参考资料:
Sora技术报告 https://openai.com/index/video-generation-models-as-world-simulators/4分钟详细揭密!Sora视频生成模型原理https://www.bilibili.com/video/BV1AW421K7Ut
https://openai.com/index/video-generation-models-as-world-simulators/4分钟详细揭密!Sora视频生成模型原理https://www.bilibili.com/video/BV1AW421K7Ut
一、概述
相较于Gen-2、Stable Diffusion、Pika等生成模型的前辈,Sora有更出众的一镜到底能力(超过60s)。一镜到底的实现中,难点在于让模型正确的理解两帧之间的逻辑性,使生成的视频具备连贯性。
二、Diffusion模型
Diffusion(扩散模型),会基于随机过程,从噪声图像中逐步祛除噪声来满足生成满足要求的图像。分为两个部分:前向扩散和反向扩散。

前向扩散会将一张清晰的图像逐步添加噪声,生成一张充满噪声的图像。而反向扩散则会从一堆噪声中逐步生成一张符合要求的清晰图片。通过反复迭代训练,模型能更好的从噪声中重建高质量的图像数据。

三、Transformer模型
这里的Transformer主要用于进行文本生成,而非图像识别领域的特征提取。当使用文本作为输入时,连续的文本会被token化,拆分为数个单词并附加位置信息。
接下来token会被编码器(Encoder)转换为更抽象的特征向量,而解码器(Decoder)则会根据特征向量来生成目标序列。需要注意的是,解码器会同时将特征向量和已生成的文本作为输入以保证上下文的连贯性。
四、Diffusion Transformer模型
Diffusion Transformer(DiT)模型借鉴了二、三的优势,为了保证生成内容的连贯性和一致性,Sora引入了时空patch的概念。类似于Transformer中的token,将原始视频通过视觉编码器被压缩为一组低维度特征向量。
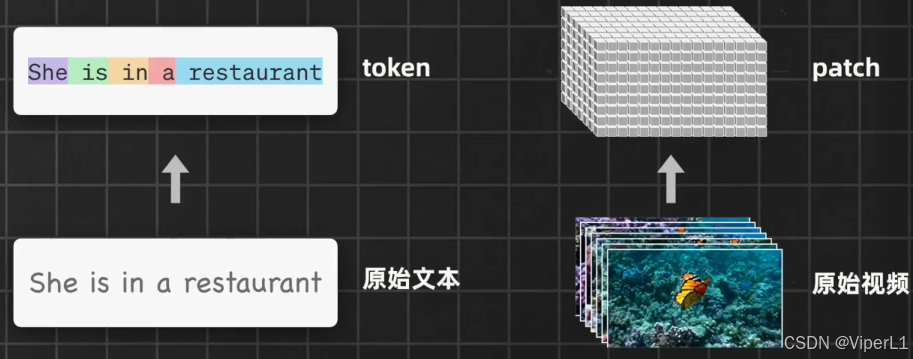
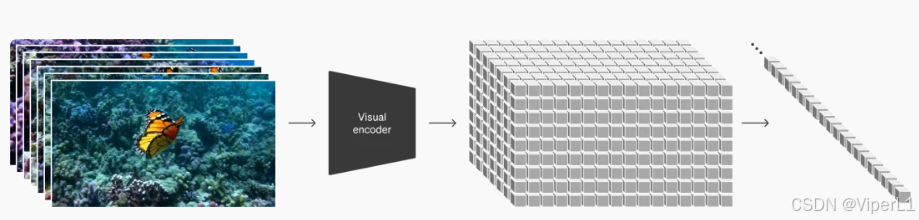
通过这种方式,模型可以同时关注视频中对象在当前帧中的空间位置和整个视频中的时间位置。

得益于视觉编码器的压缩,Sora可以很简单的在低维空间中进行训练。经过训练后,Sora会根据噪声patch和提示词生成清晰的patch。但这个patch实际上也是一个无法被人理解的低维表示。需要解码器将其还原成视频。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [大模型]视频生成-Sora简析

发表评论 取消回复