温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
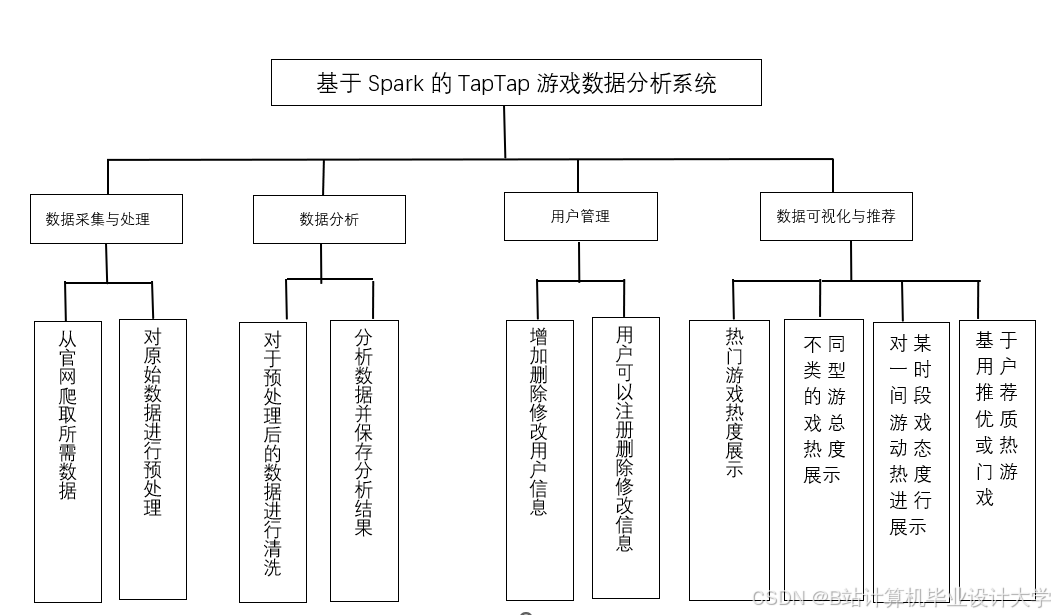
主要功能如下:
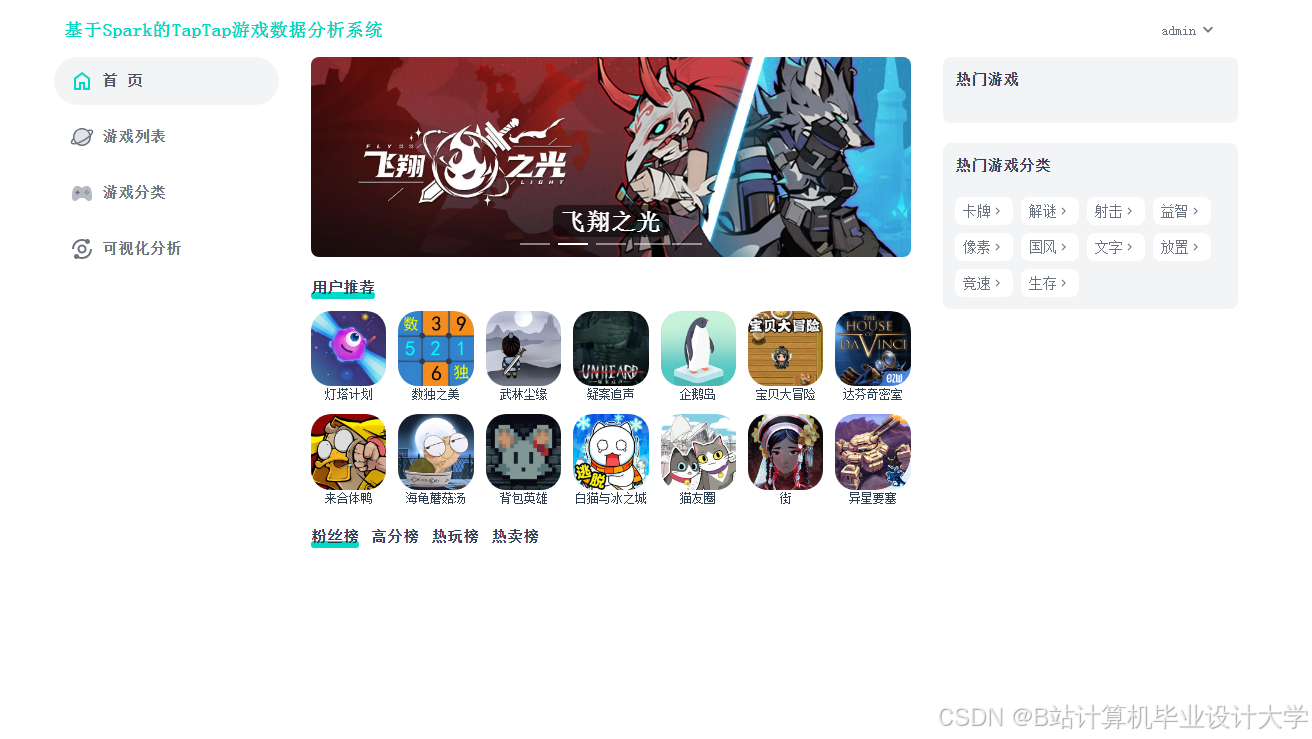
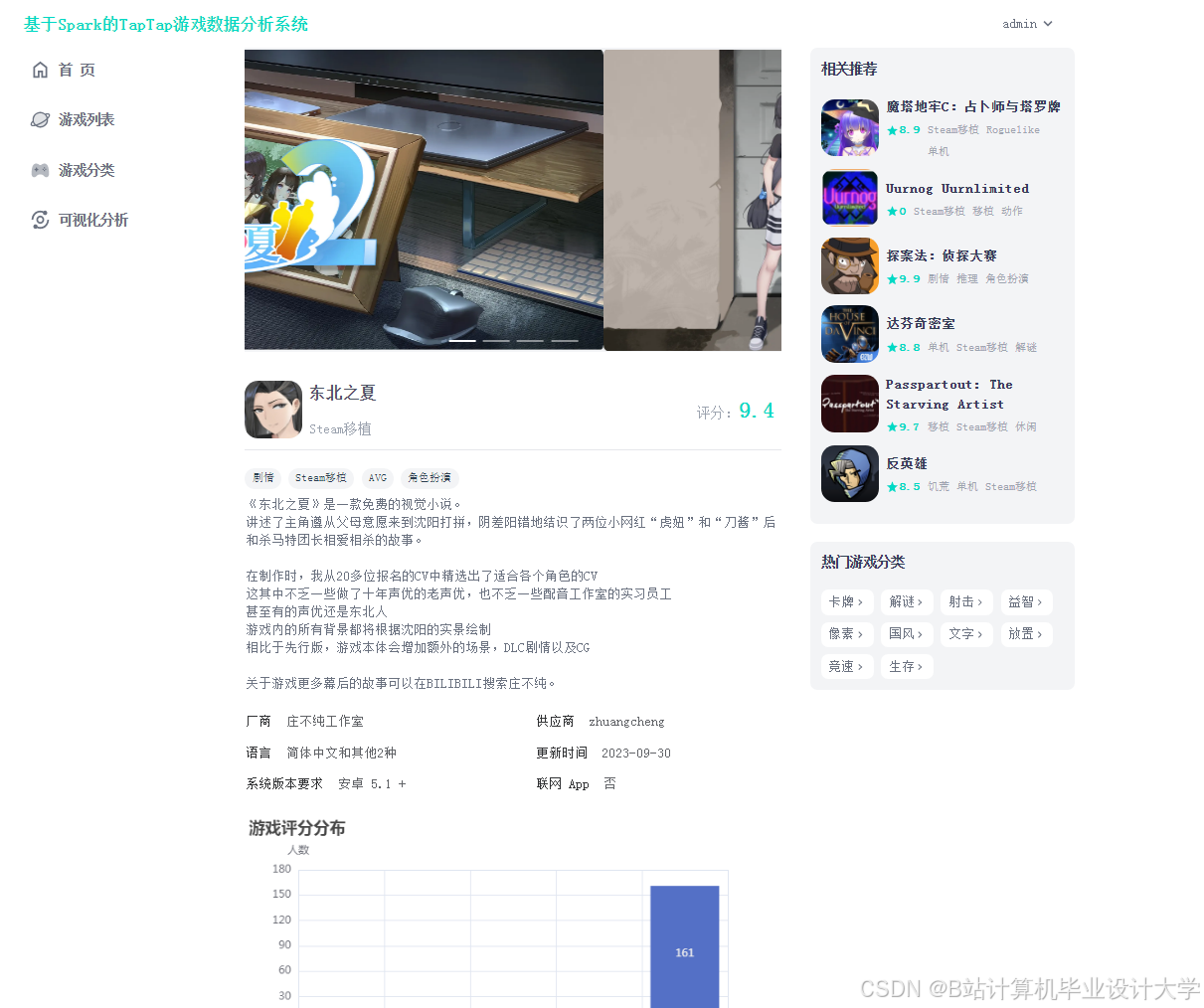
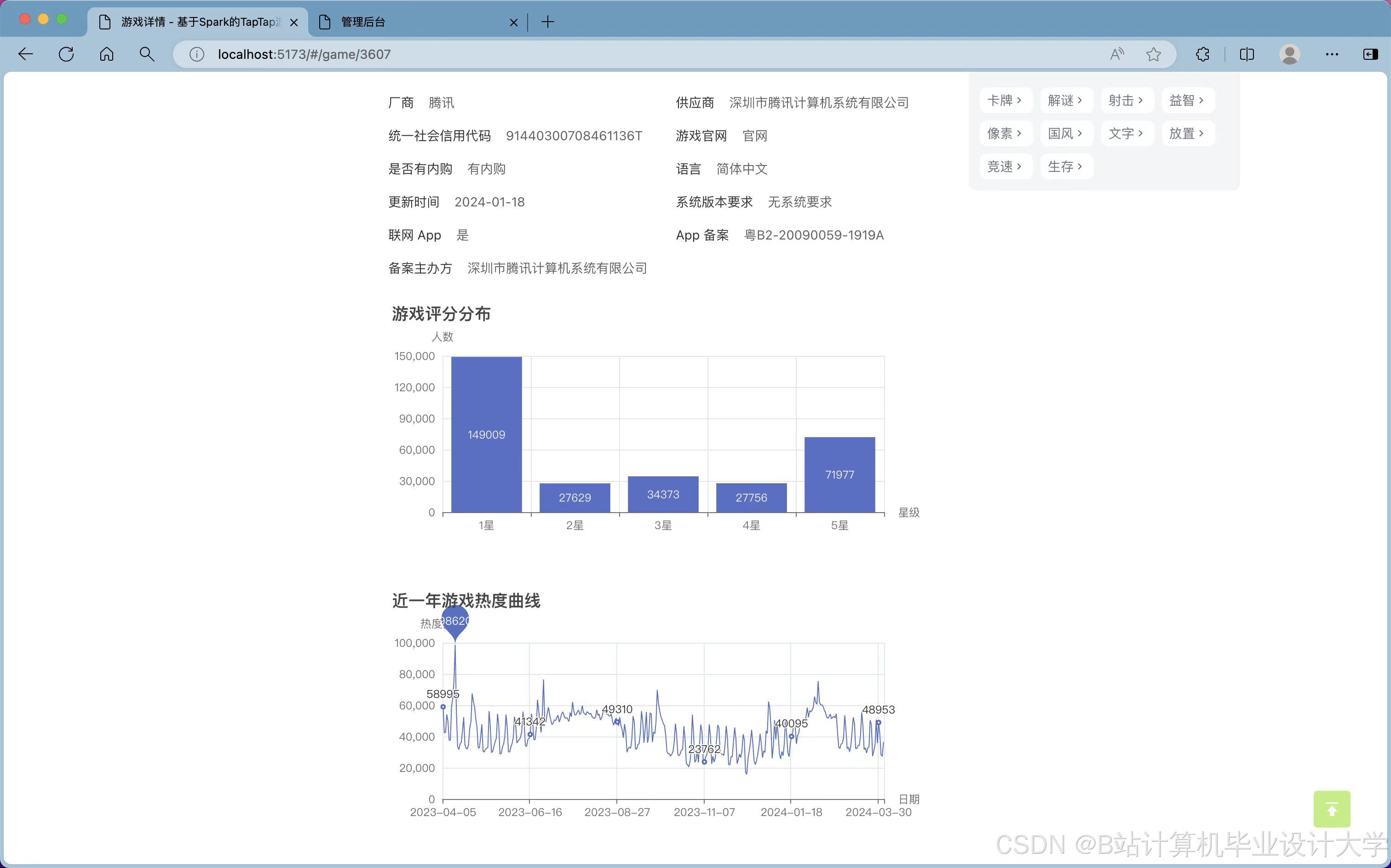
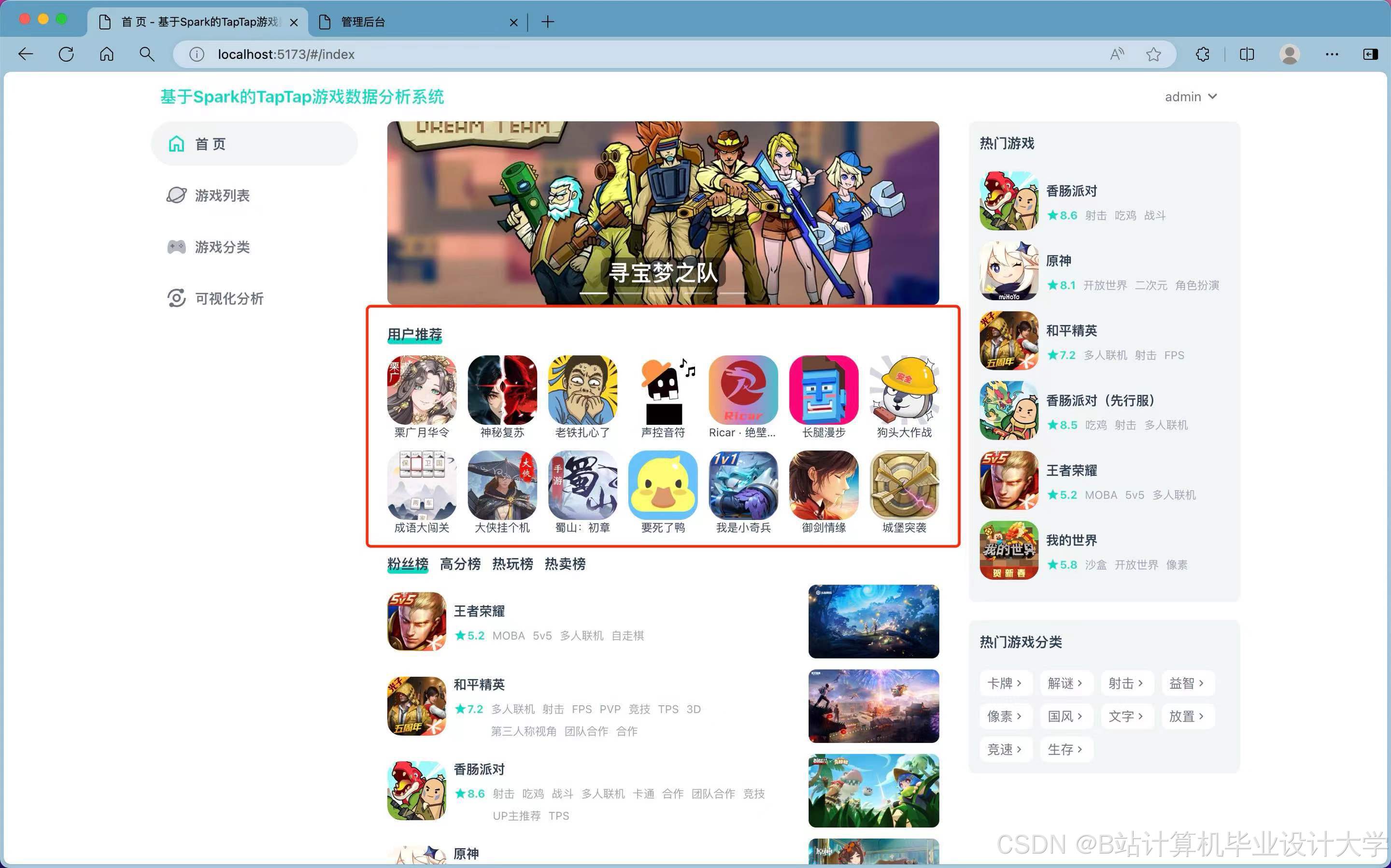
(1)用户管理模块:用户能够注册、登录及修改个人信息,查看热门游戏及攻略信息。
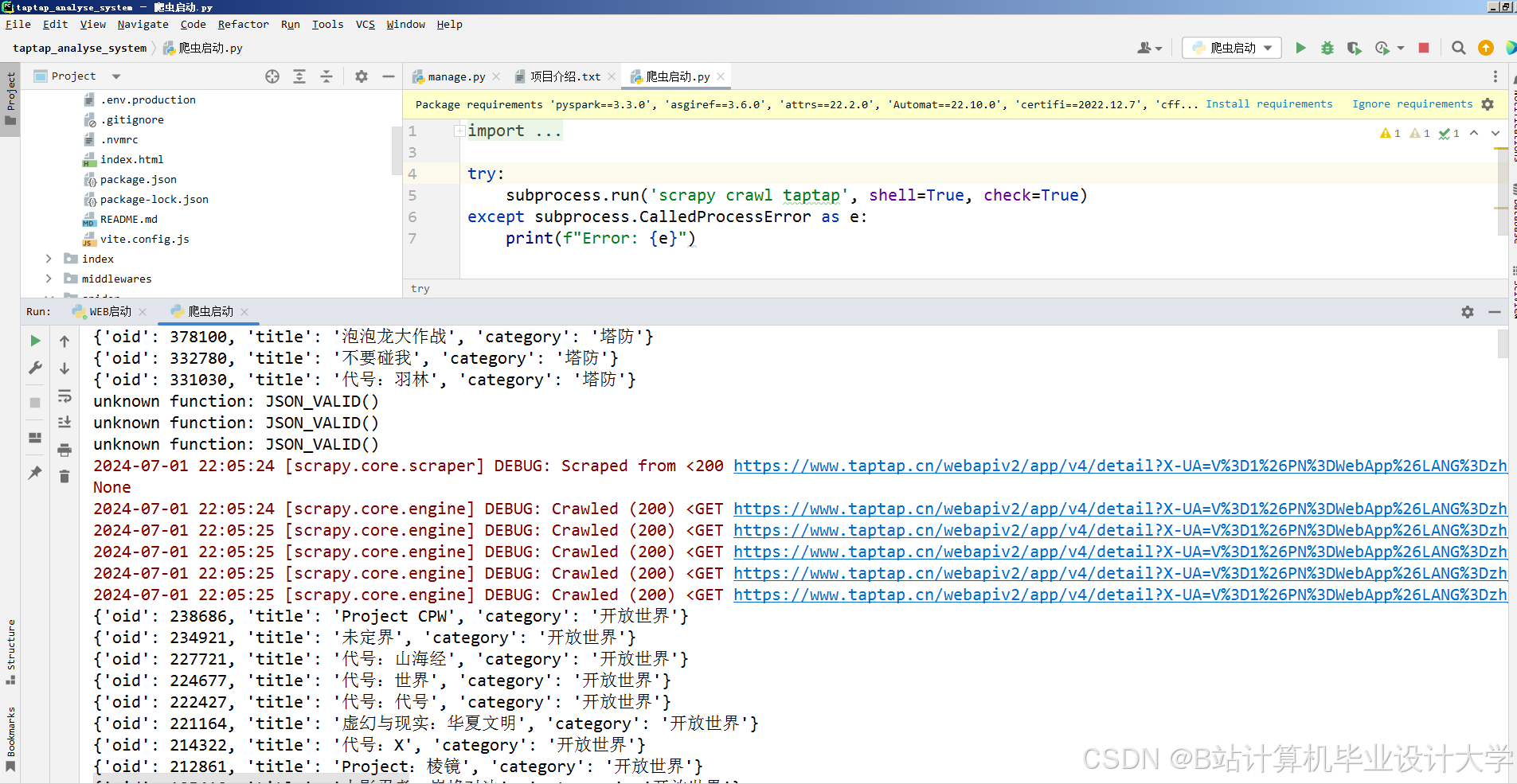
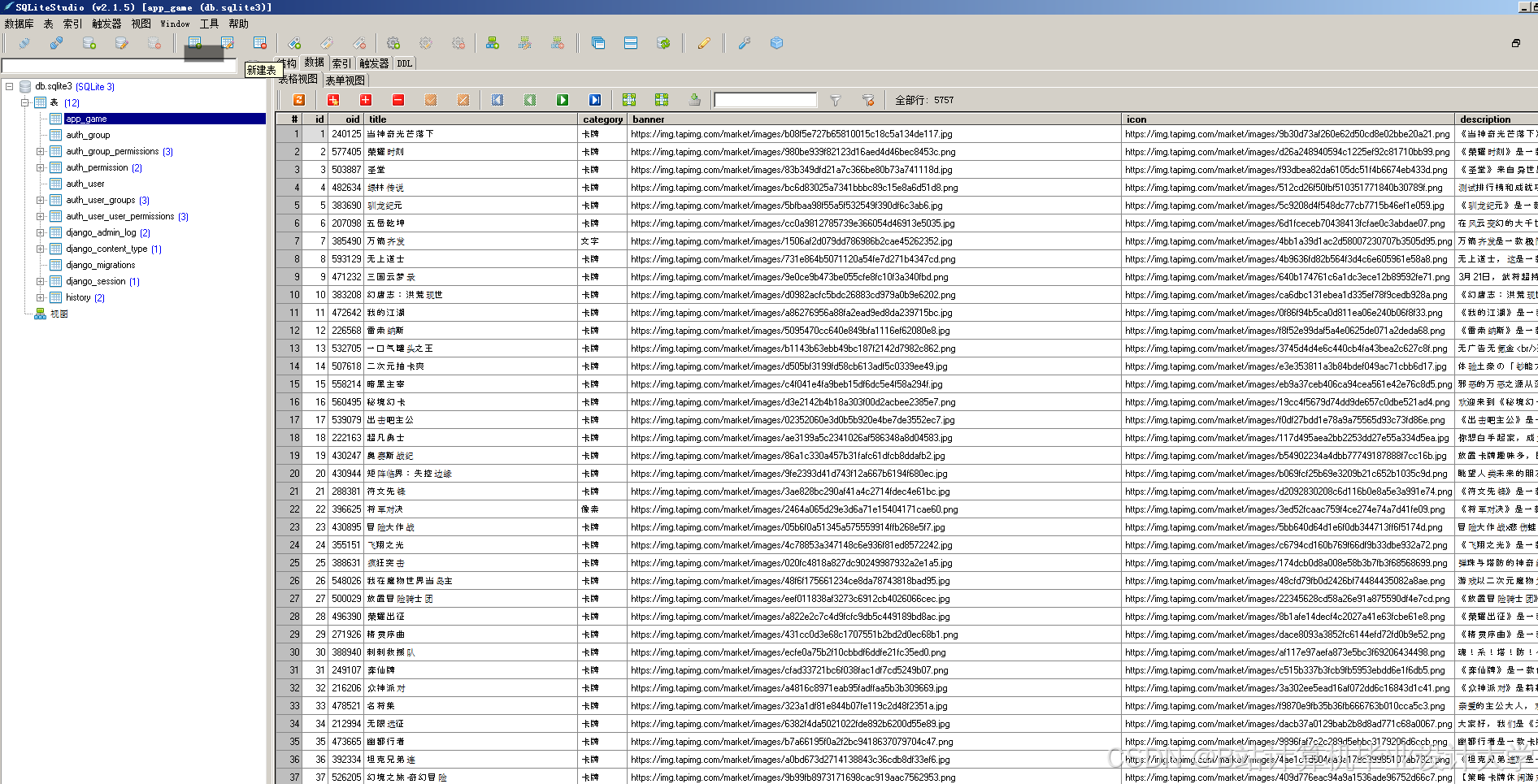
(2)数据采集与处理模块:主要通过Python编程,爬取Tap Tap社区中游戏热门榜、热玩榜以及游戏的标签、评分等数据,同时删除冗余和无用信息,以用于大数据分析。
(3)数据分析模块:
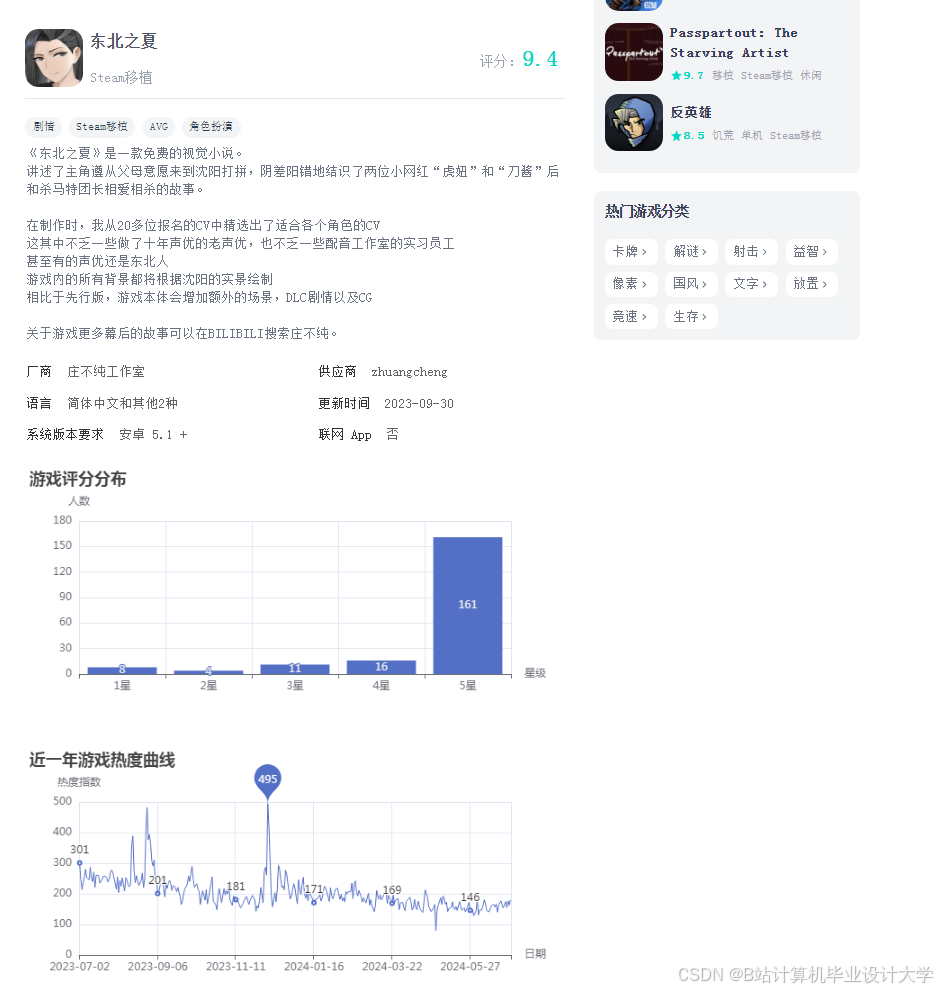
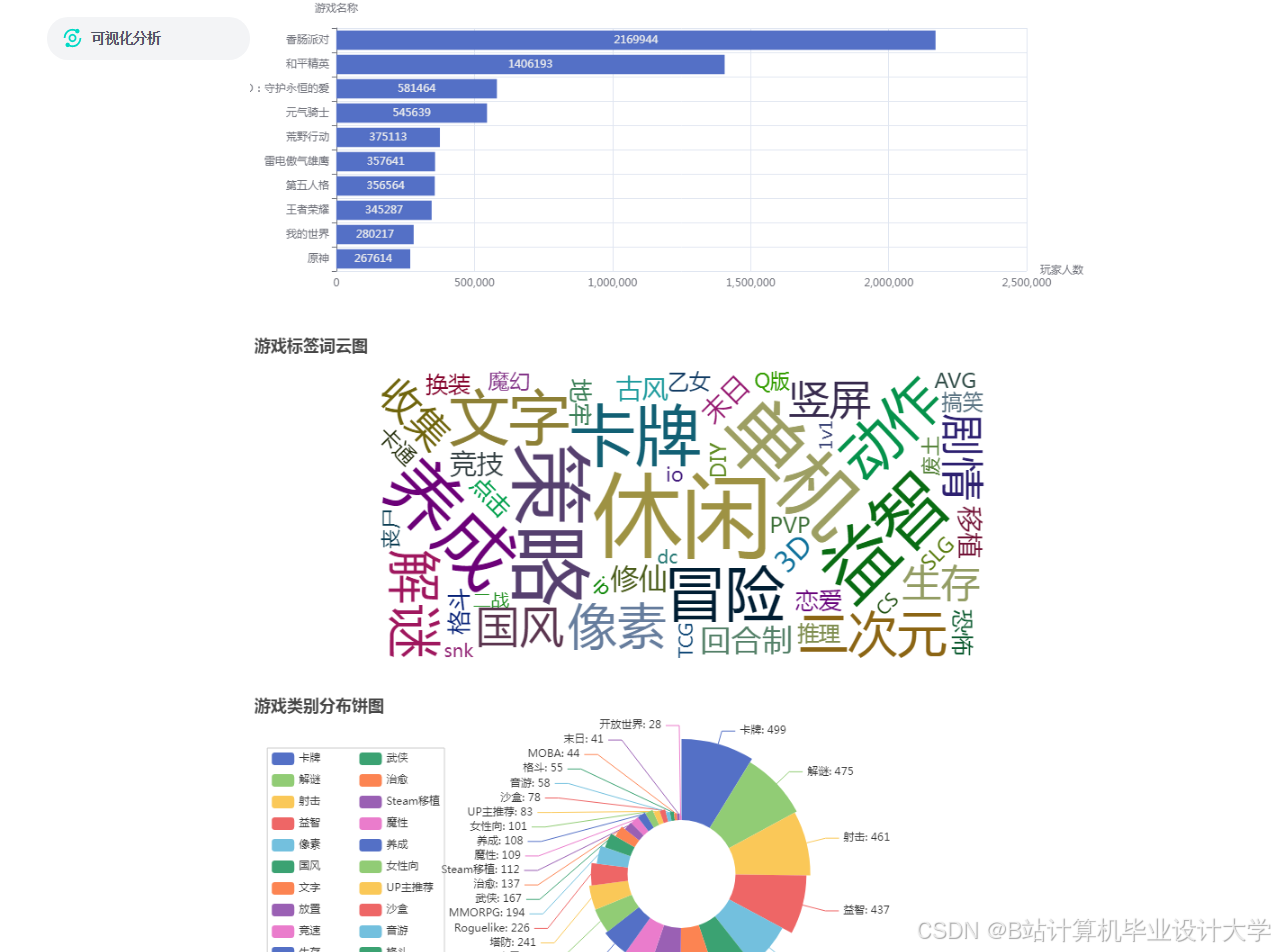
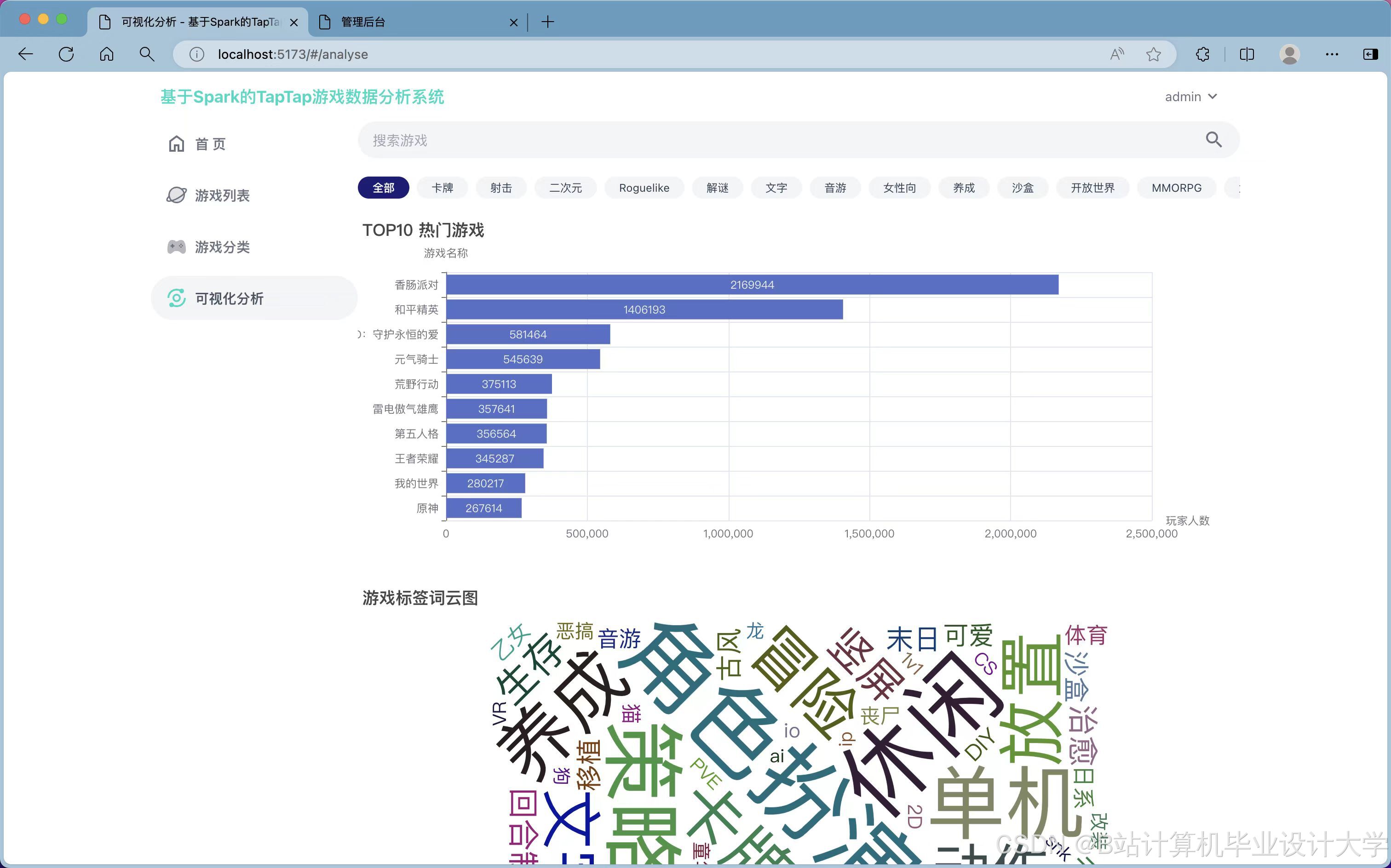
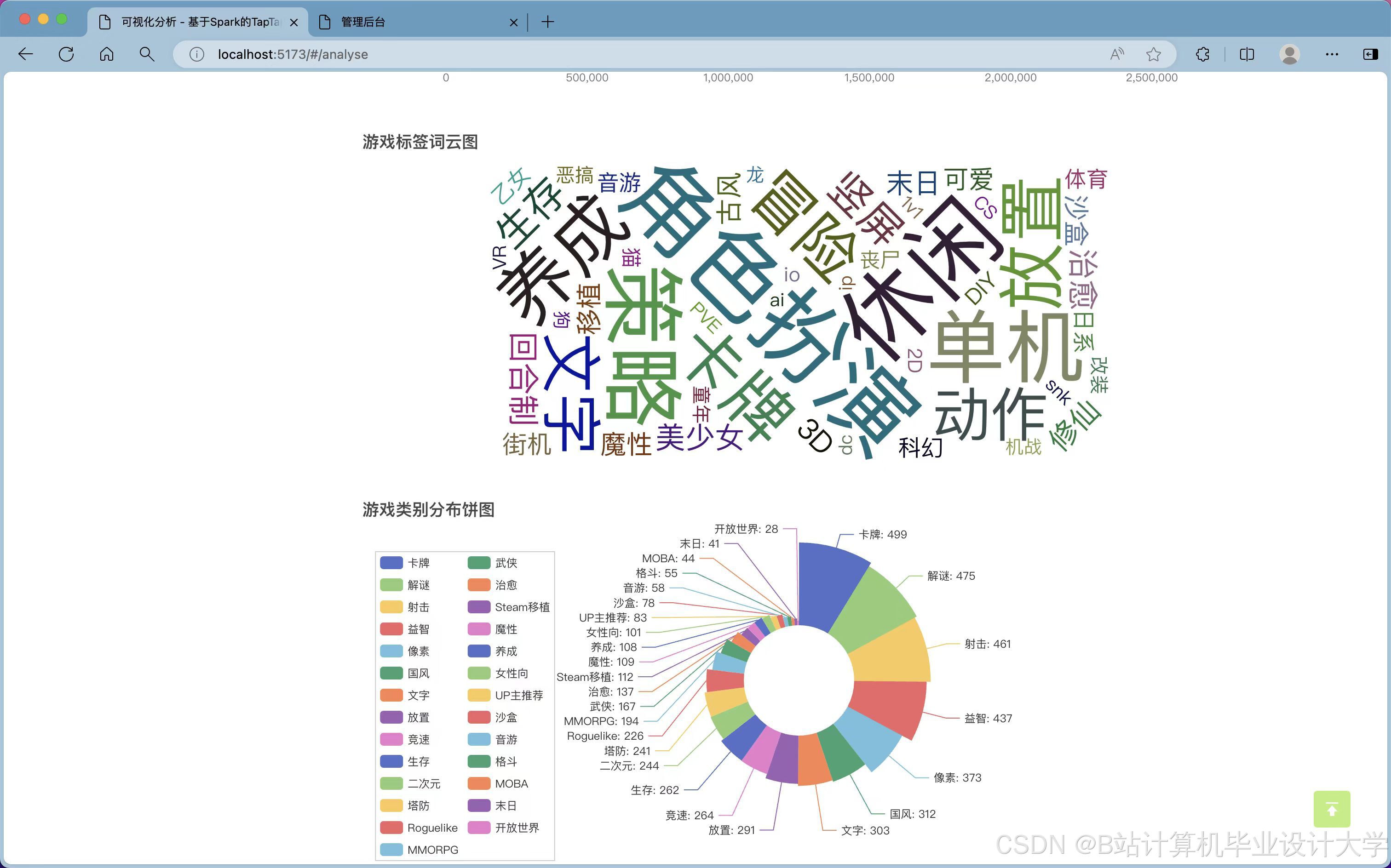
①类型分析:对爬取的数据进行梳理并分析不同标签游戏的数据榜单,例如策略、单机、休闲、卡牌等不同版块。获取游戏中下载数、关注数、评价数等信息内容并分析。
②动态分析:分析最新动态内有关游戏的图文、视频和帖子,将各种动态的发帖时间、游戏出处、讨论数,点赞数量和游戏动态数量进行数据分析,分析某一时间段游戏动态热度并进行排名。
③游戏推荐:根据数据挖掘得到的信息,对所有游戏信息、游戏动态进行热度总结,按照不同权重和热度递增的方式筛选出不同游戏类型排名前十的游戏,点击进入不同的类型,系统会以最新和最热的方式进行游戏推荐。
(4)数据可视化模块:主要利用Echarts插件,对类型分析、动态分析、游戏推荐三个模块中数据分析的内容进行可视化展示。
Hadoop+PySpark深度学习游戏推荐系统
摘要
随着互联网技术的飞速发展,电子游戏已成为人们生活中不可或缺的一部分。然而,面对海量的游戏资源,用户往往难以找到适合自己的游戏。因此,构建一个高效、准确的游戏推荐系统显得尤为重要。本文旨在探讨基于Hadoop和PySpark的深度学习游戏推荐系统的设计与实现,以提供个性化的游戏体验。
引言
近年来,电子游戏市场持续繁荣,游戏种类和数量不断增加。然而,由于游戏市场的庞大和复杂性,用户往往难以从海量的游戏资源中筛选出符合自己兴趣的游戏。随着大数据和人工智能技术的不断发展,为游戏推荐系统的研究提供了更多的可能性。游戏推荐系统可以帮助用户快速找到适合自己的游戏,提高游戏体验,同时也可以为游戏开发者提供有价值的市场信息和用户反馈,帮助他们优化游戏设计。
研究背景及意义
传统的游戏推荐系统主要依赖于简单的规则匹配和协同过滤算法,但由于计算量大、处理速度慢,难以应对大规模数据处理的挑战。Hadoop和PySpark作为两种主流的大数据处理技术,因其高扩展性和高性能,被广泛应用于大数据处理领域。结合深度学习算法,可以进一步提高推荐系统的准确性和个性化程度。
系统架构与技术选型
系统架构
本系统采用Hadoop和PySpark作为大数据处理平台,结合深度学习算法,构建一个高效的游戏推荐系统。系统架构主要分为数据采集层、数据存储层、数据处理层、推荐算法层和用户交互层。
- 数据采集层:通过爬虫技术从游戏平台或第三方数据源收集用户历史游戏数据,包括游戏类型、评分、游戏时长等。
- 数据存储层:使用Hadoop的分布式文件系统(HDFS)存储大规模的游戏数据。
- 数据处理层:利用Hadoop的MapReduce和PySpark进行数据处理和分析,提取与游戏推荐相关的特征。
- 推荐算法层:基于深度学习算法,如卷积神经网络(CNN)和循环神经网络(RNN),设计和实现游戏推荐算法。
- 用户交互层:使用Django框架构建前端界面,展示推荐的热门游戏,并提供用户注册、登录、游戏推荐等功能。
技术选型
- Hadoop:用于存储和处理大规模的游戏数据。
- PySpark:用于高效的数据分析和模型训练。
- Django:用于构建前端界面和用户交互。
- MySQL:用于存储系统的业务数据,如用户信息、游戏信息等。
- 深度学习算法:如CNN、RNN等,用于提高推荐系统的准确性和个性化程度。
系统设计与实现
数据采集与预处理
通过爬虫技术从游戏平台或第三方数据源收集用户历史游戏数据,包括游戏类型、评分、游戏时长等。然后对数据进行清洗和预处理,包括数据去重、缺失值填充、异常值处理等。
特征提取与选择
从预处理后的数据中提取与游戏推荐相关的特征,如用户兴趣、游戏类型偏好等。使用Hadoop的MapReduce和PySpark进行特征提取和选择,以提高后续推荐算法的效果。
推荐算法设计与实现
基于深度学习算法,如CNN和RNN,设计和实现游戏推荐算法。算法的目标是根据用户的历史游戏数据和特征,为用户推荐符合其兴趣和偏好的游戏。
- CNN:用于提取游戏数据的局部特征,如游戏类型、评分等。
- RNN:用于捕捉用户的历史游戏行为序列,分析用户的长期兴趣。
系统测试与优化
对推荐系统进行测试,并根据测试结果对算法进行优化。测试指标包括推荐准确率、召回率、F1分数等。通过不断优化推荐算法,提高系统的准确性和效率。
实验验证与结果分析
实验设计
设计实验方案,收集用户行为数据和游戏数据,进行系统测试和验证。实验包括以下几个步骤:
- 数据收集:从游戏平台或第三方数据源收集用户历史游戏数据。
- 数据预处理:对数据进行清洗、转换和标准化处理。
- 特征提取:从预处理后的数据中提取与游戏推荐相关的特征。
- 模型训练:使用深度学习算法进行模型训练。
- 推荐测试:使用测试数据集进行推荐测试,评估系统的性能。
结果分析
通过实验验证,评估系统的推荐准确率、召回率、F1分数等关键指标。实验结果表明,基于Hadoop和PySpark的深度学习游戏推荐系统具有较高的准确性和效率,能够为用户提供个性化的游戏体验。
结论与展望
本文设计并实现了一个基于Hadoop和PySpark的深度学习游戏推荐系统。该系统能够高效处理大规模游戏数据,为用户提供个性化的游戏推荐服务。通过实验验证,系统的性能和准确性达到了预期目标。未来,我们将进一步优化推荐算法,提高系统的准确性和个性化程度,同时探索更多的大数据处理和深度学习技术在游戏推荐系统中的应用。
参考文献
由于篇幅限制,本文仅列出了部分参考文献。实际撰写时应根据具体研究内容和需求进行选择和补充。
- 基于Hadoop的热门游戏推荐系统的设计springboot+vue的项目(源码+lw+部署文档+讲解等)。
- 计算机毕业设计hadoop+spark+hive游戏推荐系统 游戏数据分析可视化大屏 steam游戏爬虫 游戏大数据 大数据毕业设计 机器学习 知识图谱。
- 计算机毕业设计Python深度学习游戏推荐系统 Django PySpark。
- Hadoop+Spark知网文献论文推荐系统 知识图谱 爬虫。
本文介绍了基于Hadoop和PySpark的深度学习游戏推荐系统的设计与实现。通过结合大数据处理技术和深度学习算法,该系统能够为用户提供个性化的游戏推荐服务,提高用户体验和满意度。希望本文的研究能够为游戏推荐系统的研究和发展提供一定的参考和借鉴。





实现一个完整的游戏推荐算法需要涉及多个步骤,包括数据预处理、特征工程、模型选择和训练等。由于篇幅限制,我将提供一个简化的示例,使用Python和流行的机器学习库(如scikit-learn)来构建一个基于协同过滤的游戏推荐算法。这个示例不会使用Hadoop或PySpark,因为这些技术通常用于处理大规模数据集,并且需要更复杂的设置。不过,我会提供一个基础的框架,你可以根据需要进行扩展,并考虑将这些技术集成到更大的系统中。
以下是一个简化的游戏推荐算法示例:
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 假设我们有一个包含用户游戏评分的数据集
# 数据集格式:用户ID, 游戏ID, 评分
data = {
'user_id': [1, 1, 1, 2, 2, 3, 3, 4, 4, 4],
'game_id': [101, 102, 103, 101, 104, 102, 105, 103, 104, 106],
'rating': [5, 3, 4, 4, 5, 2, 3, 4, 3, 5]
}
# 创建DataFrame
df = pd.DataFrame(data)
# 创建一个用户-游戏评分矩阵
user_game_matrix = df.pivot_table(index='user_id', columns='game_id', values='rating').fillna(0)
# 计算余弦相似度矩阵(用户相似度)
cosine_sim = cosine_similarity(user_game_matrix)
# 将相似度矩阵转换为DataFrame,方便查看
user_similarity_df = pd.DataFrame(cosine_sim, index=user_game_matrix.index, columns=user_game_matrix.index)
# 为给定用户推荐游戏(例如,用户ID为1)
def recommend_games(user_id, num_recommendations=3):
# 获取该用户的评分
user_ratings = user_game_matrix.loc[user_id]
# 计算该用户与其他用户的相似度,并找到最相似的用户
similar_users = user_similarity_df[user_id].sort_values(ascending=False).index[1:num_recommendations+1] # 排除自己
# 对每个相似用户的评分进行加权平均,根据相似度作为权重
similarity_scores = user_similarity_df.loc[user_id, similar_users]
weighted_sum = user_game_matrix.loc[similar_users].mul(similarity_scores.values.reshape(-1, 1), axis=0).sum(axis=0)
# 计算加权平均后的评分
weighted_average = weighted_sum / similarity_scores.sum()
# 排除该用户已经评分的游戏
recommended_games = weighted_average[user_ratings[user_ratings > 0].index == False].sort_values(ascending=False).head(num_recommendations)
return recommended_games
# 为用户ID为1推荐游戏
recommended_games = recommend_games(1)
print("为用户1推荐的游戏(按评分排序):")
print(recommended_games)这个示例代码做了以下几件事:
- 创建了一个包含用户游戏评分的数据集。
- 使用
pivot_table方法创建了一个用户-游戏评分矩阵。 - 计算了用户之间的余弦相似度。
- 定义了一个函数
recommend_games,它根据给定用户的评分和相似用户的评分来推荐游戏。 - 为用户ID为1推荐了游戏,并打印了推荐结果。
请注意,这个示例非常简化,并且没有考虑很多实际推荐系统中需要解决的问题,比如冷启动问题(新用户或新游戏没有足够的数据来生成推荐)、数据稀疏性问题、实时性要求等。此外,对于大规模数据集,你可能需要使用更高效的算法和数据结构,以及分布式计算技术(如Hadoop和PySpark)来加速处理过程。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 计算机毕业设计Hadoop+PySpark深度学习游戏推荐系统 游戏可视化 游戏数据分析 游戏爬虫 Scrapy 机器学习 人工智能 大数据毕设

发表评论 取消回复