文章目录
论文:Boundary-guided network for camouflaged object detection(用于伪装物体探测的边界引导网络)
论文链接:Boundary-guided network for camouflaged object detection
代码链接:Github
1.Introduction
伪装目标检测(Camouflaged Object Detection)旨在识别“完美”融入周围环境的伪装目标。现有的方法主要采用卷积神经网络来利用丰富的上下文信息定位潜在目标,但由于伪装区域的纹理常常具有欺骗性,甚至可能与周围环境相同,此时就需要更多类型的信息。事实上,目前的方法普遍侧重于目标主要位置的检测,很少关注边界细化,故而得到预测图的边界图往往较为粗糙。
本文提出了一种用于COD任务的边界引导模型BgNet(Boundary-guided Network),其使用全局分支挖掘丰富的上下文信息,使用本地分支捕获丰富的低级特征,当全局上下文信息不足时,从本地分支中提取的特征可以提供信息线索以促进检测。相关贡献如下:

- 1.提出定位模块(LM,Locating Module)来推断伪装对象的初始位置。BgNet采用双骨干架构,从第一个分支提取分层特征,并通过LM模块推断伪装对象的初始位置,从而聚合多级特征。在获得伪装区域的初始位置后,可以计算出相应的边界图。
- 2.提出边界导向融合模块(BFM,Boundary-guided Fusion Module)解决粗略边界问题。在边界特征的引导下整合从骨干网络第二个分支中提取的特征,BFM会利用输入特征生成前景特征和背景特征。由于边界区域是前景区域和背景区域的交集,因此可利用这点反向优化边界特征,生成具有更清晰边界的结果。
2.Related work
边缘感知模型:现有的方法主要将边界信息作为补充线索来提炼区域特征,并未探索区域特征和边界特征之间复杂的互补关系,也很少关注细化边界特征。本文提出的边界导向融合模块(BFM,Boundary-guided Fusion Module)用于探索前景和背景信息,同时细化边界和区域特征,以提高模型性能。
3.Methodology
3.1Overview of the proposed BgNet
BgNet模型主要由三种组件构成:
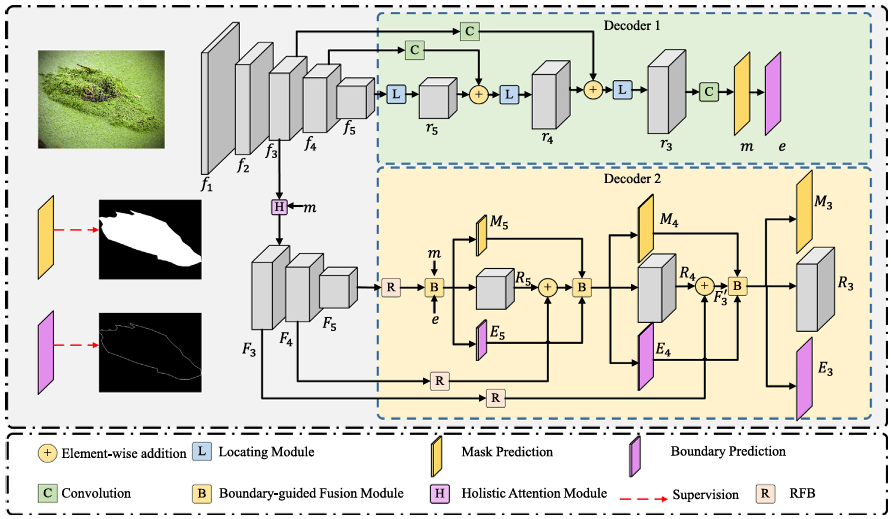
- 1.双主干编码-解码器结构。
- (1)第一个解码器:挖掘多类型数据定位目标,生成区域、边界预测图以优化第二个编码器分支的特征。
- (2)第二个解码器:聚合从第二个编码器分支中提取的特征以生成最终结果,生成有清晰边界的预测图。
- 2.定位模块(LM,Locating Module)。
- 3.提出边界导向融合模块(BFM,Boundary-guided Fusion Module)。
编码器主干采用
R
e
s
N
e
t
50
ResNet50
ResNet50结构,设输入图像
I
I
I,从编码器中可获得五个层次的特征
f
i
,
i
∈
{
1
,
2
,
3
,
4
,
5
}
f_i,i∈\{1,2,3,4,5\}
fi,i∈{1,2,3,4,5}。由于低级特征对最终性能的贡献小于高级特征,并显著增加了推理时间,因此丢弃了浅层特征
f
1
,
f
2
f_1,f_2
f1,f2,其余特征则被送入第一个解码器生成区域、边界预测图。整体过程表示为:
其中,
L
M
LM
LM表定位模块LM。最后,将
r
3
r3
r3输入
3
×
3
3×3
3×3卷积获取粗略区域预测图
m
m
m,并使用平均池化层获取相应的粗略边界预测图
e
e
e。计算公式:
其中,
a
b
s
abs
abs表绝对值函数,
P
a
v
g
P_{avg}
Pavg表
3
×
3
3×3
3×3平均池化层。区域预测图与
f
3
f_3
f3被送入整体注意力模块(HAM)来突出整个目标区域来得到细化特征图
F
3
F_3
F3,计算公式:
之后将其送入第二分支编码器中生成
F
4
、
F
5
F_4、F_5
F4、F5。
第二分支输入包括增强后的区域特征图
F
3
F_3
F3、粗略区域预测图
m
m
m、粗略边界预测图
e
e
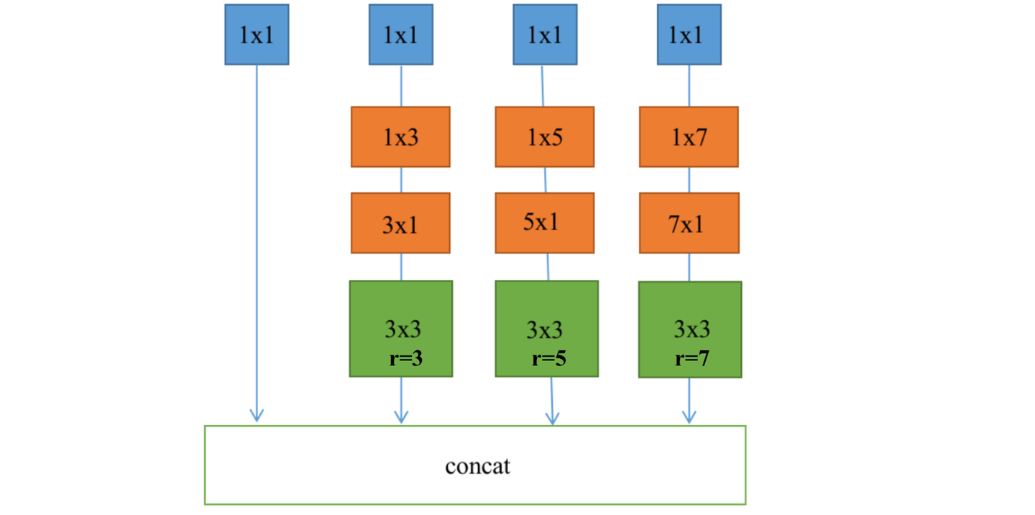
e。首先使用感受野模块(RFB,Receptive Field Block,见论文Cascaded Partial Decoder for Fast and Accurate Salient Object Detection,结构如上图所示)扩大感受野大小,并利用多尺度信息使整个模型对尺度变化具有鲁棒性。之后将优化后的特征与粗略区域预测图
m
m
m、粗略边界预测图
e
e
e共同送入
B
F
M
BFM
BFM模块生成边界增强的结果。之后不断重复这一过程,生成不同层级的边界图、区域图,计算流程如下:
其中,
M
3
,
M
4
,
M
5
M_3,M_4,M_5
M3,M4,M5是区域预测图,
E
3
,
E
4
,
E
5
E_3,E_4,E_5
E3,E4,E5是边界预测图。
其中,第二分支解码器的六个侧输出
M
3
,
M
4
,
M
5
,
E
3
,
E
4
,
E
5
M_3,M_4,M_5,E_3,E_4,E_5
M3,M4,M5,E3,E4,E5和第一分支解码器生成的粗略区域预测图
m
m
m上采样为原始图像大小后共同加入损失函数,而粗略边界预测图
e
e
e不加入损失函数中。
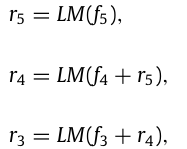
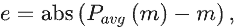
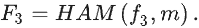
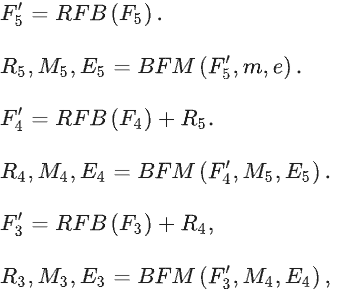
3.2Locating module
定位模块LM(Locating module)旨在利用多种类型信息准确定位潜在的伪装对象。LM模块包含两个分支:
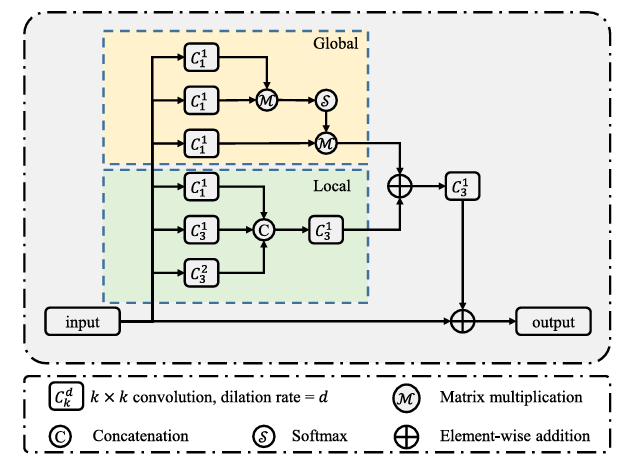
- 1.全局分支:捕获丰富的上下文信息增强语义表示。
- 2.本地分支:使用多个卷积层来挖掘局部细节,有助于在上下文线索不足的情况下提供信息丰富的边缘信息来识别目标。
在全局分支中使用三个
1
×
1
1 × 1
1×1卷积层生成查询特征
Q
Q
Q、关键功能
K
K
K和 值功能
V
V
V。设输入特征图
F
∈
R
c
×
h
×
w
F∈R^{c×h×w}
F∈Rc×h×w,
Q
Q
Q和
K
K
K通道设为
c
4
\frac{c}{4}
4c以节省计算开销。之后将
Q
Q
Q和
K
K
K重塑为
R
c
4
×
n
,
n
=
h
×
w
R^{\frac{c}{4}×n},n=h×w
R4c×n,n=h×w,
V
V
V重塑为
R
c
×
n
R^{c×n}
Rc×n。应用
s
o
f
t
m
a
x
softmax
softmax函数生成全局空间注意力图
S
A
g
∈
R
n
×
n
SA_g∈R^{n×n}
SAg∈Rn×n,将其与
V
V
V相乘得到全局分支的输出:
在全局分支中使用三个不同核大小的卷积层进行卷积,将结果
C
o
n
c
a
t
Concat
Concat后再次卷积以获得本地分支的输出。计算公式:
由于本地分支中的卷积核大小相对较小,这使得本地分支可更加关注局部边缘信息。
最后,将两分支的输出通过元素加法融合,并送入
3
×
3
3×3
3×3卷积层进一步细化,再与输入残差连接得到最终输出。计算公式:
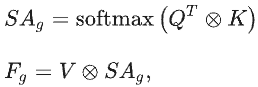
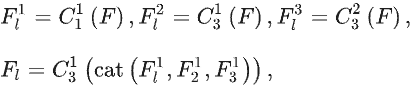
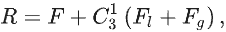
3.3Boundary-guided fusion module
边界导向融合模块(BFM,Boundary-guided Fusion Module)以特征图
I
f
I_f
If、区域预测图
I
m
I_m
Im、边界预测图
I
e
I_e
Ie作为输入,包括两个步骤:
【步骤一】
利用乘法操作得到前景特征
F
f
F_f
Ff与背景特征
F
b
F_b
Fb:
将两个特征图与边界预测图
I
e
I_e
Ie融合,得到边界增强前景、背景特征图:
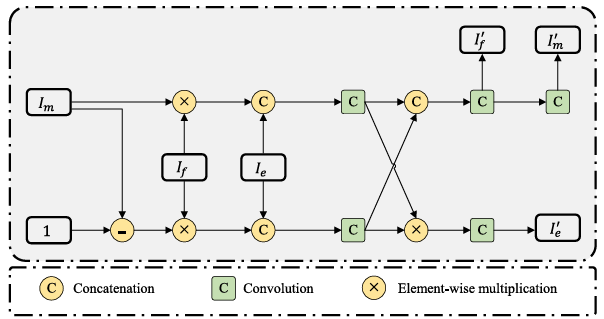
之后将二者送入卷积层,以在信息丰富的边缘信息的指导下同时探索前景和背景线索。并且,由于边界预测图隐式揭示了伪装物体的位置,因此可以有效消除背景噪声。计算公式:
由于边界区域是前景和背景区域的交集,因此可通过二者得到精细的边界预测图:
也可将二者沿通道维度连接获得融合特征,并送入卷积层得到精细化的掩码预测图:
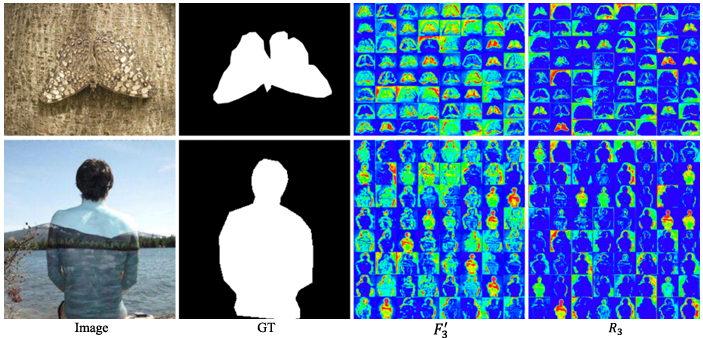
上图分别是第二解码器中最后一个 BFM 的输入和输出特征图,可见引入 BFM 使 BgNet 能够删除冗余的内部纹理并生成具有更清晰边界的特征。
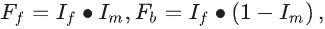
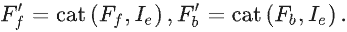
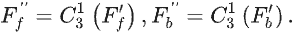
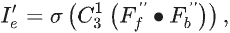
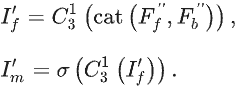
3.4Loss function
采用加权二进制交叉熵(wBCE)损失和加权交并越(wIoU)损失组成的混合损失函数:并将第二分支解码器的六个侧输出
M
3
,
M
4
,
M
5
,
E
3
,
E
4
,
E
5
M_3,M_4,M_5,E_3,E_4,E_5
M3,M4,M5,E3,E4,E5和第一分支解码器生成的粗略区域预测图
m
m
m上采样为原始图像大小后共同加入损失函数:
其中,
M
M
M是区域真实图,
E
E
E是边界真实图。
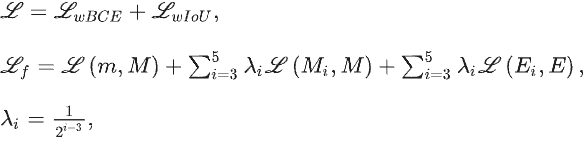
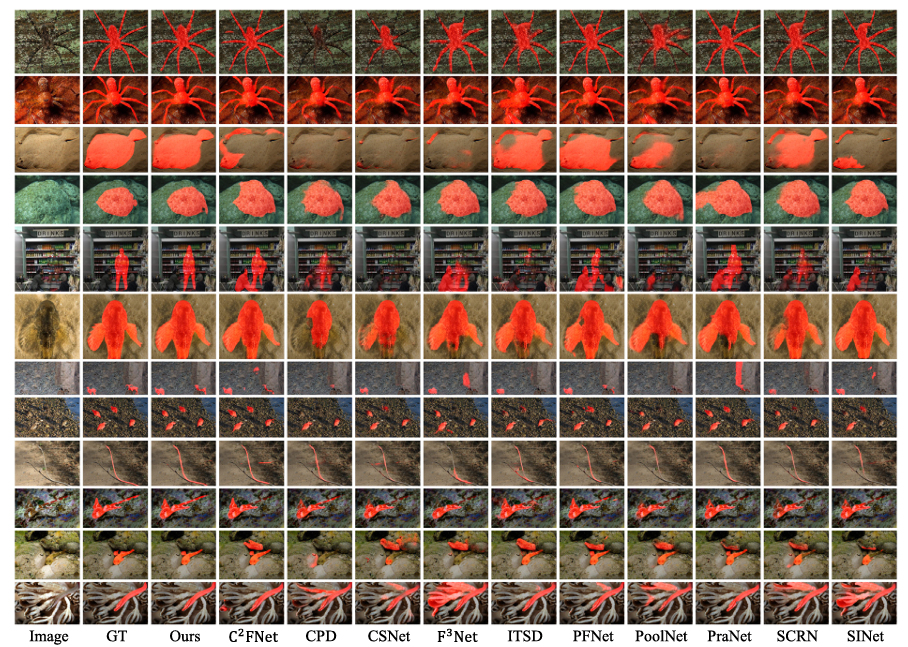
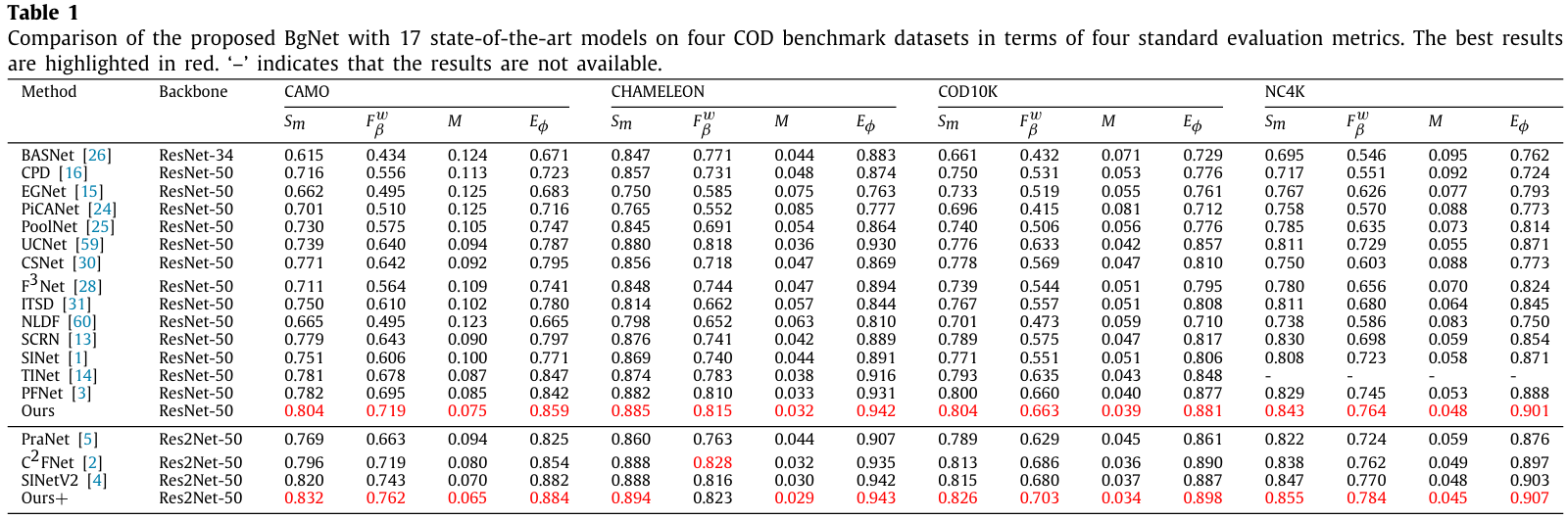
4.Experiments
4.1Datasets and evaluation metrics
使用了PR曲线、F-measure曲线、S-measure、加权F-measure( F β w F^w_β Fβw)、MAE、E-measure作为评估指标。
4.2Implementation details
ResNet-50 主干网的参数使用预训练模型的权重进行初始化,输入图像大小为
(
3
,
352
,
352
)
(3,352,352)
(3,352,352)并进行图像增强。使用初始学习率为
4
e
−
5
4e^{-5}
4e−5的Adam的优化器、
b
a
t
c
h
_
s
i
z
e
=
16
batch\_size=16
batch_size=16、每50epoch后将学习率除以10、共训练120个epoch。只使用最浅的侧输入
M
3
M_3
M3在测试阶段生成预测图,因为它具有最高的分辨率,因此可以保持最精细的细节。使用双线性插值将生成的预测图调整为完整大小。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读(三十五):Boundary-guided network for camouflaged object detection

发表评论 取消回复