目录
1.DQL数据查询语言
分为五大基本查询语法

1.1基本查询
-- 查询特定字段
select name,entrydate from tb_emp;
-- 查询所有字段
select * from tb_emp;
-- 查询所有员工的 name,entrydate,并起别名(姓名、入职日期)
select name '姓名',entrydate '入职日期' from tb_emp;
-- 查询已有的员工关联了哪几种职位(不要重复)
select distinct job from tb_emp;1.2条件查询 where关键字

select * from tb_emp where name = '陈友谅';
select * from tb_emp where job is null;1.3分组查询
首先需要知道一个知识点:聚合函数,就是对某一列的数据所作的操作

select count(id) from tb_emp;
select count(job) from tb_emp;
-- 通配符*计算总数据量
select count(*) from tb_emp;
-- 统计最早入职的员工
select min(entrydate) from tb_emp;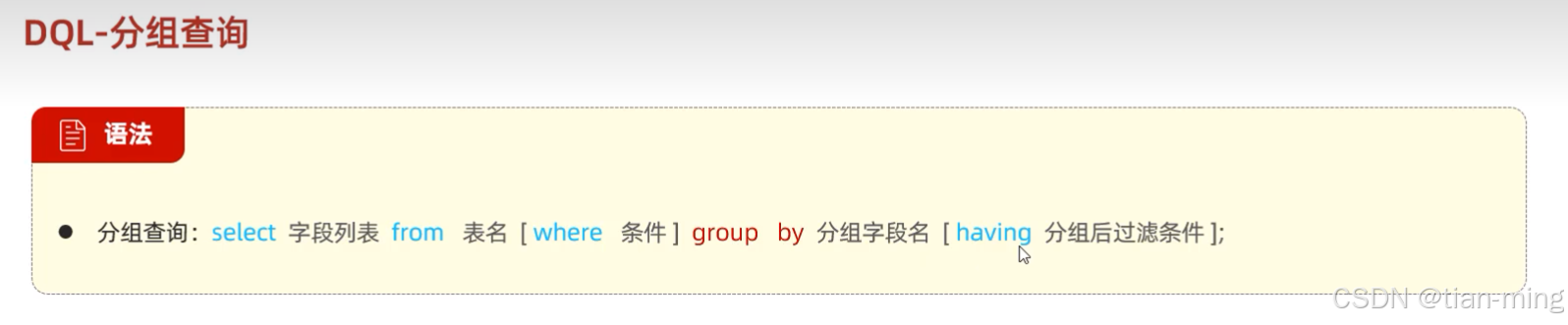
例:先査询入职时间在'2015-01-01'(包含)以前的员工,并对结果根据职位(job)分组 ,获取员工数量大于等于2的职位
select job,count(*) from tb_emp where entrydate <= '2015-01-01'
group by job having count(*) >= 2;where与having区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以
1.4排序查询

排序方式:ASC升序(默认值)、DESC降序
-- 默认升序
select * from tb_emp order by entrydate;
-- 降序
select * from tb_emp order by entrydate desc ;
-- 多个排序字段
select * from tb_emp order by entrydate, update_time desc;1.5分页查询

-- 从 起始索引0 开始査询员工数据,每页展示5条记录
select * from tb_emp limit 0, 5;2.多表设计
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)
- 多对多
- 一对一
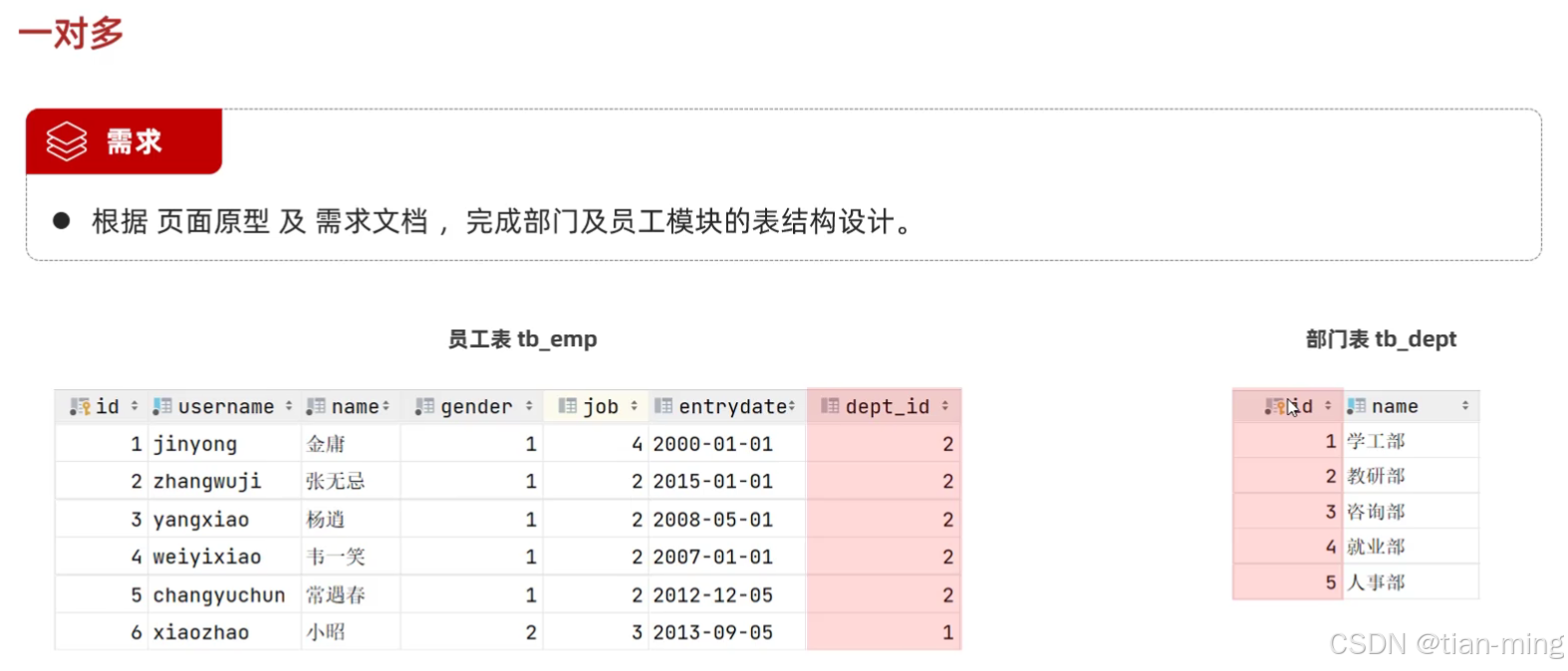
但是目前上述的两张表,在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性,比如说我在部门表中把“教研部”删除,员工表中教研部的员工依然存在,这显然是不合理的,所以就需要“外键约束”

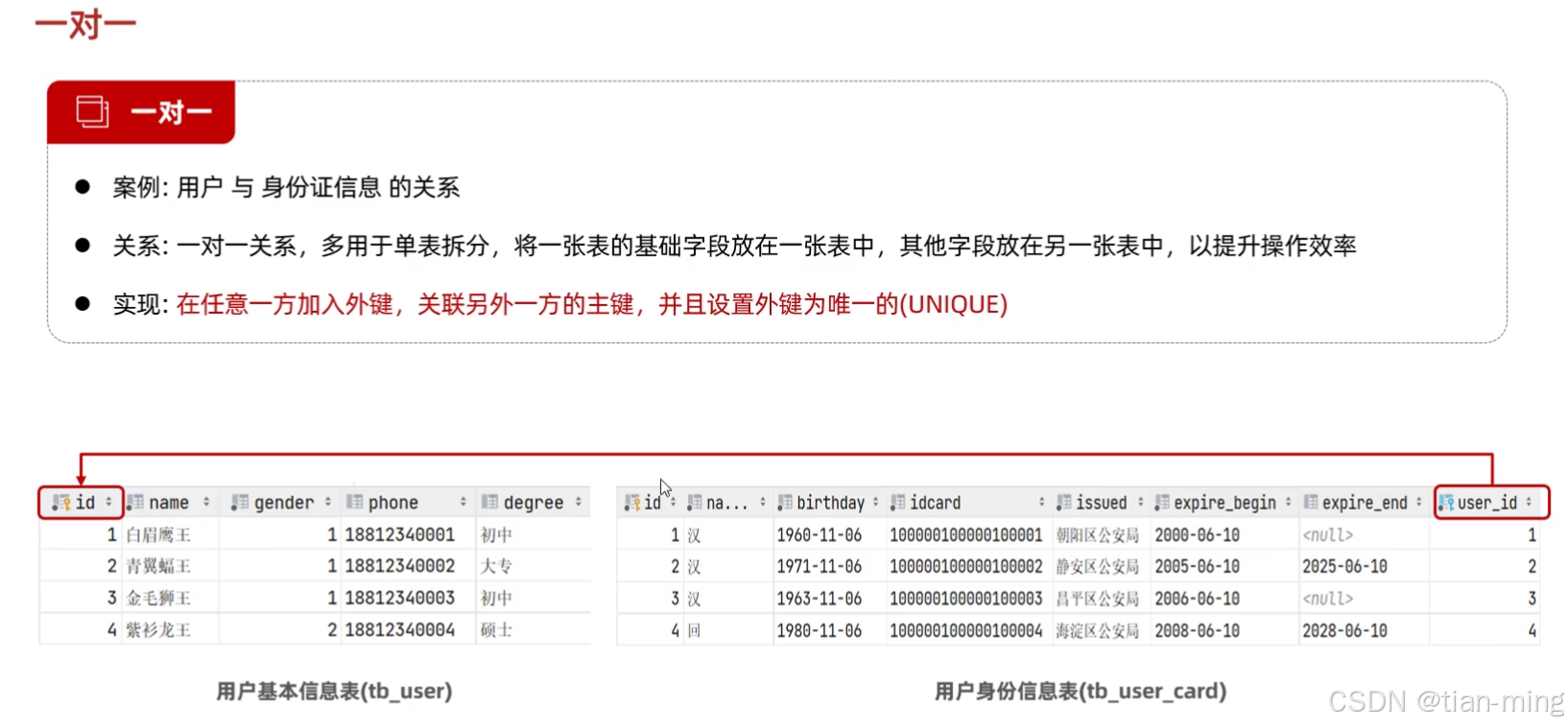
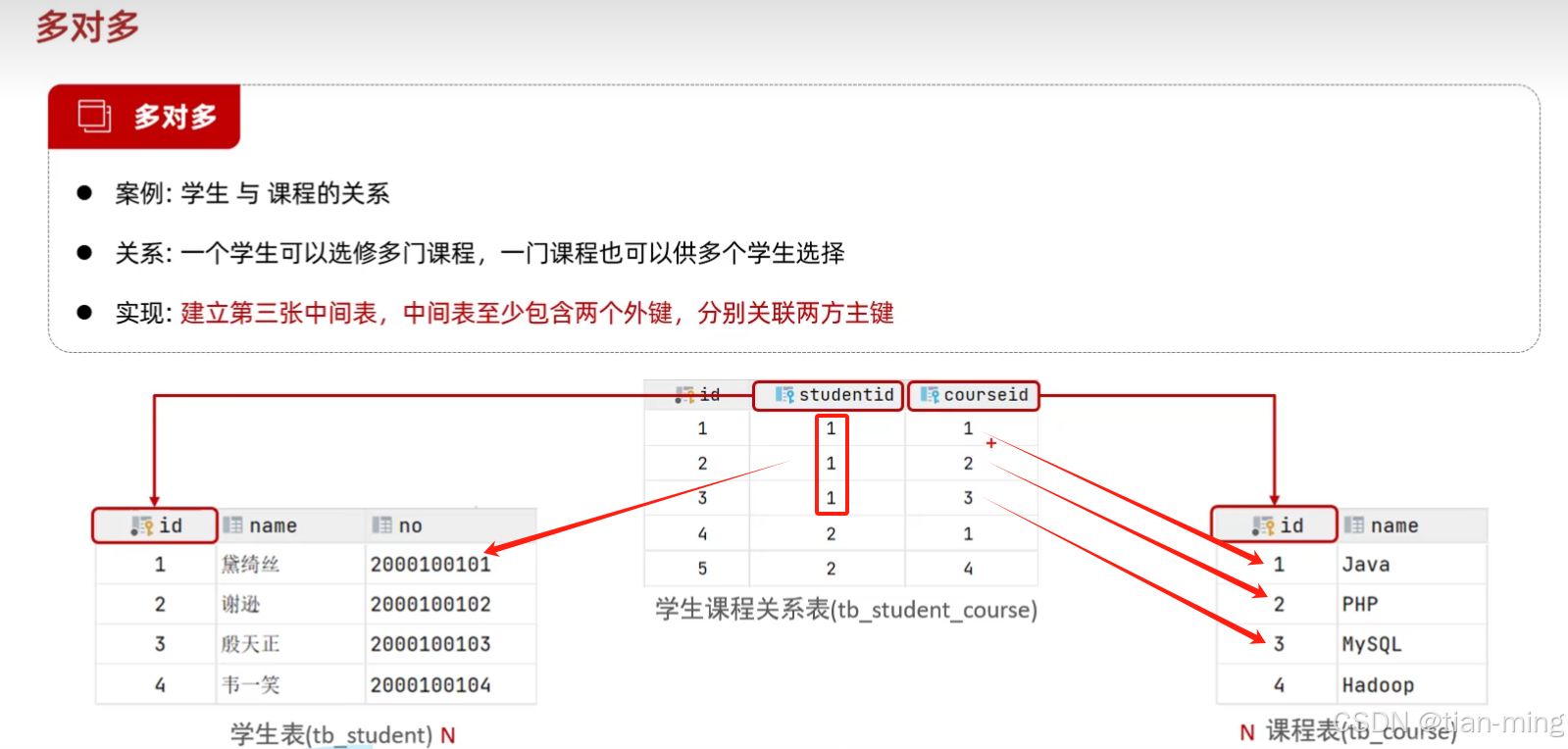
3.多表查询——联查
如果单纯执行下面的指令会出现问题——笛卡尔积
-- 多表查询
select * from tb_emp, tb_dept;
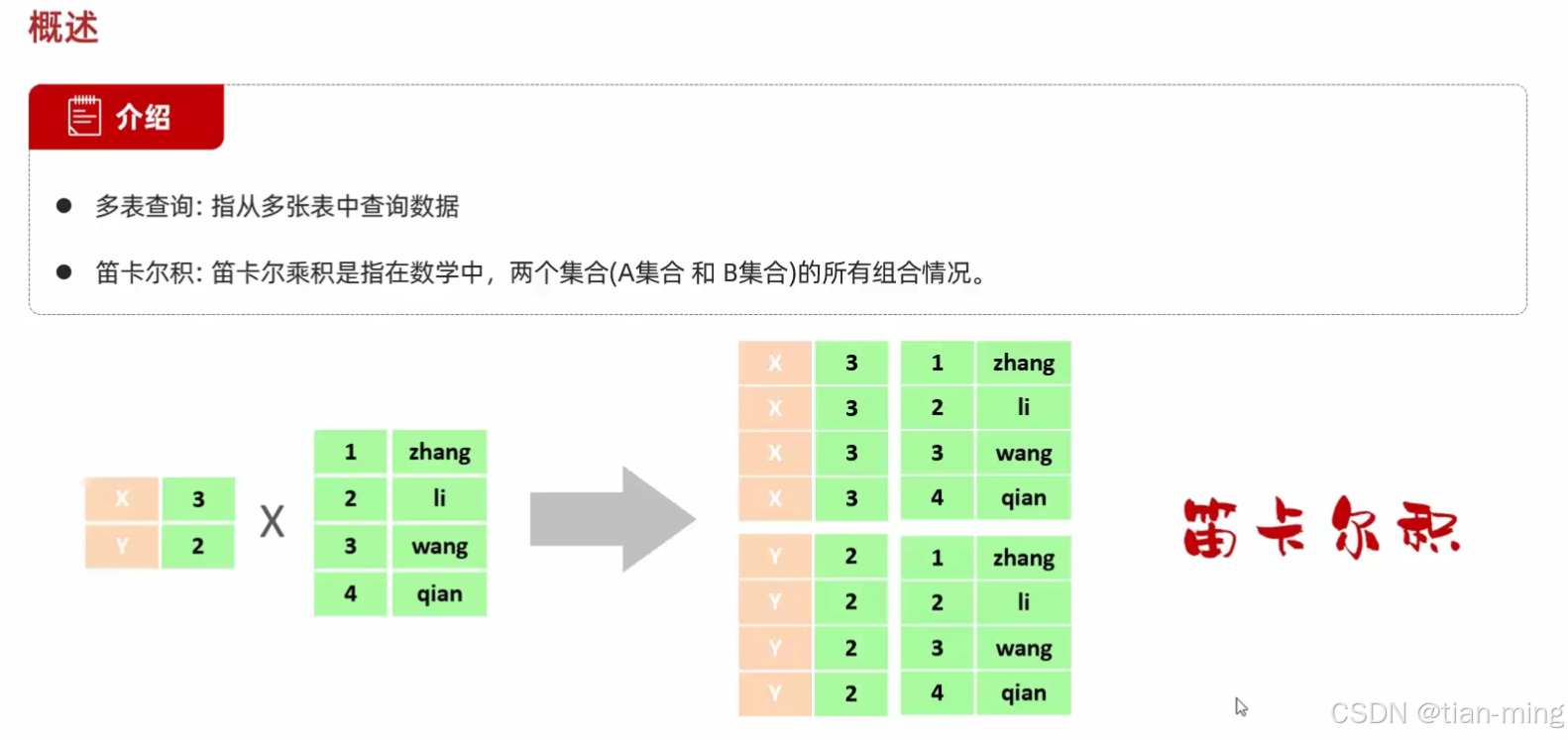
要解决这个问题只需要令员工的部门id = 部门主键id即可
select * from tb_emp, tb_dept where tb_emp.dept_id = tb_dept.id;

左外连接完全包含左表数据,右外连接完全包含右表数据
4.多表查询——子查询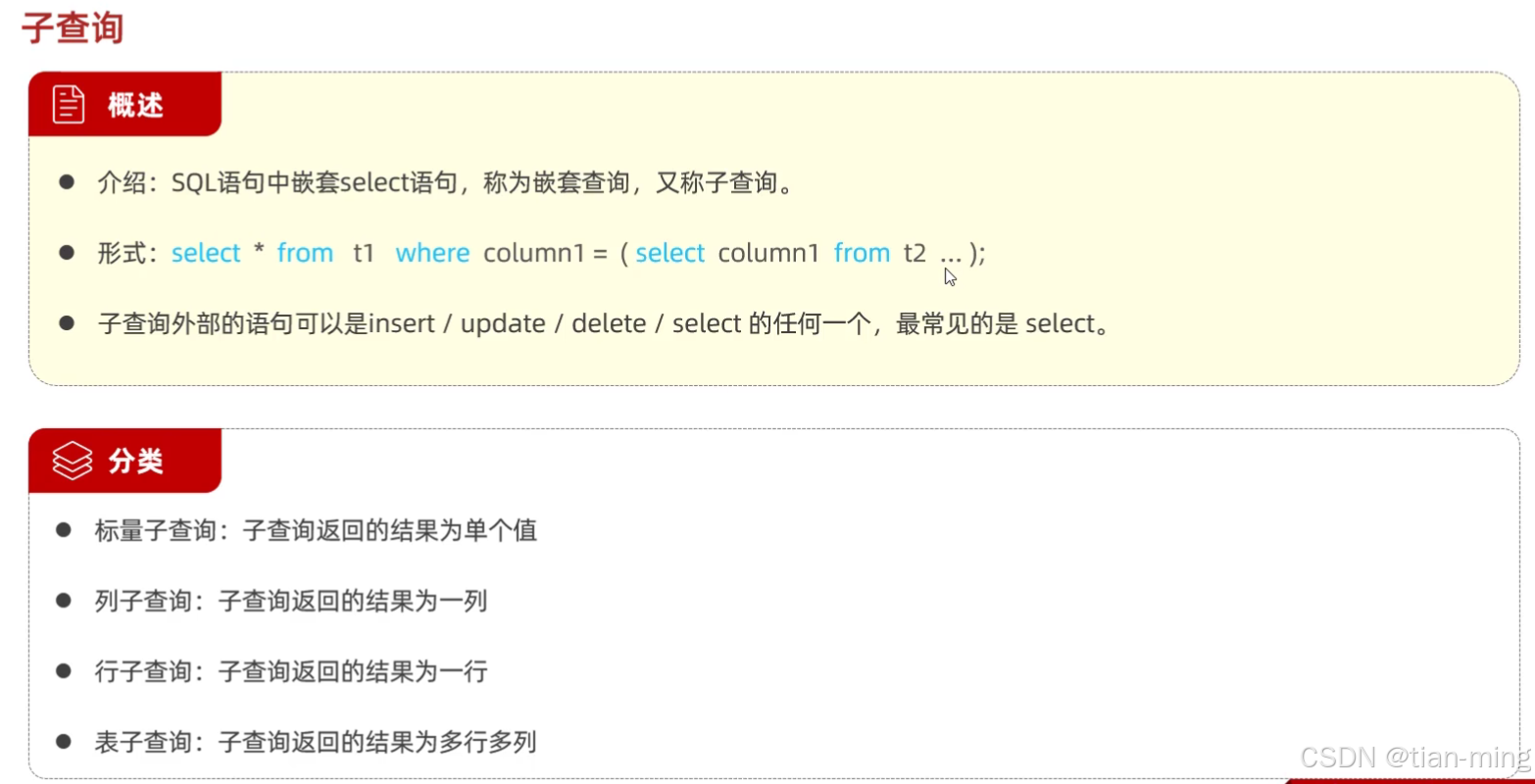
5.MySQL 事务
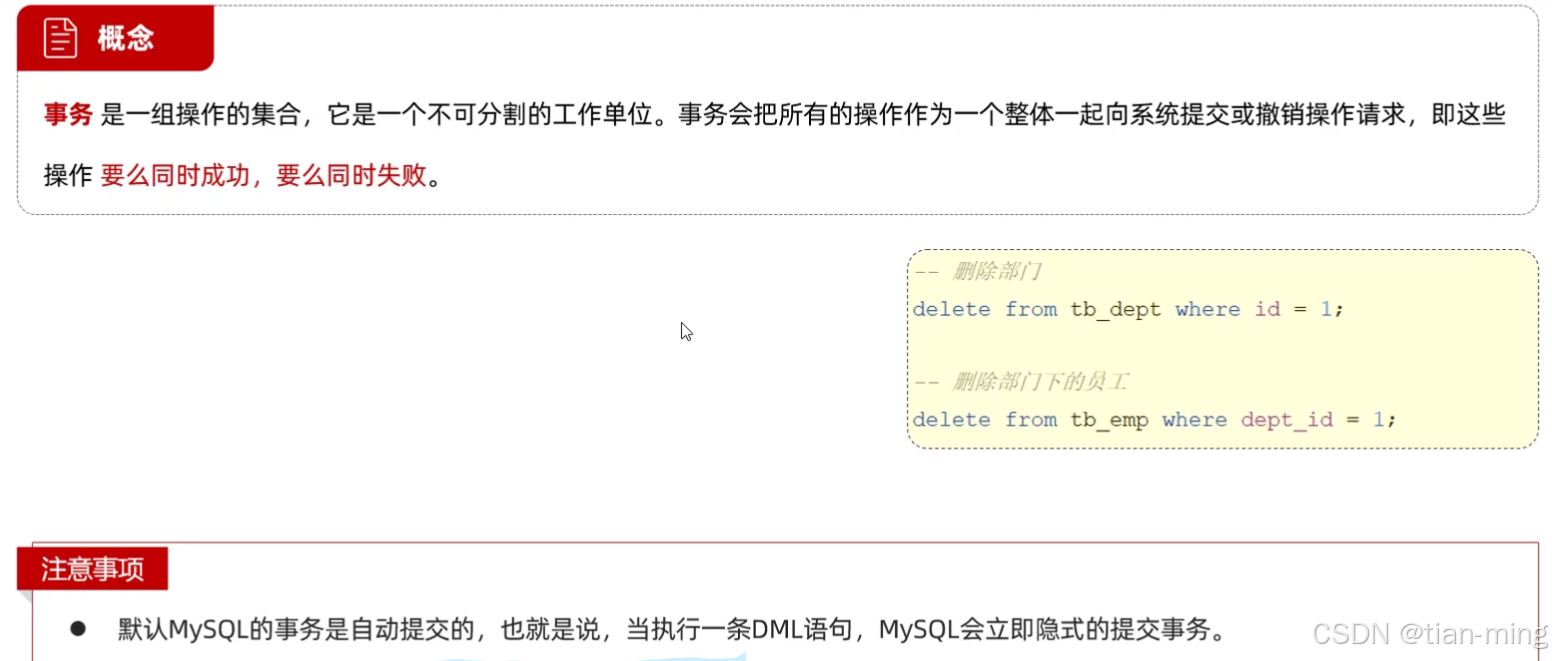
-- 事务
-- 删除部门
delete from tb_dept where id = 3;
-- 删除部门下的员工
delete from tb_emp where dept_id = 3;在上面的代码中,删除部门成功了,但是删除该部门下的员工失败了,就是因为这两个操作分属两个事务,解决办法是把这两个操作控制在一个事务内

-- 开启事务
start transaction ;
-- 删除部门
delete from tb_dept where id = 3;
-- 删除部门下的员工
delete from tb_emp where dept_id = 3;
-- 提交事务
commit ;
-- 回滚事务
rollback ;
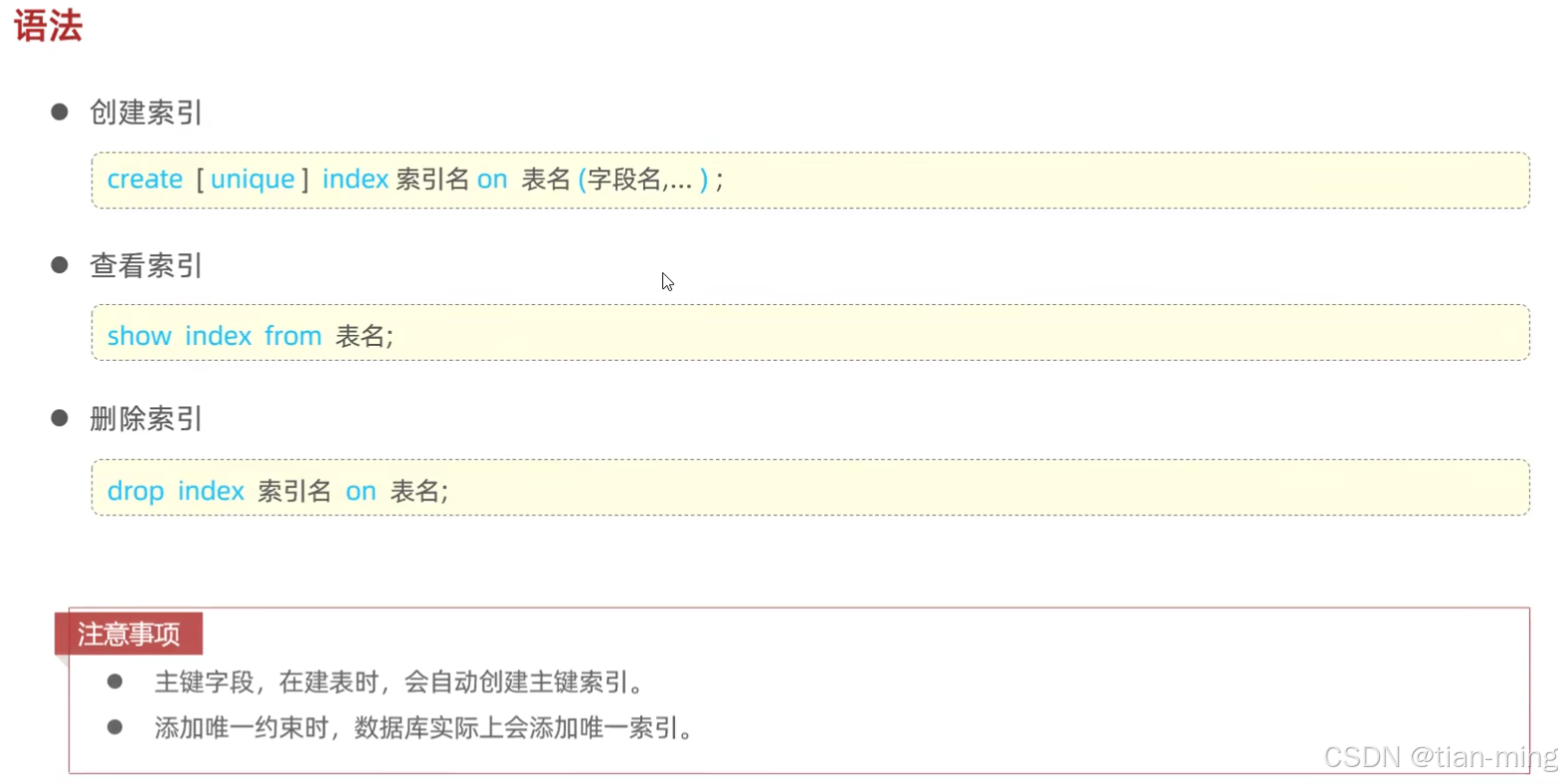
6.MySQL 索引
使用普通的sql查询语言效率很低,比如在600w的数据量里查询数据往往需要十几秒的时间,索引能大幅提高查询效率
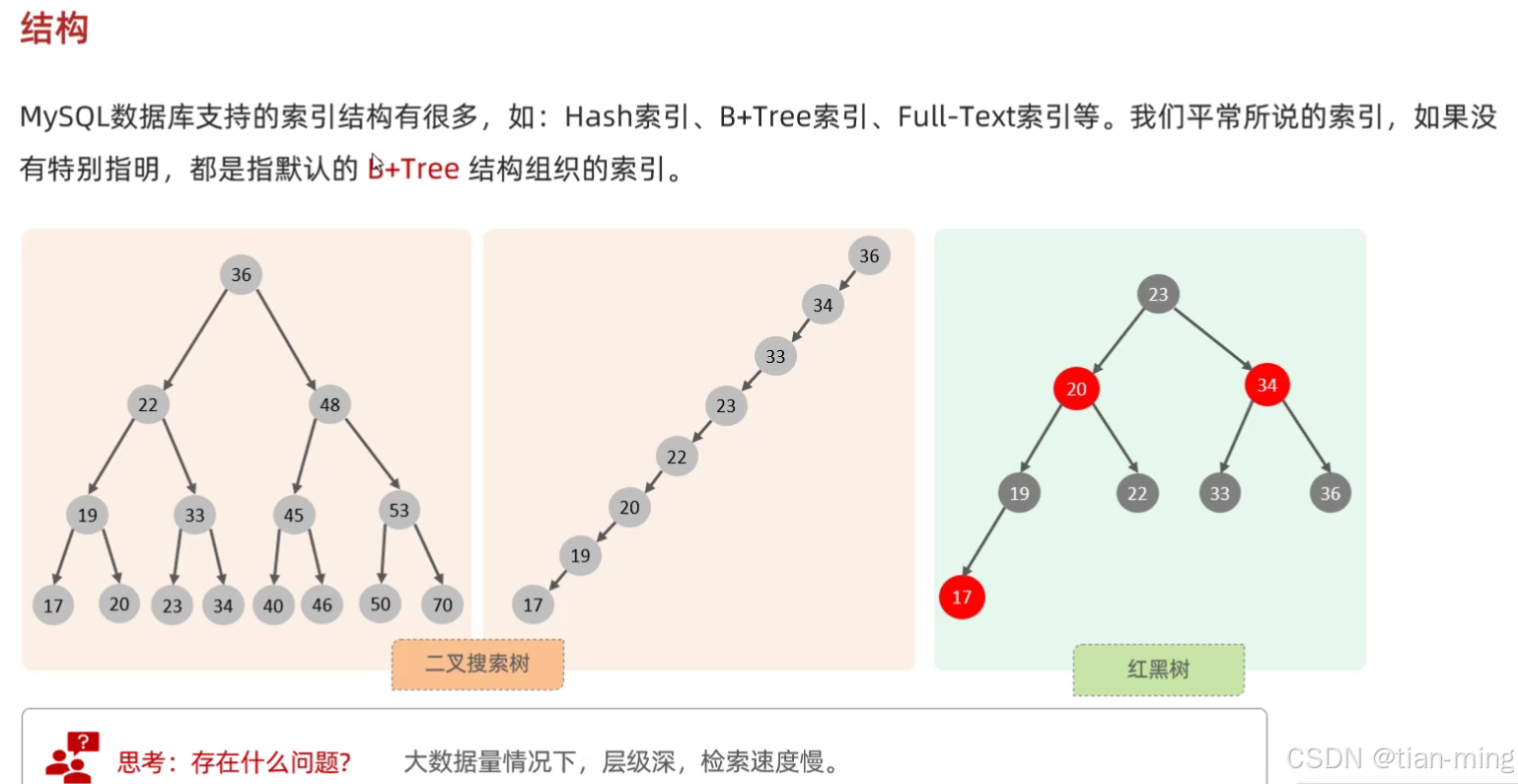
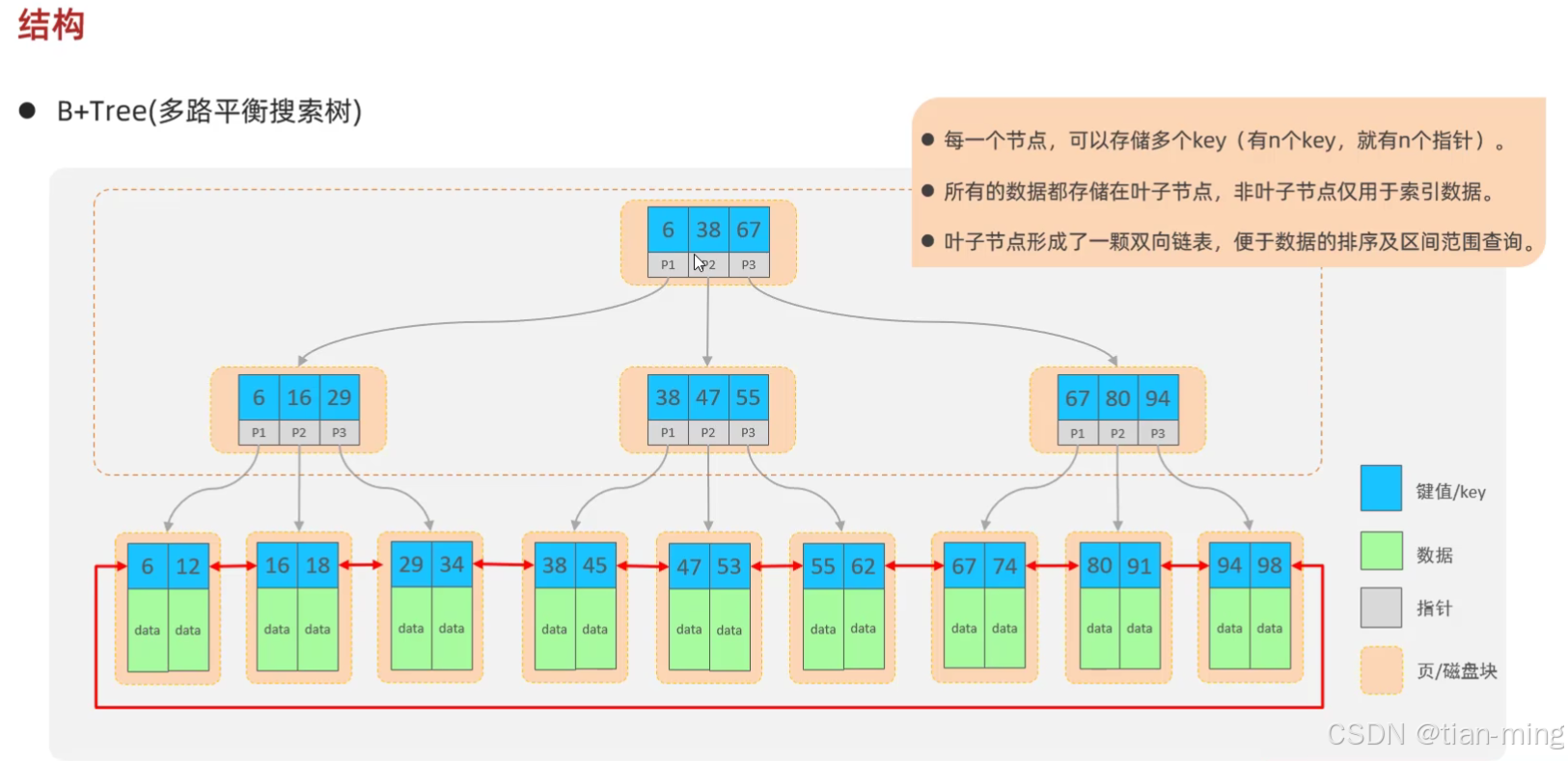
索引(index)是帮助数据库高效获取数据的数据结构(底层实现是二叉搜索树)
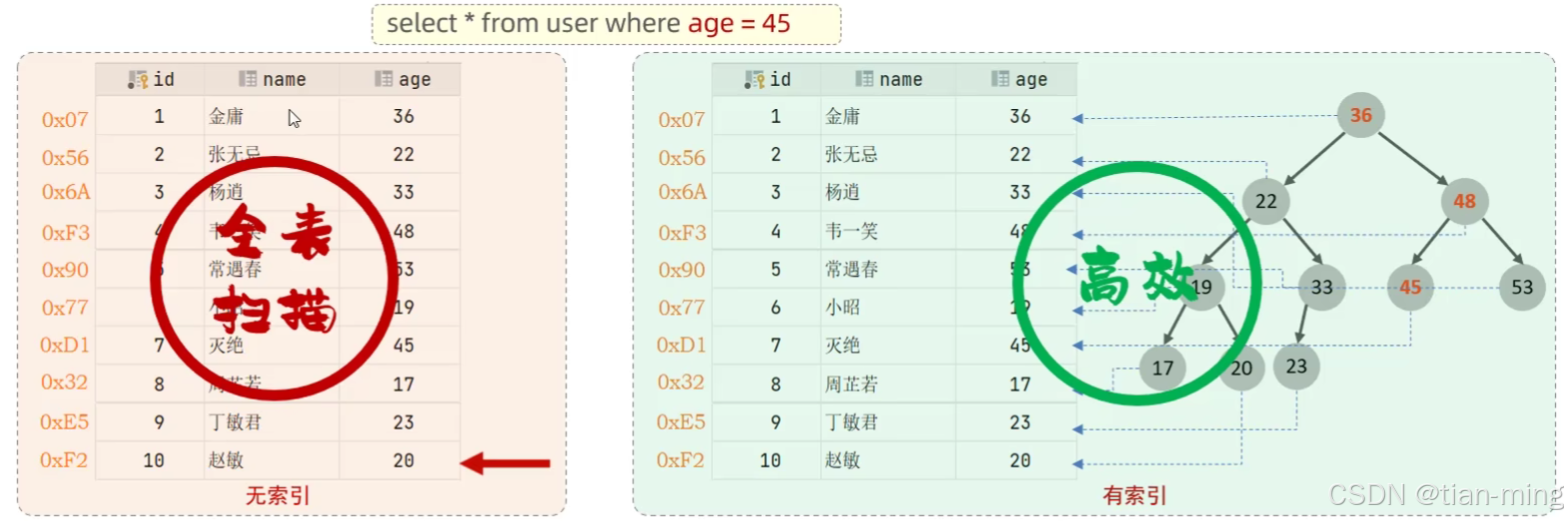
优点:
- 提高数据查询的效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗
缺点:
- 索引会占用存储空间,
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » (十三)JavaWeb后端开发——MySQL2

发表评论 取消回复