MultilingualSD3-adapter 是为 SD3 量身定制的多语言适配器。 它源自 ECCV 2024 的一篇题为 PEA-Diffusion 的论文。ChineseFLUX.1-adapter是为Flux.1系列机型量身定制的多语言适配器,理论上继承了ByT5,可支持100多种语言,但在中文方面做了额外优化。 它源于一篇题为 PEA-Diffusion 的 ECCV 2024 论文。

PEA-Diffusion
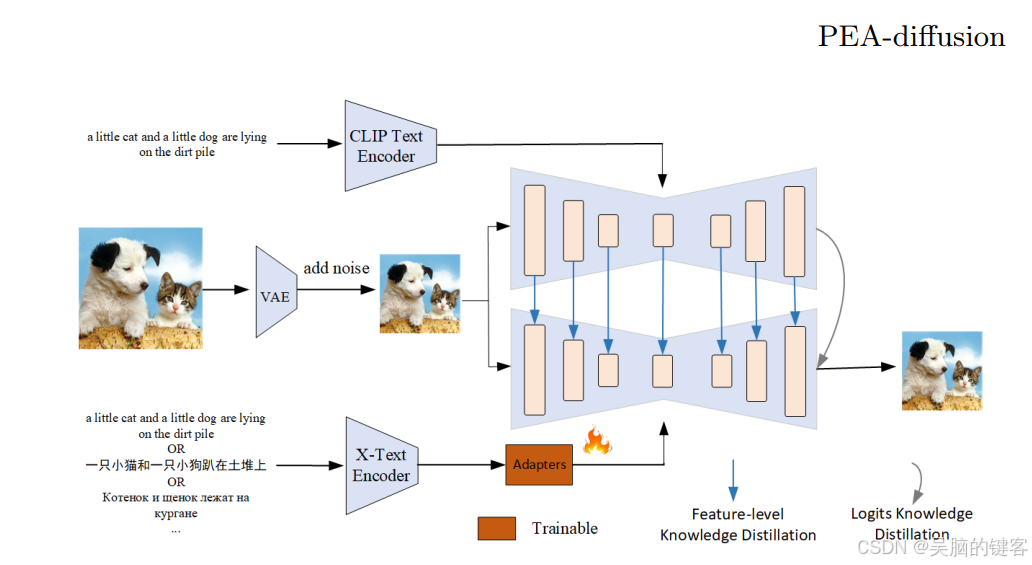
作者首先提到了一种名为 “知识蒸馏”(Knowledge Distillation,KD)的方法。KD 是一个过程,在这个过程中,一个较小的机器学习模型(称为学生)会学习模仿一个较大、较复杂的模型(称为教师)。在这种情况下,目标是让学生模型尽可能接近教师的输出或预测。这被称为 “强制学生分布与教师分布相匹配”。
然而,作者还希望确保教师模型和学生模型不仅能产生相似的输出结果,而且能以相似的方式处理信息。这就是特征对齐的作用所在。他们希望教师模型和学生模型的中间计算或特征图也能相似。因此,他们引入了一种技术,在这些模型的中间层增强这种特征对齐。这样做的目的是减少所谓的分布偏移,使学生模型更像教师模型。
现在,当模型之间存在维度差异时,OPPOer/ChineseFLUX.1-adapter 就会发挥作用。在这种情况下,他们使用的是名为 CLIP(对比语言图像预训练)的模型,一个用于英语数据,一个用于非英语数据。适配器是添加到模型中的一个小型附加组件,用于对齐或转换特征(中间计算)以匹配维度。该适配器经过训练,可以学习特定语言的信息,而且设计高效,只有 600 万个参数。
因此,总的来说,OPPOer/ChineseFLUX.1-adapter 是一种用于调整不同模型(在本例中为英语和非英语 CLIP 模型)中特征维度的技术,以促进知识提炼并提高学生模型的性能。它是这个复杂系统中一个小而重要的组成部分!
Code: https://github.com/OPPO-Mente-Lab/PEA-Diffusion
MultilingualSD3-adapter
我们使用了多语言编码器 umt5-xxl、Mul-OpenCLIP 和 HunyuanDiT_CLIP。 我们在蒸馏训练中采用了反向去噪处理。
import os
import torch
import torch.nn as nn
from typing import Any, Callable, Dict, List, Optional, Union
import inspect
from diffusers.models.transformers import SD3Transformer2DModel
from diffusers.image_processor import VaeImageProcessor
from diffusers.schedulers import FlowMatchEulerDiscreteScheduler
from diffusers import AutoencoderKL
from tqdm import tqdm
from PIL import Image
from transformers import T5Tokenizer,T5EncoderModel,BertModel, BertTokenizer
import open_clip
class MLP(nn.Module):
def __init__(self, in_dim=1024, out_dim=2048, hidden_dim=2048, out_dim1=4096, use_residual=True):
super().__init__()
if use_residual:
assert in_dim == out_dim
self.layernorm = nn.LayerNorm(in_dim)
self.projector = nn.Sequential(
nn.Linear(in_dim, hidden_dim, bias=False),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim, bias=False),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim, bias=False),
nn.GELU(),
nn.Linear(hidden_dim, out_dim, bias=False),
)
self.fc = nn.Linear(out_dim, out_dim1)
self.use_residual = use_residual
def forward(self, x):
residual = x
x = self.layernorm(x)
x = self.projector(x)
x2 = nn.GELU()(x)
x2 = self.fc(x2)
return x2
class Transformer(nn.Module):
def __init__(self, d_model, n_heads, out_dim1, out_dim2,num_layers=1) -> None:
super().__init__()
self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=n_heads, dim_feedforward=2048, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.linear1 = nn.Linear(d_model, out_dim1)
self.linear2 = nn.Linear(d_model, out_dim2)
def forward(self, x):
x = self.transformer_encoder(x)
x1 = self.linear1(x)
x1 = torch.mean(x1,1)
x2 = self.linear2(x)
return x1,x2
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
def retrieve_timesteps(
scheduler,
num_inference_steps: Optional[int] = None,
device: Optional[Union[str, torch.device]] = None,
timesteps: Optional[List[int]] = None,
sigmas: Optional[List[float]] = None,
**kwargs,
):
if timesteps is not None and sigmas is not None:
raise ValueError("Only one of `timesteps` or `sigmas` can be passed. Please choose one to set custom values")
if timesteps is not None:
accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
if not accepts_timesteps:
raise ValueError(
f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
f" timestep schedules. Please check whether you are using the correct scheduler."
)
scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
timesteps = scheduler.timesteps
num_inference_steps = len(timesteps)
elif sigmas is not None:
accept_sigmas = "sigmas" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
if not accept_sigmas:
raise ValueError(
f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
f" sigmas schedules. Please check whether you are using the correct scheduler."
)
scheduler.set_timesteps(sigmas=sigmas, device=device, **kwargs)
timesteps = scheduler.timesteps
num_inference_steps = len(timesteps)
else:
scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
timesteps = scheduler.timesteps
return timesteps, num_inference_steps
class StableDiffusionTest():
def __init__(self,model_path,text_encoder_path,text_encoder_path1,text_encoder_path2,proj_path,proj_t5_path):
super().__init__()
self.transformer = SD3Transformer2DModel.from_pretrained(model_path, subfolder="transformer",torch_dtype=dtype).to(device)
self.vae = AutoencoderKL.from_pretrained(model_path, subfolder="vae").to(device,dtype=dtype)
self.scheduler = FlowMatchEulerDiscreteScheduler.from_pretrained(model_path, subfolder="scheduler")
self.vae_scale_factor = (
2 ** (len(self.vae.config.block_out_channels) - 1) if hasattr(self, "vae") and self.vae is not None else 8
)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.default_sample_size = (
self.transformer.config.sample_size
if hasattr(self, "transformer") and self.transformer is not None
else 128
)
self.text_encoder_t5 = T5EncoderModel.from_pretrained(text_encoder_path).to(device,dtype=dtype)
self.tokenizer_t5 = T5Tokenizer.from_pretrained(text_encoder_path)
self.text_encoder = BertModel.from_pretrained(f"{text_encoder_path1}/clip_text_encoder", False, revision=None).to(device,dtype=dtype)
self.tokenizer = BertTokenizer.from_pretrained(f"{text_encoder_path1}/tokenizer")
self.text_encoder2, _, _ = open_clip.create_model_and_transforms('xlm-roberta-large-ViT-H-14', pretrained=text_encoder_path2)
self.tokenizer2 = open_clip.get_tokenizer('xlm-roberta-large-ViT-H-14')
self.text_encoder2.text.output_tokens = True
self.text_encoder2 = self.text_encoder2.to(device,dtype=dtype)
self.proj = MLP(2048, 2048, 2048, 4096, use_residual=False).to(device,dtype=dtype)
self.proj.load_state_dict(torch.load(proj_path, map_location="cpu"))
self.proj_t5 = Transformer(d_model=4096, n_heads=8, out_dim1=2048, out_dim2=4096).to(device,dtype=dtype)
self.proj_t5.load_state_dict(torch.load(proj_t5_path, map_location="cpu"))
def encode_prompt(self, prompt, device, do_classifier_free_guidance=True, negative_prompt=None):
batch_size = len(prompt) if isinstance(prompt, list) else 1
text_input_ids_t5 = self.tokenizer_t5(
prompt,
padding="max_length",
max_length=77,
truncation=True,
add_special_tokens=False,
return_tensors="pt",
).input_ids.to(device)
text_embeddings = self.text_encoder_t5(text_input_ids_t5)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=77,
truncation=True,
return_tensors="pt",
)
input_ids = text_inputs.input_ids.to(device)
attention_mask = text_inputs.attention_mask.to(device)
encoder_hidden_states = self.text_encoder(input_ids,attention_mask=attention_mask)[0]
text_input_ids = self.tokenizer2(prompt).to(device)
_,encoder_hidden_states2 = self.text_encoder2.encode_text(text_input_ids)
encoder_hidden_states = torch.cat([encoder_hidden_states, encoder_hidden_states2], dim=-1)
encoder_hidden_states_t5 = text_embeddings[0]
encoder_hidden_states = self.proj(encoder_hidden_states)
add_text_embeds,encoder_hidden_states_t5 = self.proj_t5(encoder_hidden_states_t5.half())
prompt_embeds = torch.cat([encoder_hidden_states, encoder_hidden_states_t5], dim=-2)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
if negative_prompt is None:
uncond_tokens = [""] * batch_size
else:
uncond_tokens = negative_prompt
text_input_ids_t5 = self.tokenizer_t5(
uncond_tokens,
padding="max_length",
max_length=77,
truncation=True,
add_special_tokens=False,
return_tensors="pt",
).input_ids.to(device)
text_embeddings = self.text_encoder_t5(text_input_ids_t5)
text_inputs = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=77,
truncation=True,
return_tensors="pt",
)
input_ids = text_inputs.input_ids.to(device)
attention_mask = text_inputs.attention_mask.to(device)
encoder_hidden_states = self.text_encoder(input_ids,attention_mask=attention_mask)[0]
text_input_ids = self.tokenizer2(uncond_tokens).to(device)
_,encoder_hidden_states2 = self.text_encoder2.encode_text(text_input_ids)
encoder_hidden_states = torch.cat([encoder_hidden_states, encoder_hidden_states2], dim=-1)
encoder_hidden_states_t5 = text_embeddings[0]
encoder_hidden_states_uncond = self.proj(encoder_hidden_states)
add_text_embeds_uncond,encoder_hidden_states_t5_uncond = self.proj_t5(encoder_hidden_states_t5.half())
prompt_embeds_uncond = torch.cat([encoder_hidden_states_uncond, encoder_hidden_states_t5_uncond], dim=-2)
prompt_embeds = torch.cat([prompt_embeds_uncond, prompt_embeds], dim=0)
pooled_prompt_embeds = torch.cat([add_text_embeds_uncond, add_text_embeds], dim=0)
return prompt_embeds,pooled_prompt_embeds
def prepare_latents(
self,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
generator,
latents=None,
):
if latents is not None:
return latents.to(device=device, dtype=dtype)
shape = (
batch_size,
num_channels_latents,
int(height) // self.vae_scale_factor,
int(width) // self.vae_scale_factor,
)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
latents = torch.randn(shape, generator=generator, dtype=dtype).to(device)
return latents
@property
def guidance_scale(self):
return self._guidance_scale
@property
def clip_skip(self):
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
return self._guidance_scale > 1
@property
def joint_attention_kwargs(self):
return self._joint_attention_kwargs
@property
def num_timesteps(self):
return self._num_timesteps
@property
def interrupt(self):
return self._interrupt
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
prompt_2: Optional[Union[str, List[str]]] = None,
prompt_3: Optional[Union[str, List[str]]] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 28,
timesteps: List[int] = None,
guidance_scale: float = 7.0,
negative_prompt: Optional[Union[str, List[str]]] = None,
negative_prompt_2: Optional[Union[str, List[str]]] = None,
negative_prompt_3: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
joint_attention_kwargs: Optional[Dict[str, Any]] = None,
clip_skip: Optional[int] = None,
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
):
height = height or self.default_sample_size * self.vae_scale_factor
width = width or self.default_sample_size * self.vae_scale_factor
self._guidance_scale = guidance_scale
self._clip_skip = clip_skip
self._joint_attention_kwargs = joint_attention_kwargs
self._interrupt = False
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
prompt_embeds,pooled_prompt_embeds = self.encode_prompt(prompt, device)
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
self._num_timesteps = len(timesteps)
num_channels_latents = self.transformer.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
for i, t in tqdm(enumerate(timesteps)):
if self.interrupt:
continue
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
timestep = t.expand(latent_model_input.shape[0]).to(dtype=dtype)
noise_pred = self.transformer(
hidden_states=latent_model_input,
timestep=timestep,
encoder_hidden_states=prompt_embeds.to(dtype=self.transformer.dtype),
pooled_projections=pooled_prompt_embeds.to(dtype=self.transformer.dtype),
joint_attention_kwargs=self.joint_attention_kwargs,
return_dict=False,
)[0]
if self.do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
latents_dtype = latents.dtype
latents = self.scheduler.step(noise_pred, t, latents, return_dict=False)[0]
if latents.dtype != latents_dtype:
if torch.backends.mps.is_available():
latents = latents.to(latents_dtype)
if callback_on_step_end is not None:
callback_kwargs = {}
for k in callback_on_step_end_tensor_inputs:
callback_kwargs[k] = locals()[k]
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
latents = callback_outputs.pop("latents", latents)
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
negative_pooled_prompt_embeds = callback_outputs.pop(
"negative_pooled_prompt_embeds", negative_pooled_prompt_embeds
)
if output_type == "latent":
image = latents
else:
latents = (latents / self.vae.config.scaling_factor) + self.vae.config.shift_factor
image = self.vae.decode(latents, return_dict=False)[0]
image = self.image_processor.postprocess(image, output_type=output_type)
return image
if __name__ == '__main__':
device = "cuda"
dtype = torch.float16
text_encoder_path = 'google/umt5-xxl'
text_encoder_path1 = "Tencent-Hunyuan/HunyuanDiT/t2i"
text_encoder_path2 = 'laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k/open_clip_pytorch_model.bin'
model_path = "stabilityai/stable-diffusion-3-medium-diffusers"
proj_path = "OPPOer/MultilingualSD3-adapter/pytorch_model.bin"
proj_t5_path = "OPPOer/MultilingualSD3-adapter/pytorch_model_t5.bin"
sdt = StableDiffusionTest(model_path,text_encoder_path,text_encoder_path1,text_encoder_path2,proj_path,proj_t5_path)
batch=2
height = 1024
width = 1024
while True:
raw_text = input("\nPlease Input Query (stop to exit) >>> ")
if not raw_text:
print('Query should not be empty!')
continue
if raw_text == "stop":
break
images = sdt([raw_text]*batch,height=height,width=width)
grid = image_grid(images, rows=1, cols=batch)
grid.save("MultilingualSD3.png")
ChineseFLUX.1-adapter
使用了多语言编码器 byt5-xxl,在适应过程中使用的教师模型是 FLUX.1-schnell。 我们采用了反向去噪过程进行蒸馏训练。 理论上,该适配器可应用于任何 FLUX.1 系列模型。 我们在此提供以下应用示例。
from diffusers import FluxPipeline, AutoencoderKL
from diffusers.image_processor import VaeImageProcessor
from transformers import T5ForConditionalGeneration,AutoTokenizer
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, in_dim=4096, out_dim=4096, hidden_dim=4096, out_dim1=768, use_residual=True):
super().__init__()
self.layernorm = nn.LayerNorm(in_dim)
self.projector = nn.Sequential(
nn.Linear(in_dim, hidden_dim, bias=False),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim, bias=False),
nn.GELU(),
nn.Linear(hidden_dim, out_dim, bias=False),
)
self.fc = nn.Linear(out_dim, out_dim1)
def forward(self, x):
x = self.layernorm(x)
x = self.projector(x)
x2 = nn.GELU()(x)
x1 = self.fc(x2)
x1 = torch.mean(x1,1)
return x1,x2
dtype = torch.bfloat16
device = "cuda"
ckpt_id = "black-forest-labs/FLUX.1-schnell"
text_encoder_ckpt_id = 'google/byt5-xxl'
proj_t5 = MLP(in_dim=4672, out_dim=4096, hidden_dim=4096, out_dim1=768).to(device=device,dtype=dtype)
text_encoder_t5 = T5ForConditionalGeneration.from_pretrained(text_encoder_ckpt_id).get_encoder().to(device=device,dtype=dtype)
tokenizer_t5 = AutoTokenizer.from_pretrained(text_encoder_ckpt_id)
proj_t5_save_path = f"diffusion_pytorch_model.bin"
state_dict = torch.load(proj_t5_save_path, map_location="cpu")
state_dict_new = {}
for k,v in state_dict.items():
k_new = k.replace("module.","")
state_dict_new[k_new] = v
proj_t5.load_state_dict(state_dict_new)
pipeline = FluxPipeline.from_pretrained(
ckpt_id, text_encoder=None, text_encoder_2=None,
tokenizer=None, tokenizer_2=None, vae=None,
torch_dtype=torch.bfloat16
).to(device)
vae = AutoencoderKL.from_pretrained(
ckpt_id,
subfolder="vae",
torch_dtype=torch.bfloat16
).to(device)
vae_scale_factor = 2 ** (len(vae.config.block_out_channels))
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)
while True:
raw_text = input("\nPlease Input Query (stop to exit) >>> ")
if not raw_text:
print('Query should not be empty!')
continue
if raw_text == "stop":
break
with torch.no_grad():
text_inputs = tokenizer_t5(
raw_text,
padding="max_length",
max_length=256,
truncation=True,
add_special_tokens=True,
return_tensors="pt",
).input_ids.to(device)
text_embeddings = text_encoder_t5(text_inputs)[0]
pooled_prompt_embeds,prompt_embeds = proj_t5(text_embeddings)
height, width = 1024, 1024
latents = pipeline(
prompt_embeds=prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
num_inference_steps=4, guidance_scale=0,
height=height, width=width,
output_type="latent",
).images
latents = FluxPipeline._unpack_latents(latents, height, width, vae_scale_factor)
latents = (latents / vae.config.scaling_factor) + vae.config.shift_factor
image = vae.decode(latents, return_dict=False)[0]
image = image_processor.postprocess(image, output_type="pil")
image[0].save("ChineseFLUX.jpg")
MultilingualOpenFLUX.1
是对 FLUX.1-schnell 模型的微调,已对其进行了蒸馏训练。 请务必更新以下代码中下载的 fast-lora.safetensors 的路径。
from diffusers import FluxPipeline, AutoencoderKL
from diffusers.image_processor import VaeImageProcessor
from transformers import T5ForConditionalGeneration,AutoTokenizer
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, in_dim=4096, out_dim=4096, hidden_dim=4096, out_dim1=768, use_residual=True):
super().__init__()
self.layernorm = nn.LayerNorm(in_dim)
self.projector = nn.Sequential(
nn.Linear(in_dim, hidden_dim, bias=False),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim, bias=False),
nn.GELU(),
nn.Linear(hidden_dim, out_dim, bias=False),
)
self.fc = nn.Linear(out_dim, out_dim1)
def forward(self, x):
x = self.layernorm(x)
x = self.projector(x)
x2 = nn.GELU()(x)
x1 = self.fc(x2)
x1 = torch.mean(x1,1)
return x1,x2
dtype = torch.bfloat16
device = "cuda"
ckpt_id = "ostris/OpenFLUX.1"
text_encoder_ckpt_id = 'google/byt5-xxl'
proj_t5 = MLP(in_dim=4672, out_dim=4096, hidden_dim=4096, out_dim1=768).to(device=device,dtype=dtype)
text_encoder_t5 = T5ForConditionalGeneration.from_pretrained(text_encoder_ckpt_id).get_encoder().to(device=device,dtype=dtype)
tokenizer_t5 = AutoTokenizer.from_pretrained(text_encoder_ckpt_id)
proj_t5_save_path = f"diffusion_pytorch_model.bin"
state_dict = torch.load(proj_t5_save_path, map_location="cpu")
state_dict_new = {}
for k,v in state_dict.items():
k_new = k.replace("module.","")
state_dict_new[k_new] = v
proj_t5.load_state_dict(state_dict_new)
pipeline = FluxPipeline.from_pretrained(
ckpt_id, text_encoder=None, text_encoder_2=None,
tokenizer=None, tokenizer_2=None, vae=None,
torch_dtype=torch.bfloat16
).to(device)
pipeline.load_lora_weights("ostris/OpenFLUX.1/openflux1-v0.1.0-fast-lora.safetensors")
vae = AutoencoderKL.from_pretrained(
ckpt_id,
subfolder="vae",
torch_dtype=torch.bfloat16
).to(device)
vae_scale_factor = 2 ** (len(vae.config.block_out_channels))
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)
while True:
raw_text = input("\nPlease Input Query (stop to exit) >>> ")
if not raw_text:
print('Query should not be empty!')
continue
if raw_text == "stop":
break
with torch.no_grad():
text_inputs = tokenizer_t5(
raw_text,
padding="max_length",
max_length=256,
truncation=True,
add_special_tokens=True,
return_tensors="pt",
).input_ids.to(device)
text_embeddings = text_encoder_t5(text_inputs)[0]
pooled_prompt_embeds,prompt_embeds = proj_t5(text_embeddings)
height, width = 1024, 1024
latents = pipeline(
prompt_embeds=prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
num_inference_steps=4, guidance_scale=0,
height=height, width=width,
output_type="latent",
).images
latents = FluxPipeline._unpack_latents(latents, height, width, vae_scale_factor)
latents = (latents / vae.config.scaling_factor) + vae.config.shift_factor
image = vae.decode(latents, return_dict=False)[0]
image = image_processor.postprocess(image, output_type="pil")
image[0].save("ChineseOpenFLUX.jpg")
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » OPPO开源Diffusion多语言适配器—— MultilingualSD3-adapter 和 ChineseFLUX.1-adapter

发表评论 取消回复