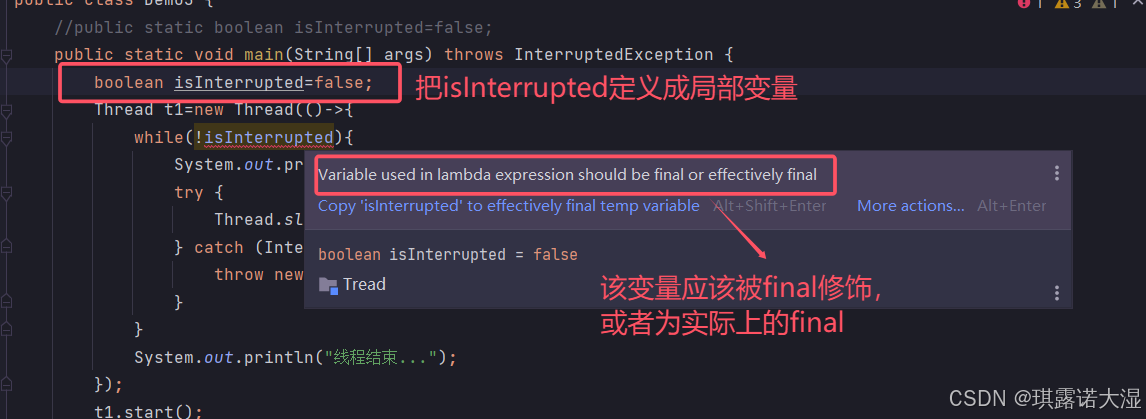
首先解释一下这个变量该如何修改正确:
1.用final修饰isInterrupted变量:
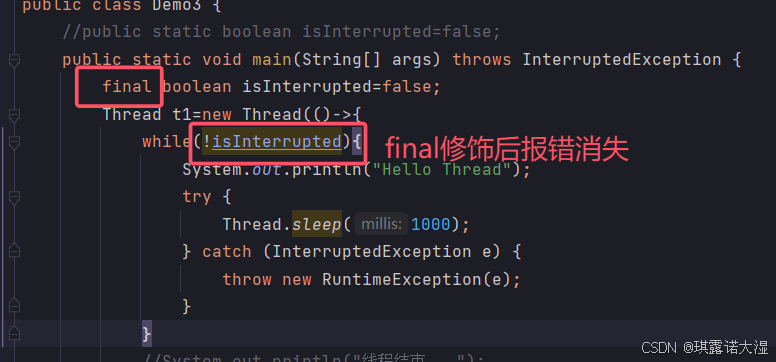
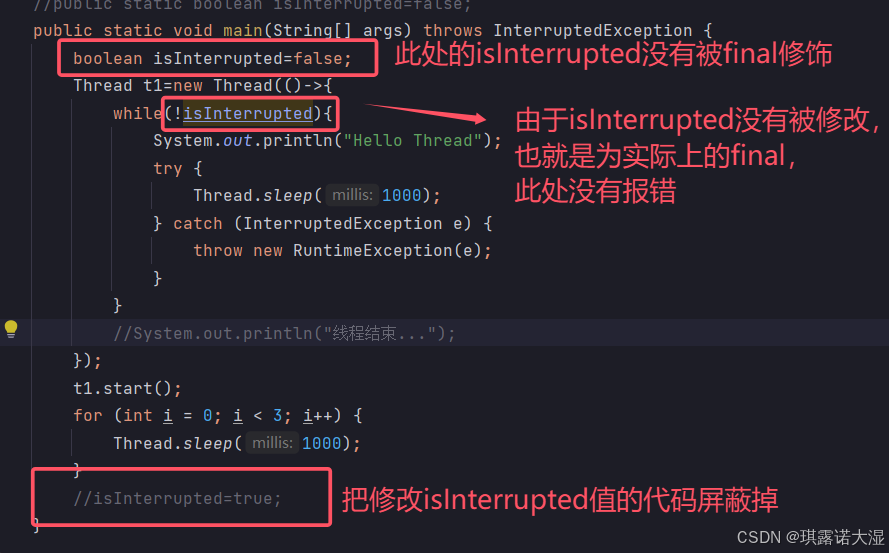
2.变量isInterrupted实际上为final,意思就是:isInterrupted不能被修改:
变量捕获
会有这样的现象,是因为:lambda里面希望使用外面的变量,就会触发“变量捕获”。
对于“变量捕获”的解释:
1.产生变量捕获的原因
lambda是回调函数,他要在操作系统真正创建出线程之后才会被执行。
因此很有可能会发生:当这个线程刚创建好的时候,main线程就已经结束了,isInterrupted变量也已经被销毁了。
2.“变量捕获”
为了解决上述的问题,Java的做法是,把lambda外面的变量拷贝一份到lambda里面,如此一般外面的变量无论销毁与否,都不会影响到lambda里面的执行。这个过程就是“变量捕获”
3.为什么不能修改变量
拷贝,就是把一个变量的值拷贝给另一个变量,本质上这两个变量是没有关联的。
由于这两个变量没有关联,修改了lambda外面的变量并不会影响到lambda里面的变量。
因此Java大佬干脆压根就不让程序员修改这个变量。
这就是为什么被捕获的变量必须为final或者effectively final 。
而使用成员变量的isInterrupted可以被修改,是因为:
1.lambda本质上是函数式接口,相当于一个内部类。
2.isInterrupted变量是外部类的成员。
3.内部类本来就可以访问外部类的成员。
4.成员变量的生命周期是由GC(垃圾回收线程)来管理的。在lambda里不必担心该变量生命周期失效的问题,也就不需要发生“变量捕获”,也就不必限制final之类。
使用Thread自带的属性
Java的Thread对象中提供了现成的变量,直接进行判定,不需要再自己创建了。
但是由于lambda里的定义是在new Thread之前的,也就是在Thread t声明之前,因此不能直接使用t1:
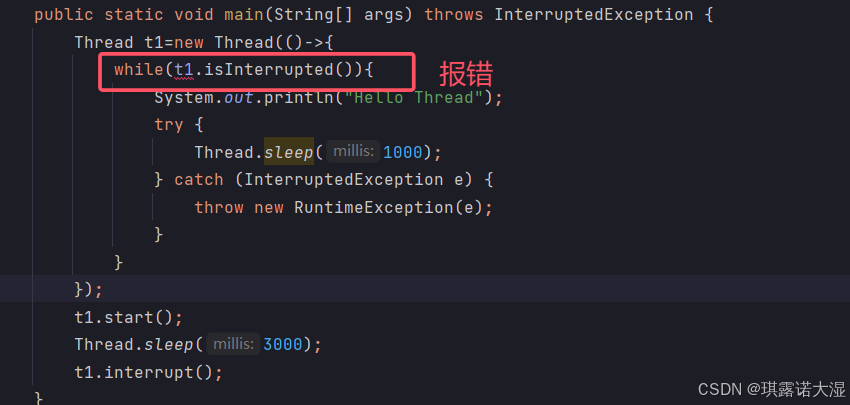
此时就需要用到获得当前线程引用的方法:Thread.currentThread()
这个方法可以返回当前线程的引用(相当于this):
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
while(!Thread.currentThread().isInterrupted()){
try {
System.out.println("Hello Thread");
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("线程结束...");
});
t1.start();
Thread.sleep(3000);
System.out.println("main线程尝试终止t1线程");
t1.interrupt();
}执行结果:
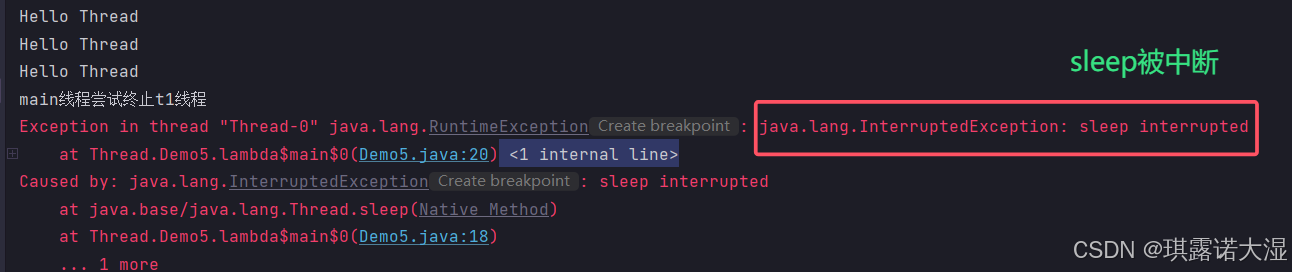
执行后系统抛出异常,异常原因:sleep被中断。
解释:
当t1.interrupt()执行时,此时t1线程内大概率还在处于sleep(1000)的状态,interrupted()的执行强行唤醒了sleep,因此就会抛出异常,异常被try catch捕获,然后抛出一个RuntimeException。
将抛出的RuntimeException给改成break就不会抛出异常了,但是sleep被唤醒的异常依旧存在:
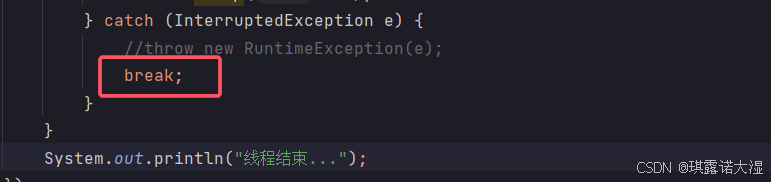
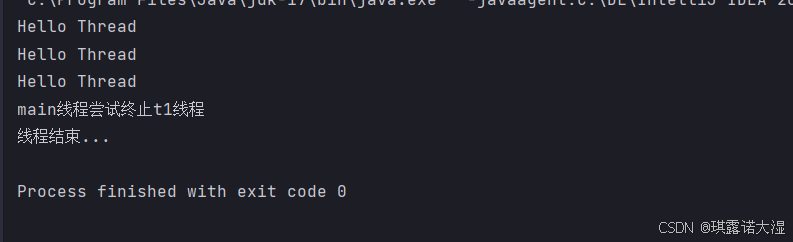
为什么要使用break?如果不加break(直接空着),这个线程就会继续死循环执行:
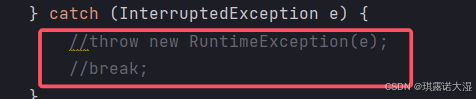

原因:
正常来说,调用Interrupt方法就会修改isInterrupted方法内部的标志位,设为true
由于上述代码中,是把sleep给强行唤醒了,这种提前唤醒的情况下,sleep就会在唤醒后,把isInterrupted的标志位设置回false
因此,while循环条件达成,会继续进行死循环执行
至于为什么要这样设计,个人认为是想让程序员拥有更多选择:
程序员可以自行决定,这个线程是要立即结束,要是等会再结束,还是不结束...
2.6 等待一个线程
方法:join()
作用:从此处开始阻塞等待,等到一个线程结束了再继续执行
案例:
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for (int i = 0; i < 3; i++) {
System.out.println("Hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("t1线程结束...");
});
t1.start();
t1.join();
System.out.println("main线程结束...");;
}
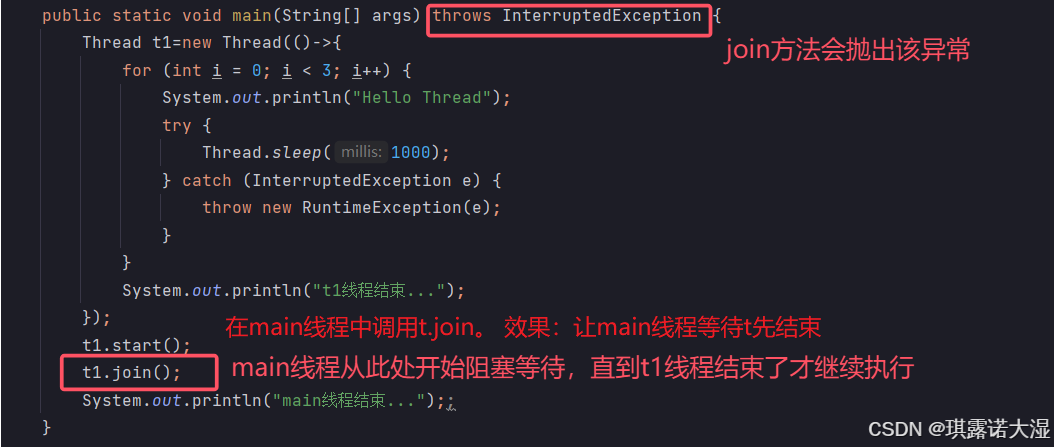
执行结果:
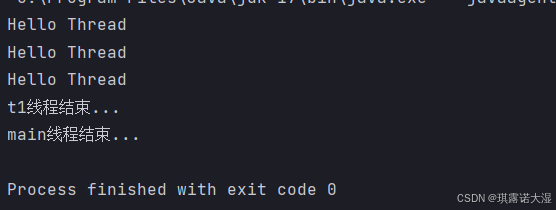
但是这样设计,只要线程t1不结束,主线程的join就会一直等待下去,这样并不科学。
因此Java提供了带参数的方法,可以指定超时时间(最大等待时间)
当等待的时间超出了设置好的超时时间,不论t1线程是否结束,main线程都继续执行。
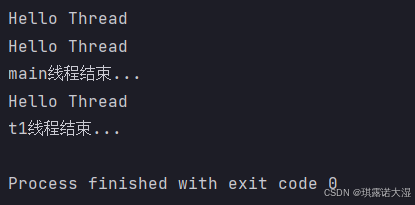
join方法还有带两个参数的版本:

一般不会用到纳秒这个参数:在计算机中,很难进行ns(纳秒)级别的精确时间的测量(误差比较大)。尤其是,线程本身的开销往往就会达到ms级别。
1s=1000ms
1ms=1000ns
1us=1000ns
2.7 获得当前线程的引用
方法:public static Thread currentThread();
作用:返回当前线程对象的引用(这个方法在哪个线程里就返回哪个线程的引用)
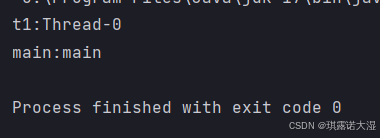
public static void main(String[] args) {
Thread t1=new Thread(()->{
System.out.println("t1:"+Thread.currentThread().getName());
});
t1.start();
System.out.println("main:"+Thread.currentThread().getName());
}
2.8 休眠当前线程:sleep
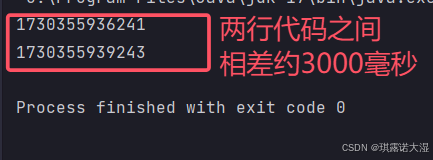
因为线程的调度是不可控的,所以,这个⽅法只能保证实际休眠时间是⼤于等于参数设置的休眠时间的。
语法:

public static void main(String[] args) throws InterruptedException {
System.out.println(System.currentTimeMillis());
Thread.sleep(1000*3);
System.out.println(System.currentTimeMillis());
}
完
如果哪里有疑问的话欢迎来评论区指出和讨论,如果觉得文章有价值的话就请给我点个关注还有免费的收藏和赞吧,谢谢大家

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » JavaEE-多线程初阶(2)

发表评论 取消回复